Tree-Base
라이브러리 설치
원핫인코딩을 위해 category_encoders 라이브러리를 설치해줍니다.
!pip install category_encoders
!pip install pandas-profiling==3.1.0
해당 라이브러리 설치 후 런타임 다시 시작 -> 이후 셀 진행
!pip install scikit-learn==1.1.3
!pip install xgboost
!pip install catboost
필수 라이브러리 설치
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import RandomizedSearchCV
from sklearn.pipeline import make_pipeline
from sklearn.ensemble import RandomForestClassifier
from category_encoders import OrdinalEncoder
from sklearn.impute import SimpleImputer
from scipy.stats import randint, uniform
from sklearn.metrics import accuracy_score, precision_score, recall_score, confusion_matrix
import warnings
warnings.filterwarnings(action='ignore')
데이터 불러오기
naver_shop = pd.read_csv('https://raw.githubusercontent.com/yskim1230/AIB_Section2-PJT_Modeling-Plan/main/naver_shop_FE_comp.csv')
naver_shop.info()

Target 변수는 Price_range 컬럼
target ='Price_range'
import seaborn as sns
import matplotlib.pyplot as plt
fig = sns.displot(naver_shop[target])
fig.fig.set_size_inches(10,4)
naver_shop[target].value_counts(normalize=True)
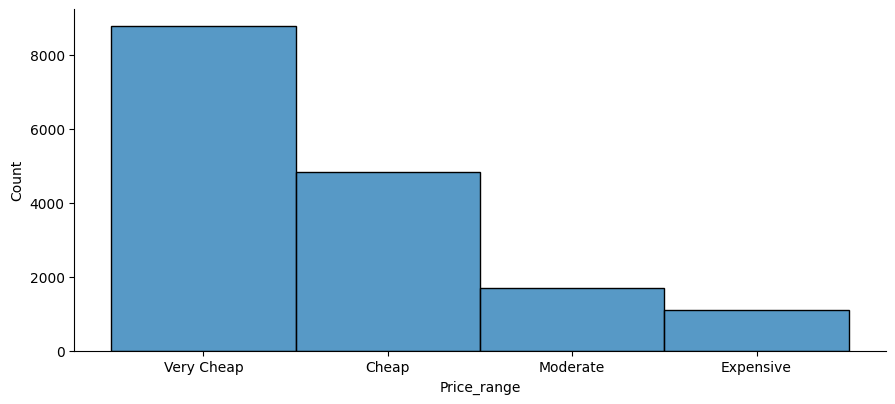

타겟에 불균형이 어느정도 있지만 감수할 만한 부분이라 생각했다.
* 기준모델의 평가지표
major = naver_shop[target].mode()[0]
pred = [major] * len(naver_shop[target])
from sklearn.metrics import f1_score
import sklearn.metrics as metricsprint("training accuracy: ", metrics.f1_score(naver_shop[target], pred,average ='weighted'))
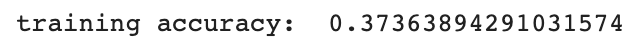
데이터 셋 나누기
from sklearn.model_selection import train_test_split
train, test = train_test_split(naver_shop, train_size=0.7, stratify=naver_shop[target], random_state=2)
train.shape,test.shape
타겟나누는 함수 작성
def divide_data(df):
X = df.drop(['Price_range', 'Low price'], axis = 1)
y = df['Price_range']
return X, y
train, test = train_test_split(naver_shop, train_size=0.7, stratify=naver_shop[target], random_state=2)
X_train, y_train = divide_data(train)
X_test, y_test = divide_data(test)
print(X_train.shape,y_train.shape)
print(X_test.shape,y_test.shape)
def get_clf_eval(y_test, pred):
#오차행렬(confusion matrix)을 구합니다
confusion = confusion_matrix(y_test, pred)
#정확도(accuracy)를 구합니다
accuracy = accuracy_score(y_test, pred)
#정밀도(precision)를 구합니다. average='weighted'로 설정하면
#다중 클래스 분류일 경우 각 클래스별로 가중치를 적용한 평균 값을 계산합니다.
precision = precision_score(y_test, pred,average='weighted')
#재현율(recall)를 구합니다. average='weighted'로 설정하면
#다중 클래스 분류일 경우 각 클래스별로 가중치를 적용한 평균 값을 계산합니다.
recall = recall_score(y_test, pred,average='weighted')
#오차행렬, 정확도, 정밀도, 재현율을 출력합니다
print('Confusion Matrix')
print(confusion)
print('정확도:{}, 정밀도:{}, 재현율:{}'.format(accuracy, precision, recall))
#train test 셋 분리
train, test = train_test_split(naver_shop, train_size=0.7, stratify=naver_shop[target], random_state=2)
X_train, y_train = divide_data(train)
X_test, y_test = divide_data(test)
1. Randomforest 적용 함수 구현
def fit_rf(X_train, y_train): pipe = make_pipeline( OrdinalEncoder(), SimpleImputer(), RandomForestClassifier(class_weight = "balanced", random_state=42) ) dists = { 'randomforestclassifier__max_depth' : randint(1, 30), 'randomforestclassifier__max_features' : randint(1, 10), 'randomforestclassifier__n_estimators' : randint(1, 300) } clf = RandomizedSearchCV( pipe, param_distributions=dists, n_iter=10, cv=5, scoring='f1', verbose=1, n_jobs=-1, random_state = 42 ) clf.fit(X_train, y_train) print("Optimal Hyperparameter:", clf.best_params_) return clf
* 모델 적용
clf_rf = fit_rf(X_train, y_train)

pred_rf = clf_rf.predict(X_test)
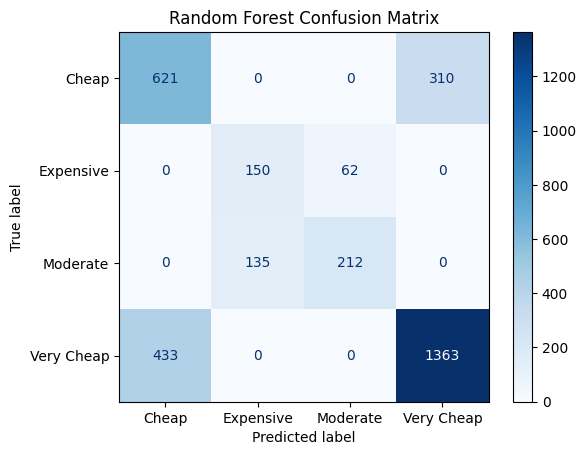
get_clf_eval(y_test, pred_rf)
f1 = f1_score(y_test, pred_rf,average='weighted')
print('f1 score :', f1)

* 랜덤 포레스트 모델의 혼동 행렬을 그래프
from sklearn.metrics import plot_confusion_matrix
plot_confusion_matrix(clf_rf, X_test, y_test, cmap=plt.cm.Blues)
plt.title('Random Forest Confusion Matrix')
plt.show()
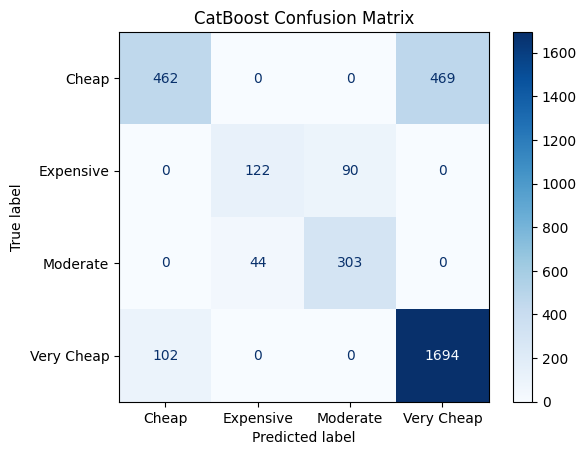
2. CatBoostClassifier
from catboost import CatBoostClassifier
def fit_cb(X_train, y_train):
pipe = make_pipeline(
OrdinalEncoder(),
SimpleImputer(),
CatBoostClassifier(loss_function = 'MultiClass',class_weights=[0.619,0.818,0.916,0.953],early_stopping_rounds=35,verbose=100)
)
pipe.fit(X_train, y_train)
return pipe
clf_cb = fit_cb(X_train, y_train)
pred_cb = clf_cb.predict(X_test)
get_clf_eval(y_test, pred_cb)
f1 = f1_score(y_test, pred_cb,average='weighted')
print('f1 score :', f1)

from sklearn.metrics import plot_confusion_matrix
plot_confusion_matrix(clf_cb, X_test, y_test, cmap=plt.cm.Blues)
plt.title('CatBoost Confusion Matrix')
plt.show()
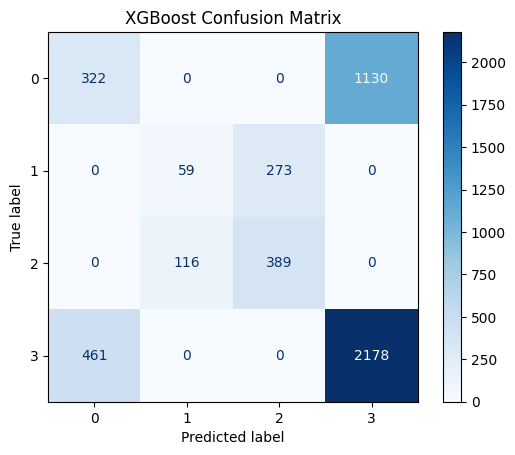
3. XGBClassifier
train, test = train_test_split(naver_shop, train_size=0.7, stratify=naver_shop[target], random_state=2)
X_train, y_train = divide_data(train)
X_test, y_test = divide_data(test)
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y_train_encoded = le.fit_transform(y_train)
y_test_encoded = le.fit_transform(y_test)
from sklearn.utils import class_weight
from xgboost import XGBClassifier
def fit_xg(X_train, y_train):
processor = make_pipeline(
OrdinalEncoder(),
SimpleImputer(strategy='median')
)
X_train_processed = processor.fit_transform(X_train)
classes_weights = class_weight.compute_sample_weight(
class_weight='balanced',
y=y_train_encoded
)
clf = XGBClassifier(eval_metric='mlogloss',max_depth = 21,n_estimators = 190)
clf.fit(X_train_processed, y_train_encoded, sample_weight=classes_weights)
return clfclf_xg = fit_xg(X_train, y_train)
processor = make_pipeline(
OrdinalEncoder(),
SimpleImputer(strategy='median')
)
X_test_processed = processor.fit_transform(X_test)
pred_xg = clf_xg.predict(X_test_processed)
get_clf_eval(y_test_encoded, pred_xg)
f1 = f1_score(y_test_encoded, pred_xg,average='weighted')
print('f1 score :', f1)

from sklearn.metrics import plot_confusion_matrix
plot_confusion_matrix(clf_xg, X_test_processed, y_test_encoded, cmap=plt.cm.Blues)
plt.title('XGBoost Confusion Matrix')
plt.show()
4. baseline / Randomforest / CatBoost / XGB
import seaborn as sns
import matplotlib.pyplot as plt
df_by_group = pd.DataFrame(columns=['model 1', 'f1'])
data_to_insert = {'model 1': 'baseline','f1': 0.37363}
df_by_group = df_by_group.append(data_to_insert, ignore_index=True)
data_to_insert = {'model 1': 'RandomForestClassifier','f1': 0.69460}
df_by_group = df_by_group.append(data_to_insert, ignore_index=True)
data_to_insert = {'model 1': 'CatBoostClassifier','f1': 0.67849}
df_by_group = df_by_group.append(data_to_insert, ignore_index=True)
data_to_insert = {'model 1': 'XGBClassifier','f1': 0.56114}
df_by_group = df_by_group.append(data_to_insert, ignore_index=True)
df_by_group.plot.bar(x='model 1',y='f1',rot=0)
plt.xticks(rotation=45)
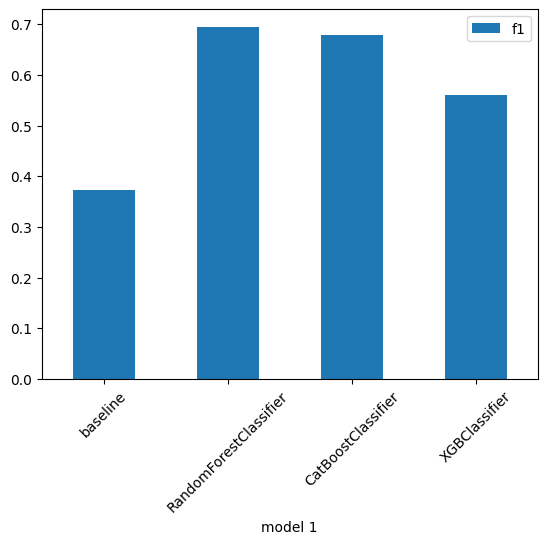
RandomForest가 약간 앞서는 것으로 확인.
5. RandomForest 추가 검증
train, test = train_test_split(naver_shop, train_size=0.7, stratify=naver_shop[target], random_state=2)
X_train, y_train = divide_data(train)
X_test, y_test = divide_data(test)
from sklearn.model_selection import cross_val_score
from sklearn.metrics import make_scorer
(참고) warning 제거를 위한 코드
np.seterr(divide='ignore', invalid='ignore')
pipe = make_pipeline(
OrdinalEncoder(),
SimpleImputer(strategy='mean'),
RandomForestClassifier(n_estimators=100, random_state=42)
)
5-fold 교차검증을 수행합니다.
k = 5
scores = cross_val_score(pipe, X_train, y_train, cv=k, scoring=make_scorer(f1_score,average ='weighted'))
print(f'f1 ({k} folds):', scores)
'''
f1 (5 folds): [0.64729627 0.6919973 0.68725693 0.68272027 0.69757024]
'''
scores.mean()
'''
0.6813682010473587
'''
scores.std()
'''
0.017736321340533073
'''
import seaborn as sns
import matplotlib.pyplot as plt
data = {'fold1': ['fold1', 'fold2', 'fold3', 'fold4', 'fold5'], 'f1': [0.64729627 ,0.6919973, 0.68725693, 0.68272027, 0.69757024]}
df_by_fold = pd.DataFrame(data=data)
df_by_fold.plot.bar(x='fold1',y='f1',rot=0)
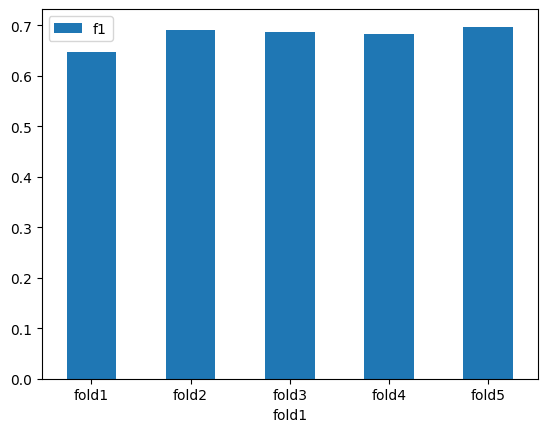
scores.mean()은 교차 검증의 k개 fold에서 얻은 성능 점수들의 평균이고,
scores.std()는 해당 성능 점수들의 표준편차입니다.
scores.std()가 낮다는 것은 성능 점수들이 평균적으로 가까이 분포해 있다는 것을 의미합니다.
이 경우, 모델의 성능이 안정적이며 fold간 성능 차이가 크지 않아 더 일반화된 모델일 가능성이 높습니다.
하지만, scores.std()가 낮다고 해서 반드시 샘플수가 충분하다는 것을 보장하지는 않습니다. 모델의 복잡도나 학습 데이터의 특성에 따라 적은 수의 샘플에서도 scores.std()가 낮을 수 있습니다. 따라서, 모델 평가시 scores.mean()과 scores.std() 모두를 고려하여 모델의 성능을 평가해야 합니다.
5-fold 교차검증 결과를 보면, 5개의 fold에서 모두 비슷한 f1 score를 얻었으며, 평균 f1 score는 대략 0.68 정도로 나타납니다. 따라서, 이 모델은 일반화 성능이 괜찮은 것으로 판단할 수 있습니다
6. 특성 중요도 파악
importances = resclf.feature_importances
feat_importances = pd.Series(importances, index=X_train.columns)
feat_importances.nlargest(10).plot(kind='barh', figsize=(8,6))
plt.title('Top 10 Feature Importances')
plt.xlabel('Relative Importance')
plt.show()
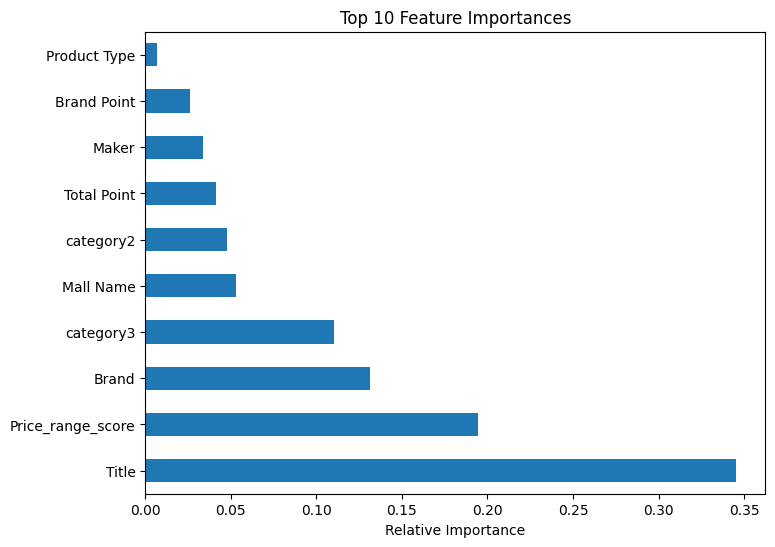
여기서 Title 과 Price_range_score가 가격대에 영향을 미친다고 나왔으나,
이는 잘못된 설정으로 인한 결과이다.
Title(상품명) 의 경우 카디널리티가 높아 발생한 문제이며, Price_range_score는 타겟인Price_range를 기반으로 만들어져 데이터 누수 현상이 발견됐다고 할 수있다.
위 두 컬럼을 제외하고 다시 모델링을 진행하면 다른 결과가 나오지 않을까 싶다.
