EBCLR
Contrastive learning은 Deep Neural Networks (DNNs)를 훈련함으로써 visual representation을 학습하는 방법이다. 일반적으로 positive pairs (transformations of the same image)들의 유사도는 증가시키고 negative pairs (transformations of different images)들의 유사도는 감소시킨다.
이 논문에서는 EBM(Energy-based Models)과 contrastive learning을 결합하여 the power of generative learning을 활용한다. EBCLR은 이론적으로 joint distribution of positive pairs를 학습하는 것으로 해석할 수 있고, MNIST, Fashion MNIST, CIFAR-10 및 CIFAR100과 같은 중소 규모 데이터 셋에서 좋은 결과를 얻는다.
EBM에 대해 모르는 사람이라면, Energy-based Model이 가지고 있는 power of generative learning이라는 뜻의 의미를 제대로 해석하기가 어렵다. Energy-based model을 아주 간단하게 설명해보면, 어떤 에너지 함수를 통해 두 변수 X,Y를 scalar로 매핑하는 모델이며, 이 때 옳은 페어인 (X,Y)에 대해서 에너지 값이 낮아지도록 model을 만들어 낸다고 생각하면 될 것이다. 마치 머신러닝 모델이 어떤 입력을 받아 모든 y의 logits값중에 가장 높은 값이 정답 class라고 예측하듯, EBM은 어떤 입력 joint distribution p(x,y) 혹은 p(x)에 대한 옳은 확률값을 내뱉도록 하는 모델링 방법이라고 이해하면 되지 않을까 싶다.
특히, EBCLR은 SimCLR과 MoCo v2에 비해 4배에서 20배의 가속도를 보인다.
더불어, 하나의 positive pair당 254개의 negative pairs(batch 256)로 훈련된 SimCLR과 비교하여 30개의 negative pairs(batch 32)로 거의 동일한 성능을 달성하여 적은 수의 네거티브 페어에 대한 EBCLR의 우수성을 입증했다. EBCLR은 합리적인 성능을 달성하기 위해 다른 방법들에 비해 적은 수의 negative pair가 필요한 방법이다.
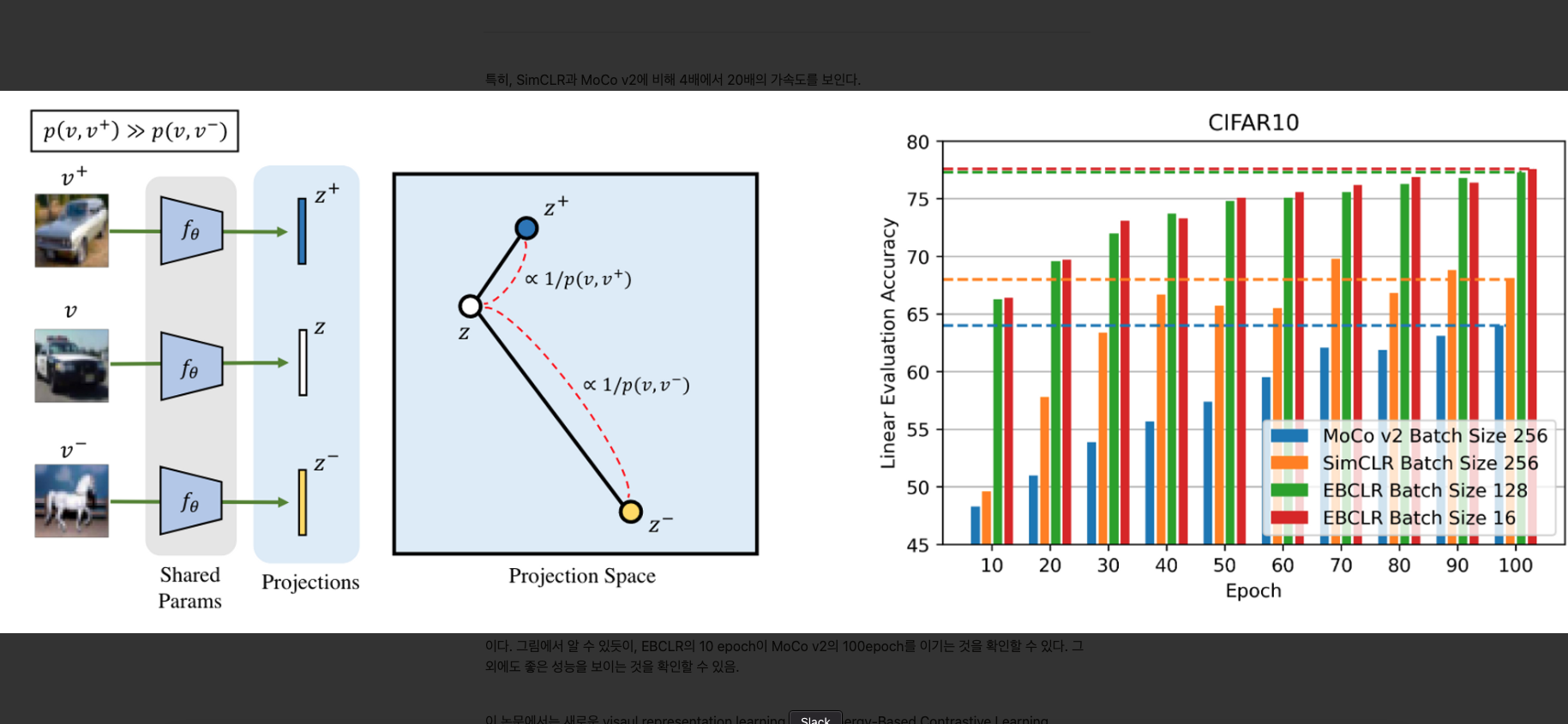
왼쪽 그림이 EBCLR을 잘 나타낸 그림이다. 여기서 ∝ 가 의미하는 것은 “is a monotonically increasing function of”이다. 여기서 논문의 저자들은 joint distribution p(v,v′)를 사용하는데, 이것은 positive pairs의 joint distribution으로 이미지들의 semantic similarity를 측정한 것이다. 특별히, p(v,v′)는 v와 v′가 semantically similar할 때 높게 측정되고, 아닐때 낮게 측정된다. DNN fθ는 Projection space에서 보이는 거리로 훈련이 되는데, 이 거리가 1/p(v,v′) 으로부터 조절된다.
오른쪽 그림의 경우 EBCLR과 SimCLR, MoCo v2에서의 CIFAR10에 대한 linear evaluation accuracy 결과이다. 그림에서 알 수 있듯이, EBCLR의 10 epoch이 MoCo v2의 100epoch를 이기는 것을 확인할 수 있다. 그 외에도 좋은 성능을 보이는 것을 확인할 수 있음.
이 논문에서는 새로운 visaul representation learning 방법인 Energy-Based Contrastive Learning (EBCLR)방법을 제안한다. 이 방법은 leverages the power of geneartive learning by combining contrastive learning with energy-based models(EBMs).
EBCLR은 Contrastive learning loss를 generative loss로 보완하며, 이것은 positive pairs의 joint distribution 을 학습시키는 것으로 해석할 수 있다. 이를 통해, 기존의 Contrastive learning loss가 EBCLR의 특수한 경우임을 증명한다. 그리고 EBM은 SGLD에 의존하기 때문에, 훈련이 어려운 것으로 알려져 있지만, 논문에서는 특별한 SGLD를 제안하여 이를 극복하였다.
EBCLR을 이해하기 위해서, EBM과 contrastive learning, generative model에 대해 간략하게 설명한다.
Contrastive Learning
한 배치의 이미지 {xn}n=1N 와 두개의 transformations t,t′이 주어졌을 때, contrastive learning methods는 먼저 각 instance xn에 대하여 이미지를 두개의 view로 만들어낸다. vn=t(xn),vn′=t′(xn). 여기서 만약 n=m인 경우, pair (vn,vm′)은 positive pair로 불리고 n=m인 경우는 negative pair로 불린다. DNN fθ가 주어질때, 이 view들은 fθ와 normalizing을 통해 projection space로 embedding된다.
Contrastive methods는 fθ가 positive pair의 projection에 대해서는 일치할 수 있도록 만들며, negative pairs에 대해서는 일치하지 않도록 학습한다. 특히, fθ는 InfoNCE objective를 최대화하기 위해 훈련된다. 훈련이 끝난 뒤에, fθ의 마지막 레이어 혹은 중간 레이어로부터 나오는 outputs들은 downstream task에 이용된다.
Energy-Based Models
scalar값을 가지는 energy function Eθ(v) with parameter θ가 주어졌을 때, energy-based model(EBM)은 다음의 식으로부터 분포가 정의된다.
qθ(v):=Z(θ)1exp{−Eθ(v)}
여기서 Z(θ)는 partition function이며 qθ의 integrates가 1이 되도록 보장해준다. 여기에 필수적으로 energy function의 선택에 대한 아무런 제약이 존재하지 않기 때문에, EBM은 distributions을 모델링하는데 있어서 매우 유연하게 작동한다. 따라서 EBM은 매우 다양한 머신러닝 테스크(차원축소, generative classifier, generating images, 등등)에 사용된다. Wang은 EBM과 InfoNCE사이의 EBM의 generative performance를 향상시키는 연결에 대해 조사했는데, 이 논문에서는 처음으로 EBM을 representation learning을 위한 contrastive learning으로 사용하였다.
target distribution이 주어지면, EBM은 오직 p로부터 샘플링할 때, density qθ에 대해 추정할 수 있다. 이를 가능케하는 한가지 방법은 qθ와 p 사이의 Kullback-Leibler (KL) divergence를 최소화하는 방법이며, p에 대하여, qθ의 log-likelihood의 기댓값을 최대화하는 것이다.
θmaxEp[logqθ(v)].
Stochastic gradient ascent가 이를 해결하기 위해 사용될 수 있다. 특히, paramether θ의 관점에서 log-likelihood의 기댓값의 gradient는 다음과 같다.
∇θEp[logqθ(v)]=Eqθ[∇θEθ(v)]−Ep[∇θEθ(v)].(3)
유도
logpθ(x)=logZ(θ)exp(−Eθ(x))=log[exp(−Eθ(x))]−log[Z(θ)]=−logZ(θ)−Eθ(x)
∇θlogpθ(x)=−Z(θ)1∇θZ(θ)−∇θEθ(x)=−Z(θ)1∇θ∫xexp(−Eθ(x))−∇θEθ(x)=Z(θ)1∫x′exp(−Eθ(x′))∇θEθ(x′)−∇θEθ(x)=∫x′Z(θ)exp(−Eθ(x′))∇θEθ(x′)−∇θEθ(x)=Epθ(x′)[∇θEθ(x′)]−∇θEθ(x)
따라서, θ를 업데이트 하는 것은 qθ로 부터 샘플링된 에너지에 대해 pulling up하는 것이고 p로부터 샘플링된 energy에 대해서는 pushing down하는 것이다. 이러한 optimization methods는 contrastive divergence로 잘 알려져있다.
위 식에서 두번째 있는 term (−Ep[∇θEθ(v)])는 p로부터 샘플함으로써 쉽게 계산될 수 있는 반면에, 첫번 째 텀은 (Eqθ[∇θEθ(v)])는 qθ로 부터 샘플이 필요하다. 이전 works들은 Stochastic Gradient Langevin Dynamic을 통해 qθ로 부터 샘플을 생성해준다. 특히, some proposal distribution q0로부터의 하나의 샘플 v0이 주어질때,
vt+1=vt−2αt∇vtEθ(vt)+ϵt,ϵt∼N(0,σt2)
는 {vt}의 시퀀스가 qθ로부터 나온 샘플로 converge함을 guarantee한다. (guarantees that the sequence {vt} converges to a sample from qθ assuming {αt} decays at a polynomial rate )
무슨 말이냐면, EBM은 위 생성된 샘플이 qθ에서 생성된 샘플이라는 것을 guarantee하는 방향으로 생성된다는 의미이다. 위의 에너지함수 Eθ(vt)의 vt에 대한 미분값은 위 에너지 함수가 작아지는 방향으로 이미지를 만든다는 의미인데, 이 때 에너지함수가 작아진다는 것은 샘플 vt가 분포 qθ에서 나올 확률을 높여준다는 것을 의미한다. 즉, step이 무한이 진행된다면 {vt}의 시퀀스가 qθ로부터 나온 샘플임을 guarantee한다.
하지만, SGLD는 proposal distribution 로부터 나온 샘플이 target distribution로 converge할 때 까지 엄청나게 많은 step 수를 필요로 한다. 이것은 현실적으로 불가능하고, 오직 constant step size, i.e. αt=α 와 constant noise variance σt=σ2 가 사용된다. 게다가 Yang and Ji는 SGLD가 EBM을 훈련도중 발산하도록 하는 pixel값을 생성한다고 주장한다. 따라서 그들은 proximal SGLD라는 방법으로 gradient values를 threshold δ>0을 갖는 특정 구간 [−δ,δ]로 clamp해줌으로써 EBM의 발산을 막는다. 따라서, update equation은
vt+1=vt−α⋅clamp{∇vEθ(vt),δ}+ϵ(5)
for t=0,...T−1, where ϵ∼N(0,σ2) and clamp{⋅,δ} clamps each element of the input vector into [−δ,δ].
본 논문에서는 추가적인 수정을 통해 SGLD를 EBCLR에 더욱 가속해서 수렴하도록 만들었다.
Theory
Let D be a distribution of images and T a distribution of stochastic image transformations. Given x∼D and i.i.d. t,t′∼T, our goal is to approximate the joint distribution of the views
우선 D라는 image distribution과 T라는 image transformationdl 있다고 생각해보자. 주어진 분포 D에서의 샘플 x,x∼D와 i.i.d t,t′∼T, 에서 우리의 목표는 model distribution qθ를 사용해 실제 joint distribution p인 아래 분포를 잘 근사하는 것이다.
p(v,v′),wherev=t(x),v′=t′(x)
using the model distribution
qθ(v,v′):=Z(θ)1exp{−∣∣z−z′∣∣2/τ}.(6)
where Z(θ) is a normalization constant, τ>0 is a temperature hyper-parameter, and z and z′ are projections computed by passing the views v and v′ through the DNN fθ and then normalizing to have unit norm. We now explain the intuitive meaning of matching qθ to p.
본 논문의 키 아이디어는 p(v,v′)을 v와 v′의 semantic similarity를 측정하기 위해 사용한다는 것이다. 만약에 두 이미지 v,v′이 semantically 비슷하다면, 그것들은 비슷한 이미지의 transformation일 가능성이 높다는 것을 의미할 것이다. 따라서 p(v,v′)은 semantically 비슷한 v,v′에서는 높고, 다른 경우에는 낮다.
qθ가 p를 아주 잘 근사한다고 가정하자. 만약 식 6번 처럼 식을 만들어 내고 ∣∣z−z′∣∣을 풀게 한다면, z와 z′ 사이의 거리는 monotone increasing function of 1/p(v,v′)이 될 것이다. 이 1/p(v,v′)은 v,v′의 semantic similarity의 inverse이다. 따라서 semantically 비슷한 이미지들은 가까운 projections을 가지고, 다른 이미지들은 먼 projection을 가진다. 이것은 Figure.1을 보면 알 수 있다.
To approximate p using qθ, we train fθ to maximize the expected log-likelihood of qθ under p:
θmaxEp[logqθ(v,v′)](7)
In order to solve this problem with stochastic gradient ascent, we could naively extend (3) to the setting of joint distributions to obtain the following result.
Proposition 1
Proposition 1. The joint distribution (6) can be formulated as an EBM
qθ(v,v′):=Z(θ)1exp{−Eθ(z,z′)},Eθ(v,v′)=∣∣z−z′∣∣2/τ
and the gradient of the objective of (7) is given by
∇θEp[logqθ(v,v′)]=Eqθ[∇θEθ(v,v′)]−Ep[∇θEθ(v,v′)].(9)
However, computing the first expectation in (9) requires sampling pairs of views (v,v′) from qθ(v,v′) via SGLD, which could be expensive. To avert this problem, we use Bayes’rule to decompose
모델에서 샘플링 된 데이터에 대한 에너지함수의 기댓값인 Eqθ[∇θEθ(v,v′)] 는 모델 qθ에서 샘플링 해야 된다는 치명적인 문제가 발생한다. 이러한 문제가 발생하지않게 하기 위해 베이즈룰을 이용해 위 식을 decompose해주면 아래와 같다.
Ep[logqθ(v,v′)]=Ep[logqθ(v′∣v)]+Ep[logqθ(v)]whereqθ(v)=∫qθ(v,v′)dv′.
위 식에서 우변의 첫번째와 두번째 term들은 각각 discriminative와 generative term을 나타낸다.
the first and second terms at the RHS will be referred to as discriminative and generative terms, respectively, throughout the paper. A similar decomposition was used by Grathwohl et al. in the setting of learning generative classifiers.
Furthermore, we add a hyper-parameter λ to balance the strength of the disciriminative term and the generative term. The advantage of this modification will be discussed in Section 4.3. This yields our EBCLR objective
L(θ):=Ep[logqθ(v′∣v)]+λEp[logqθ(v)].(11)
The discriminative term can be easily differentiated since the partition function Z(θ) cancels out when qθ(v,v′) is divided by qθ(v). However, the generative term still contains Z(θ). We now present our key result, which is used to maximize (11). The proof is deferred to Appendix C.1.
What your classifier is hiding
최근 머신러닝에서, K class를 갖는 분류 문제는 전형적으로 각각의 데이터 포인트 x∈RD를 K real-valued numbers known as logits로 맵핑해주는 parametric function, fθ:RD→RK를 사용하여 푸는 것이다. 이러한 logits는 categorical distribution을 parameterize하는 것으로 사용되는데, 이 때 Softmax transfer function을 사용한다.
pθ(y∣x)=∑y′exp(fθ(x)[y′])exp(fθ(x)[y]),(4)
여기서 fθ(x)[y] 는 fθ(x)의 yth index를 가리키고, logit은 yth class label을 의미한다.
논문의 저자의 주요한 관점은 다음과 같다.
fθ로 부터 얻은 logit을 p(x,y)와 p(x)로 약간 재해석할 수 있다는 것이다. fθ를 변화시키지 않고, logits을 재활용 하여 joint distribution of data point x and labels y 에 기반한 energy based model을 만들어낼 수 있다 :
pθ(x,y)=Z(θ)exp(fθ(x)[y]),(5)
여기서 Z(θ)는 unknown normalizing constant이고, Eθ(x,y)=−fθ(x)[y]이다.
y를 marginalizing함으로써, unnormalized density model x를 얻어낼 수 있다.
pθ(x)=y∑pθ(x,y)=Z(θ)∑yexp(fθ(x)[y]),(6)
여기서 아무 분류기의 logtis의 LogSumExp(⋅)은 x data point에서 energy function으로 정의되기 위해 재사용될 수 있다.
Eθ(x)=−LogSumExpy(fθ(x)[y])=−logy∑exp(fθ(x)[y]).(7)
이게 무슨 말이냐면, 위에 pθ(x)에서의 Energy function Eθ(x)가 energy based model 기준에서 −LogSumExp가 되어야 pθ(x)가 만들어진다는 의미이다.
pθ(x)=Z(θ)exp(−Eθ(x))
logpθ(x)=−logZ(θ)−Eθ(x)∇θlogpθ(x)=−Z(θ)1∇θZ(θ)−∇θEθ(x)=−Z(θ)1∇θ∫exp{−Eθ(x)}dx−∇θEθ(x)=−Z(θ)1∫{−∇θEθ(x)}⋅exp{−Eθ(x)}dx−∇θEθ(x)=∫{∇θEθ(x)}⋅Z(θ)1exp{−Eθ(x)}dx−∇θEθ(x)=∫{∇θEθ(x)}⋅pθ(x)dx−∇θEθ(x)=Epθ(x′)[∇θEθ(x)]−∇θEθ(x).
qθ(v):=Z(θ)1exp{−Eθ(v)},Eθ(v):=−log∫e∣∣z−z′∣∣2/τdv′(12)
Z(θ)1exp{−Eθ(v)}=Z(θ)1∫e−∣∣z−z′∣∣2/τdv′=∫Z(θ)1e−∣∣z−z′∣∣2/τdv′=∫qθ(v,v′)dv′=qθ(v)
qθ(v,v′):=Z(θ)1exp{−∣∣z−z′∣∣2/τ}.(6)
logqθ(v)=−logZ(θ)−Eθ(v)
∇θlogqθ(v)=−Z(θ)1∇θZ(θ)−∇θEθ(v)=−Z(θ)1∇θ∫exp{−Eθ(v)}dv−∇θEθ(v)=−Z(θ)1∫∇θexp{−Eθ(v)}dv−∇θEθ(v)=−Z(θ)1∫{−∇θEθ(v)}⋅exp{−Eθ(v)}dv−∇θEθ(v)=∫{∇θEθ(v)}⋅Z(θ)1exp{−Eθ(v)}dv−∇θEθ(v)=∫{∇θEθ(v)}⋅qθ(v)dv−∇θEθ(v)=Eqθ[∇θEθ(v)]−∇θEθ(v).
where Z(θ) is the partition function in (6), and the gradient of the generative term is given by
∇θEp[logqθ(v)]=Eqθ(v)[∇θEθ(v)]−Ep[∇θEθ(v)].(13)
Thus, the gradient of the EBCLR objective(14) is
∇θL(θ)=Ep[∇θlogqθ(v′∣v)]+λEqθ(v)[∇θEθ(v)]−λEp[∇θEθ(v)].(14)
Theorem 2 suggests that the EBM for the joint distribution can be learned by computing the gradients of the discriminative term and the EBM for the marginal distribution. Moreover, we only need to sample v from qθ(v) to compute the second expectation in (14).
Approximating the EBCLR Objective
L(θ):=Ep[logqθ(v′∣v)]+λEp[logqθ(v)].(11)
To implement EBCLR, we need to approximate expectations in (11) with their empirical means.
For a given batch of images {xn}n=1N and two image transformations t,t′, contrastive learning methods first create two views vn=t(xn),vn′=t′(xn) of each instance xn.
Suppose samples {(vn,vn′)}n=1N from p(v,v′) are given, and let {(zn,zn′)}n=1N be the corresponding projections. As the learning goal is to make qθ(vn,vn′) approximate the joint probability density function p(vn,vn′), the empirical mean qθ^(vn) can be defined as:
qθ^(vn)=N′1vm′:vm′=vn∑qθ(vn,vm′)(15)
where the sum is over the collection of vm′ defined as
{vm′:vm′=vn}:={vk}k=1N∪{vk′}k=1N−{vn}
and N′:=∣{vm′:vm′=vn}∣=2N−1. One could also use a simpler form of the empirical mean :
qθ^(vn)=N1m=1∑Nqθ(vn,vm′)(17)
L(θ):=Ep[logqθ(v′∣v)]+λEp[logqθ(v)].(11)
Similarly, qθ(v′∣v) in (11), which should approximate the conditional probability density p(v′∣v), can be represented in terms of qθ(vn,vn′). Specifically, we have
qθ(vn′∣vn)≃qθ^(vn)qθ(vn,vn′)=N′1∑vm′:vm′=vnqθ(vn,vm′)qθ(vn,vn′)=N′1∑vm′:vm′=vne−∣∣zn−zm′∣∣2/τe−∣∣zn−zm′∣∣2/τ
It is then immediately apparent that the empirical form of the discriminative term using (18) is a particular instance of the contrastive learning objective such as InfoNCE and SimCLR. Hence, EBCLR can be interpreted as complementing contrastive learning with a generative term defined by an EBM.
For the second term, we use the simpler form of the empirical mean in (17):
qθ^(vn)=N1m=1∑Nqθ(vn,vm′)=Z(θ)1⋅N1m=1∑Nexp{−∣∣zn−zm′∣∣2/τ}
We could also use (15) as the empirical mean, but either choice showed identical performance (see Appendix E.3.). So, we have found (15) to be not worth the additional complexity, and have resorted to the simpler approximation (17) instead. (17이 더 간단)
Eθ(v;{vm′}m=1N):=−log(m=1∑Ne−∣∣z−zm′∣∣2/τ).(20)
Modifications to SGLD
∇θL(θ)=Ep[∇θlogqθ(v′∣v)]+λEqθ(v)[∇θEθ(v)]−λEp[∇θEθ(v)].(14)
Theorem 2에 따르면, 식 14에서 두번째 기댓값을 계산하기 위해서는 marginal qθ(v)로부터의 샘플이 필요하다. 따라서, 이를 위해 proximal SGLD with the energy function (20)을 적용하면
v~t+1=v~t−α⋅clamp{∇vEθ(v~t;{vm′}m=1N),δ}+ϵ(21)
fort=0,...,T−1,whereϵ∼N(0,σ2)이다. 본 논문에서는 proximal SGLD를 추가적으로 세가지를 수정한다. 지금부터 언급하는 SGLD는 아래의 proximal SGLD를 의미한다
vt+1=vt−α⋅clamp{∇vEθ(vt),δ}+ϵ(5)
첫번째로, 논문에서는 SGLD를 probability ρ를 가지고, 이전 iterations으로 부터 나온 generated samples 으로부터 initialize하고, 다시 SGLD chains를 proposal distribution q0로부터 샘플링된 샘플로부터 reinitialize한다. 이것은 keeping a replay buffer B of SGLD samples from previous iterations를 통해 달성한다. 이러한 기술은 replay buffer를 유지하는 기술로, EBM의 convergence를 가속화시키고 안정화시키기 위해 중요한 기술이며, 이전 works에서 증명되었다.
First, we initialize SGLD from generated samples from previous iterations, and with probability ρ, we reinitialize SGLD chains from samples from a proposal distribution q0. This is achieved by keeping a replay buffer B of SGLD samples from previous iterations. This technique of maintaining a replay buffer has also been used in previous works and has proven to be crucial for stabilizing and accelerating the convergence of EBMs.
Second, the proposal distribution q0 is set to be the data distribution p(v). This choice differs from those of previous works which have either used the uniform distribution or a mixture of Gaussians as the proposal distribution.
Finally, we use multi-stage SGLD (MSGLD), which adaptively controls the magnitude of noise added in SGLD. For each sample v~ in the replay buffer B, we keep a count κv~ of number of times it has been used as the initial point of SGLD. For samples with a low count, we use noise of high variance, and for samples with a high count, we use noise of low variance. Specifically, in (5), we set
σ=σmin+(σmax−σmin)⋅[1−κv~/K]+
where [⋅]+:=max{0,⋅},σmax2andσmin2 are the upper and lower bounds on the noise variance, respectively, and K controls the decay rate of noise variance. The purpose of this technique is to facilitate quick exploration of the modes of qθ and still gurantee SGLD generates samples with sufficiently low energy. The pseudocodes for MSGLD and EBCLR are given in Algorithms 1 and 2, respectively, in Appendix B, and the overall learning flow of EBCLR is described in Figure 2.
