1. 데이터 분석 프로세스
matplotlib에서 막대그래프를 그리는 것은 단순하게 간단한 일이 아니다. 데이터 시각화 하는데 내가 이런 것까지 알아야 해? 라고 할 때까지 해야한다. 화가 날 수 있지만 천천히 해보자.
그래프를 그리기 위해 어떤 데이터가 필요할까? 각 그래프 마다 요구하는 데이터의 형식은 다르기 때문에 이같은 이해가 필요하다.
데이터 분석이란, 데이터를 올바르게 추출하는 것도 중요하지만, 어떻게 데이터를 시각화할 것인지도 매우 중요하기에, 올바른 데이터 시각화 방법을 택하는 것도 중요하다.
뿐만 아니라 사전 지식으로 두 가지를 알아야 한다.
- 범주형 데이터(factor, character형): 범주 ex) 혈액형, MBTI, 성별, 사는지역 …
- 연속형 데이터(integer numeric형): 숫자, ex) 키, 몸무게, 판매량, 매출 ..
이것을 인지하고 있어야 데이터 형식에 맞는 그래프를 시각화할 수 있기 때문이다. 데이터 시각화 종류에 대해 알아보자.
데이터 시각화?
비교 분석: 막대차트 / 라인차트
구성 분석: 파이차트, 히트맵
관계 분석: 스케터 차트
분포 분석: 히스토그램 / 박스플롯
이런 분석 목적에 따라 차트를 그릴 수 있다.
비교분석) 막대그래프
막대 그래프는 여러 항목 간 비교 수월하고 이해하기 쉽다는 점이 장점이라고 할 수 있다.
하지만 아래와 같은 주의사항이 존재한다.
- 주의사항
- 중복된 내용이 없어야 함
- 색상을 통해 강조 필요
- 명도 부분으로 데이터 정도 표현 가능
- 축의 범위로 데이터 과장, 축소되지 않게 주의
비교분석) 라인 그래프
라인 그래프는 시간에 따른 데이터 경향 파악 용이하다. 항목 간의 변동 사항을 확인할 수 있어서 색깔 별로 시각적인 차이를 발견할 수 있다. 주의사항은 아래와 같다.
주의사항
- 여러 항목을 비교 시 색상 대비를 확실하게
- 너무 많은 라인을 넣지 말 것
구성분석) 파이 그래프
파이차트는 여러 항목들의 상대적 비율을 이해할 수 있다는 점이 장점이다. 그러나 여러 개의 변수 활용이 불가능하며, 전체 데이터 크기를 파악할 수 없다는 점이 한정적이라는 점에서 그래프를 그릴 때 크게 추천하지 않는 방법이다.
- 주의사항
- 5개가 넘는 항목 비교X
- 그외 or 기타로 표현
구성분석) 히트맵
히트맵은 데이터 값을 컬러로 변환시켜 열 분포 형태로 보여주어 시각적인 분석을 가능하게 한다는 점이 장점이다.
주의사항
- X 데이터: 범주형 데이터
- Y 데이터: 연속형 데이터
관계분석) 스케터차트
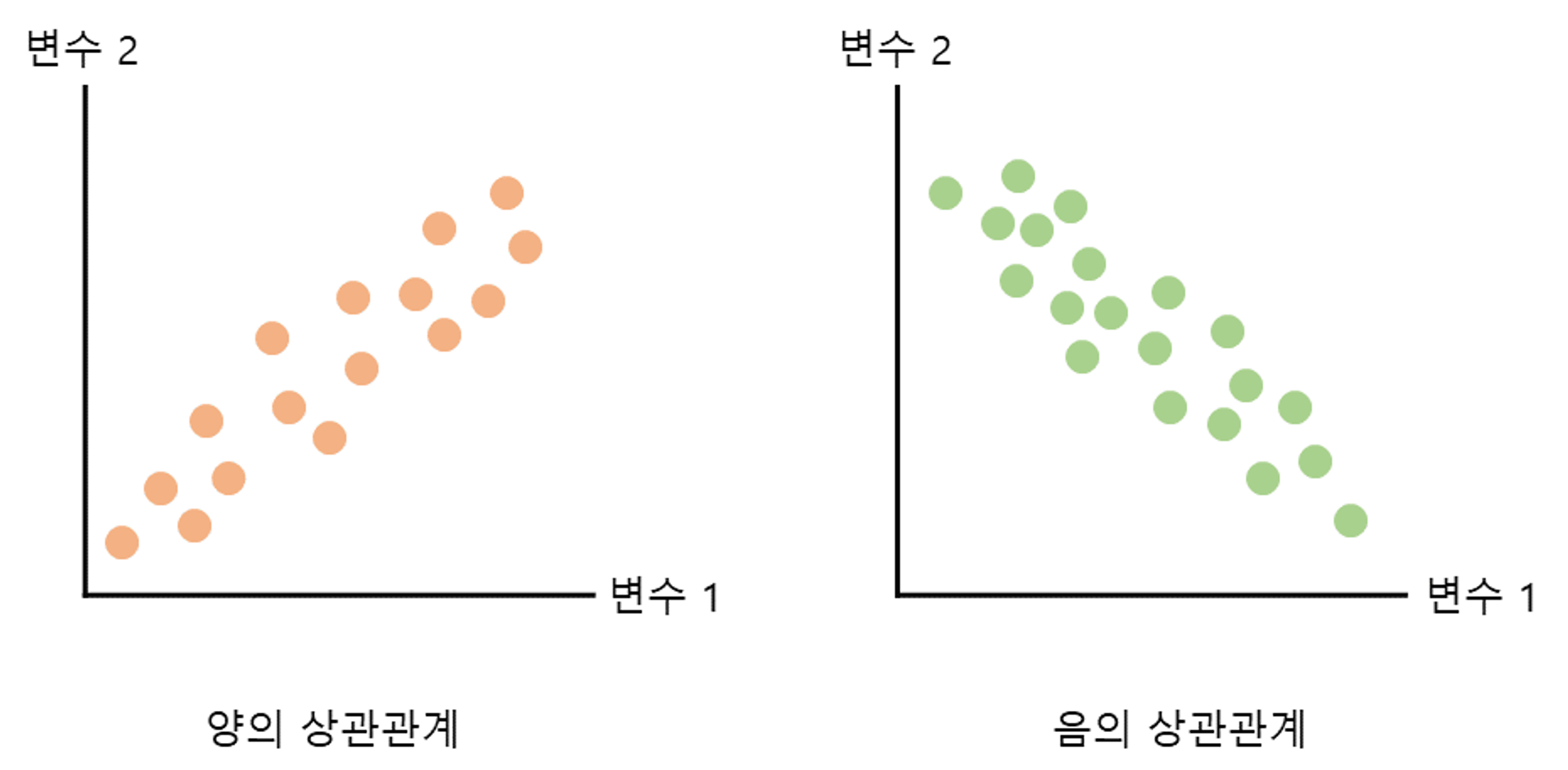
- 두 변수간의 관계 파악하기 용이
- 데이터 개수가 많은 경우 시각화하기 어려움
- 3개 이상 변수 시각화 불가능
- 주의사항
- 추세선을 활용하는게 좋다고 판단되면 추세선 활용도 가능
- 색상으로 구분해 데이터를 구분
분포분석) 히스토그램
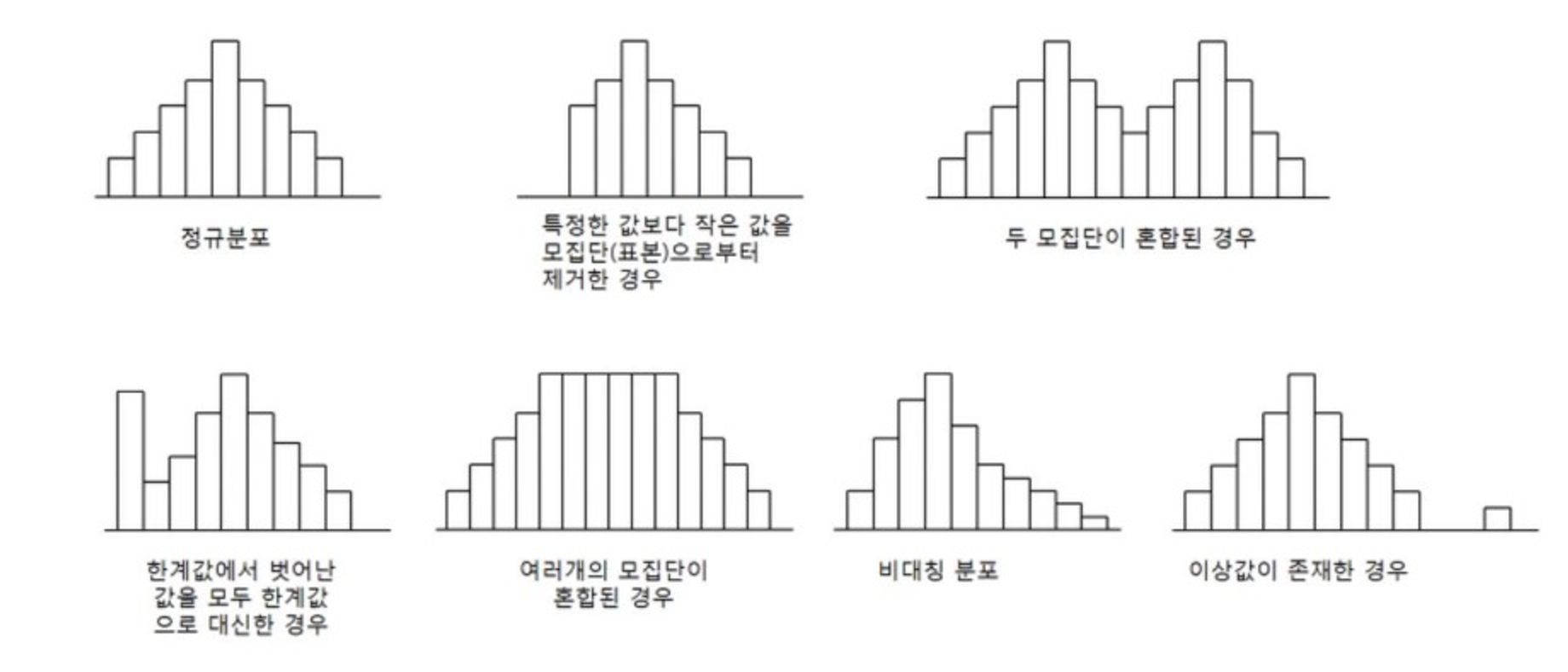
히스토그램은 데이터 분포를 파악하기 용이하다는 점에서 그 장점이 있다. 뿐만 아니라 대용량 데이터를 확인하기 용이하며, 이상치 여부를 판별하기에도 용이하다. 그러나 정확한 값을 알기 어렵고, 다양한 변수의 확인이 어렵다는 점에서 한계를 지닌다
주의사항
- 시각적으로 보기 좋은 구간 수 활용 필요
- 추세선을 활용할 때를 알아야함
분포분석) 박스 플롯 ***중요
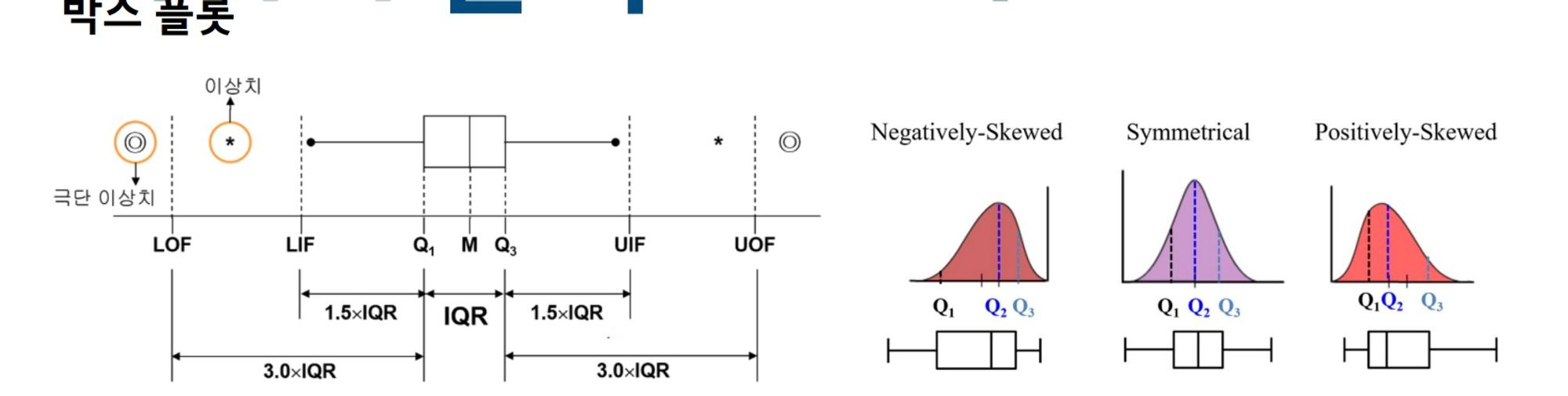
박스플롯은 분포를 파악하기 용이하며 그래프에서 이상치를 확인하고자 할 때 활용할 수 있다는 점이 특징이다. 사분위 값을 차트를 이용해 시각화 하는 차트이며, Bos whisker(수염)을 벗어난 값을 이상치로 책정한다. 또한 이상치는 통계 분석 전 처리 방법을 고민해야 함
또한 박스플롯은 아래와 같은 계산 방식을 지니고 있다.
Q0: 줄 세웠을 때 0번째
Q1: 25번째
Q2: 50번째 = median
Q3: 75번째
IQR: | Q3 - Q1 |
이상치: 어떤 값보다 월등히 크거나 작은 경우
- 계산식: (Q3 - Q1) x 1.5 초과
문제
Q3: 180 / Q1: 150 일 때, 이상치의 범위는?
이상치 경계 (아래 경계): Q1 - 1.5 IQR = 150 - 1.5 30 = 150 - 45 = 105
이상치 경계 (위 경계): Q3 + 1.5 IQR = 180 + 1.5 30 = 180 + 45 = 225
예시
이렇게 데이터 형식에 맞는 올바른 분석 방법을 알게 되었다. 하지만 정답은 없다. 상황에 알맞는 표현 방법을 예시를 통해 알아보자
💡 **예시 1 : A사가 판매하는 10개의 제품의 월별 판매량 비교?**- 비교 분석
- 막대(x: 범주형(월, 제품 명), y : 연속형(판매량)
- 각 항목별 판매량이 한눈에 확인할 수 있다.
- 높이 차이를 직관적으로 파악할 수 있다.
- 라인(x: 범주형(월), y : 연속형(제품에 따른 판매량)
- 월별 판매량 변화를 보기 쉬움
- 시간에따라 보기에 적합
- (기간이 길수록 라인이 괜찮을 것 같다.)
- 막대(x: 범주형(월, 제품 명), y : 연속형(판매량)
- 관계 분석
- 스케터(x : 연속형, y : 연속형)
- 분포분석
- 히스토그램(X or y : 연속형(학생 시험점수))
- 바이올린(X or y : 연속형(학생 시험점수))
- 관계 분석 (X: 연도, Y : GDP, 색상 : 대륙, 원크기 : GDP)
- 스케터 : 각 대륙별로 나라를 x축에 넣고 다른 색으로 표시해주어 분포를 알 수 있게 해줌
- 비교 분석
- 막대 :
- 대륙별이어서 막대로 해도 한눈에 보기 쉬울거같아서했습니다
- 대륙으로 카테고리 나누고 그 사이에서 높은 순서대로 막대그래프를 하면 비교분석하기 편할 것 같아서요
- 라인
- 대륙별 GDP 추세 변화를 파악하려는 의도
- 막대 :
데이터를 어떻게 가공할 지는 배웠지만, 결국 어떤 데이터를 보여줘야 하는지가 가장 중요하다.
데이터 범주를 설정한 뒤, 보여주고자 하는 내용을 강조해주어야 한다.
범주형을 연속형으로 바꿀 수 있을까?
범주형을 연속형으로 바꾸는 것은 불가능하다. 하지만 연속형은 범주형으로 변환이 가능하다
2. matplotlib 익히기
이렇게 데이터의 형식을 배웠다. 그렇다면 실제로 사용하기 위해 템플릿을 만들어보자.
막대그래프
막대 그래프를 만들어보자. X와 Y 데이터의 형식은 어떻게 정할까? X는 범주형으로 과일의 품목을 선택해주고, Y는 연속형 데이터로 숫자를 집어넣어보자
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
fruits = ['apple', 'blueberry', 'cherry', 'orange']
counts = [40, 100, 30, 55]
bar_labels = ['red', 'blue', '_red', 'orange'] # _red : 이미 존재하는 red에 포함
bar_colors = ['tab:red', 'tab:blue', 'tab:red', 'tab:orange']fig, ax를 통해 서브 플롯을 만들어준 후, fruit 리스트에 값을 집어넣어준다.
bar의 이름과 컬러를 지정해줘야 하기 때문에 값을 지정해준다. bar_labels의 리스트에 _red에 있는 이유는 이미 존재하는 red를 포함시켜줘야 하기 때문에 삽입을 해줬다.
ax.bar(fruits, counts, label=bar_labels, color=bar_colors)
ax.set_ylabel('fruit supply')
ax.set_title('Fruit supply by kind and color')
ax.legend(title='Fruit color')
plt.show()ax.bar(x축 , y축, label = 라벨 리스트, color = 바 컬러)를 생성해주면된다.
ax 서브플롯의 y라벨, title, 범례에 이름을 붙여준 후 그래프를 show()를 해준다
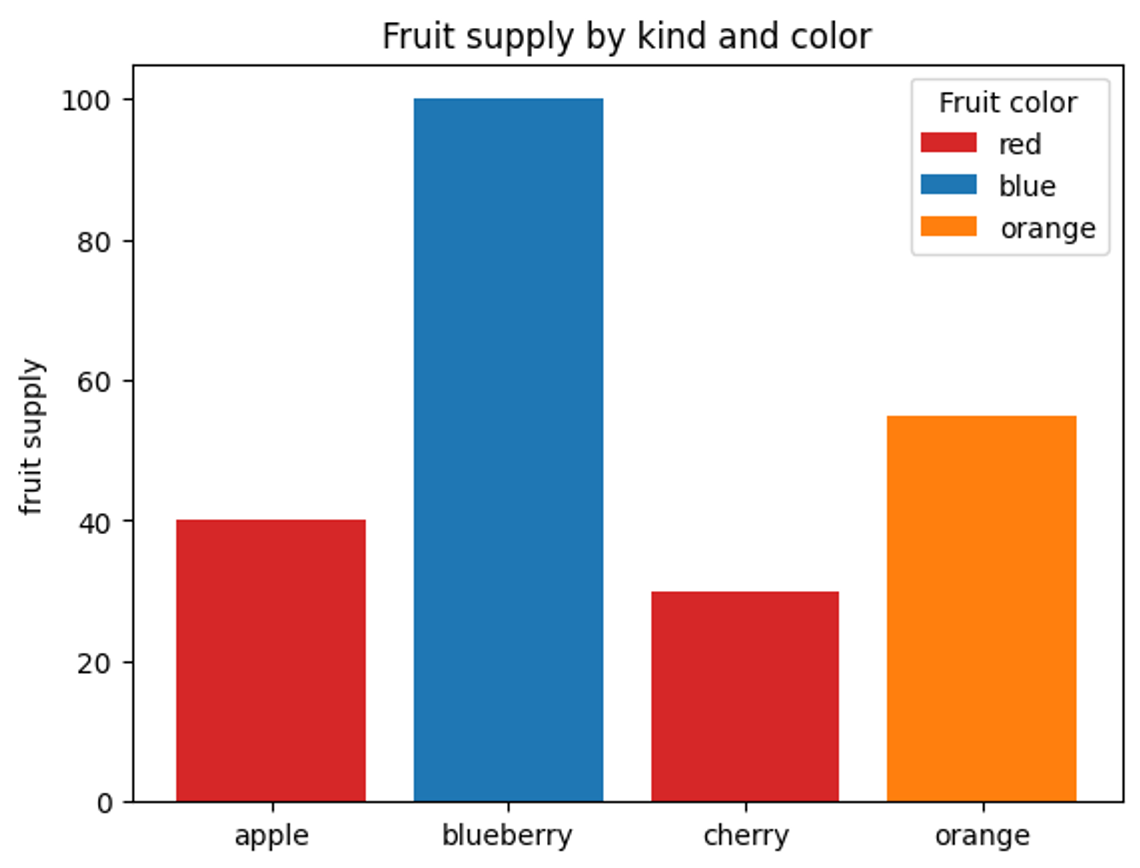
해당 결과는 위와 같다.
3. seaborn
seaborn은 matplotlib을 기반으로 만들어진 라이브러리다. pandas에서 활용하는 데이터프레임 데이터타입을 시각화하는데 유리하다는 장점을 지니고 있다. 예시를 들어보자.
import seaborn as sns
df = sns.load_dataset("penguins")
df.head()penguins라는 데이터셋을 불러와보자.
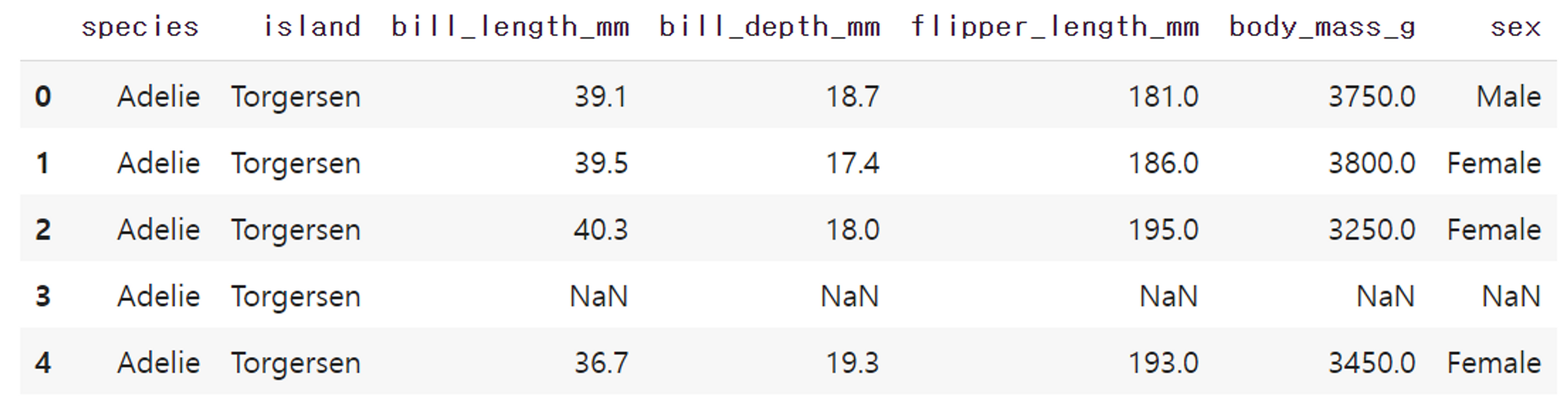
출력 결과는 위와 같다.
g1 = df[['island', 'body_mass_g']].groupby('island').mean()
sns.barplot(data=g1, x=g1.index, y="body_mass_g")섬 별로 펭귄들의 평균 몸무게를 측정하고 싶다는 욕구가 들어 위와 같은 코드를 작성해봤다. barplot을 활용해 x축엔 x1의 인덱스인 섬 종류와, y는 body_mass_g 밸류들을 시각화했다. 결과는 어떻게 나올까?
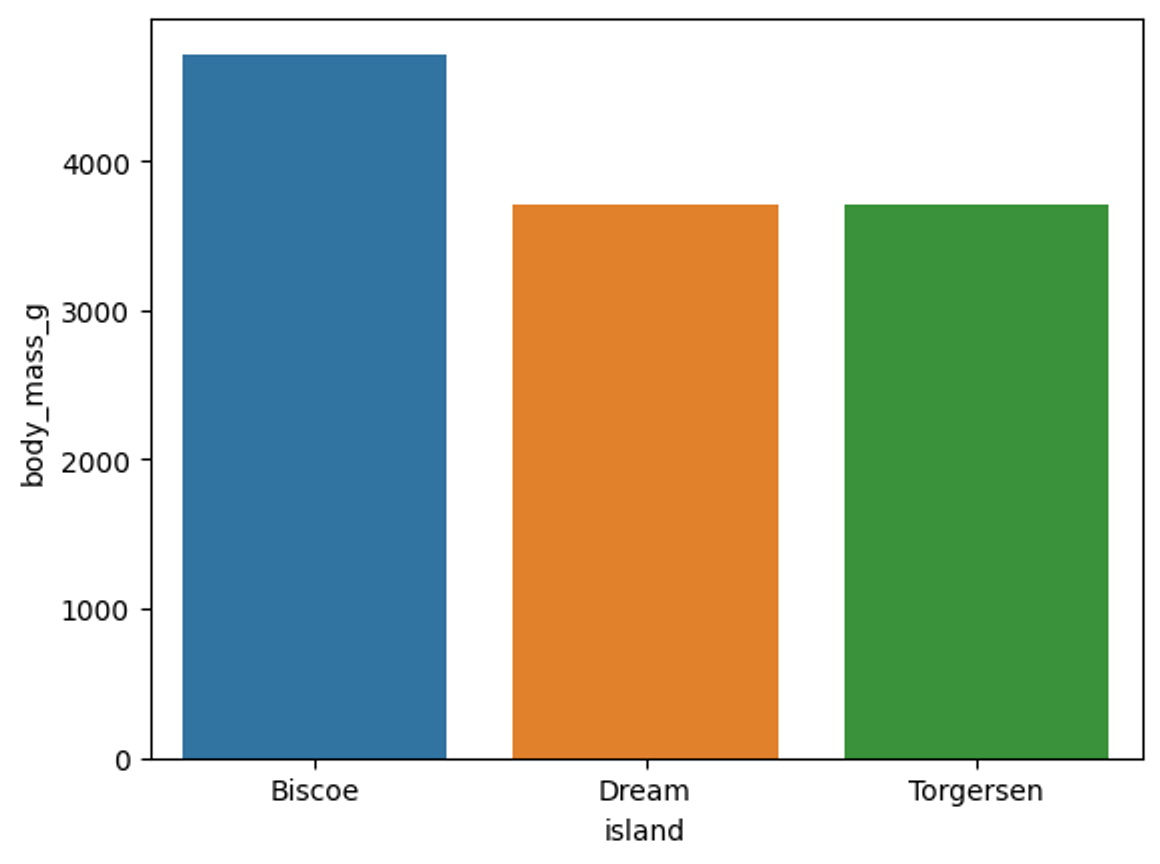
알아서 색을 지정해준다는 것이 편리하다. 그렇다면 성별 별로 다시 바 그래프를 만들어보자.
sns.barplot(data=df, x="island", y="body_mass_g", hue="sex")seaborn은 hue라는 인자를 사용해 세 번째 변수를 삽입할 수 있다. 하지만 범주형만 가능하다는 점을 인지해야 한다.
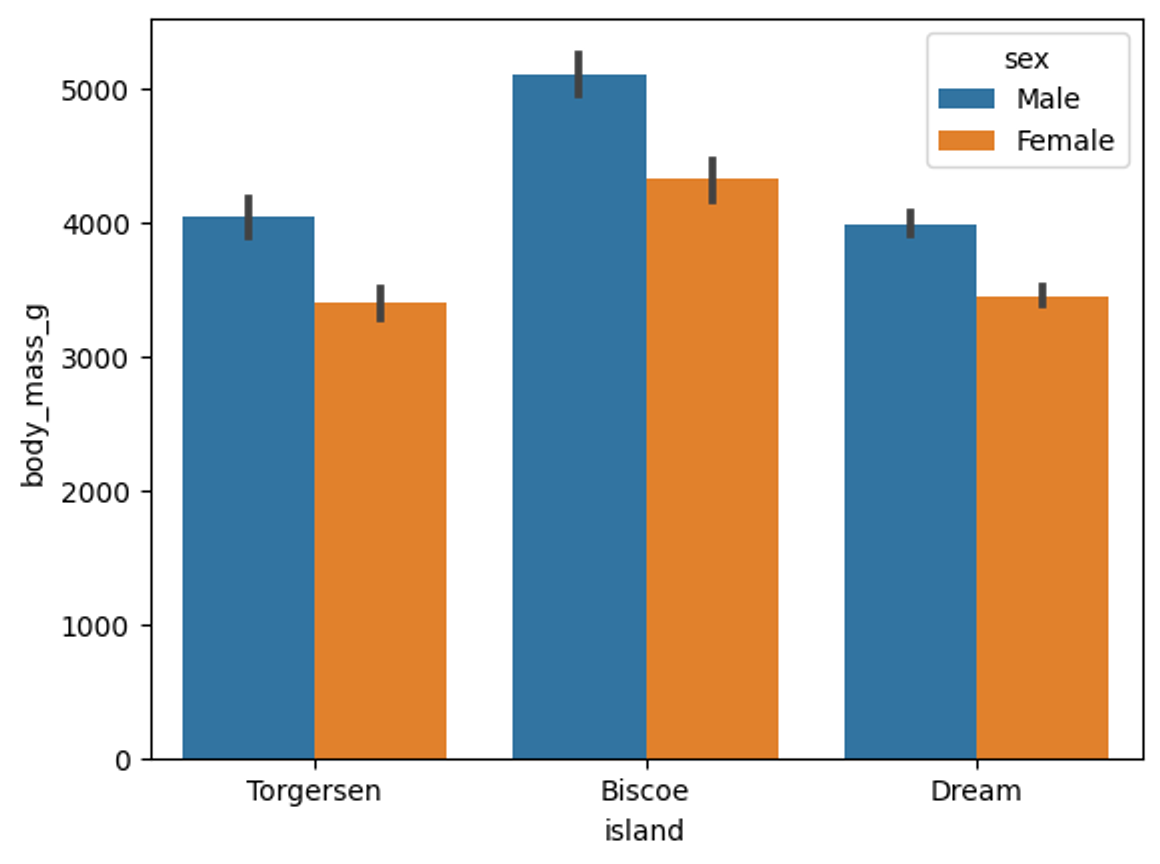
이렇게 되면 성별에 따른 몸무게도 시각화를 진행할 수 있다. 정말 좋다! seaborn.
4. plotly
그렇다면 plotly는 어떤 데이터 라이브러리일까? seaborn이 matplotlib을 기반으로 만들어진 라이브러리라면, plotly는 matplotlib와 seaborn을 개선한 데이터 라이브러리라고 할 수 있다.
plotly는 인터렉터브하게 그래프를 확인할 수 있다는 점이 장점이며, 뿐만 아니라 배열과 데이터프레임워크를 데이터로 삼을 수 있다는 점 또한 장점이다. 예제를 들어보자.
import plotly.express as px
data_canada = px.data.gapminder().query("country == 'Canada'")
data_canada.head()plotly의 약어는 보통 px로 표현한다. 캐나다의 데이터를 가져와 가공시켜 시각화를 진행하고자 하므로 데이터를 불러와본다.
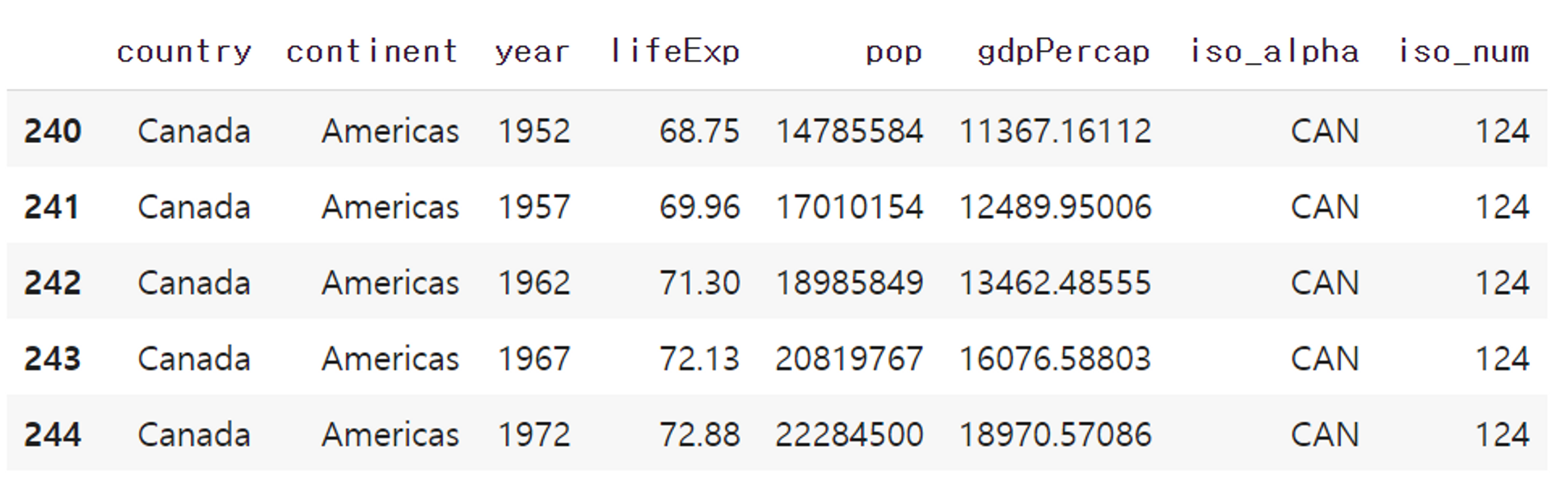
출력 결과는 위와 같다. plotly를 활용해 데이터를 시각화 해보자. bar plot으로 시각화를 진행할 것이기 때문에 px. bar를 활용해 그래프를 만들어준다.
fig = px.bar(data_canada, x='year', y='pop')
fig.show()px.bar는 x를 year 칼럼을 가지고, y를 pop칼럼으로 가진다. 결과는 아래와 같다
시대별로 pop항목이 상승한다는 것을 확인할 수 있다.
다시 강조하지만, 데이터를 가공하는 방법을 모두 숙지하고, 이를 시각화 하는 방법을 마스터한다는 생각 보다는 적재적소에 데이터를 시각화할 안목을 기르는 것이 중요하다.
