
Case2(컬럼제거)
- 카이제곱 및 t-test를 통해 컬럼 선정
데이터 전처리 과정
- 컬럼 Occupation, Customer Id, Martial Status, Prizm Code 제외
- 통계적 검정을 통해 컬럼 선별 진행 (t-test, 카이제곱 검정)
- recommendation이 drop이면 drop함
- 총 43개의 컬럼을 선정
- Rpbust Scaler를 통해 진행
- 이상치는 제거하지 않았음
- 모델을 돌려 결과 나옴
함수
# chi2test
def chi2test(X, y, alpha=0.05):
# X: DataFrame
# y: series
target = y.name
test_df = []
for index, col in X.select_dtypes(include=['object']).columns.to_series().items():
df = pd.concat([y, X[col]], axis=1)
contingency_table = df.value_counts().rename('counts').reset_index().pivot(index=target, columns=col, values='counts').fillna(0)
stat, p, dof, expected = chi2_contingency(contingency_table.values)
test_df.append([target, col, stat, p,
'Dependent (reject H0)' if p <= alpha else 'Independent (H0 holds true)','include' if p <= alpha else 'drop'])
test_df = pd.DataFrame(test_df, columns=["variable1", "variable2", "chi2-stat", "p-value", "result", "recommendation"])
return test_df
# t_test
def t_test(X, y, alpha=0.05):
target = y.name
print('t_test with alpha', alpha)
test_df = []
for index, col in X.select_dtypes(exclude=['object']).columns.to_series().items():
df = pd.concat([y, X[col]], axis=1)
ttest_df = df.set_index(target, drop=True).fillna(0)
stat, p = ttest_ind(ttest_df.loc["Yes"], ttest_df.loc["No"], equal_var=False)
test_df.append([target, col, stat, p,
'Dependent (reject H0)' if p <= alpha else 'Independent (H0 holds true)', 'include' if p <= alpha else 'drop'])
test_df = pd.DataFrame(test_df, columns=['variable1', 'variable2', 't-test', 'p-value', 'result', 'recommendation'])
return test_df
# scale_data_with_robust_scaler
def scale_data_with_robust_scaler(data):
rs = RobustScaler()
scaled_data = pd.DataFrame(rs.fit_transform(data), columns=data.columns)
return scaled_data
# apply_smote
def apply_smote(data, target_variable, random_state=70):
X = data.drop(target_variable, axis=1)
y = data[target_variable]
smote = SMOTE(random_state=random_state)
X_resampled, y_resampled = smote.fit_resample(X, y)
data_resampled = pd.concat([X_resampled, y_resampled], axis=1)
return data_resampled
# plot_bar_chart_with_percent
def plot_bar_chart_with_percent(data, column):
value_counts = data[column].value_counts()
ax = value_counts.plot(kind='bar', color=['blue', 'orange'])
def autolabel_percent(rects):
for rect in rects:
height = rect.get_height()
ax.text(rect.get_x() + rect.get_width() / 2, height,
f'{height} ({height / value_counts.sum() * 100:.1f}%)',
ha='center', va='bottom')
autolabel_percent(ax.patches)
plt.xticks(rotation=360)
plt.show()
# split_train_test_data
def split_train_test_data(data, target_variable, test_size=0.3, random_state=70):
y = data[target_variable]
X = data.drop(columns=[target_variable])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=random_state)
print('X train shape: ', X_train.shape)
print('Y train shape: ', y_train.shape)
print('X test shape: ', X_test.shape)
print('Y test shape: ', y_test.shape)
return X_train, X_test, y_train, y_test
# evaluate_models_rs
def evaluate_models_rs(models, X_train, y_train, X_test, y_test, df):
for name, model in models:
kfold = KFold(n_splits=5, random_state=70, shuffle=True)
model.fit(X_train, y_train)
pred = model.predict(X_test)
print(name)
print(classification_report(y_test, pred, target_names=['No', 'Yes']))
accuracy = accuracy_score(y_test, pred)
precision = precision_score(y_test, pred, pos_label=1.0)
recall = recall_score(y_test, pred, pos_label=1.0)
f1 = f1_score(y_test, pred, pos_label=1.0)
model_results = pd.DataFrame({'Model': [name],
'Accuracy': [accuracy],
'Precision': [precision],
'Recall': [recall],
'F1-Score': [f1]})
df = pd.concat([df, model_results], ignore_index=True)
return df
# 전처리 된 데이터 셋
train = pd.read_csv('./cell2celltrain.csv')
columns_to_drop = ['CustomerID', 'MaritalStatus', 'Occupation', 'PrizmCode']
train = train.drop(columns_to_drop, axis=1)
train_null = train.copy()
null_rows_selector = train_null.isnull().any(axis=1)
null_row_count = train_null[null_rows_selector].shape[0]
df_null = train_null.isnull().groupby(train_null.Churn).sum().transpose()
df_null['total'] = train_null.isnull().sum()
df_null['percent'] = (df_null['total'] / len(train_null)) * 100
df_null = df_null[df_null.total != 0]
pd.concat([train_null.Churn.value_counts(normalize=True).rename("Overall"), train_null[null_rows_selector].Churn.value_counts(normalize=True).rename("within_null_rows")], axis=1)
contingency_table = pd.concat([train_null.Churn.value_counts().rename("Overall"), train_null[null_rows_selector].Churn.value_counts()
.rename("within_null_rows")], axis=1).transpose()
stat, p, dof, expected = chi2_contingency(contingency_table.values)
# p-value 확인
alpha = 0.05 # 유의값 수준
print("p value is " + str(p))
print("Dependent (reject H0)") if p <= alpha else print("Independent (H0 holds true)")
chi2test(train_null.drop('Churn', axis=1), train_null['Churn'])
t_test(train_null.drop('Churn', axis=1), train_null['Churn'])include recommendation이 된 컬럼만 선정하여 train_null_1 재정의
columns_to_drop = ['TruckOwner', 'RVOwner', 'OptOutMailings', 'NonUSTravel', 'OwnsComputer', 'HasCreditCard',
'NewCellphoneUser', 'NotNewCellphoneUser', 'OwnsMotorcycle', 'BlockedCalls',
'CallForwardingCalls']
train = train.drop(columns_to_drop, axis=1)LabelEncoder
le = LabelEncoder()
object_cols = train.select_dtypes(include=['object']).columns
train[object_cols] = train[object_cols].apply(le.fit_transform)
train.reset_index(drop=True, inplace=True)RobustScaler
scale_data_with_robust_scaler(train)train.isnull().sum().sort_values(ascending=False)
train_not_null = train.copy()
train_not_null.dropna(inplace=True)
train_not_null.isnull().sum().sort_values(ascending=False)models
models = [
('RandomForestClassifier', RandomForestClassifier()),
('DecisionTreeClassifier', DecisionTreeClassifier()),
('AdaBoostClassifier', AdaBoostClassifier()),
('GradientBoostingClassifier', GradientBoostingClassifier()),
('LogisticRegression', LogisticRegression())
]X_train, X_test, y_train, y_test = split_train_test_data(train_rs, 'Churn')
train_rs_df = pd.DataFrame(columns=['Model', 'Accuracy', 'Precision', 'Recall', 'F1-Score'])
train_rs_df = evaluate_models_rs(models, X_train, y_train, X_test, y_test,train_rs_df)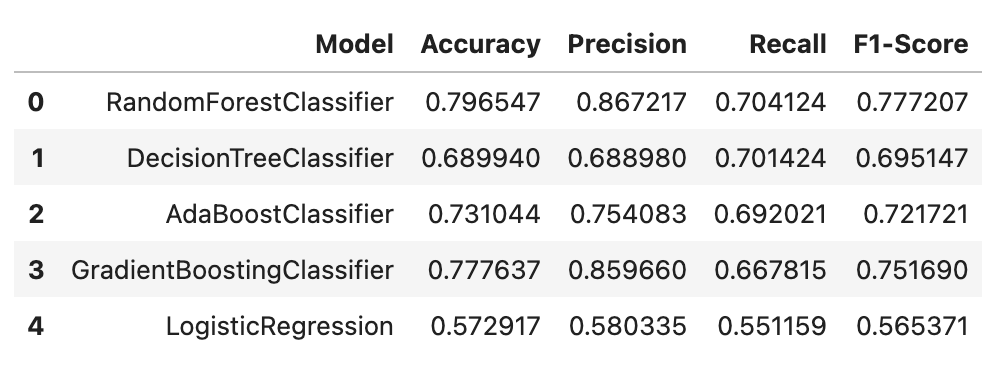

21세기 주인공