2022.06.21 연구실 공부(PyTorch). 'PyTorch로 시작하는 딥 러닝 입문'< 이 글은 이 책의 내용을 요약 정리한 것임.>(내 저작물이 아니고 저 위 링크에 있는 것이 원본임)
03-01 Linear Regression, 03-02 Autograd
Summary
- Data Definition
- Hypothesis Design
- Compute loss
- Gradient Descent
1. Data Definition
- 예제 : 공부한 시간과 점수에 대한 상관관계
1-1. Training Dataset and Test Dataset
- 만약 어떤 학생이 1시간을 공부하여 2점, 2시간을 공부하여 4점, 3시간을 공부하여 6점이 나왔을때, 내가 4시간을 공부한다면 몇 점을 맞을 수 있을까?
| Hour | Score |
|---|---|
| 1 | 2 |
| 2 | 4 |
| 3 | 6 |
| 4 | ? |
- 이때, 1,2,3 시간을 공부했을 때 각각 2점,4점,6점이 나왔다는 앞선 정보를 이용
- 훈련 데이터셋(training dataset) : 예측을 위해 사용하는 데이터셋
- 테스트 데이터셋(test dataset) : 모델이 얼마나 잘 작동하는지 판별하는 데이터셋
1-2. Training Dataset의 구성
- 모델을 학습시키기 위한 데이터는 파이토치의 텐서의 형태(torch.tensor)를 가져야 함.
- 입력과 출력을 각기 다른 텐서에 저장해야 함.(보편적으로 입력은 x, 출력은 y를 사용)
x_train = torch.FloatTensor([[1], [2], [3]])
y_train = torch.FloatTensor([[2], [4], [6]])- x_train은 공부한 시간, y_train은 그에 맵핑되는 점수를 의미
2. Hypothesis Design
- 머신 러닝에서 식을 세울때 이 식을 가설(Hypothesis)라고 한다.(이 식은 임의로 추측한 것일수도, 경험적으로 아는 식일 수도 있음 -> 맞지 않으면 계속 수정해가면 됨.)
- 선형 회귀란 학습 데이터와 가장 잘 맞는 하나의 직선을 찾는 일이므로 아래와 같은 식 사용
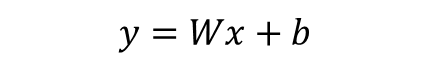
- 가설(Hypothesis)의 H를 따와 다음과 같이 표현하기도 함.(x와 곱해지는 W를 가중치(Weight), b를 편향(bias)라고 한다)
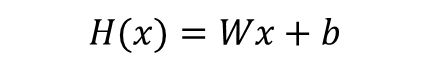
- 가중치(W)와 편향(b)을 0으로 초기화하고 출력해보기
# 가중치 W, 편향 b를 0으로 초기화하고 학습을 통해 값이 변경되는 변수임을 명시함.
W = torch.zeros(1, requires_grad=True)
b = torch.zeros(1, requires_grad=True)
# 가중치 W, 편향 b를 출력
print(W)
print(b)- 위는 그저 0이므로 적절한 값이 아님.
- 위 사진은 아래와 같이 코딩
hypothesis = x_train * W + b
print(hypothesis)3. Compute loss
- 선형회귀일 경우, 여러 직선(가설 들) 중에서 데이터를 가장 잘 표현하는 직선을 골라야 함.
- 이 직선을 고를 때 수학적으로 충분한 근거를 들어야 함.
- 이 수학적 근거로 오차(error)라는 개념을 도입 -> 이 오차들은 양수, 음수 등으로 방향성이 다 다름
- 오차를 제곱한 값을 합계 = 오차 제곱 합
- 오차 제곱 합의 평균 = 평균 제곱 오차(MSE)
- 이를 W, b에 의한 비용 함수(Cost Function)으로 재정의하면 다음과 같음
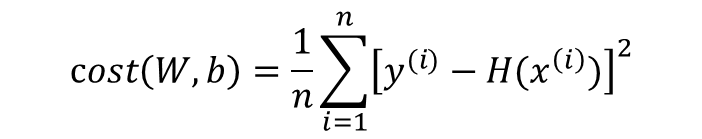
- 이 cost(W, b)를 최소가 되게 만드는 W와 b를 구하면 훈련 데이터를 가장 잘 나타내는 직선을 구할 수 있다.
- 위 식은 다음과 같이 코딩
# 앞서 배운 torch.mean으로 평균을 구한다.
cost = torch.mean((hypothesis - y_train) ** 2)
print(cost)tensor(18.6667, grad_fn=<MeanBackward1>)4. Gradient Descent
- 비용 함수의 값을 최소로 하는 W와 b를 찾는 방법 -> 옵티마이저(Optimizer) 알고리즘 혹은 최적화 알고리즘 -> 이 알고리즘에서 가장 기본적인 경사하강법(Gradient Descent)
- 예제에서는 편향 b를 고려안함(즉, b=0)
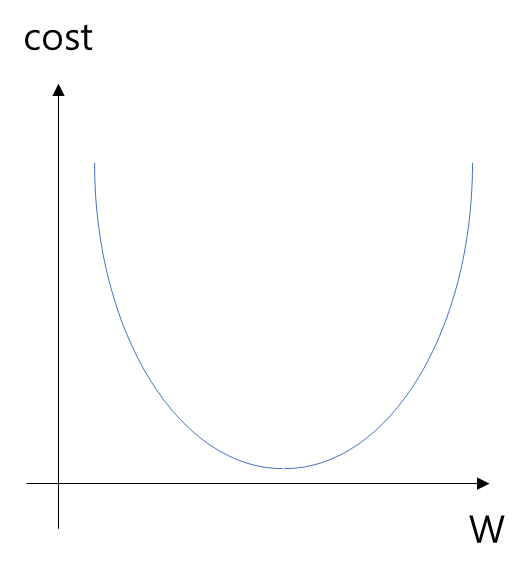
- 위 그래프에서 cost를 가장 작게 하려면 맨 아래의 볼록한 부분의 W값을 찾아야 함.
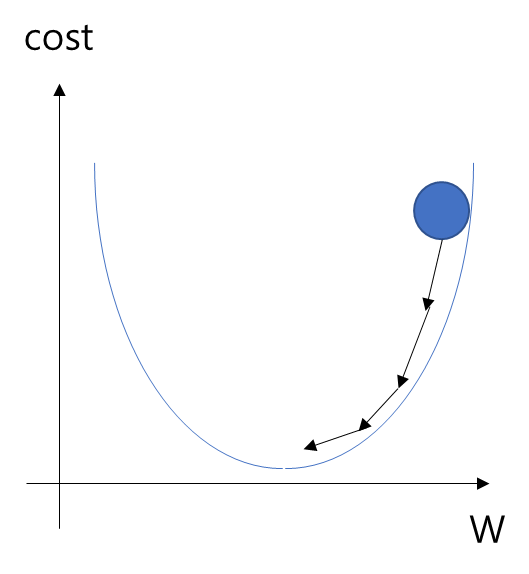
- 위 그림은 W값을 점점 수정하면서 볼록한 지점을 찾아가는데 이것을 가능하게 하는 것이 경사하강법이고, 경사하강법은 한 점에서의 순간변화율이나 접선의 기울기를 사용함.
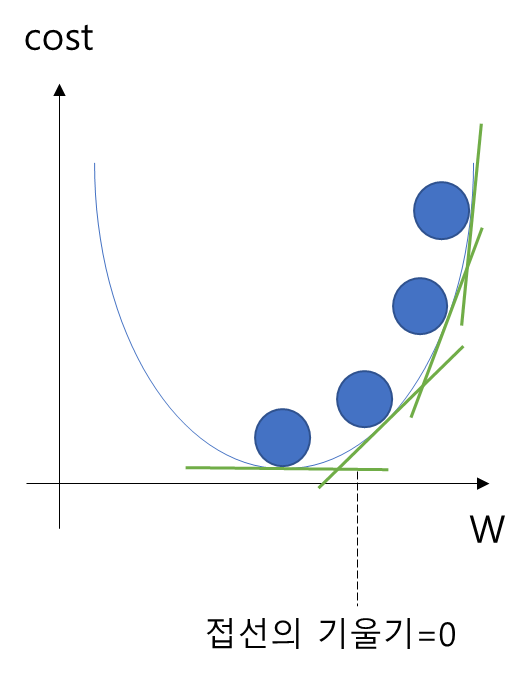
- 즉, cost가 최소화가 되는 지점은 접선의 기울기가 0이 되는 지점이며, 또한 미분값이 0이 되는 지점이다.
- 이 반복 작업에는 현재 W에 접선의 기울기를 구해 특정 숫자 α를 곱한 값을 빼서 새로운 W로 사용하는 식이 사용됨
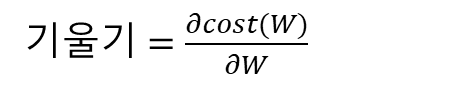
- 기울기가 음수일 때, W의 값이 증가
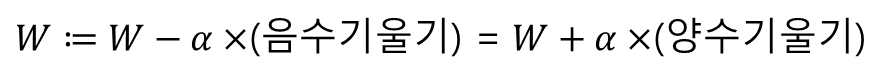
- 기울기가 양수일 때, W의 값이 감소
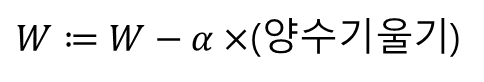
- 위 두 경우는 결과적으로 다음 식과 같다.
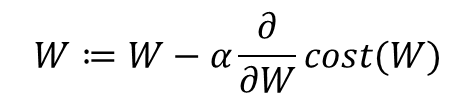
- 여기서 학습률(learning rate, 여기선 알파로 표기)은 W 값이 변화할때, 얼마나 크게 변경할지를 결정한다.
- 학습률이 지나치게 높으면 W의 값이 발산하는 상황이 될 수 있다. 반대로 학습률이 지나치게 낮으면 학습 속도가 너무 느려질 수 있다.
- 경사하강법(아래는 SGD를 사용, lr은 학습률)은 다음과 같이 구현
optimizer = optim.SGD([W, b], lr=0.01)- optimizer.zero_grad()를 실행하므로서 미분을 통해 얻은 기울기를 0으로 초기화
- cost.backward() 함수를 호출하면 가중치 W와 편향 b에 대한 기울기가 계산
- 최적화 함수 opimizer의 .step() 함수를 호출하여 인수로 들어갔던 W와 b에서 리턴되는 변수들의 기울기에 학습률(learining rate) 0.01을 곱하여 빼줌으로서 업데이트
# gradient를 0으로 초기화
optimizer.zero_grad()
# 비용 함수를 미분하여 gradient 계산
cost.backward()
# W와 b를 업데이트
optimizer.step() - 결과
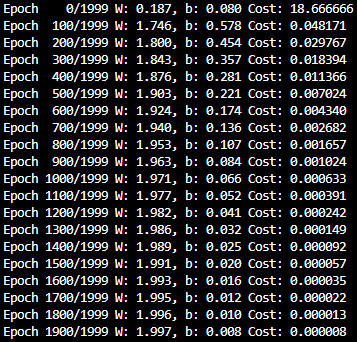
- 결과를 보면 W는 1.997로, b는 0.008로 W는 2에 가까워 졌고, b는 0에 가까워 졌다.
- 실제 결과는 W가 2이고, b가 0인 H(x)=2x이므로 거의 정답을 맞추었다.
4-1. 자동 미분(Autograd) 실습
- 임의로 다음 식을 세우고 w에 대해 미분하기

- 값이 2인 임의의 스칼라 텐서 w를 선언하는데, 이때 required_grad를 True로 설정(이는 이 텐서에 대한 기울기를 저장한다는 의미 -> w.grad에 w에 대한 미분값이 저장됨)
w = torch.tensor(2.0, requires_grad=True)- 수식 정의
y = w**2
z = 2*y + 5- 해당 수식을 w에 대해서 미분(.backward()로 해당 수식의 w에 대한 기울기 계산)
z.backward()- w.grad를 출력하면 w가 속한 수식을 w로 미분한 값이 저장된 것을 확인할 수 있음
print('수식을 w로 미분한 값 : {}'.format(w.grad))수식을 w로 미분한 값 : 8.0출처 : 'PyTorch로 시작하는 딥 러닝 입문' <이 책의 내용을 요약 정리한 것임.>

매일 매일 새로워지는 나 자신을 꿈꾸며