
# 1. 전처리
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import RobustScaler
from sklearn.preprocessing import OneHotEncoder
from sklearn.preprocessing import Binarizer
from sklearn.preprocessing import scale
# 2. 데이터 분리, 교차검증, GridSearchCV
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import cross_validate
from sklearn.model_selection import GridSearchCV
# 3. pipeline
from sklearn.pipeline import Pipeline
# 4. 분류
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import plot_tree
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import GradientBoostingClassifier
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_samples
from sklearn.metrics import silhouette_score
from yellowbrick.cluster import silhouette_visualizer
from matplotlib.image import imread
# 5. 값 예측
from sklearn.linear_model import LinearRegression
# 6. 평가
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
from sklearn.metrics import roc_auc_score
from sklearn.metrics import roc_curve
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import mean_squared_error
# 7. 통계적 회귀
import statsmodels.api as sm
# 8. 오버샘플링
from imblearn.over_sampling import SMOTE
# 9. 주성분분석
from sklearn.decomposition import PCA텍스트
# 1. 자연어 처리
from konlpy.tag import Kkma
from konlpy.tag import Hannanum
from konlpy.tag import Okt
# 2. 워드클라우드
from wordcloud import WordCloud
from wordcloud import STOPWORDS
from PIL import Image
# 3. 감성분석
import nltk
from nltk.tokenize import word_tokenize
# 4. 유사도
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
import scipy as sp
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.metrics.pairwise import linear_kernel

-
key 가져올 때(딕셔너리)
-iris['target_names']
-iris.target_names -
dict(zip)
list1 = ['a','b','c']
list2 = [1,2,3]
# 합치기
dict(zip(list1, list2)) # {'a': 1, 'b': 2, 'c': 3}
pairs = [pair for pair in zip(list1, list2)] # [('a', 1), ('b', 2), ('c', 3)]
# 해체
x, y = zip(*pairs)
print(list(x)) # ['a', 'b', 'c']
print(list(y)) # [1, 2, 3]iris 데이터 분석
1. 데이터 가져오기
from sklearn.datasets import load_iris
import pandas as pd
iris = load_iris()
#iris.keys()
#print(iris['DESCR'])
iris_pd = pd.DataFrame(iris.data, columns=iris.feature_names)
iris_pd['species'] = iris.target2. 분석 시각화
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(10,5))
sns.boxplot(x="petal length (cm)", y="species", data=iris_pd, orient="h");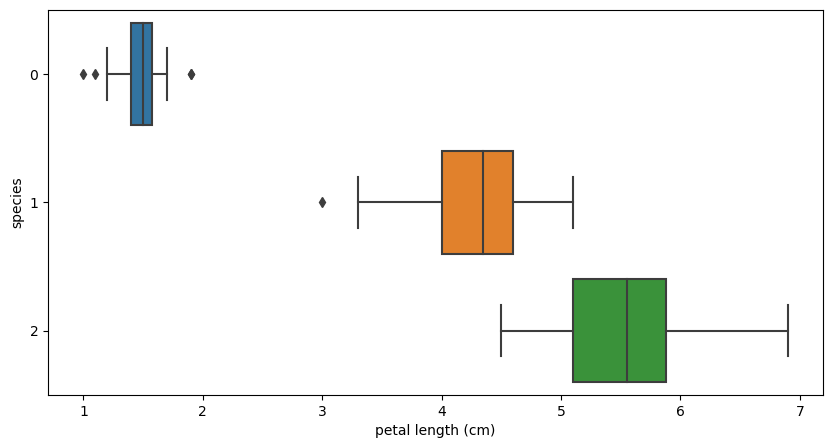
sns.pairplot(iris_pd, hue="species");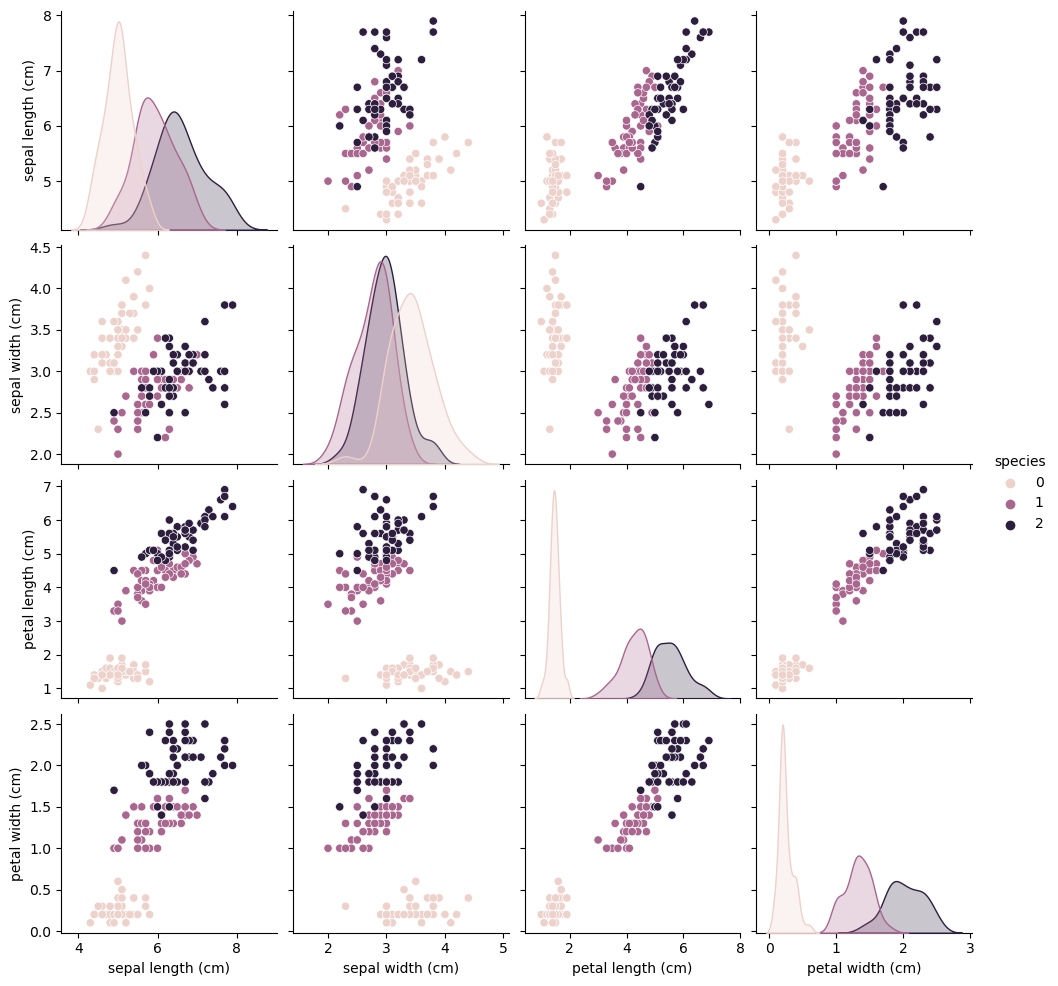
plt.figure(figsize=(5,4))
sns.scatterplot(x='petal length (cm)', y='petal width (cm)', data=iris_pd, hue='species');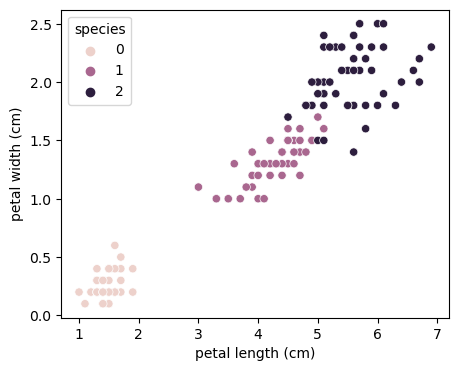
3. 머신러닝
# 학습
from sklearn.tree import DecisionTreeClassifier
iris_tree = DecisionTreeClassifier()
iris_tree.fit(iris.data[:, 2:], iris.target)
# 예측
from sklearn.metrics import accuracy_score
y_pred_tr = iris_tree.predict(iris.data[:, 2:])
accuracy_score(iris.target, y_pred_tr) # 0.9933333333333333# plot_tree
from sklearn.tree import plot_tree
plt.figure(figsize=(10,8))
plot_tree(iris_tree);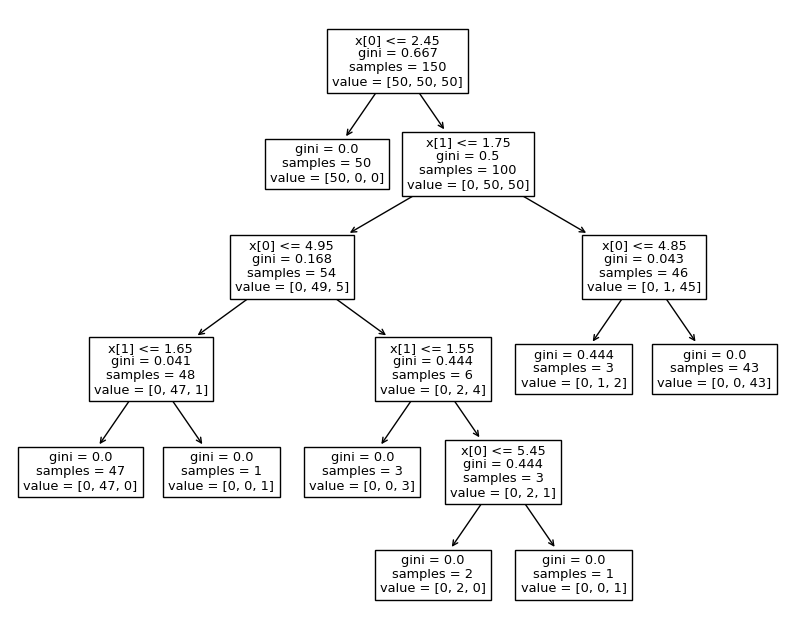
# plot_decision_regions
from mlxtend.plotting import plot_decision_regions
plt.figure(figsize=(10,8))
plot_decision_regions(X=iris.data[:,2:], y=iris.target, clf=iris_tree, legend=2)
plt.show()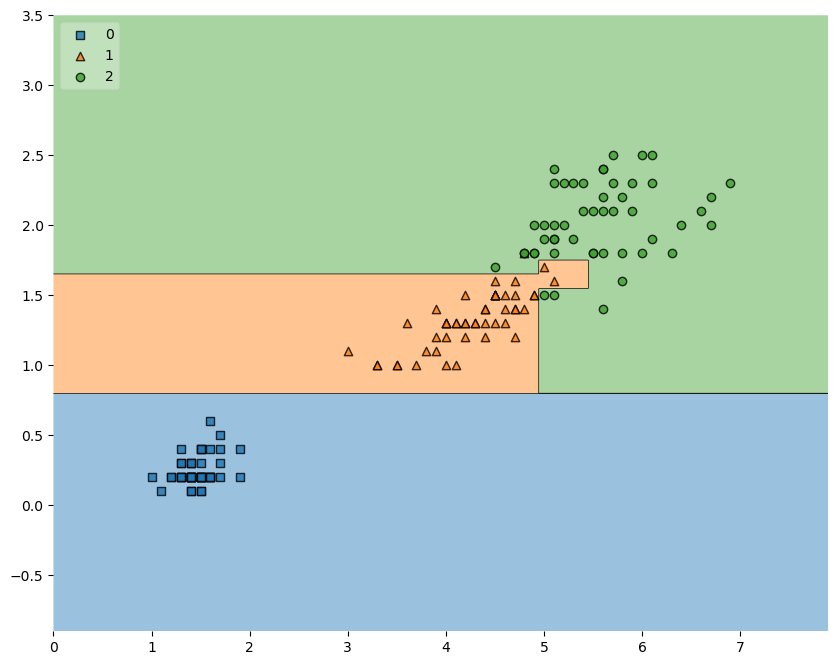
# 데이터 분리
from sklearn.model_selection import train_test_split
features = iris.data[:, 2:]
labels = iris.target
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, stratify=labels, random_state=13)# 학습
iris_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
iris_tree.fit(X_train, y_train)
# 예측
y_pred_tr = iris_tree.predict(X_test)
accuracy_score(y_test, y_pred_tr) # 0.9666666666666667
# 테스트
test_data = np.array([[1.2, 1]])
# iris_tree.predict_proba(test_data) # 각 target일 확률 확인
iris.target_names[iris_tree.predict(test_data)]타이타닉 데이터 분석
1. 데이터 가져오기
import pandas as pd
import numpy as np
url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/titanic.xls'
titanic = pd.read_excel(url)2. 분석 시각화
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
f, ax = plt.subplots(1,2, figsize=(12,5));
# 생존자 비율 (0:사망자, 1:생존자)
titanic['survived'].value_counts().plot.pie(ax=ax[0], autopct='%1.1f%%', explode=[0, 0.05])
ax[0].set_title('Pie plot - survived');
ax[0].set_ylabel('')
# 생존자 수
sns.countplot(ax=ax[1], x='survived', data=titanic)
ax[1].set_title('Count plot - survived');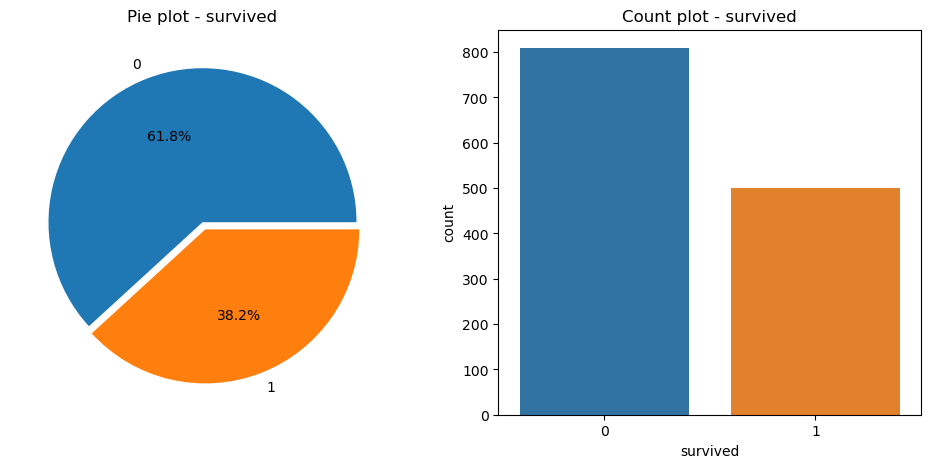
f, ax = plt.subplots(1,2, figsize=(12,5))
# 남녀 승객 수
sns.countplot(ax=ax[0], x='sex', data=titanic)
ax[0].set_title('Count of Passengers of Sex');
ax[0].set_ylabel('')
# 남녀 승객별 생존자/사망자 수
sns.countplot(ax=ax[1], x='sex', hue='survived', data=titanic)
ax[1].set_title('Sex : Survived and Unsurvived');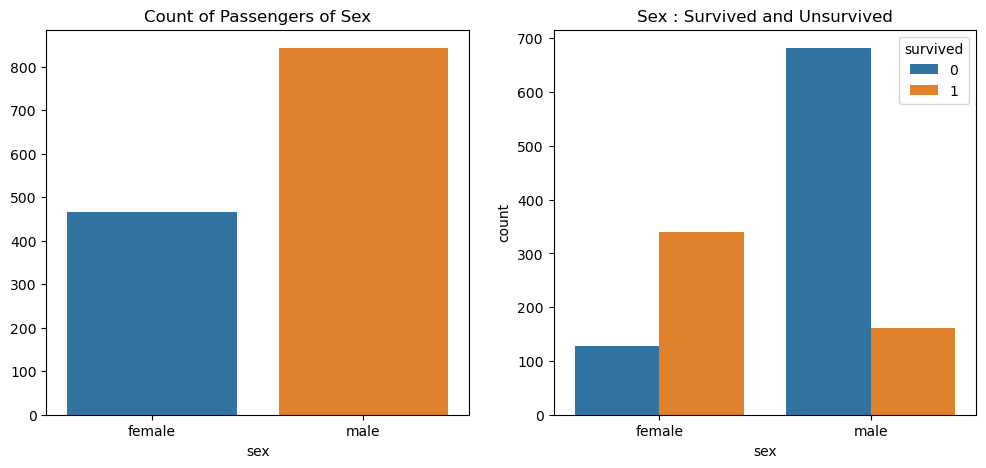
# 선실 등급별 사망자/생존자 수
pd.crosstab(titanic['pclass'], titanic['survived'], margins=True)
# 선실 등급별 남녀별 연령별 수
grid = sns.FacetGrid(titanic, row='pclass', col='sex', height=2, aspect=4)
grid.map(plt.hist, 'age', bins=20);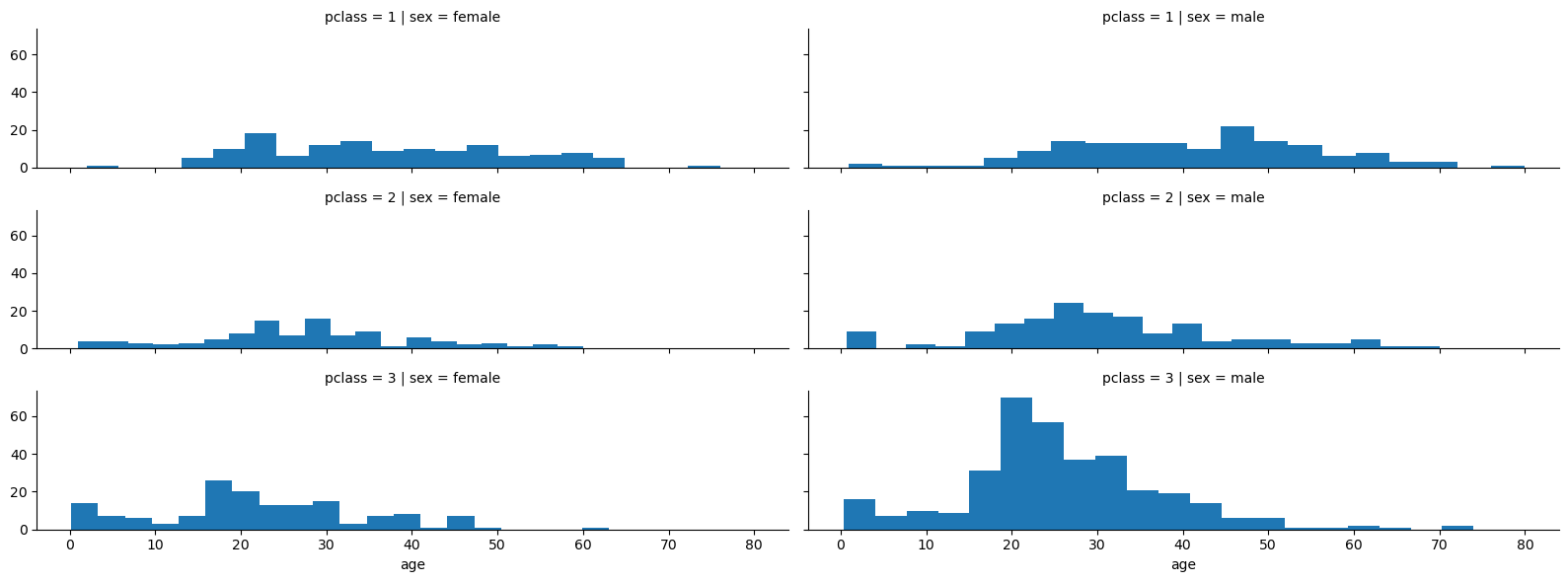
# 연령별 승객 수
import plotly.express as px
fig = px.histogram(titanic, x='age')
fig.show()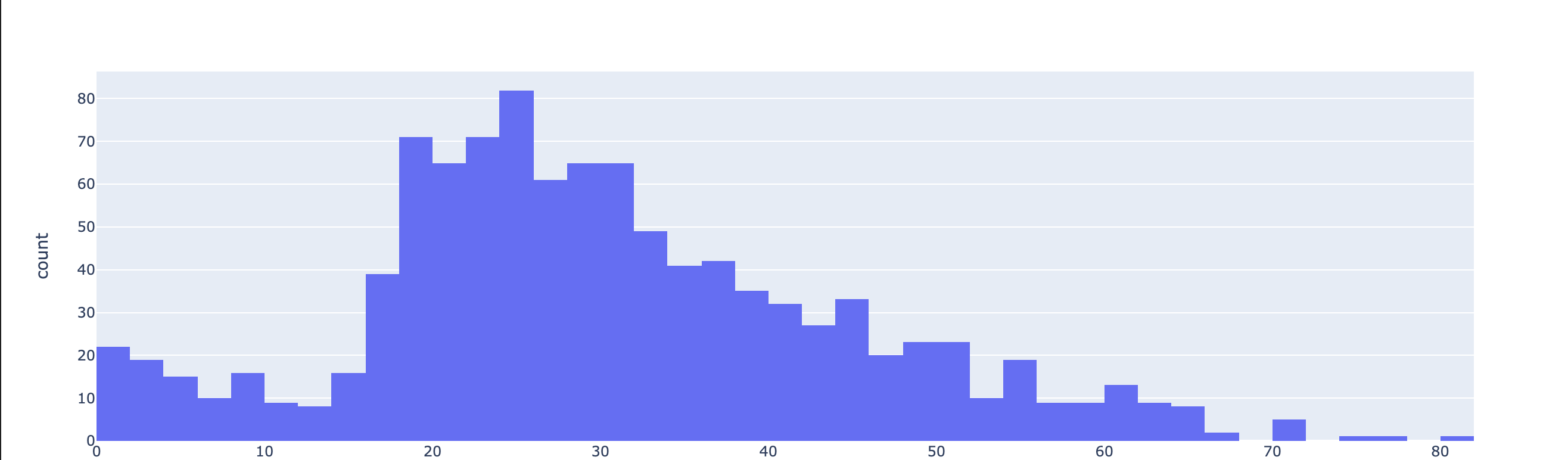
# 등실별 연령별 생존률
grid = sns.FacetGrid(titanic, row='pclass', col='survived', height=2, aspect=4)
grid.map(plt.hist, 'age', bins=20);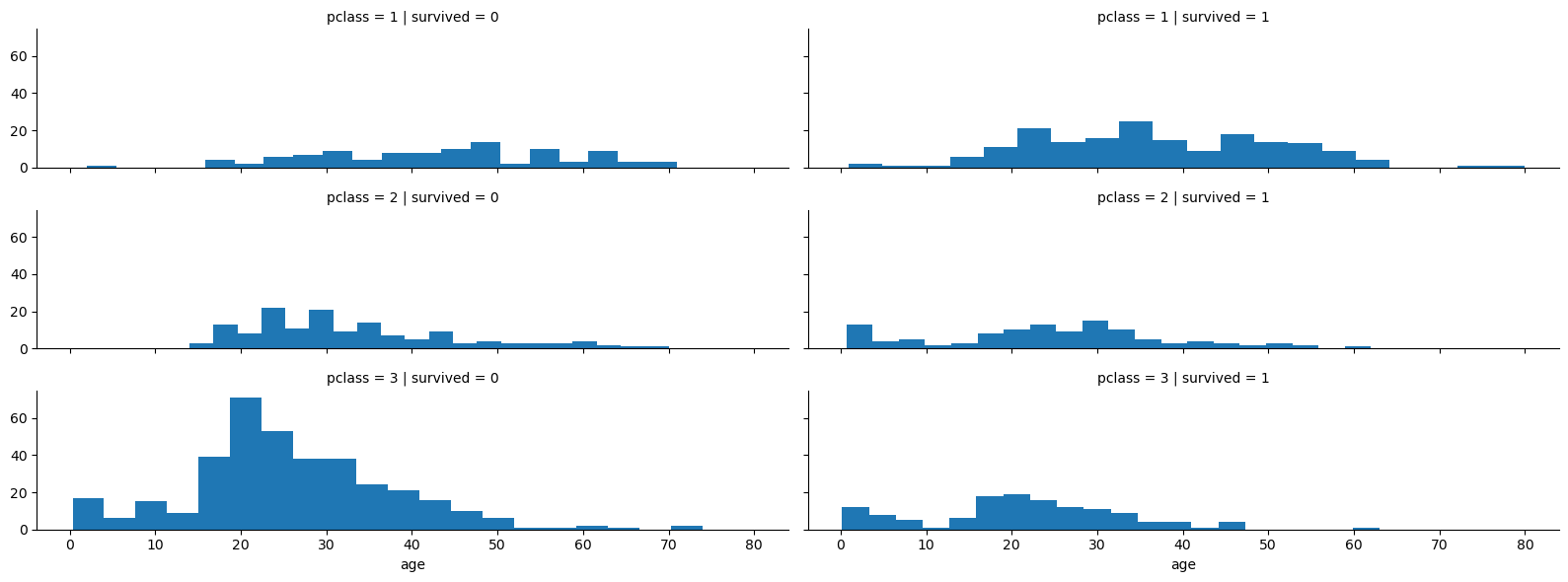
# 연령대 구분
titanic['age_cut'] = pd.cut(titanic['age'], bins=[0,7,15,30,60,100], include_lowest=True, labels=['baby','teen','young','adult','old'])
plt.figure(figsize=(15,5))
plt.subplot(131)
sns.barplot(x='pclass', y='survived', data=titanic);
plt.subplot(132)
sns.barplot(x='age_cut', y='survived', data=titanic);
plt.subplot(133)
sns.barplot(x='sex', y='survived', data=titanic);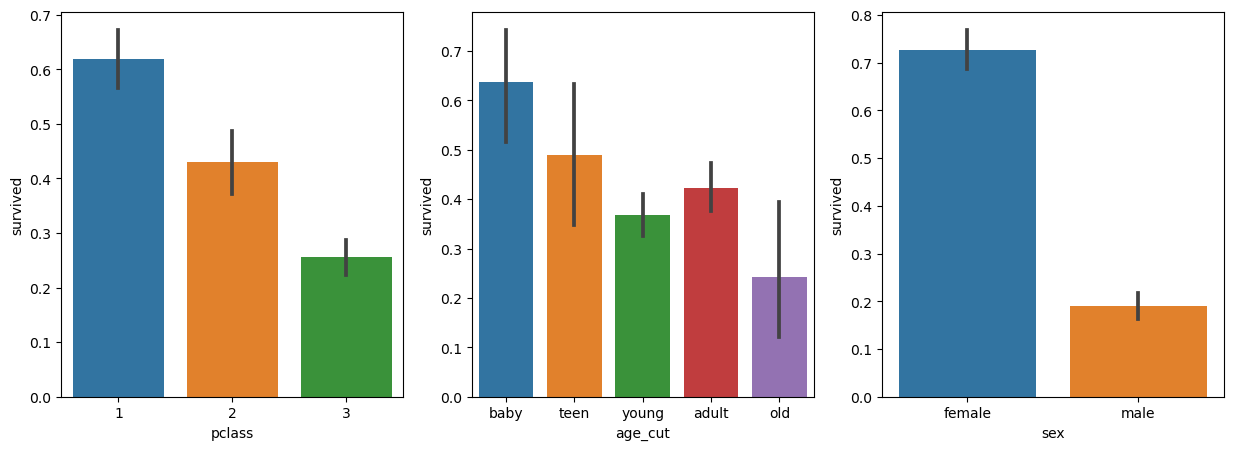
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(14,5))
women = titanic[titanic['sex']=='female']
men = titanic[titanic['sex']=='male']
ax = sns.histplot(women[women['survived']==1]['age'], label='Women survived', bins=20, ax=axes[0])
ax.legend();
ax = sns.histplot(men[men['survived']==1]['age'], label='Men survived', bins=20, ax=axes[1])
ax.legend();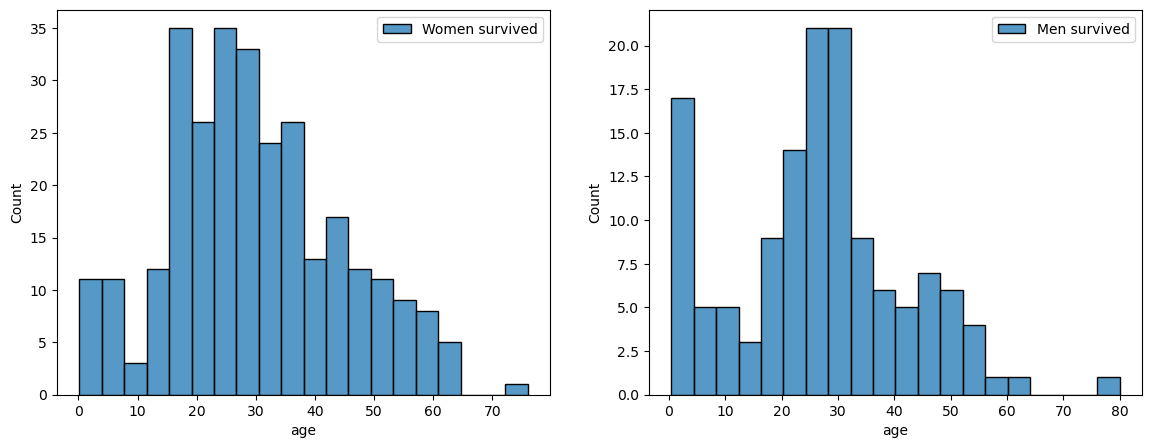
# 성명에서 직위 찾아 분류하기
import re
title=[]
for idx, dataset in titanic.iterrows():
tmp = dataset['name']
title.append(re.search('\,\s\w+(\s\w+)?\.', tmp).group()[2:-1])
titanic['title'] = title
pd.crosstab(titanic['title'], titanic['sex'])
titanic['title'] = titanic['title'].replace('Mlle','Miss')
titanic['title'] = titanic['title'].replace('Ms','Miss')
titanic['title'] = titanic['title'].replace('Mme','Mrs')
rare_f = ['Dona','Lady','the Countess']
rare_m = ['Capt','Col','Don','Major','Rev','Sir','Dr','Master','Jonkheer']
for each in rare_f:
titanic['title'] = titanic['title'].replace(each, 'rare_f')
for each in rare_m:
titanic['title'] = titanic['title'].replace(each, 'rare_m')
titanic[['title', 'survived']].groupby(['title'], as_index=False).mean()3. 머신러닝
# sex 컬럼 숫자로 변환
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(titanic['sex'])
titanic['gender'] = le.transform(titanic['sex'])
# notnull행만 사용
titanic = titanic[titanic['age'].notnull()]
titanic = titanic[titanic['fare'].notnull()]
# 데이터 분리
from sklearn.model_selection import train_test_split
X = titanic[['pclass','age', 'sibsp', 'parch','fare','gender']]
y = titanic['survived']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.8, random_state=13)
# 학습
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
dt = DecisionTreeClassifier(max_depth=4, random_state=13)
dt.fit(X_train, y_train
# 테스트데이터로 테스트
pred = dt.predict(X_test)
print(accuracy_score(y_test, pred))
# 테스트
dicaprio = np.array([[3, 10, 0, 0, 5, 1]])
print('Dicaprio : ', dt.predict_proba(dicaprio)[0,1])
winslet = np.array([[1, 16, 1, 1, 100, 0]])
print('Winslet : ', dt.predict_proba(winslet)[0,1])
21세기 주인공