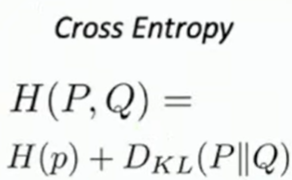CS231N 강의를 기반으로 최신 기술이 추가된 EECS 498-007/598-005 강의가 새롭게 MIT에서 진행되었다.
본 강의는 MIT 홈페이지와 유튜브에 오픈되어 있고,
이 강의를 공부하면서, 다른 사람들도 이해하기 쉽도록 내용을 정리해보려고 한다.
기본 Setting
Dataset은 기본적으로 CIFAR10을 사용한다.
본 강의에서는 10개의 범주가 있다고 가정한다.
CIFAR10의 특징
- 50,000개의 훈련 데이터셋
- 10,000개의 테스트 데이터셋
- 여러가지의 카테고리에 대한 사진들 (Classification에 가장 많이 사용되는 데이터셋 중 하나이다)
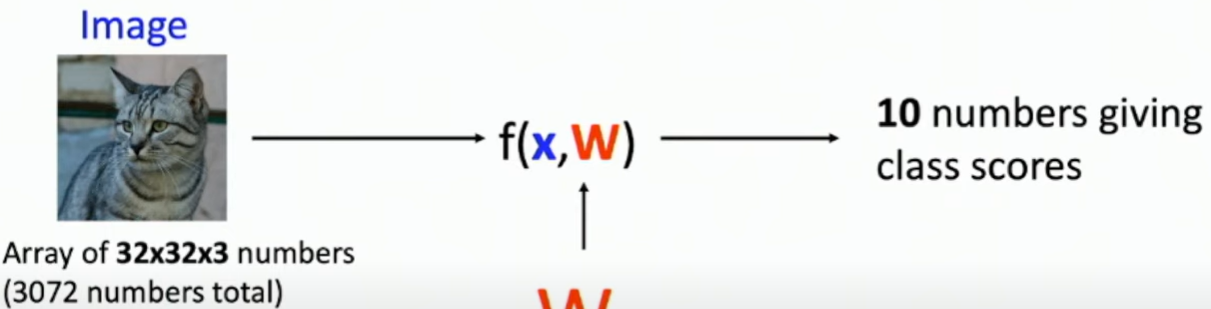
🦊Linear Classifier
input인 이미지를 넣어 f라는 함수를 거치면 10개의 라벨에 대한 이미지의 score 10가지가 출력되는 형식
🦊🦊 f(x, W) 함수
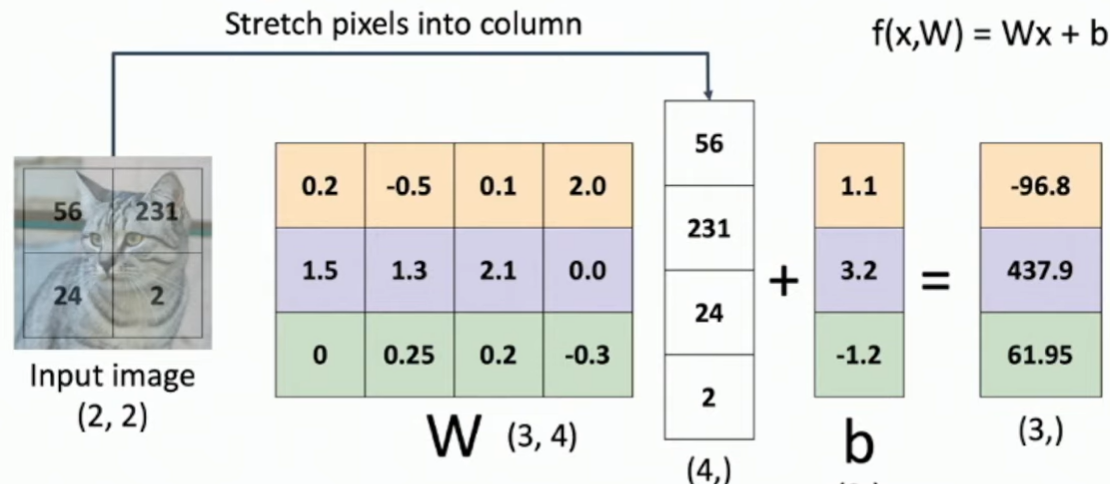
f(x, W) = Wx + b로 각 변수의 의미는 다음과 같다.
- 가중치
W: 말 그대로 가중치이다. 중요한 정도를 의미한다. - bias
b: 학습하려는 10개의 범주 각각에 대한 오프셋을 제공하는 벡터 - 위 식의 의미 : 가중치를 입력값의 pixel에 곱하여 계산 - 즉, 행렬 벡터 곱
🦊🦊 함수 연산 과정
- input image의 vector를 1차원으로 만든다. ⇒ Flatten
- 가중치 행렬 W와 (1)에서의 행렬을 곱한다.
- bias를 더한다.
- 출력값으로 원하는 범주의 개수(=bias의 개수 =4)에 대한 score 값이 출력된다.
그러나 문제! 입력값이 그대로 곱해지기 때문에 값의 의존도가 매우 크다.
예를 들어, 같은 input image의 전체적인 대비가 조금만 바뀌어도, 출력 값이 줄어들 수 있다.
🐨 Linear Classifier 해석
🐨🐨 Visual 관점
각 범주마다 하나의 template을 갖고 있는 특징이 있다.
위 사진에서의 행렬 식을 각 범주마다 계산한다고 보면, 다음과 같다.
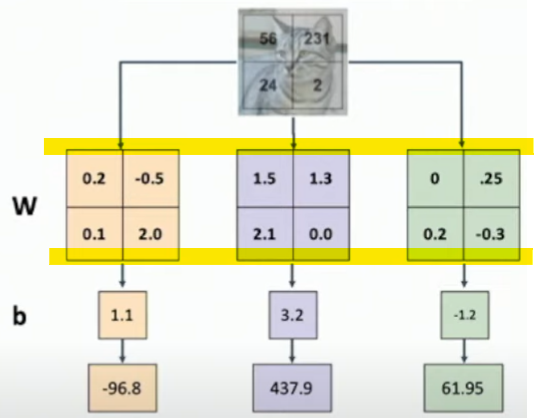
노란색 부분이 template처럼 작용을 하는 것이다.
가중치에 따라 초점을 두고 있는 부분들을 나타낸 이미지가 아래의 이미지이다.

deer의 경우, 초록색을 배경으로 하고 가운데 노란~갈색의 얼룩이 있는 것을 template으로 두고 있다.
그런데 이때, 숲 속에 비슷한 색의 차가 있는 이미지를 입력하면 어떻게 될까? 혼동이 될 것이다.
즉, Linear Classifier는 context 의존도가 높아 자칫하면 분류 실패가 될 수 있다.
🐨🐨 Linear Classifier로 분류할 수 없는 경우
픽셀이 4개라고 가정
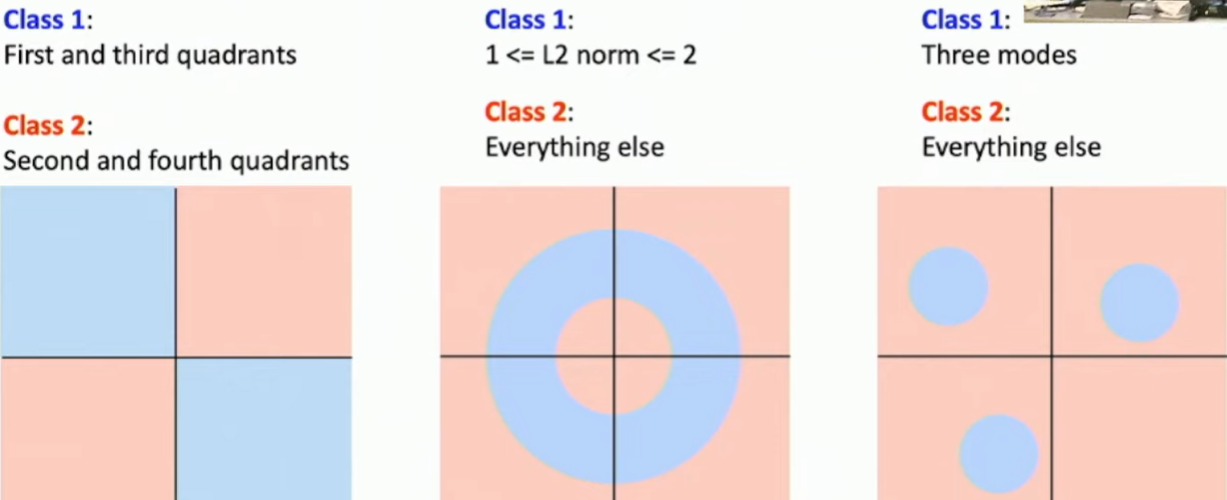
단일선 혹은 단일평면으로 분류할 수 없는 경우를 말하는 것 같다.
🦁 Loss Function, 손실함수
High Loss의 경우 나쁜 Classifier다! 라는 해석으로 Classifier의 성능을 판단한다.

L: 손실함수f(x, W): 예측값y: label (정답)
즉, 각 이미지의 예측값과 정답에 대한 Loss를 측정하여 평균 Loss 값을 내는 것.
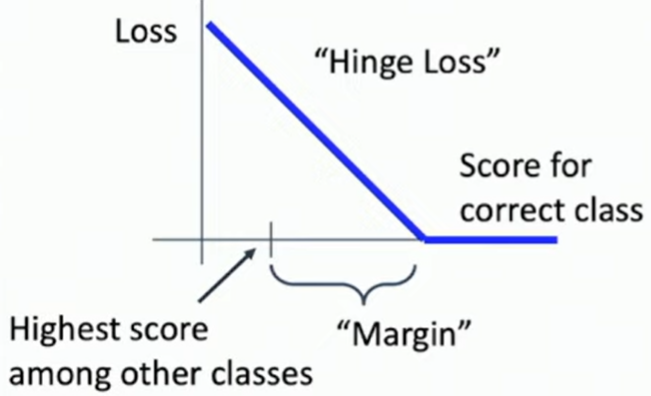
🦁🦁 Multiclass SVM Loss (LF 종류)
정답 클래스가 아닌 다른 클래스에 대한 점수보다 정답 클래스에 할당된 점수가 margin 값 이상 높아야 함.
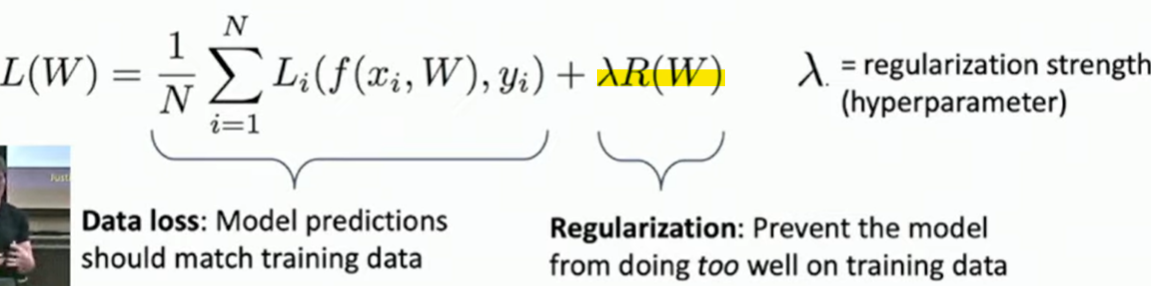
🦁🦁 Regularization, 정규화
- 훈련 데이터셋에 대한 과적합을 줄이기 위함
훈련 데이터셋에서만 잘 작동하는 분류기는 X! 일반화가 필요! - λ를 통해 모델이 얼마나 잘 작동해야하는지 균형을 제어
- 더 단순한 모델을 선호 ⇒ 이를 통해 일반화의 장점을 알 수 있음
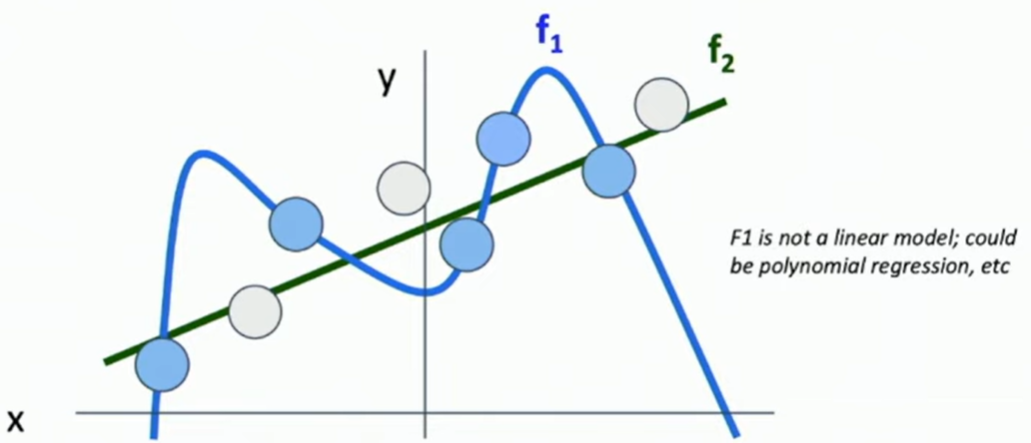
파란색이 훈련 데이터셋일 때, 과적합하게 예측을 하게 되면 f1과 같이 되는데, 보지 않았던 데이터셋 (new dataset)인 흰색 점에 대해서는 완전히 다를 수도 있다는 것을 보여줌.
즉, f2처럼 단순화된, 일반화 된 모델이 더 좋은 성능을 보일 수 있음을 보여줌.
🦁🦁 Cross-Entropy Loss (LF 종류)
모델이 예측한 값에 대한 확률론적 해석(probabilities)을 위함
과정
-
softmax 함수 적용
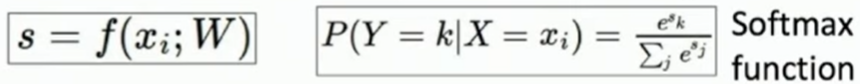
-
올바른 클래스에 대한 마이너스 로그 연산 :: Loss 값
답이 첫 번째 카테고리라고 했을 때 (1)을 통해 나온 값(
0.13)을 마이너스 로그로 취하면 Loss=2.04가 될 것이다.

-
correct 확률 벡터와 비교
첫 번째 카테고리가 정답이므로 correct 확률 벡터의 값은
[1.00, 0.00, 0.00]이다.
이 벡터와[0.13, 0.87, 0.00]을 비교한다.
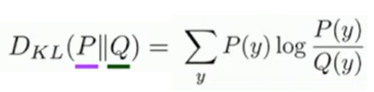
P가 correct 확률 벡터, Q가 예측 확률이다.
이때, cross-entropy 값을 사용한다.