
Case3
- 결측치 제거
- 불필요 컬럼 삭제 (ServiceArea, CustomerID)
- Unknown 많은 컬럼 삭제
- Age 컬럼 조정
- 이상치 제거
- RobustScaler 적용
함수
# scale_data_with_robust_scaler
def scale_data_with_robust_scaler(data):
rs = RobustScaler()
scaled_data = pd.DataFrame(rs.fit_transform(data), columns=data.columns)
return scaled_data
# split_train_test_data
def split_train_test_data(data, target_variable, test_size=0.3, random_state=70):
y = data[target_variable]
X = data.drop(columns=[target_variable])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=random_state)
print('X train shape: ', X_train.shape)
print('Y train shape: ', y_train.shape)
print('X test shape: ', X_test.shape)
print('Y test shape: ', y_test.shape)
return X_train, X_test, y_train, y_test
# report
def report(y_test, pred):
accuracy = accuracy_score(y_test, pred)
print("Accuracy:", accuracy)
precision = precision_score(y_test, pred)
print("Precision:", precision)
recall = recall_score(y_test, pred)
print("Recall:", recall)
f1 = f1_score(y_test, pred)
print("F1 Score:", f1)
tn = ((y_test == 0) & (pred == 0)).sum()
fp = ((y_test == 0) & (pred == 1)).sum()
specificity = tn / (tn + fp)
print("Specificity:", specificity)
# perform_cross_validation
def perform_cross_validation(X, y, models):
results = []
names = []
for name, model in models:
kfold = KFold(n_splits=5, random_state=70, shuffle=True)
cv_results = cross_val_score(model, X, y, cv=kfold, scoring='accuracy')
results.append(cv_results)
names.append(name)
print(name, cv_results.mean(), cv_results.std())
# evaluate_models_rs
def evaluate_models_rs(models, X_train, y_train, X_test, y_test, df):
for name, model in models:
kfold = KFold(n_splits=5, random_state=70, shuffle=True)
model.fit(X_train, y_train)
pred = model.predict(X_test)
print(name)
print(classification_report(y_test, pred, target_names=['No', 'Yes']))
accuracy = accuracy_score(y_test, pred)
precision = precision_score(y_test, pred, pos_label=1.0)
recall = recall_score(y_test, pred, pos_label=1.0)
f1 = f1_score(y_test, pred, pos_label=1.0)
model_results = pd.DataFrame({'Model': [name],
'Accuracy': [accuracy],
'Precision': [precision],
'Recall': [recall],
'F1-Score': [f1]})
df = pd.concat([df, model_results], ignore_index=True)
return dfdata2 = train.copy()결측치 제거
data2.dropna(inplace=True)
data2.reset_index(drop=True, inplace=True)
data2.isnull().sum().sort_values(ascending=False)Unknown 값이 50% 이상인 컬럼과 ServiceArea 제거
drop_cols = ['MaritalStatus', 'HandsetPrice', 'Homeownership', 'ServiceArea' , 'CustomerID']
data2.drop(drop_cols, inplace=True, axis=1)AgeHH1, AgeHH2의 0값은 소득 그룹과, 신용등급이 동일한 그룹의 중간값으로 대치
cond1 = (data2[['AgeHH1']]!=0).values
cond2 = (data2[['AgeHH2']]!=0).values
data_not_zero = data2[cond1&cond2]
grouped_median = data_not_zero.groupby(['IncomeGroup', 'CreditRating'])[['AgeHH1', 'AgeHH2']].agg('median')
for index, row in data2.iterrows():
if row['AgeHH1'] == 0:
median_value = grouped_median.loc[(row['IncomeGroup'], row['CreditRating']), 'AgeHH1']
data2.at[index, 'AgeHH1'] = median_value
if row['AgeHH2'] == 0:
median_value = grouped_median.loc[(row['IncomeGroup'], row['CreditRating']), 'AgeHH2']
data2.at[index, 'AgeHH2'] = median_value라벨인코딩
le = LabelEncoder()
object_cols = data2.select_dtypes(include=['object']).columns
data2[object_cols] = data2[object_cols].apply(le.fit_transform)이상치 제거
# n_estimators : 노드 수 (50 - 100사이의 숫자면 적당하다.)
# max_samples : 샘플링 수
# contamination : 이상치 비율
# max_features : 사용하고자 하는 독립변수 수 (1이면 전부 사용)
# random_state : seed를 일정하게 유지시켜줌(if None, the random number generator is the RandomState instance used by np.random)
# n_jobs : CPU 병렬처리 유뮤(1이면 안하는 것으로 디버깅에 유리. -1을 넣으면 multilple CPU를 사용하게 되어 메모리 사용량이 급격히 늘어날 수 있다.)
clf_ss = IsolationForest(n_estimators=100,
max_samples="auto",
contamination=0.01,
max_features=1,
bootstrap=False,
n_jobs=1,
random_state=None,
verbose=0)
# fit 함수를 이용하여, 데이터셋을 학습시킨다.
clf_ss.fit(data2)
# predict 함수를 이용하여, outlier를 판별해 준다. 0과 1로 이루어진 Series형태의 데이터가 나온다.
y_pred_outliers = clf_ss.predict(data2)
# 이상치의 개수를 Count하는 과정
collections.Counter(y_pred_outliers)
# 원래의 DataFrame에 붙히기. out행의 값이 -1인 것을 제거하면 이상치가 제거된 DataFrame을 얻을 수 있다.
data2['out']=y_pred_outliers
outliers=data2.loc[data2['out']== -1]
outlier_index=list(outliers.index)
train_rm_out = data2[data2['out'] != -1]
train_rm_out['Churn'] = data2["Churn"]RobustScaler
train_rs = scale_data_with_robust_scaler(train_rm_out)오버샘플링
# Separate features (X) and target variable (y)
X = train_rs.drop('Churn', axis=1)
y = train_rs['Churn']
# Apply SMOTE to balance the target variable
smote = SMOTE(random_state=70)
X_resampled, y_resampled = smote.fit_resample(X, y)
# Create a new DataFrame with the balanced data
train_rs_ov = pd.concat([X_resampled, y_resampled], axis=1)Case3 모델 학습
models = [
('RandomForestClassifier', RandomForestClassifier()),
('DecisionTreeClassifier', DecisionTreeClassifier()),
('AdaBoostClassifier', AdaBoostClassifier()),
('GradientBoostingClassifier', GradientBoostingClassifier()),
('LogisticRegression', LogisticRegression())
]
X_train, X_test, y_train, y_test = split_train_test_data(train_rs_ov, 'Churn')
perform_cross_validation(X_train, y_train, models)
train_rs_ov_df = pd.DataFrame(columns=['Model', 'Accuracy', 'Precision', 'Recall', 'F1-Score'])
train_rs_ov_df = evaluate_models_rs(models, X_train, y_train, X_test, y_test,train_rs_ov_df)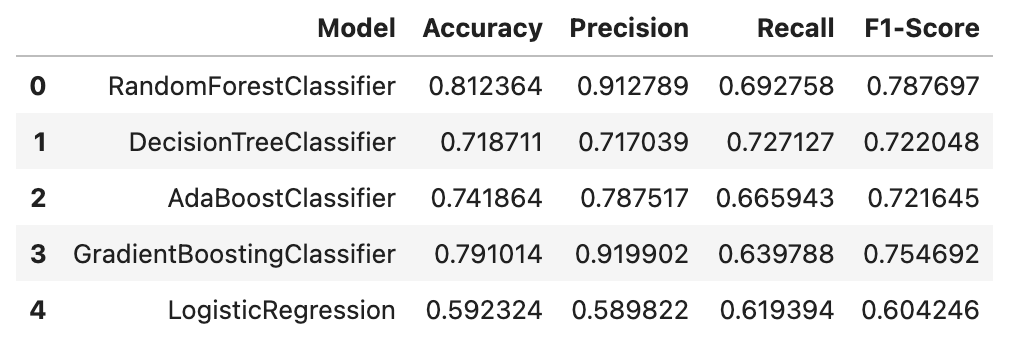

21세기 주인공