제로베이스 데이터취업스쿨 DAY52 머신러닝5~8
GridSearchCVMinMaxScalerRobustScalerStandardScalerkfoldlabelencoderpipeline교차검증데이터전처리데이터취업스쿨모델평가분류모델이진분류모델제로베이스회귀모델
제로베이스 교육
목록 보기
41/54

- 결정나무에서는 이런 전처리는 의미를 가지지 않는다.
- 주로 Cost Function을 최적화할 때 유효화할 때가 있다.



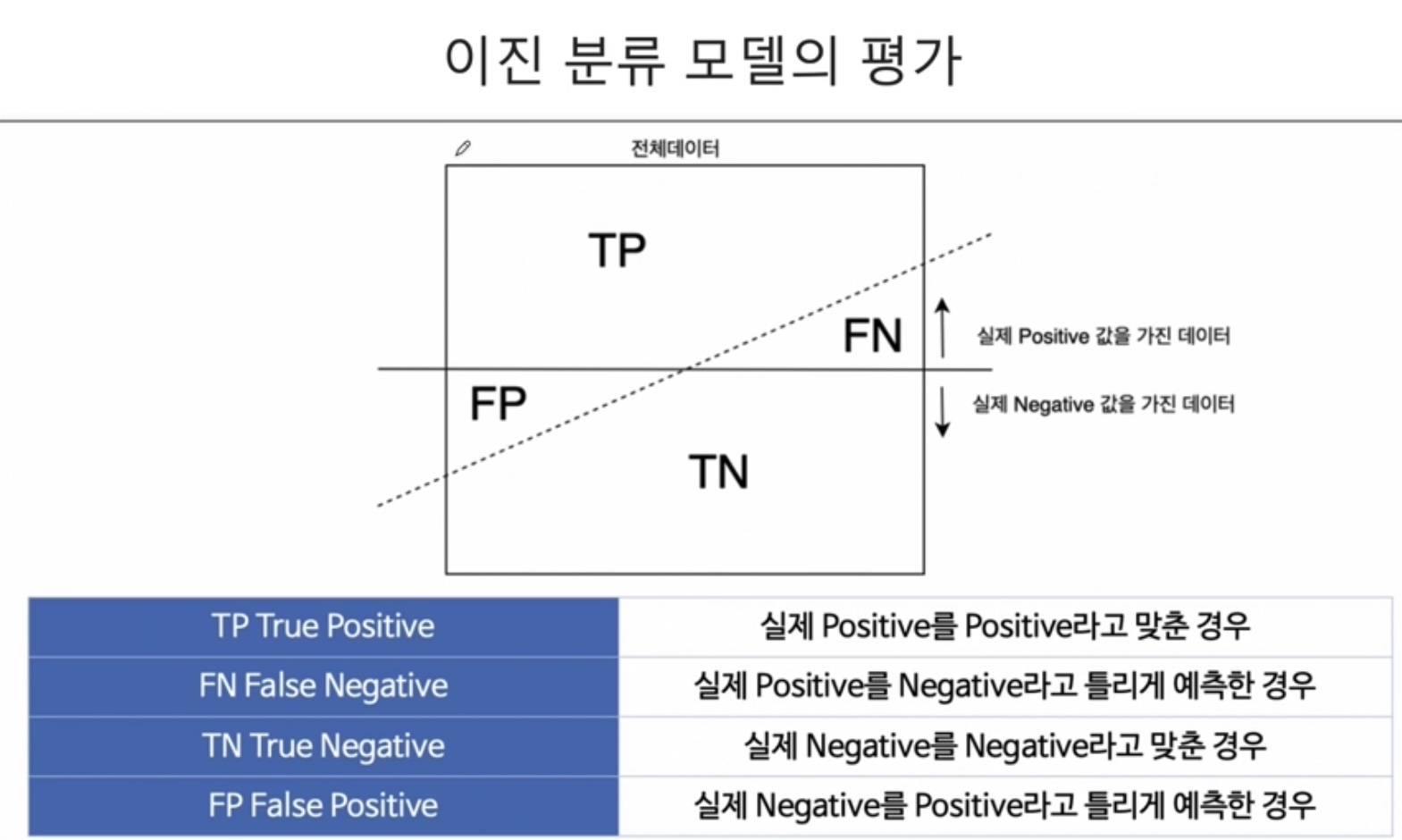
- Recall : 놓치면 안되는 데이터. ex) 암환자

와인 데이터 분석
데이터 전처리 전
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
red_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-red.csv'
white_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-white.csv'
red_wine = pd.read_csv(red_url, sep=';')
white_wine = pd.read_csv(white_url, sep=';')
red_wine['color']=1
white_wine['color']=0
wine = pd.concat([red_wine, white_wine])import plotly.express as px
fig = px.histogram(wine, x='quality')
fig.show()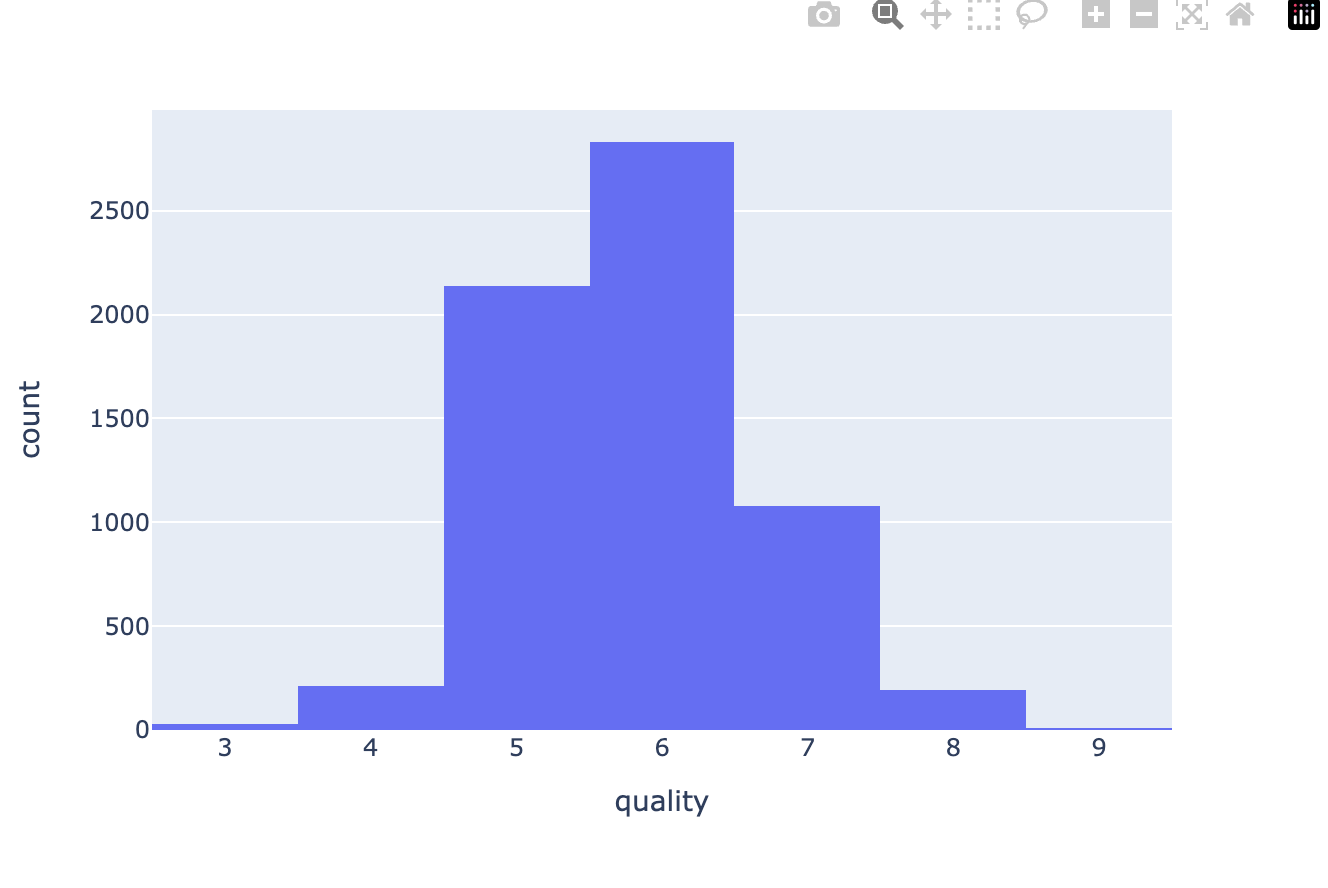
fig = px.histogram(wine, x='quality', color='color')
fig.show()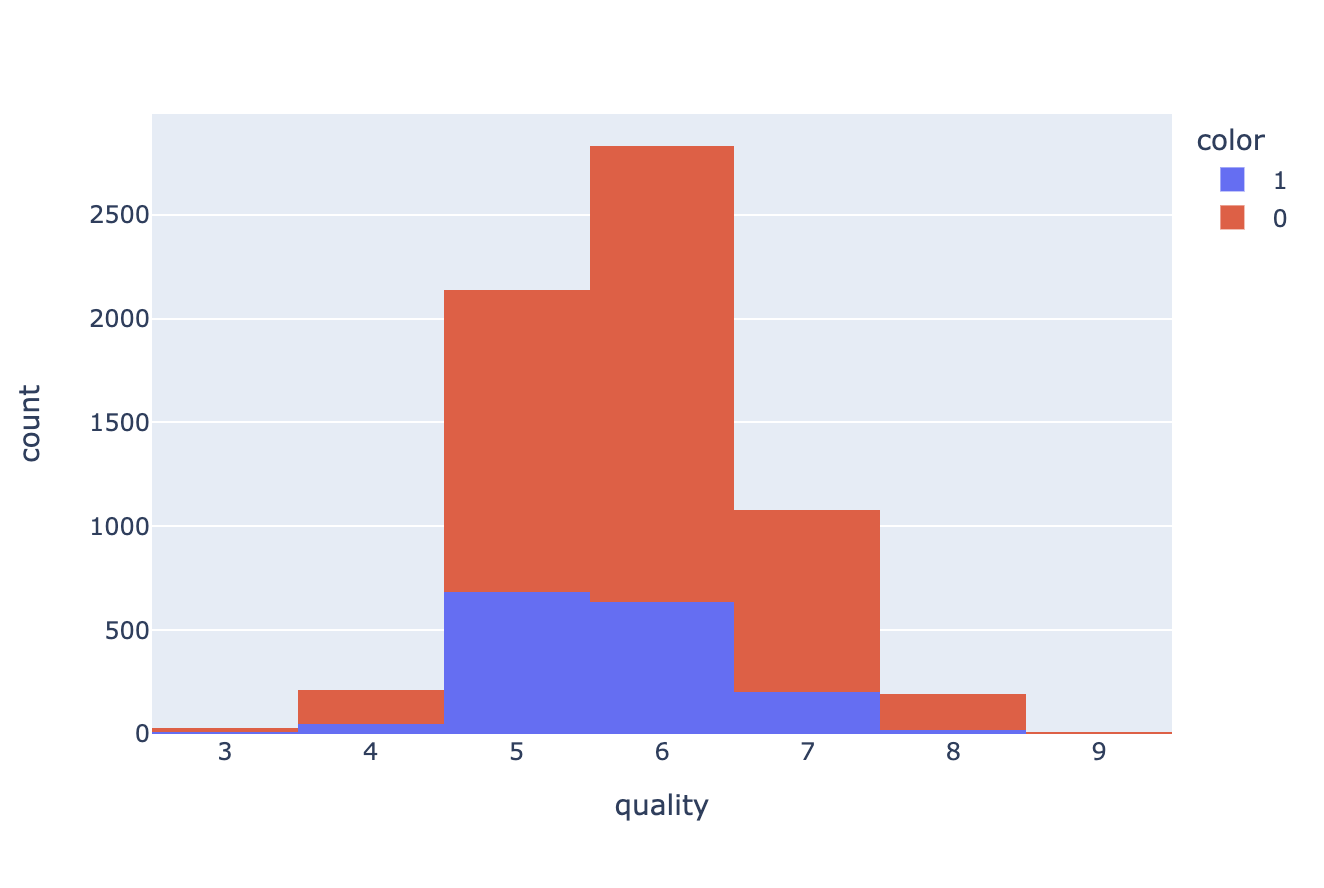
# 데이터 분리
from sklearn.model_selection import train_test_split
X = wine.drop(['color'], axis=1)
y = wine['color']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
# 훈련데이터 와인 색 0,1 비율 확인
np.unique(y_train, return_counts=True)# 학습
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train, y_train)
# 예측
y_pred_tr = wine_tree.predict(X_train)
y_pred_test = wine_tree.predict(X_test)
# 정확도
print(accuracy_score(y_train, y_pred_tr)) # 0.9553588608812776
print(accuracy_score(y_test, y_pred_test)) # 0.9569230769230769데이터 전처리
import plotly.graph_objects as go
# 데이터 전처리 전
fig = go.Figure()
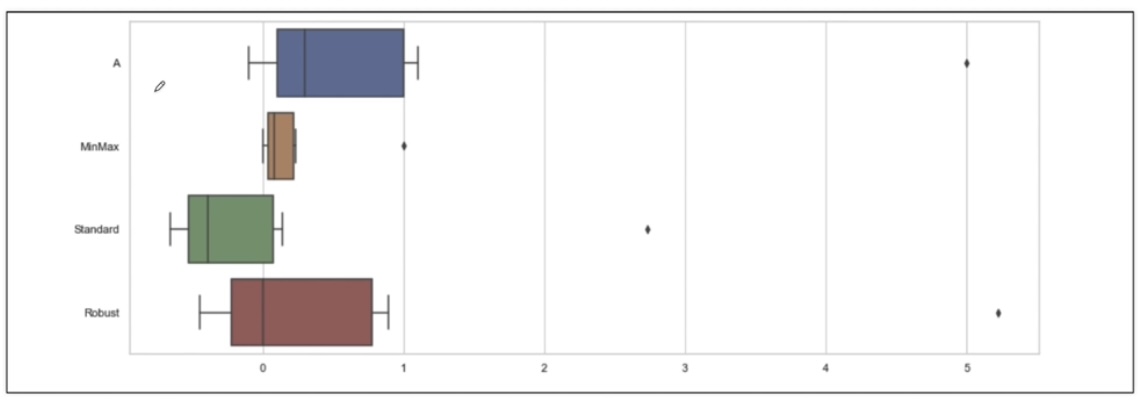
fig.add_trace(go.Box(y=X['fixed acidity'], name='fixed acidity'))
fig.add_trace(go.Box(y=X['chlorides'], name='chlorides'))
fig.add_trace(go.Box(y=X['quality'], name='quality'))
fig.show()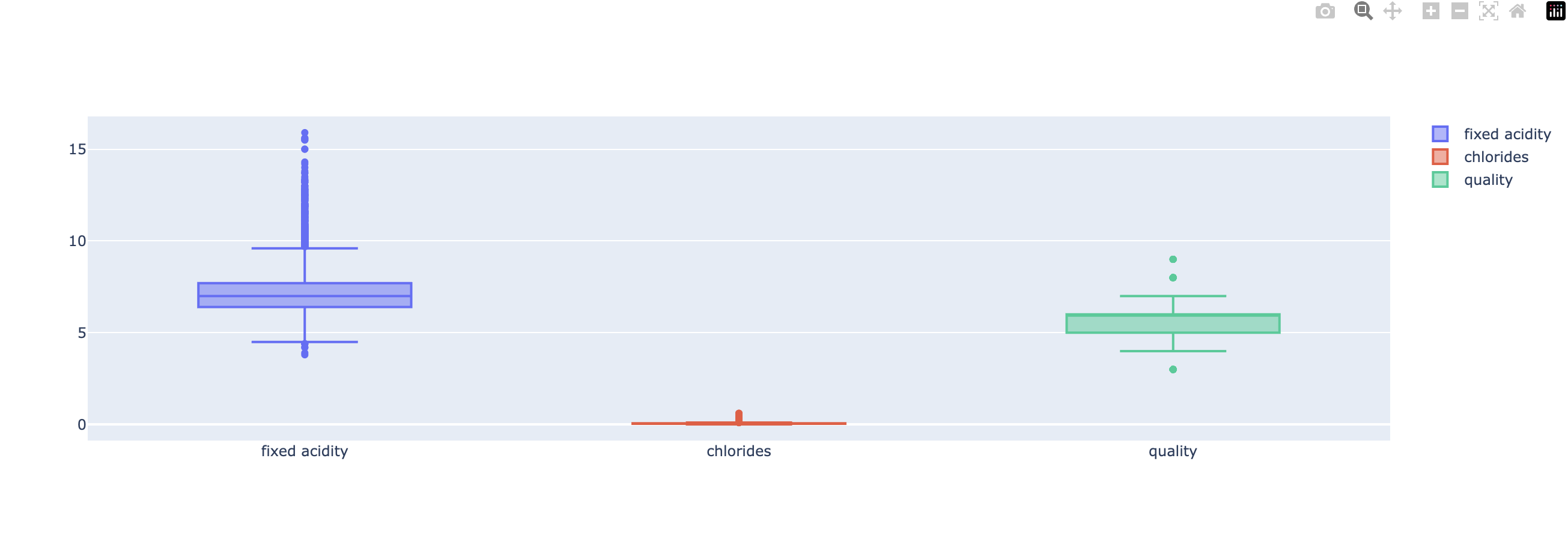
# MinMaxScaler, StandardScaler
from sklearn.preprocessing import MinMaxScaler, StandardScaler
mms = MinMaxScaler()
ss = StandardScaler()
X_mms = mms.fit_transform(X)
X_ss = ss.fit_transform(X)
X_mms_pd = pd.DataFrame(X_mms, columns=X.columns)
X_ss_pd = pd.DataFrame(X_ss, columns=X.columns)# MinMaxScaler
fig = go.Figure()
fig.add_trace(go.Box(y=X_mms_pd['fixed acidity'], name='fixed acidity'))
fig.add_trace(go.Box(y=X_mms_pd['chlorides'], name='chlorides'))
fig.add_trace(go.Box(y=X_mms_pd['quality'], name='quality'))
fig.show()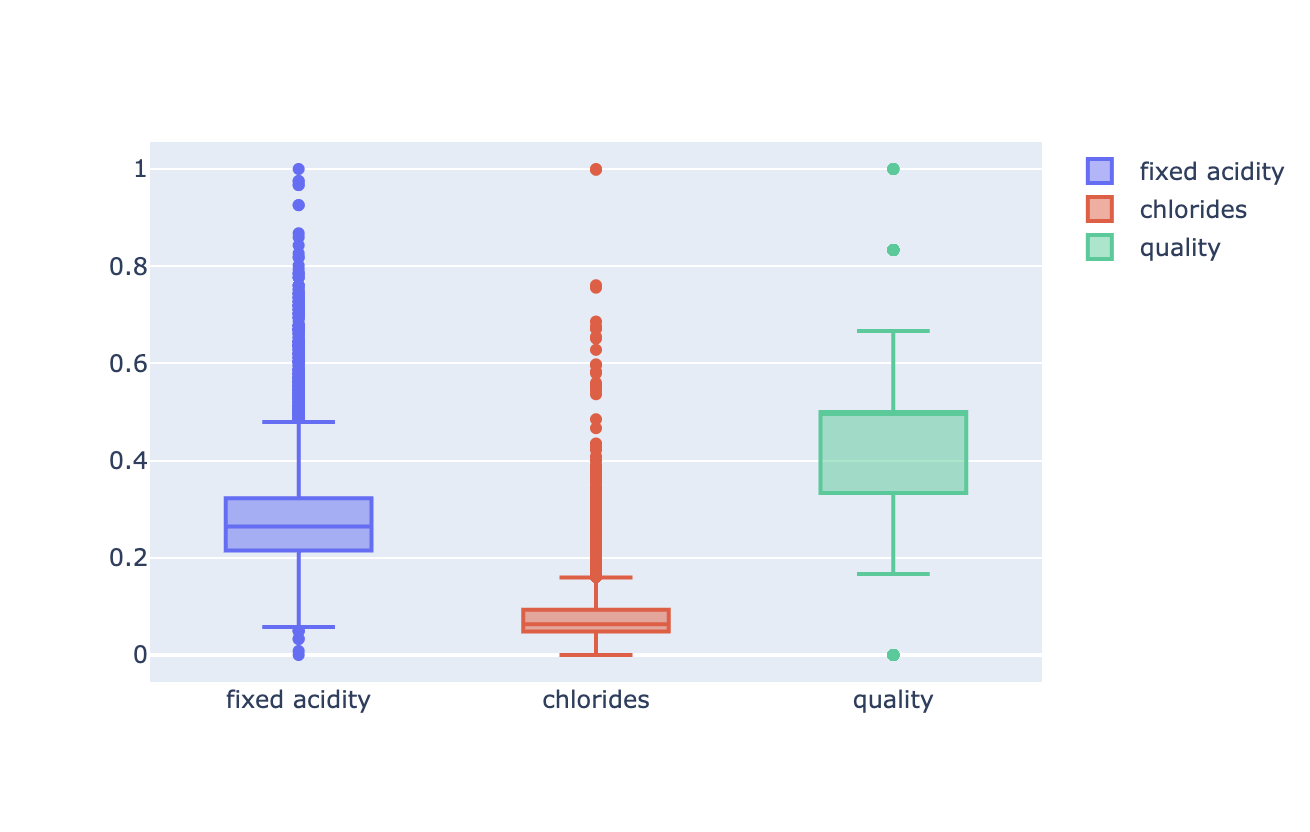
# StandardScaler
fig = go.Figure()
fig.add_trace(go.Box(y=X_ss_pd['fixed acidity'], name='fixed acidity'))
fig.add_trace(go.Box(y=X_ss_pd['chlorides'], name='chlorides'))
fig.add_trace(go.Box(y=X_ss_pd['quality'], name='quality'))
fig.show()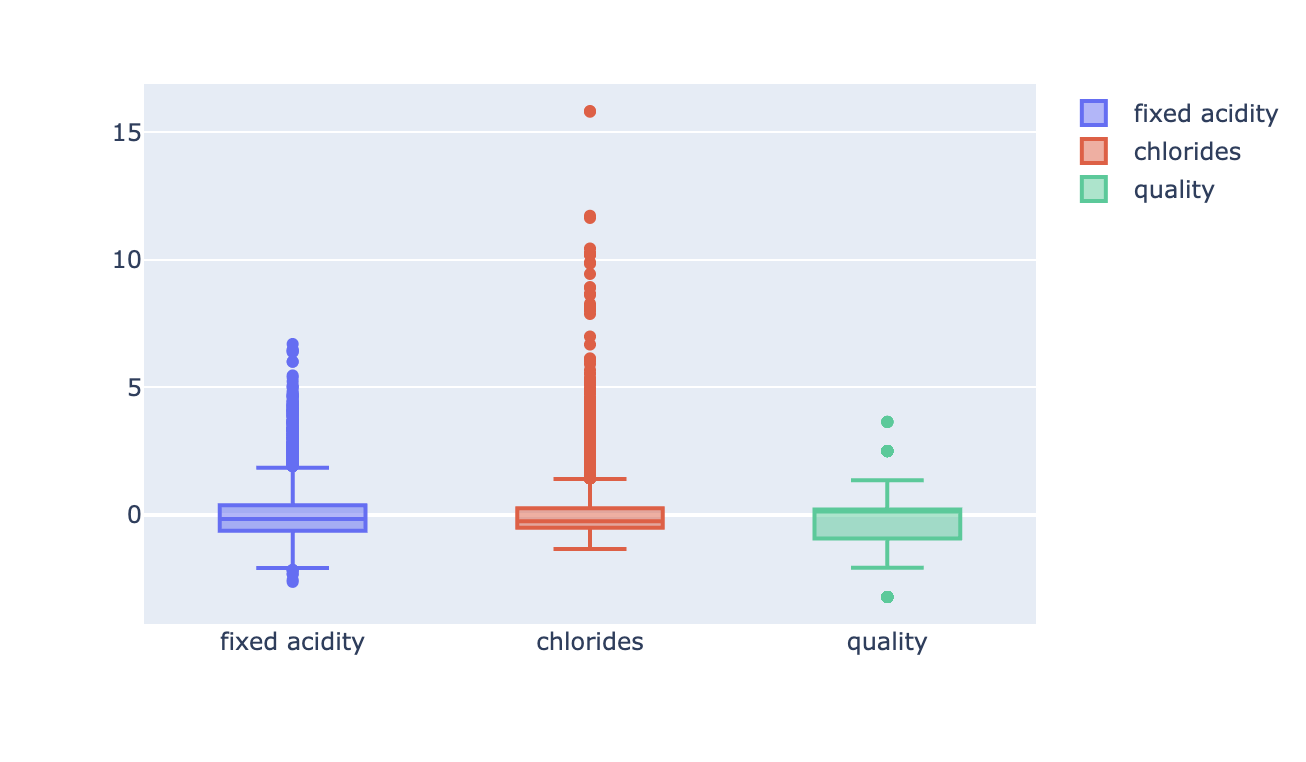
학습 & 테스트
# MinMaxScaler
X_train, X_test, y_train, y_test = train_test_split(X_mms_pd, y, test_size=0.2, random_state=13)
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train, y_train)
y_pred_tr = wine_tree.predict(X_train)
y_pred_test = wine_tree.predict(X_test)
print(accuracy_score(y_train, y_pred_tr)) # 0.9553588608812776
print(accuracy_score(y_test, y_pred_test)) # 0.9569230769230769# StandardScaler
X_train, X_test, y_train, y_test = train_test_split(X_ss_pd, y, test_size=0.2, random_state=13)
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train, y_train)
y_pred_tr = wine_tree.predict(X_train)
y_pred_test = wine_tree.predict(X_test)
print(accuracy_score(y_train, y_pred_tr)) # 0.9553588608812776
print(accuracy_score(y_test, y_pred_test)) # 0.9569230769230769이진분류
wine['taste'] = [1. if grade>5 else 0. for grade in wine['quality']]
X = wine.drop(['taste', 'quality'], axis=1)
y = wine['taste']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train, y_train)
y_pred_tr = wine_tree.predict(X_train)
y_pred_test = wine_tree.predict(X_test)
# 정확도
print(accuracy_score(y_train, y_pred_tr)) # 0.7294593034442948
print(accuracy_score(y_test, y_pred_test)) # 0.7161538461538461# plot_tree
from sklearn.tree import plot_tree
plt.figure(figsize=(10,8))
plot_tree(wine_tree, feature_names=X.columns, rounded=True, filled=True);
plt.show()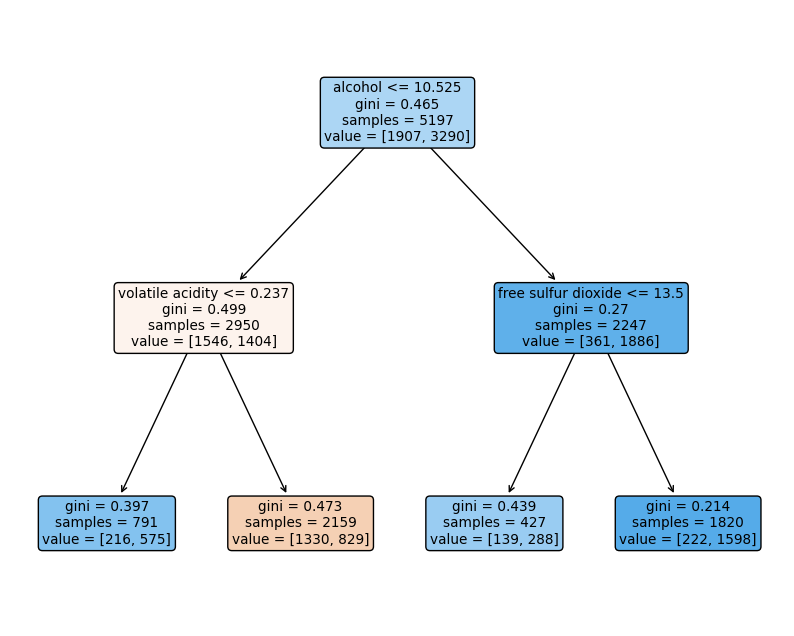
Pipeline
from sklearn.pipeline import Pipeline
X = wine.drop(['color'], axis=1)
y = wine['color']
estimators = [('scaler', StandardScaler()),
('clf', DecisionTreeClassifier())]
pipe = Pipeline(estimators)
pipe.set_params(clf__max_depth=2)
pipe.set_params(clf__random_state=13)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13, stratify=y)
pipe.fit(X_train, y_train)
y_pred_tr = pipe.predict(X_train)
y_pred_test = pipe.predict(X_test)
print(accuracy_score(y_train, y_pred_tr)) # 0.9657494708485664
print(accuracy_score(y_test, y_pred_test)) # 0.9576923076923077교차검증
# KFold
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
X = wine.drop(['color'], axis=1)
y = wine['color']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13, stratify=y)
kfold = KFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13)
cv_accuracy = []
for train_idx, test_idx in kfold.split(X):
X_train, X_test = X.iloc[train_idx], X.iloc[test_idx]
y_train, y_test = y.iloc[train_idx], y.iloc[test_idx]
wine_tree_cv.fit(X_train, y_train)
pred = wine_tree_cv.predict(X_test)
cv_accuracy.append(accuracy_score(y_test, pred))
np.mean(cv_accuracy) # 0.9142953751406407# StratifiedKFold
from sklearn.model_selection import StratifiedKFold
skfold = StratifiedKFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13)
cv_accuracy = []
for train_idx, test_idx in skfold.split(X, y):
X_train, X_test = X.iloc[train_idx], X.iloc[test_idx]
y_train, y_test = y.iloc[train_idx], y.iloc[test_idx]
wine_tree_cv.fit(X_train, y_train)
pred = wine_tree_cv.predict(X_test)
cv_accuracy.append(accuracy_score(y_test, pred))
np.mean(cv_accuracy) # 0.9604440101853496# cross validation 간편히
from sklearn.model_selection import cross_val_score
skfold = StratifiedKFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13)
cross_val_score(wine_tree_cv, X, y, scoring=None, cv=skfold)# train score 같이 보기
from sklearn.model_selection import cross_validate
cross_validate(wine_tree_cv, X, y, scoring=None, cv=skfold, return_train_score=True)GridSearchCV
from sklearn.model_selection import GridSearchCV
X = wine.drop(['color'], axis=1)
y = wine['color']
params = {'max_depth':[2,4,7,10]}
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
gridsearch = GridSearchCV(estimator=wine_tree, param_grid=params, cv=5)
gridsearch.fit(X, y)# 결과 확인
import pprint
pp = pprint.PrettyPrinter(indent=4)
pp.pprint(gridsearch.cv_results_)
gridsearch.best_estimator_
gridsearch.best_score_
gridsearch.best_params_# GridSearchCV, Pipeline
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
X = wine.drop(['color'], axis=1)
y = wine['color']
estimators = [('scaler', StandardScaler()),
('clf', DecisionTreeClassifier())]
pipe = Pipeline(estimators)
param_grid = [{'clf__max_depth':[2,4,7,10]}]
gridsearch = GridSearchCV(estimator=pipe, param_grid=param_grid, cv=5)
gridsearch.fit(X, y)
print(gridsearch.best_estimator_)# 데이터프레임으로 정리
score_df = pd.DataFrame(gridsearch.cv_results_)
score_df[['params', 'rank_test_score','mean_test_score','std_test_score']]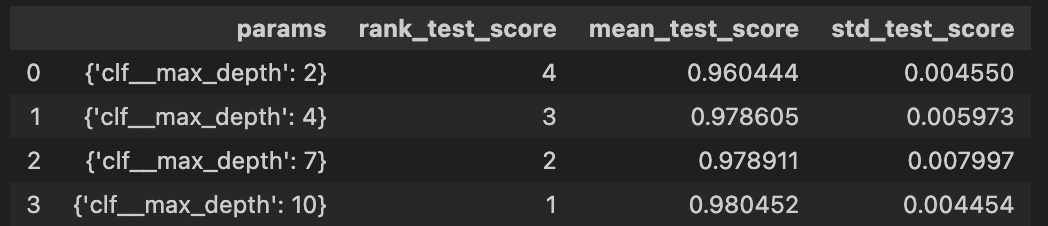
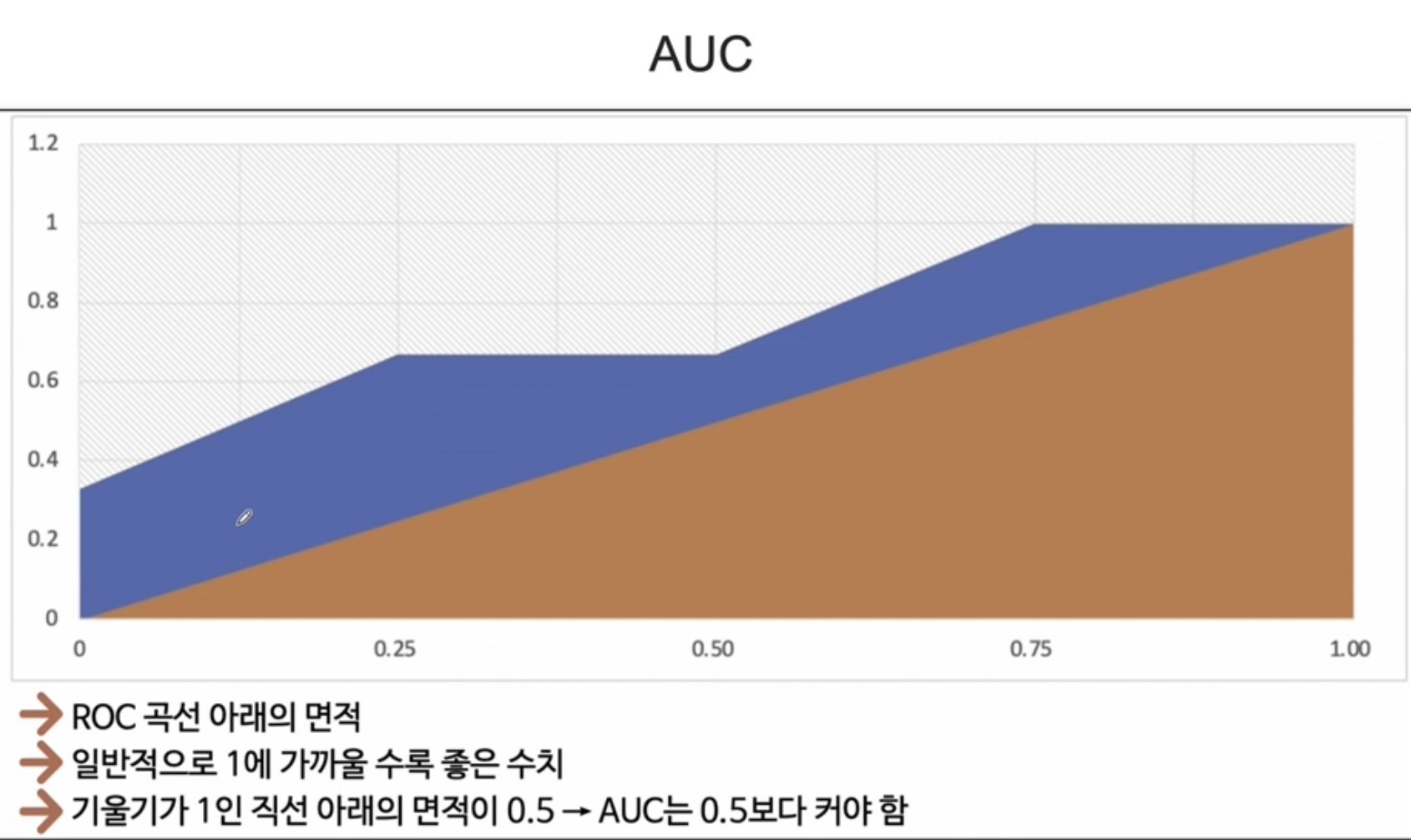
ROC 커브
# 수치 확인
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score, roc_curve
print('accuracy : ', accuracy_score(y_test, y_pred_test))
print('precision : ', precision_score(y_test, y_pred_test))
print('recall : ', recall_score(y_test, y_pred_test))
print('f1 : ', f1_score(y_test, y_pred_test))
print('auc : ', roc_auc_score(y_test, y_pred_test))
# accuracy : 0.9576923076923077
# precision : 0.9206349206349206
# recall : 0.90625
# f1 : 0.9133858267716536
# auc : 0.9403698979591837# roc 커브 그리기
import matplotlib.pyplot as plt
%matplotlib inline
pred_proba = wine_tree.predict_proba(X_test)[:, 1]
fpr, tpr, thresholds = roc_curve(y_test, pred_proba)
plt.figure(figsize=(10,8))
plt.plot([0,1],[0,1])
plt.plot(fpr, tpr)
plt.title('ROC Curve')
plt.grid()
plt.show()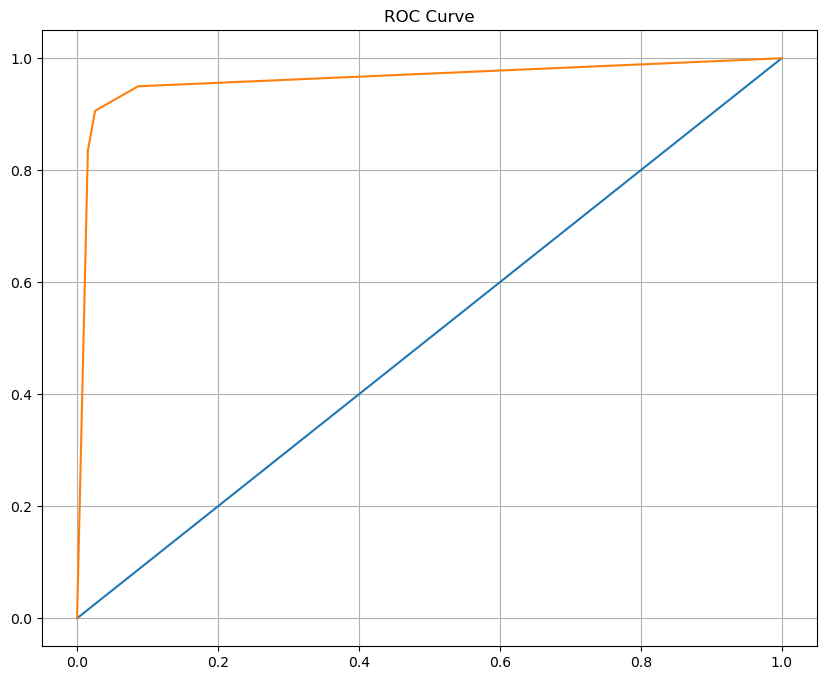

21세기 주인공