이 글은 Deep learning with pytorch - Eli Stevens, Luca Antiga, Thomas Viehmann 을 공부한 내용을 정리하는 글
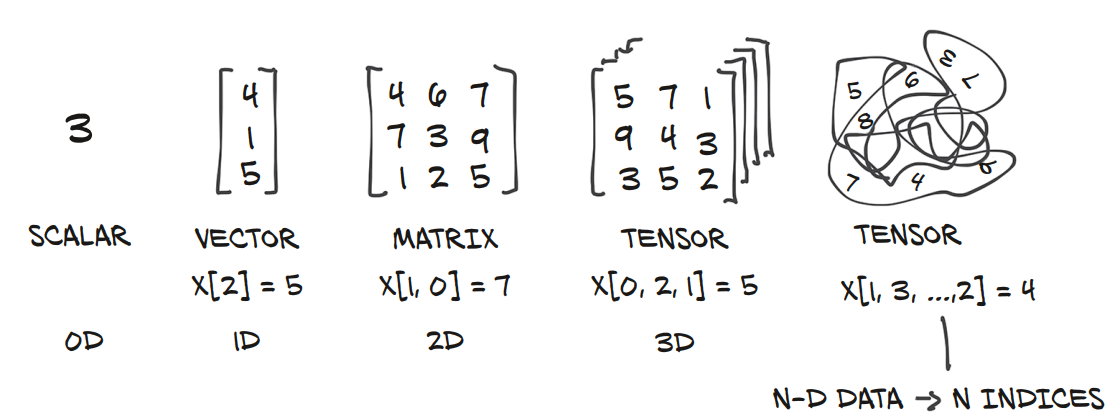
텐서는 고차원의 데이터를 표현하는 방법이다.
그럼에도 다른 multidimensional array들과 다른 점은, GPU연산을 통해 여러대의 device에서 분산 연산이 가능하다는 점이다.
lists 나 tuples과의 차이점
tensor와 list, tuples의 표면적인 차이점은 없지만, 좀 깊이 살펴보면 완전히 다른 방식의 type이다.
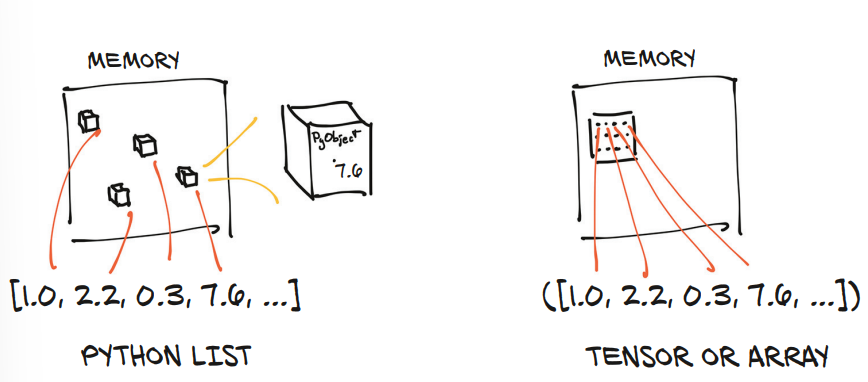
위와 같다. (이해 안됨. 추가 찾아보기.)
이 때문에, Tensor를 사용하는 것이라고 한다.
img_t = torch.randn(3, 5, 5) # shape [channels, rows, columns]
weights = torch.tensor([0.2126, 0.7152, 0.0722])위 img_t를 gray-scale로 변환하고 싶다.
배치로 된 이미지가 있다고 하면
batch_t = torch.randn(2, 3, 5, 5) # shape [batch, channels, rows, columns]이럴 경우에, 채널 단에서 일반화 하기 위해서는 dim 0 혹은 dim 1 를 같이 표현해 줄 수 있는, dim -3을 사용해야한다.
# In[4]:
img_gray_naive = img_t.mean(-3)
batch_gray_naive = batch_t.mean(-3)
img_gray_naive.shape, batch_gray_naive.shape# Out[4]:
(torch.Size([5,5])), torch.size([2, 5, 5]))근데 weight도 있으니까, 이를 잘 곱해서 합쳐야 한다. 브로드캐스팅을 이용해서, 쉽게 할 수 있다.
# In[5]:
unsqueezed_weights = weights.unsqueeze(-1).unsqueeze_(-1)
img_weights = (img_t * unsqueezed_weights)
batch_weights = (batch_t * unsqueezed_weights)
img_gray_weighted = img_weights.sum(-3)
batch_gray_weighted = batch_weights.sum(-3)
batch_wegihts.shape, batch_t.shape, unsqueezed_weights.shape# Out[5]:
(torch.Size([2, 3, 5, 5]), torch.Size([2, 3, 5, 5]), torch.Size([3, 1, 1]))근데 이렇게 처리하기에는 너무 코드도 길고 비효율 적이다.
따라서 PyTorch에서는 einsum 이라는 함수가 있다.
# In[6]:
img_gray_weighted_fancy = torch.einsum('...chw,c->...hw', img_t, weights)
batch_gray_weighted_fancy = torch.einsum('...chw,c->...hw', batch_t, weights)
batch_gray_weighted_fancy.shape# Out[6]:
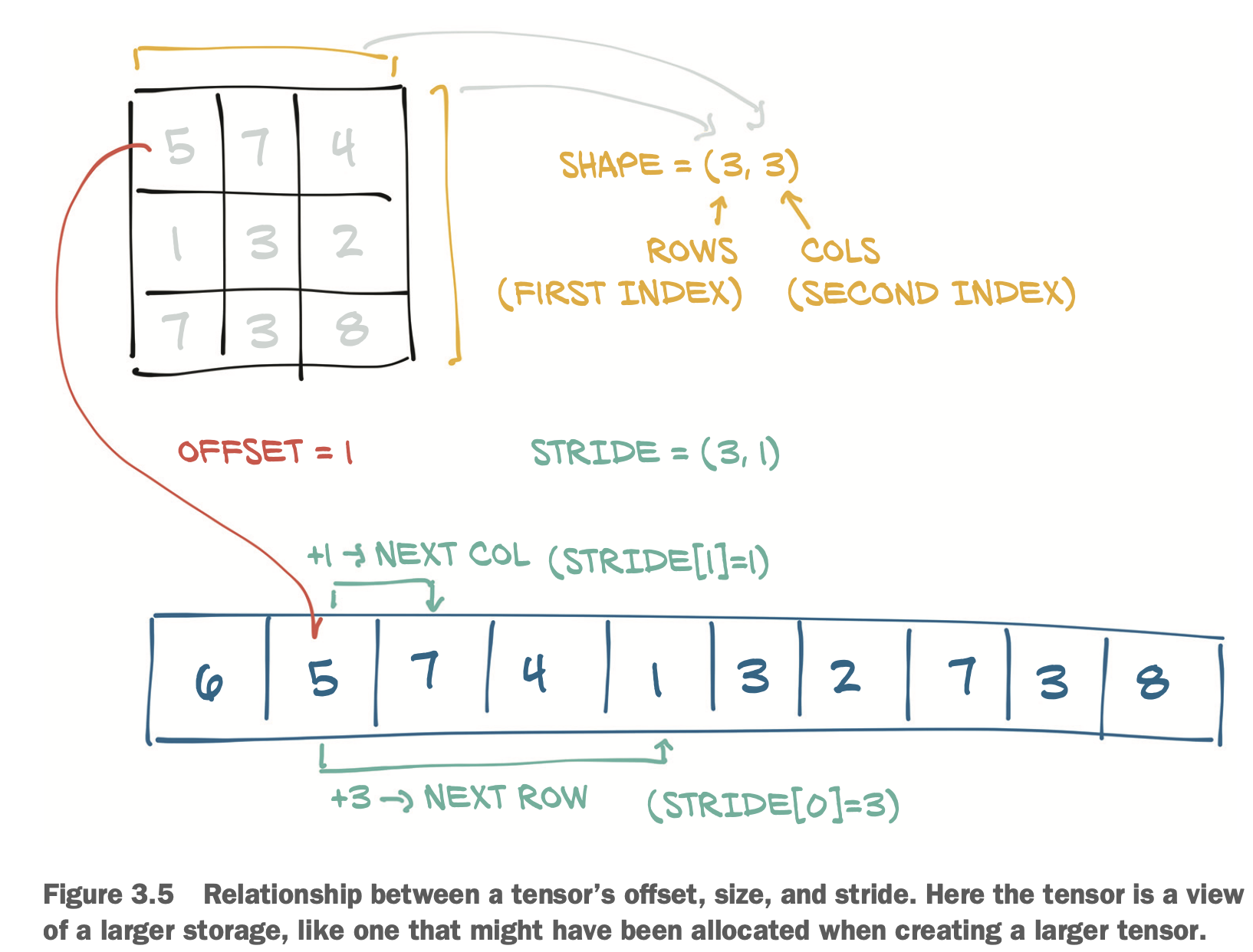
torch.Size([2, 5, 5])Accessing an element in a 2D tensor results in accssing the
storage_offset + stride[0] * i + stride[1] * jThe offset will usually be zero;
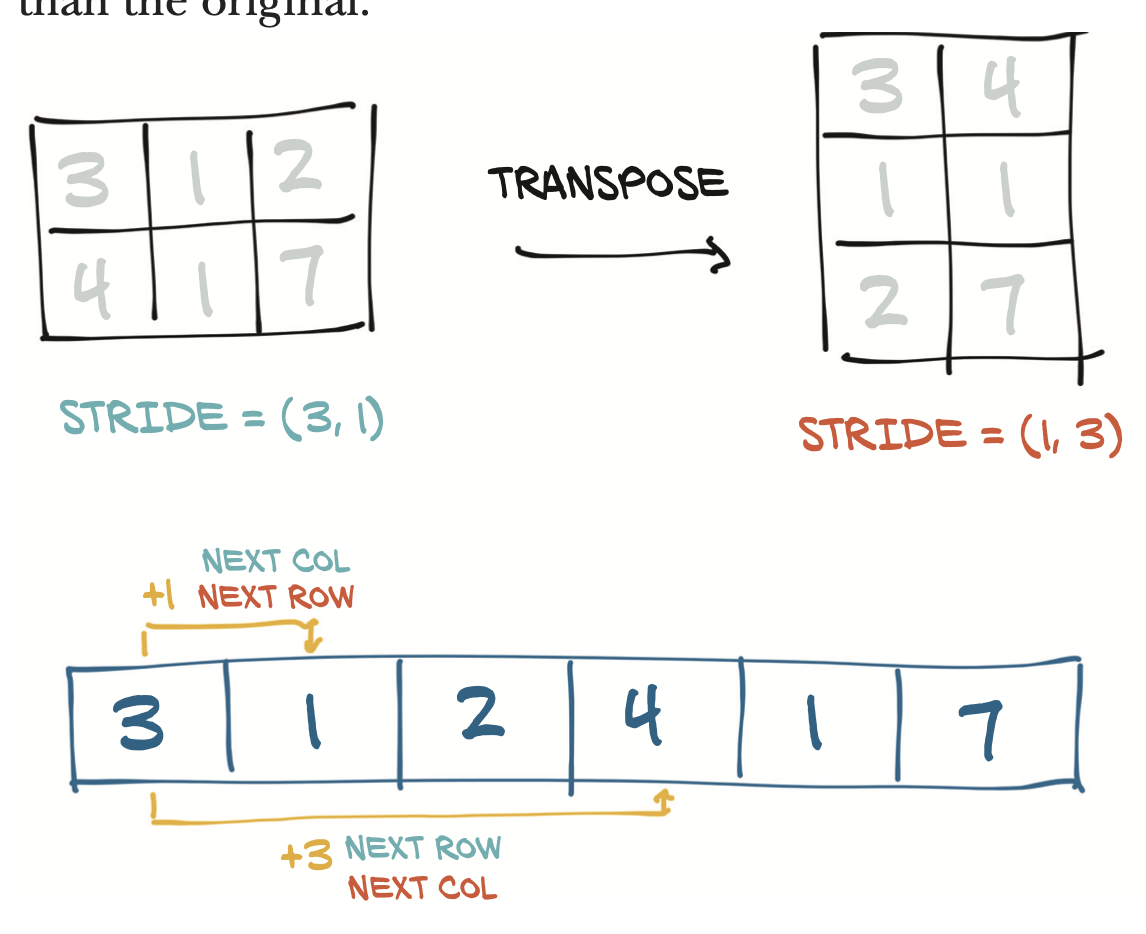
Storage와 Tensor사이의 관계는, Tensor를 새롭게 할당 할 때 Storage의 변환 없이 size, storage offset, stride만 바꿔준다.
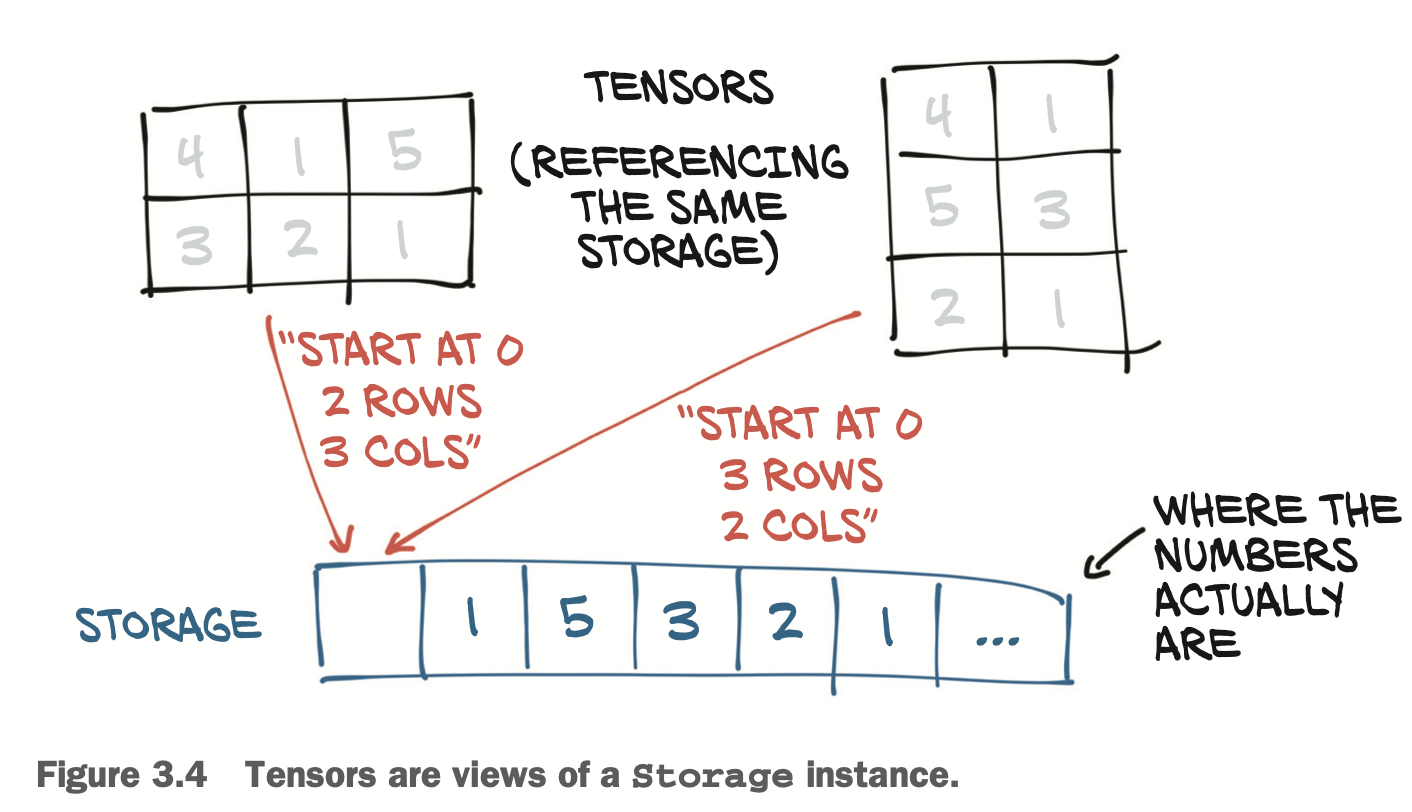

클론을 사용하는 이유; Storage()는 그대로 이기 때문.
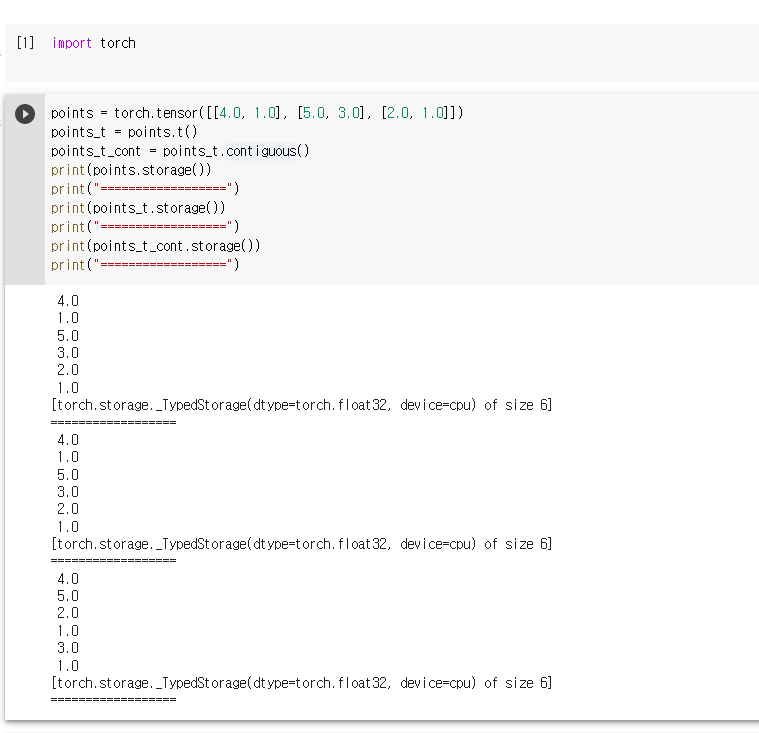
contiguous()함수는 연속체로 만들어 주는건데, 만약 연속체가 아닌 경우 새로운 Storage()를 만들어 할당하는 것 같다.
지금까지는 CPU에서의 연산 방법들에 대해 설명, 이제 GPU로 옮기자.
dtype에 덧붙여서 Tensor는 device라는 개념이 존재한다.
# In[64]:
points_gpu = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]], device='cuda')CPU를 GPU에 올리기 위해서는 to method를 쓴다.
# In[65]:
points_gpu = points.to(device='cuda')이렇게 하면 같은 데이터를 가지는 새로운 텐서를 RAM이 아니라 GPU에 저장한다. 그럼 이제 저장된 데이터는 GPU에 존재하고, 빠른 연산이 가능해 진다.
만약에 하나 이상의 GPU를 사용하고 있다면, 어떤 GPU에 할당할 지 정해줄 수 있다.
# In[66]:
points_gpu = points.to(device='cuda:0')
points_gpu tensor는 CPU로 돌아오지 않는다.

따라서, 상수를 더해주는 연산도 가능하다.
# In[68]:
points_gpu = points_gpu + 4이 연산도 GPU에서 일어난다. 이 연산을 다시 CPU로 되돌아 오게 하기 위해서는 to연산을 통해 데려온다.
# In[69]:
points-cpu = points_gpu.to(device='cpu')이를 간단하게 쓸 수도 있다.
# In[70]:
points_gpu = points.cuda()
points_gpu = points.cuda(0)
points_cpu = points_gpu.cpu()
