
지도학습
- 분류(Classification), 회귀(Regression)
비지도학습
- 군집, 차원 축소

비용함수(Cost Function)
-원래의 값과 가장 오차가 작은 가설함수 를 도출하기 위해 사용되는 함수

선형 회귀
import pandas as pd
data = {'x':[1,2,3,4,5], 'y':[1,3,4,6,5]}
df = pd.DataFrame(data)import statsmodels.formula.api as smf
lm_model = smf.ols(formula="y ~ x", data=df).fit()
lm_model.params # Intercept=0,5, x=1.1# 시각화
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
sns.lmplot(x='x', y='y', data=df);
plt.xlim([0,5])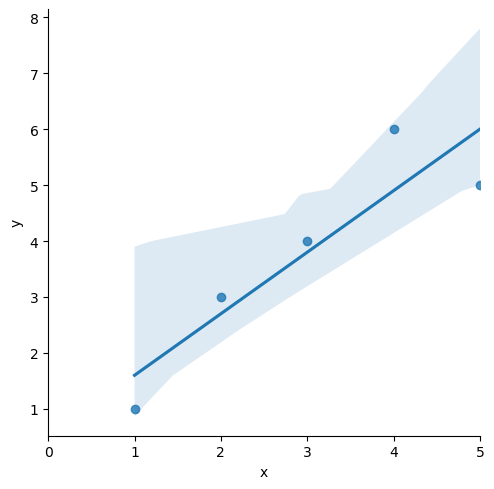
# 잔차
resid = lm_model.resid
#-0.6, 0.3, 0.2, 1.1, -1.0
# 결정계수(R-Squared)
lm_model.rsquared # 0.8175675675675677# 잔차 시각화
sns.distplot(resid, color='black')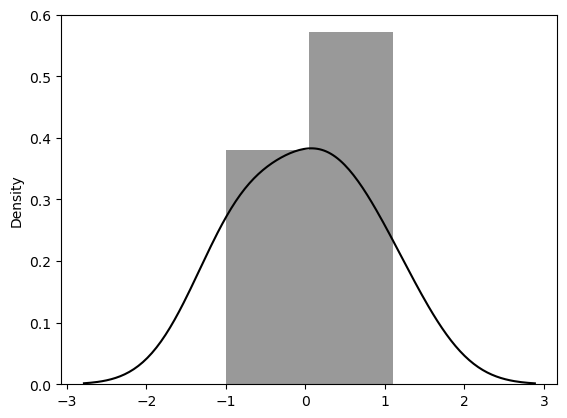
통계적 회귀
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
data_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/ecommerce.csv'
data = pd.read_csv(data_url)
data.drop(['Email','Address','Avatar'], axis=1, inplace=True)plt.figure(figsize=(10,5))
sns.boxplot(data=data.iloc[:, :-1]);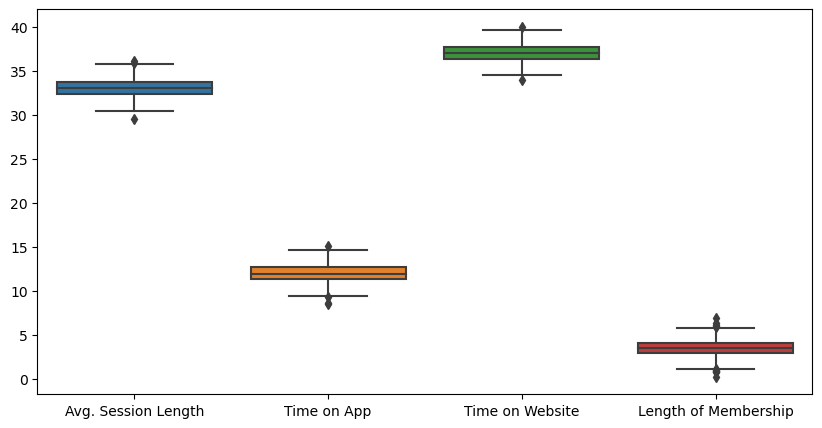
plt.figure(figsize=(5,4))
sns.boxplot(data=data['Yearly Amount Spent']);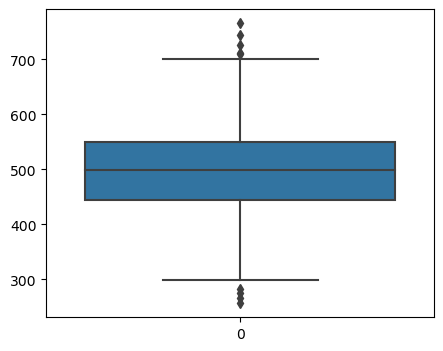
sns.pairplot(data=data);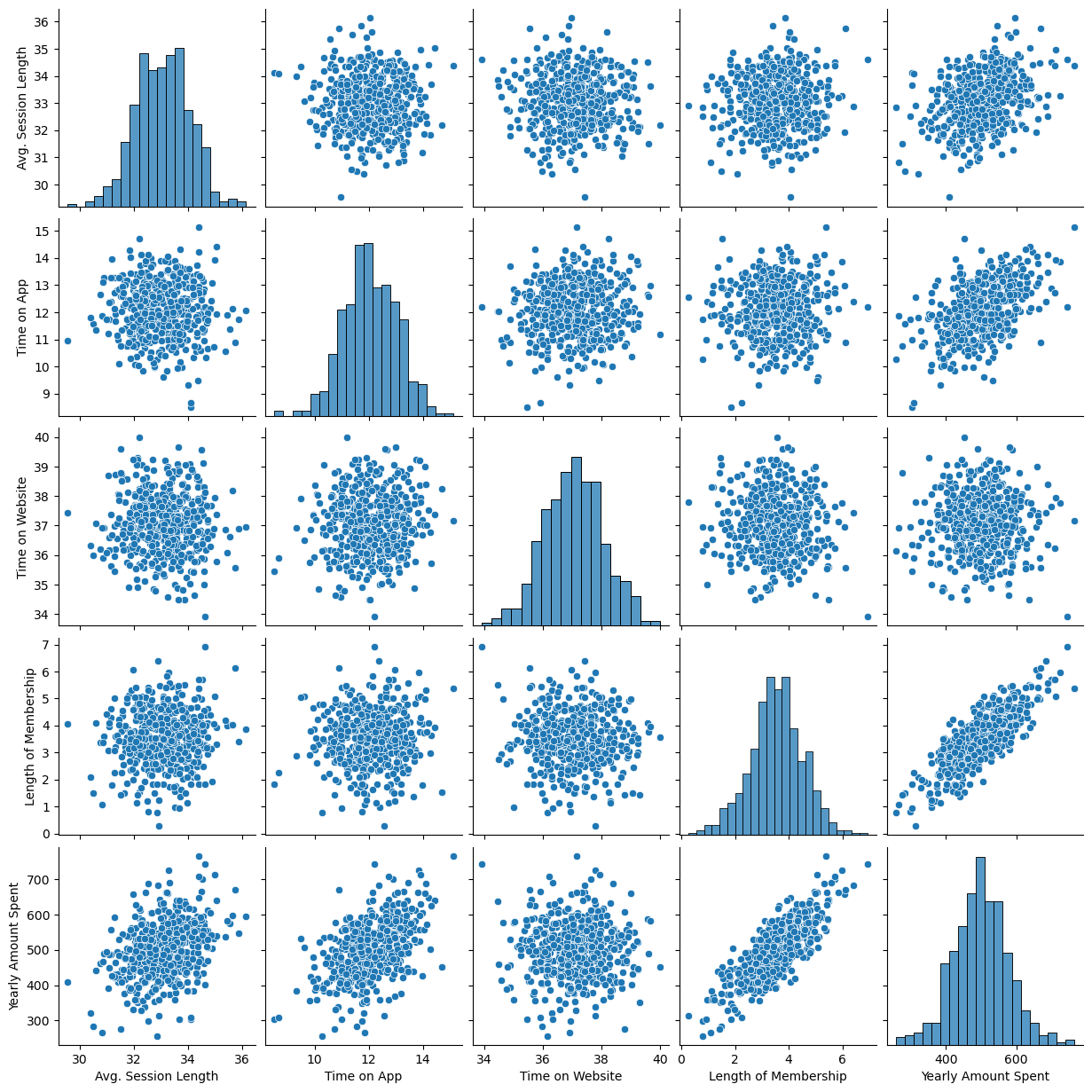
plt.figure(figsize=(5,4))
sns.lmplot(x='Length of Membership', y='Yearly Amount Spent', data=data);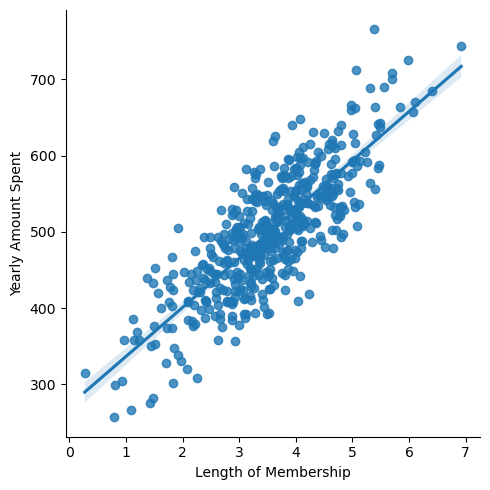
# 통계적 회귀('Length of Membership', 'Yearly Amount Spent' )
import statsmodels.api as sm
X = data['Length of Membership']
y = data['Yearly Amount Spent']
lm = sm.OLS(y, X).fit()
lm.summary()
# 회귀모델 그리기
# 상수항이 없어서 잘 안 맞음
pred = lm.predict(X)
plt.figure(figsize=(6,5))
sns.scatterplot(x=X, y=y)
plt.plot(X, pred, 'r', ls='dashed', lw=2);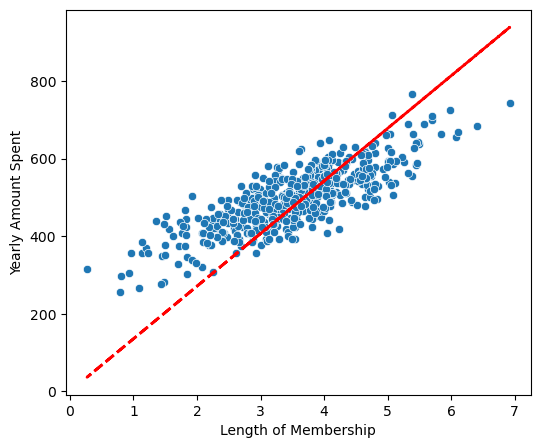
# 상수항 문제 해결하여 다시 회귀모델 그리기
X = np.c_[X, [1]*len(X)]
pred = lm.predict(X)
plt.figure(figsize=(6,5))
sns.scatterplot(x=X[:,0], y=y)
plt.plot(X[:,0], pred, 'r', ls='dashed', lw=2);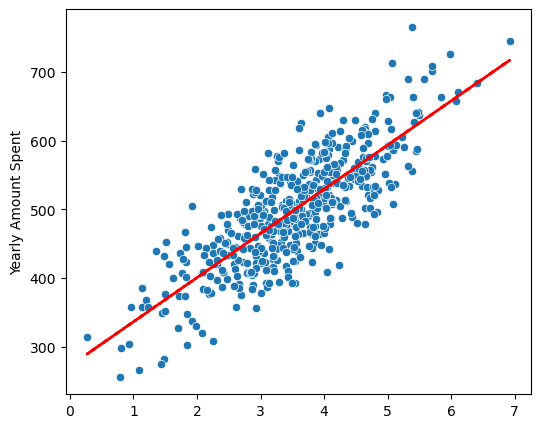
# 학습 데이터
from sklearn.model_selection import train_test_split
X = data.drop('Yearly Amount Spent', axis=1)
y = data['Yearly Amount Spent']
X_train, X_test, y_train, y_test = train_test_split(X, y , test_size=0.2, random_state=13)# 학습데이터 회귀
lm = sm.OLS(y_train, X_train).fit()
lm.summary()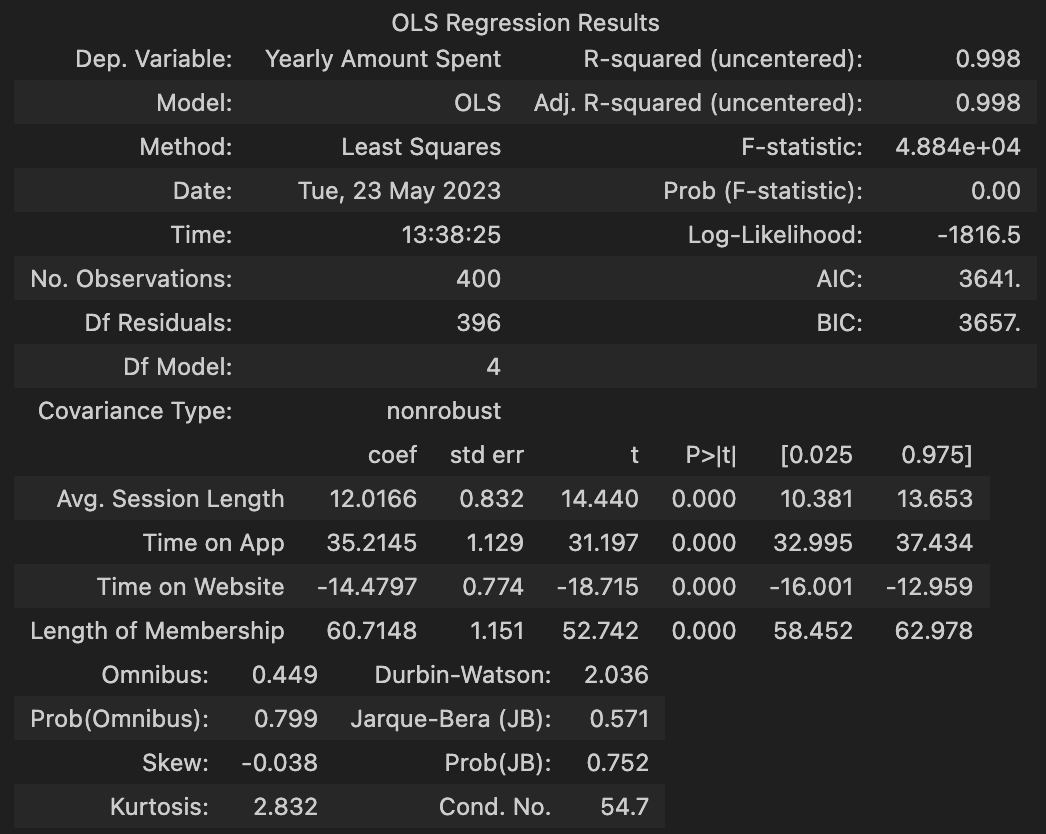
# 테스트 데이터
pred = lm.predict(X)
plt.figure(figsize=(6,5))
sns.scatterplot(x=y_test, y=pred)
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], 'r', ls='dashed', lw=2);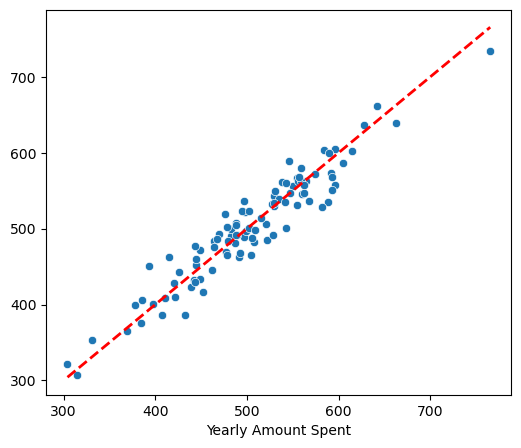
Boston 집값 예측
import pandas as pd
import numpy as np
data_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/boston.csv'
boston = pd.read_csv(data_url)
boston.rename(columns={'MEDV' : 'PRICE'}, inplace=True)import plotly.express as px
# price별 가구 수
fig = px.histogram(boston, x='PRICE')
fig.show()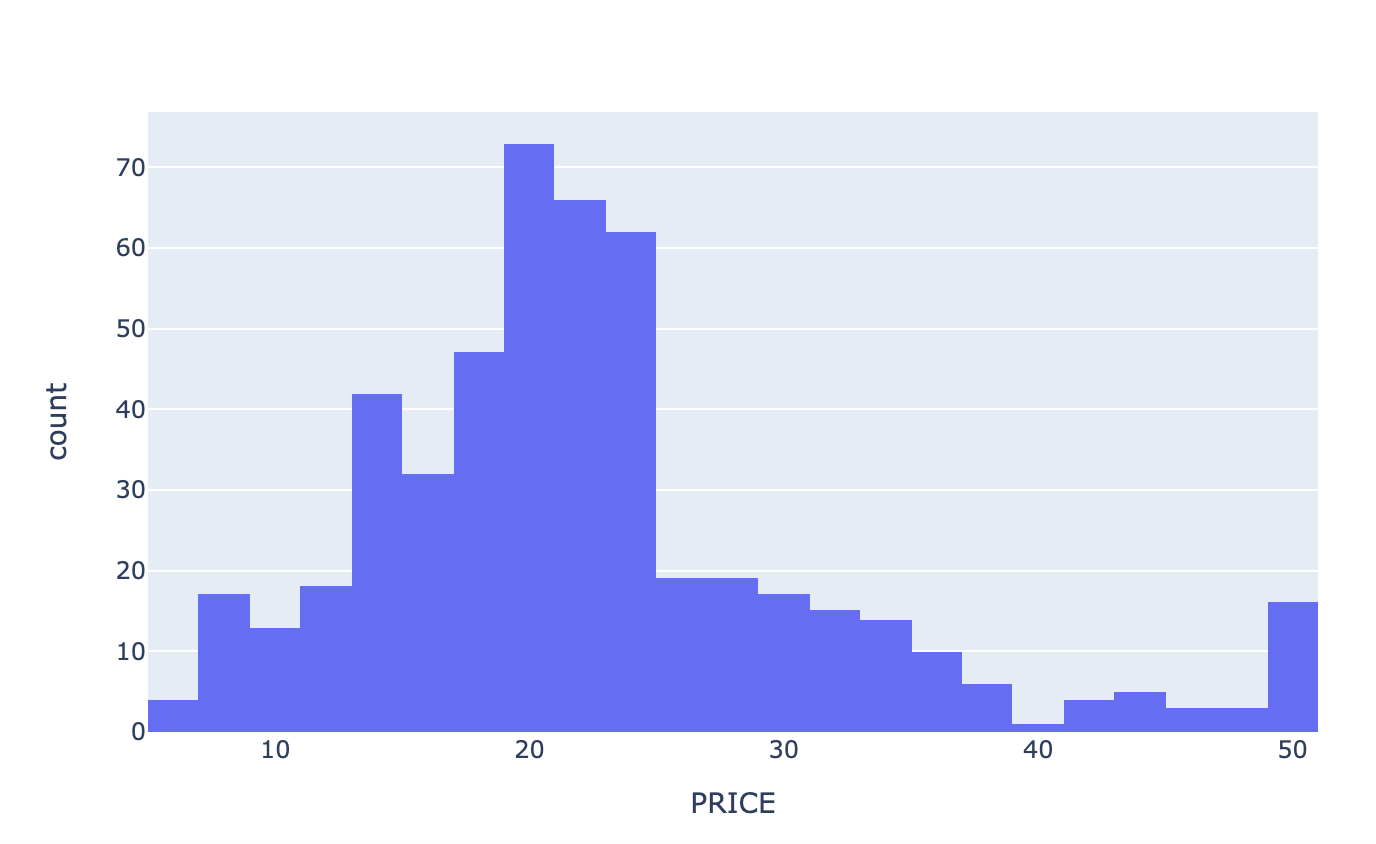
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
# 상관관계 확인
corr_mat = boston.corr().round(1)
sns.heatmap(data=corr_mat, annot=True, cmap='bwr');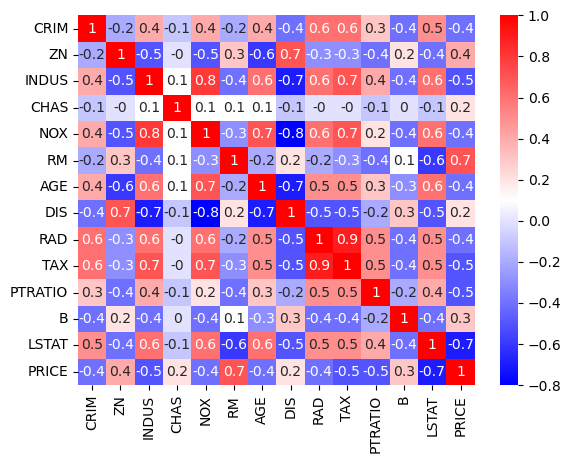
# RM(방의 개수), LSTAT(저소득층 인구 수)
sns.set_style('darkgrid')
f, ax = plt.subplots(1,2, figsize=(10,5))
sns.regplot(x='RM', y='PRICE', data=boston, ax=ax[0])
sns.regplot(x='LSTAT', y='PRICE', data=boston, ax=ax[1])
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
X = boston.drop('PRICE', axis=1)
y = boston['PRICE']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
reg = LinearRegression()
reg.fit(X_train, y_train)
pred_tr = reg.predict(X_train)
pred_test = reg.predict(X_test)
# 모델평가
rmse_tr = (np.sqrt(mean_squared_error(y_train, pred_tr)))
rmse_test = (np.sqrt(mean_squared_error(y_test, pred_test)))
print(rmse_tr) # 4.642806069019824
print(rmse_test) # 4.931352584146709# 성능 확인
plt.scatter(y_test, pred_test)
plt.xlabel('Actual House Prices ($1000)')
plt.ylabel('Predicted Prices')
plt.title('Real vs Predicted')
plt.plot([0,50], [0,50], 'r')
plt.show()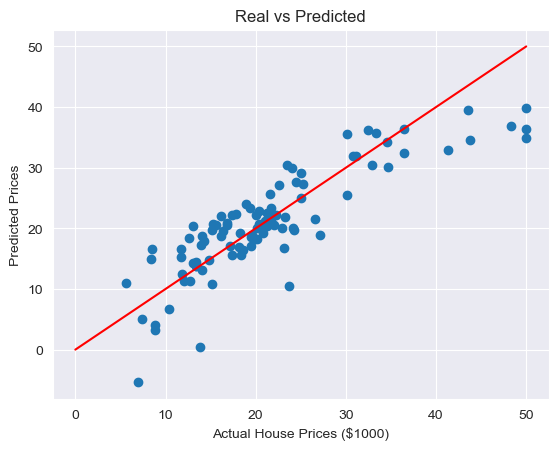

21세기 주인공