Human Pose Estimation 글
latest update : 2022-03-04
Human Pose Estimation?
Human Pose Estimation은 직역하면 "사람 자세 추정"입니다.
즉, 영상/이미지 내에서 사람의 자세를 추정하는 분야라고 할 수 있습니다.

그런데 위 그림처럼 야구나 테니스와 같은 운동에서는 팔과 다리 동작이 다양하고,
허리를 굽히거나 앉아 있는 등 사람의 자세는 일상 생활에서 매우 다양합니다.
그러면 어떻게 사람의 자세를 추측하고 표현할 수 있을까요?
Human Pose Estimation = Find Joints
인체를 살펴보면 사람은 "관절(joint)"을 중심으로 움직이는 것을 알 수 있습니다.
팔 움직임의 경우, 어깨(shoulder), 팔꿈치(elbow), 손목(wrist) 관절을 중심으로 여러 가지 팔 움직임이 나타나게 되고
다리 움직임의 경우, 엉덩이(hip), 무릎(knee), 발목(ankle) 관절을 중심으로 여러 가지 다리 움직임이 나타나게 됩니다.
여러 가지 자세를 볼 때, 관절을 찾고 서로 연관된 관절끼리 직선으로 표현한다면,
일상생활에서 다양한 사람의 자세들을 찾고 표현할 수 있을 것입니다.
(아래 그림처럼 사람은 관절 중심으로 빨간색 직선처럼 움직이는 것이지, 파란색 곡선처럼 움직이지 않겠죠?)
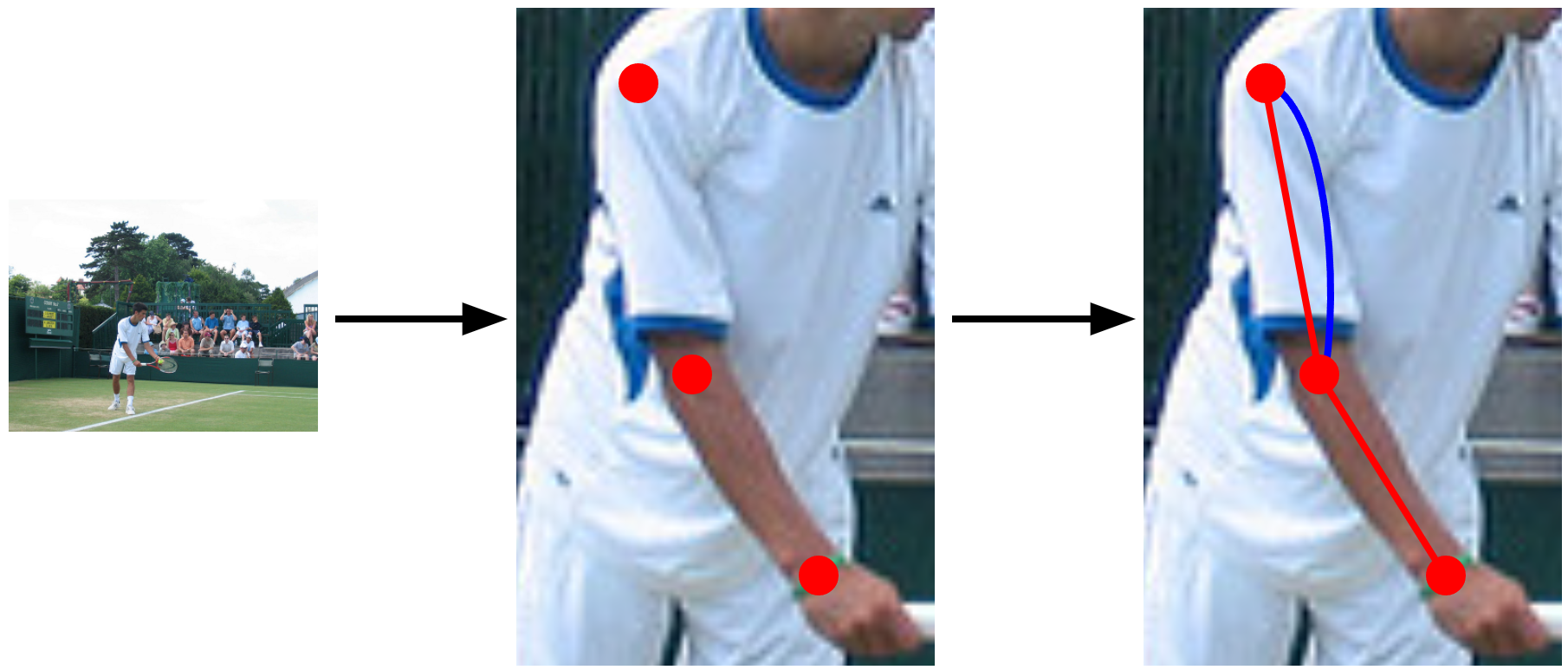
이처럼 영상/이미지 내에서 사람의 관절들(joints)을 찾는다면, 각 관절들을 직선으로 연결하여 사람의 자세를 추정할 수 있을 것입니다.
즉, Human Pose Estimation의 주된 목적은 영상/이미지 내에서 사람의 관절들(joints)을 찾는 것임을 알 수 있습니다.

Define Joints : COCO vs. MPII
앞에서 Human Pose Estimation은 관절들(joints)을 찾는 분야임을 설명했는데,
그렇다면 관절들(joints)을 어떻게 정의하면 좋을까요?
개인마다 생각하는 관절의 종류가 다르겠지만, 일반적으로 COCO 데이터셋 정의 방식과 MPII 데이터셋 정의 방식의 2가지 표현 방법이 있습니다.

COCO와 MPII는 Human Pose Estimation 분야에서 학습 및 평가를 위해 사용되는 데이터셋입니다.
두 데이터셋은 공통적으로 팔과 다리의 관절을 포함하고 있습니다.
그러나 MPII 데이터셋은 얼굴에서 머리 윗부분을 관절로 포함되어 있지만,
COCO 데이터셋은 얼굴에서 눈, 코, 귀 부분을 관절로 포함되어 있습니다.
또한 COCO는 가슴(chest) 부분을 관절로 포함되어 있지 않지만, MPII는 포함되어 있습니다.
COCO 데이터셋 정의 방식은 관절의 총 개수가 18개이고, MPII 데이터셋 정의 방식은 관절의 총 개수가 15개 입니다.
그러나 대부분의 논문들을 살펴보면 Background를 제외한 나머지를 GT로 사용하여 관절들을 예측합니다.
Human Pose Estimation을 활용하고자 하는 분야에 따라 COCO 방식을 사용할지, MPII 방식을 사용할지 결정하면 좋을 것 같습니다.
(COCO 데이터셋 : https://cocodataset.org/#home)
(MPII 데이터셋 : http://human-pose.mpi-inf.mpg.de/)
Create GT for Human Pose Estimation
일반적으로 모델을 학습하기 위해서는 그 분야에 맞게 GT를 구성해야 합니다.
Object Detection 같은 경우는 bounding box를 찾는 문제이기 때문에 클래스에 대한 (tlx, tly, brx, bry) 혹은 (cx, cy, w, h)의 형식으로 GT가 구성됩니다.
(tlx:top-left x, brx:bottom-right x, cx:center x, w:width, h:height)
그렇다면 Human Pose Estimation에서 Joint에 대한 GT는 어떻게 구성될까요?

일반적으로 Human Pose Estimation에서는 각 joint마다 heatmap을 생성하여 GT를 정의합니다.
위 그림처럼 왼쪽 이미지에 대한 joint(파란색 점)들이 있을 때, 각 joint에 해당하는 heatmap을 생성하여 이를 GT로 정의합니다.
여기서 heatmap은 주로 2D Gaussian Filter를 이용하여 생성됩니다.
아래 왼쪽 식은 2D Gaussian Filter 식이고, 가운데 표는 Filter의 크기가 5x5일 때의 실제 이미지 상의 부여되는 픽셀 값들을 의미합니다.
오른쪽 그림을 보면 왜 heatmap을 통해 GT를 구성하는지 알 수 있을 것 같네요.
오른쪽 그림과 같이 파란색 점이 실제 joint에 대한 좌표이고,
연두색/주황색 점이 모델 A/B가 예측한 joint라고 가정합시다.
그러면 연두색 점보다 주황색 점이 실제 joint(파란색 점)와 가깝기 때문에 주황색 점의 accuracy가 더 높고 loss는 더 낮아야겠죠?
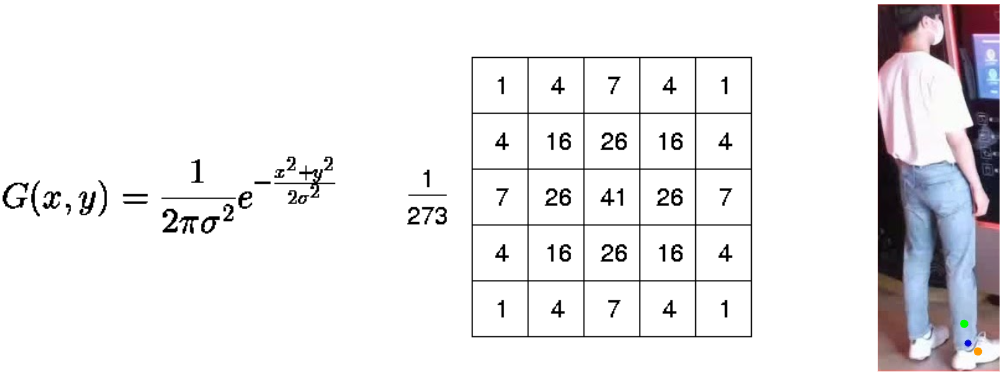
따라서 heatmap을 사용하여 GT를 구성할 경우, 학습할 때마다 점점 더 실제 joint에 가깝게 학습될 것입니다.
MARKANY_둘러보기
