PaDiM : a Patch Distribution Modeling Framework for Anomaly Detection and Localization
PaDiM : a Patch Distrivution Modeling Framework for Anomaly Detection and Localization
- International Conference on Pattern Recognition, International Workshops and Challenges 2021 (ICPR 2021)
Abstract
- pre-trained CNN based model
- 이상 부분이 존재하는 구역을 탐지
- Multivariate Gaussian distribution : normal class의 probabilistic representation을 얻기 위한 목적
Introduction
이미지 분야의 anomaly detection은 주로 이미지 전체에 대해 정상 혹은 이상을 판단
본 논문에서 제안하는 PaDiM은 patch 단위로 이상을 탐지하여 보다 정확하고 설명 가능한 결과를 도출하고자 함
이상 부분을 patch 단위로 탐지하는 여러 방법이 존재 (ex. SPADE, Patch SVDD etc.)
but 본 논문에서 말하는 이전 방법들은 아래와 같은 한계점이 존재
- normal data를 학습 시키는 과정이 필요하거나,
- 전체 training dataset에 대해 kNN을 통한 distance 도출 과정이 필요
특히 kNN의 경우는 training dataset이 커짐에 따라 complexity가 linear하게 증가
본 논문에서는 위의 문제점을 보완하고자 Patch Distribution Modeling(PaDiM)을 제안
PaDiM은 아래 두 논문을 참고하여 성능을 개선시키고자 함
-
Modeling the Distribution of Normal Data in Pre-Trained Deep Features for Anomaly Detection (International Conference on Pattern Recognition 2020; ICPR 2020)
-
Sub-Image Anomaly Detection with Deep Pyramid Correspondences (arxiv 2020)
PaDiM은 두 논문문과 같이 pre-trained model을 사용하여 학습에 필요한 시간 소모를 없애고, Multivariate Gaussian distribution을 사용하여 patch 간의 correlation을 측정
Patch Distribution Modeling
PadiM의 전체적인 process
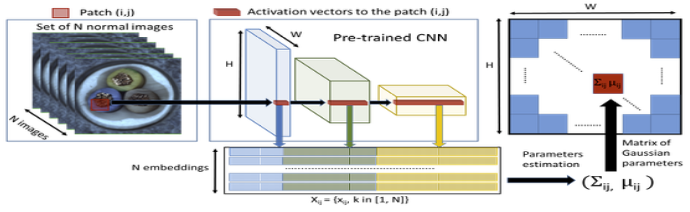
출처 : PaDiM papaer
Embedding extraction
Normal image의 feature를 추출하는 과정
본 논문에서는 pre-trained model을 사용하여 dataset에 최적화 시키기 위한 학습 과정을 skip
- 사용한 pre-trained model : ResNet18, Wide ResNet-50-2, EfficientNet-B5
PaDiM의 feature extraction 과정은 SPADE와 유사
N개의 normal images로부터 embedding된 feature 추출
위의 참고 논문들과 같이 다양한 layer에서 추출한 feature를 같이 사용하여 local/global information을 함께 사용
3개의 layer에서 추출한 feature를 함께 사용
이 때, 가장 큰 resolution의 feature에 맞게 resize 한 뒤 concat해서 embedding vector를 생성
➞ 서로 다른 sementic level과 resolution에서 나온 정보 포함하고 있는 embedding vector
3개의 layer에서 추출한 feature를 합하여 하나의 feature로 구성
추출한 wxh개의 patch들이 각각의 mean과 covariance를 가짐
Learning of the normality
normal embedding vector의 분포를 구함
추출한 feature의 patch 별 mahalanobis distance를 구하기 위해 mean과 covariance를 계산
patch embedding vector는 multivariate gaussian distriution에 의해 생성되었음을 가정
Inference : computation of the anomaly map
Mahalanobis distance를 사용하여 normal/abnormal을 판단
-
AD_ICPR 2020 : 추출된 하나의 feature map들로 분포를 구한 뒤 mahalanobis distance 계산
-
PaDiM : patch 별 적용하여 mahalanobis distance 계산
-
SPADE : patch 별 kNN을 사용하여 측정
patch 별로 anomaly score를 측정
➞ image 당 patch 개수만큼의 anomaly score가 계산되어 anomaly map이 생성됨
anomaly map은 patch 별 이상치 정도로 표현 가능하며,
전체 image의 anomaly score는 score map의 가장 큰 anomaly score로 표현
➞ 이미지에서 가장 결함이 큰 부분이 이미지의 결함 정도로 대표될 수 있음
Anomaly socre 비교
- SPADE
- patch 별 anomaly score 측정
- kNN을 사용하여 모든 patch와 비교(k개)
- Multivariate Gaussian & Mahalanobis AD
- image 하나에 대한 anomaly score
- mahalanobis distance를 사용
- PaDiM
- patch 별 anomaly score 측정
- mahalanobis distance를 사용, 동일한 위치에 존재하는 patch들과 비교
Experiments and Conclusion
Experiments
PaDiM으로 이상 부분을 탐지한 결과 예시

left column : normal images
middle column : abnormal images(ground truth)
right column : anomaly heatmap obtained PaDiM(high score : yellow)
비정상 이미지의 결함 부분의 anomaly score가 높게 측정
결함 위치에 따라 normal/abnormal 판단
MVTec과 Shanghai Tec Campus (STC) dataset 사용
MVTec의 경우 ramdom rotation과 random crop 후에 사용
➞ real dataset의 경우에 탐지하고자 하는 물체가 항상 잘 정렬되어 있지 않을 경우가 많기 때문
MVTec 실험 결과를 texture class와 object class로 나눠서 비교
texture class : 전체적으로 비슷하게 구성되어 있음
object class : 핵심이 되는 물체가 존재(물체의 특징 뚜렷)
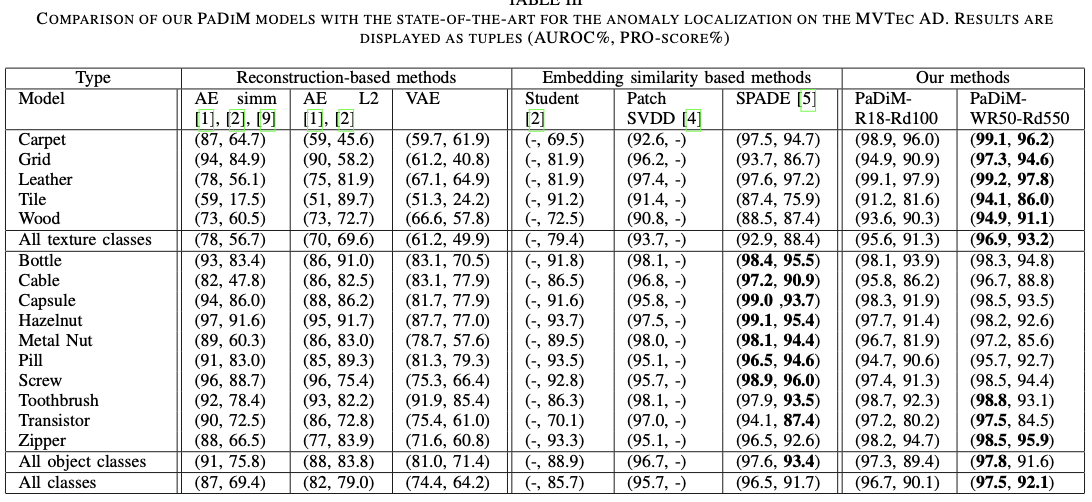
* 결과에 대한 추가 고찰 필요 (추가)
Conlusion
- Pretrained model 사용하여 feature extraction
- Mahalanobis distance를 사용하여 anomaly score 측정
- patch 단위의 연산을 통해 불량의 위치 탐지 가능
- 추가적인 학습 없이 사용 가능
