Motivation
Do we really need graph augmentations when integrating CL with recommendation?
- SGL과 같은 Graph structure augmentation based CL 방법 SGL-ED와 graph augmentation을 안한 SGL-WA와 성능상 거의 비등하다는 것이 관찰됨
Are there more effective and efficient augmentation approaches?
- Graph augmentation이 불러올 수 있는 문제점들
- Epoch마다 새로운 structure을 augment하면서 계속 새로운 graph adjacency matrix를 만드는 과정이 너무 time consuming
- 안그래도 sparse한 데이터에서 중요한 연결지점인 node나 edge를 drop하게 되면 graph structure 자체가 너무 달라져서 이를 align하는 것은 오히려 역효과를 불러올 수도 있음 - Graph augmentation이 무용지물이라면, 성능 향상을 이끌었던 주원인이 무엇이었는지 파악할 필요가 있음
Method
Summary
- Data Augmentation: Feature Noises
- Contrast Type: Node-Node
- Contrastive Objective: InfoNCE
- Training Scheme: Joint learning
Do we really need graph augmentations when integrating CL with recommendation?
- 사실상 성능 향상을 이끈 주원인은 Uniformity를 향상시킨 덕으로 드러났음 (CL: alignment + uniformity)
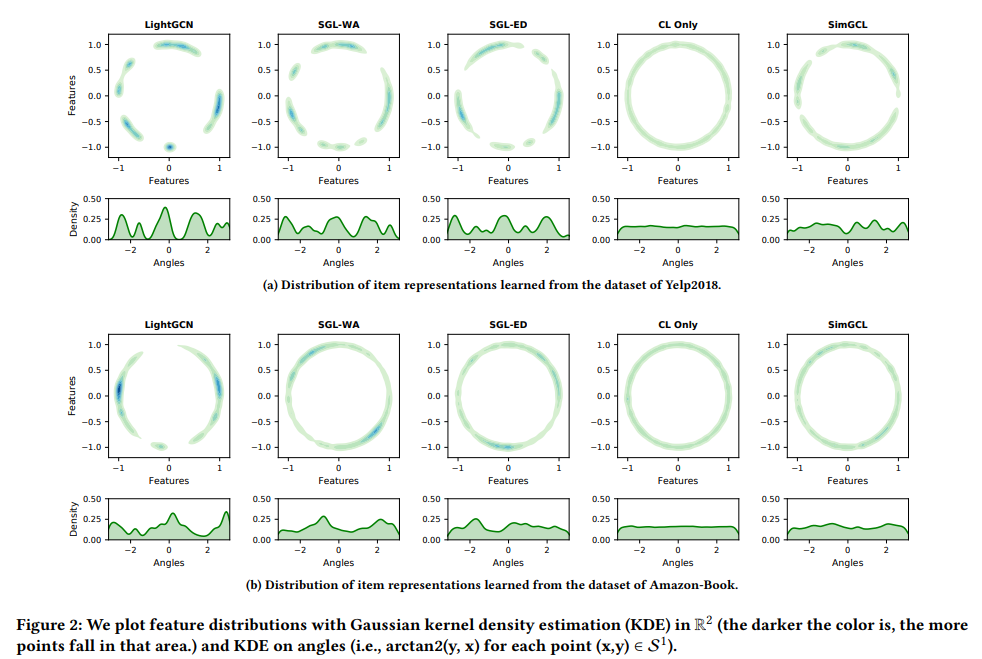
- 그림에서 앞선 4 columns(LightGCN, SGL-WA, SGL-ED, CL Only)만 봤을때, 왼쪽에서 오른쪽으로 갈수록 Clustered에서 Uniform으로 감
- Clustered LightGCN: 1) Message passing, 2) Popularity bias (U-I interaction이 long-tail distribution이기 때문) Representation degeneration을 초래함
- 보다 오른쪽 그림들처럼 uniformity를 증가시키기 위해서는 Contrastive loss를 optimizize 해야함
- 근데 극단의 경우에 CL loss만을 최적화하는 4번째 그림과 같은 경우는 uniformity는 최고로 좋지만 성능적으로는 더 떨어지게됨. Uniformity를 너무 높이려고 한다면 실제로 similar pair간이나 dissimilar pair들 모두 최대로 uniform하게 분포시키기 때문에 오히려 역효과가 남
'The excessive pursuit to the uniformity will overlook the closeness of interacted pairs and similar users/items, and impairs recommendation performance' - 따라서 결론적으로, Optimizing the contrastive loss (InfoNCE) > Graph augmentation
- Uniformity를 높이고 싶어! CL loss를 optimize해! 하지만 적당히 해야해 과하면 안됨! (Hyperparameter 로 CL loss의 기여도 조절)
Are there more effective and efficient augmentation approaches?
- SimGCL
- 이제 CL을 적용할건데, 아까 SGL-ED나 SGL-WA나 별 차이 없다는걸 보면 graph augmentation을 쓰는건 의미가 없고, 오히려 cumbersome하니까 다른 방식으로 augmentation을 해볼거야
- Embedding space 상에서 바로 representation에 랜덤 노이즈를 더해줌으로써 augmentation 함, 이 때 embedding space란 GCN을 통해서 neighbor aggregation이나 update 다 되고 나온 그 node embedding을 의미하는 거임! 이 최종 node embedding representation 자체에 노이즈만 더해주는 것!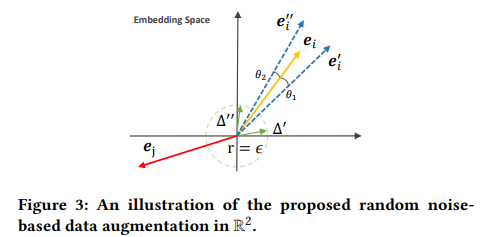
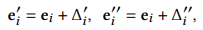 이 때, 더해주는 랜덤 노이즈의 두가지 constraints
이 때, 더해주는 랜덤 노이즈의 두가지 constraints
1) 그림의 초록색 원에서 볼 수 있다시피, 은 노이즈의 magnitude를 설정하는 hyperparameter
2) 빨간색처럼 되지 않게 하기 위해 노이즈를 더한 view들이 동일 사분면 내에 존재할 수 있도록 방향적인 constraint 또한 걸어줌
- Augmentation type이 바뀐 것을 제외하면 SGL과 완전히 동일함: LightGCN, BPR loss(SL loss), InfoNCE loss(CL loss)
Experiments
-
Benchmark Datasets: Douban-Book(#user 13,024, #item 22,347, #interaction 792,062), Yelp2018(#user 31,668, #item 38,048, #interaction 1,561,406), Amazon-Book(#user 52,463, #item 91,599, #interaction 2,984,108)
-
Evaluation Metrics: Recall@K, NDCG@K (K=20), all-ranking protocol
-
Analysis
- SGL이나 SimGCL이나 GCN 기반이라 그런지 shallow가 더 나음
- 전체적으로 SGL보다 수렴이 빠름, 애초에 SGL 저자들이 주장하는바와 같이 CL loss에 존재하는 다양한 negative sample을 사용하여 수렴이 빨라지는건 근거 없고, 사실 노이즈가 어떤식으로 momentum과 같은 역할을 하여 수렴을 빠르게 하는 것임
- Popular, Normal, Unpopular 아이템으로 나눠서 어떤 그룹이 성능 향상에 가장 크게 기인했는지 살펴보니 popular은 SGL에 비해 다소 약세하지만 Unpopular에서 크게 향상이 일어남. 이는, representation의 uniformity와 debias 능력간에 양의 상관관계가 있다는 반증이 됨
Pros(Contributions) and Cons(Possible Future Works)
Pros
- Regulating Uniformity
Uniformity Debias의 효과(long-tail distribution에서 unpopular item 또한 uniform하게 representation함으로써 unpopular item들도 추천되도록 장려할 수 있음)
정리하자면, SimGCL은 SGL처럼 CL loss를 최적화함으로써 uniform에 가깝게 가려고 하는데 여기서 보다 쓸데없는 graph augmentation을 안쓰고 더 효율적, 효과적인 random noise를 통한 embedding space augmentation을 한 것, 근데 이렇게 하니까 을 가지고 uniformity의 정도도 조절할 수 있어서 더 좋음
