# 목표 설정
- 와인의 속성을 분석한 뒤 품질 등급을 예측
# 핵심 개념 이해
기술 통계
데이터의 특성을 나타내는 수치를 이용해 분석하는 기본적인 통계 방법으로 요약 통계라고도 한다.회귀 분석
독립 변수 x와 종속 변수 y간의 상호 연관성 정도를 파악하기 위한 분석 기법이다.
독립 변수가 한 개이면 단순 회귀 분석, 두 개 이상이면 다중 회귀 분석이라고 하며 독립 변수와 종속 변수의 관계에 따라 선형 회귀 분석과 비선형 회귀 분석으로 나누기도 한다.t-검정
데이터에서 찾은 평균으로 두 그룹에 차이가 있는지 확인하는 방법이다.히스토그램
데이터 값의 범위를 몇 개의 구간으로 나누고 각 구간에 해당하는 값의 숫자나 상대적 빈도 크기를 차트로 나타낸 것이다.
# 데이터 수집
# 데이터 준비
1. 다운로드한 CSV 파일 정리하기
- 엑셀에서 열 구분자를 세미콜론으로 인식시키기
>>> import pandas as pd
>>> red_df = pd.read_csv('winequality-red.csv 저장된 경로', sep=';', header=0, engine='python')
>>> white_df = pd.read_csv('winequality-white.csv 저장된 경로', sep=';', header=0, engine='python')
>>> red_df.to_csv('7장_data 폴더 경로/winequality-red2.csv', index=False)
>>> white_df.to_csv('7장 data 폴더 경로/winequality-white2.csv', index=False)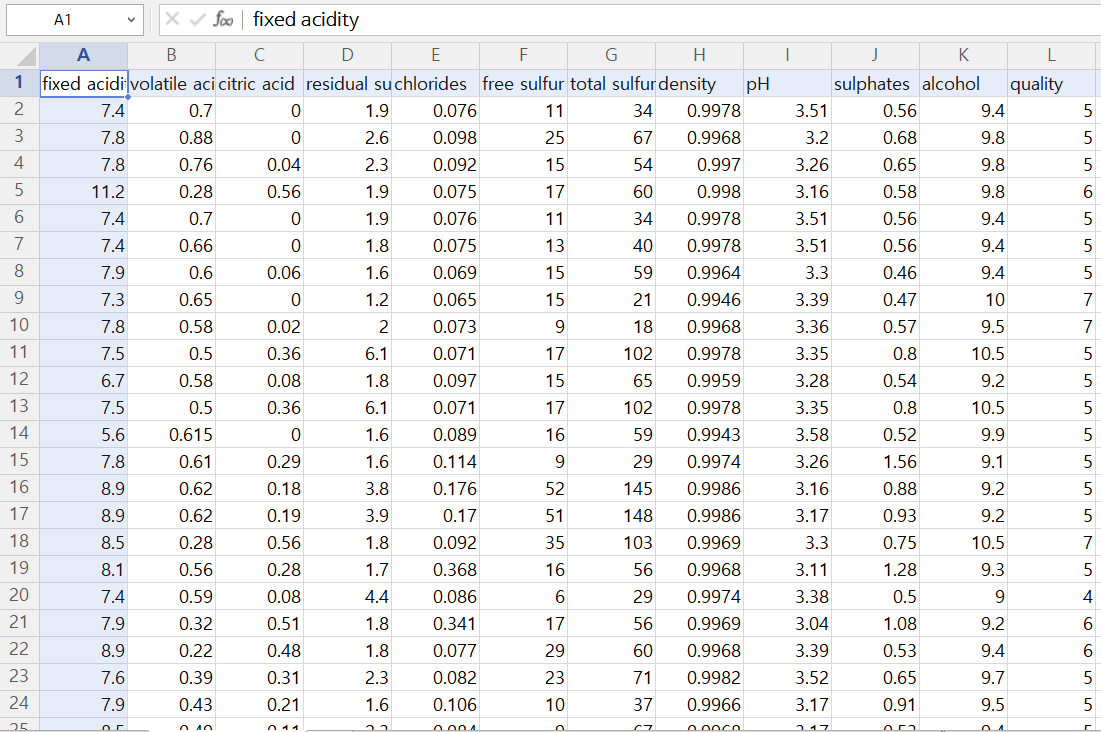 👉 winequality-red2.csv
👉 winequality-red2.csv
: 샘플 1,599개
: 입력 변수 fixed acidity ~ alcohol - 11개
: 출력 변수 quality - 1개
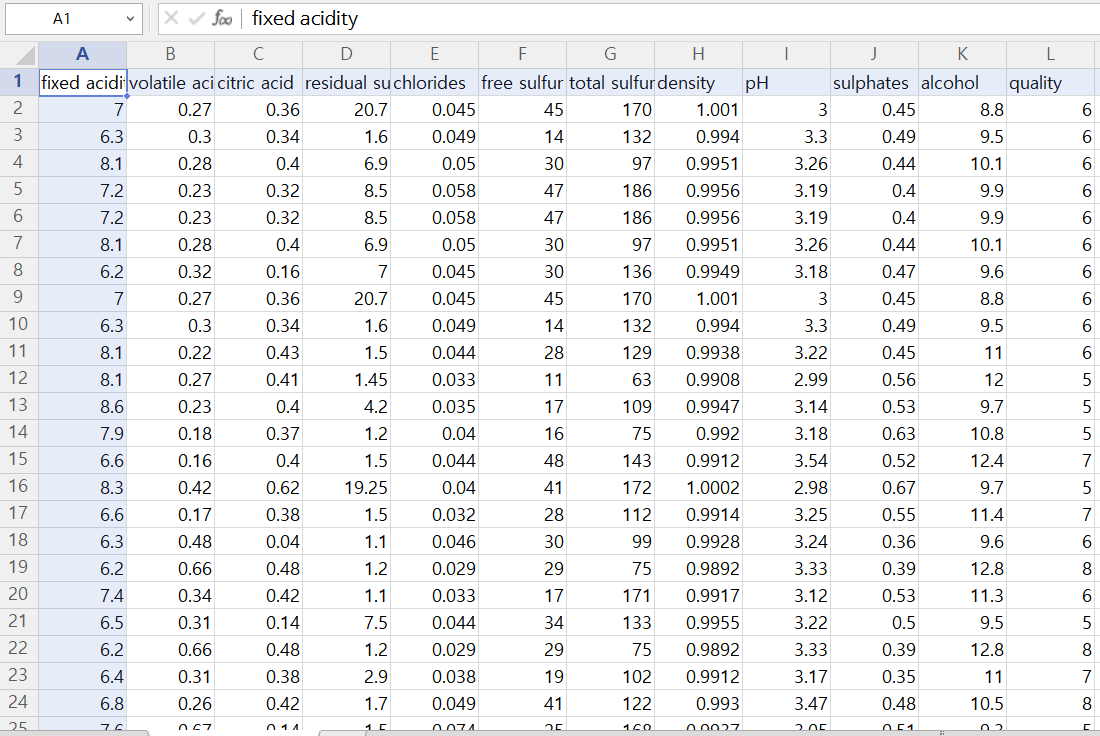 👉 winequality-white2.csv
👉 winequality-white2.csv
: 샘플 4,898개
: 입력 변수 fixed acidity ~ alcohol - 11개
: 출력 변수 quality - 1개
2. 데이터 병합하기
- 레드 와인과 화이트 와인 파일 합치기
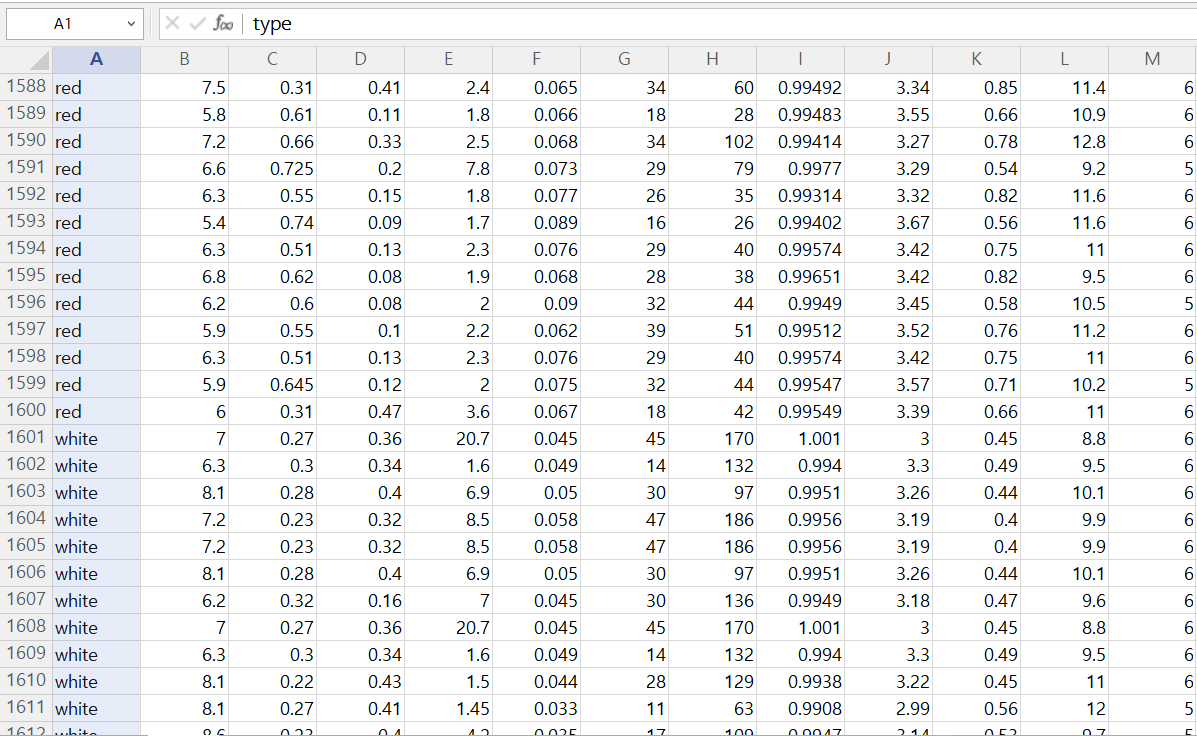 👉 wine.csv
👉 wine.csv
# 데이터 탐색
1. 기본 정보 확인하기
: 전체 샘플 - 6,497개
: 속성 type ~ quality - 13개
: 독립 변수(x) type ~ alcohol - 12개
: 종속 변수(y) quality - 1개
2. 함수를 사용해 기술 통계 구하기
: 열 이름에 공백이 있으면 밑줄로 바꾼 뒤 한 단어로 연결한다.
: describe() 함수를 사용하여 속성별 개수(count), 평균(mean), 표준편차(std), 최소값(min), 전체 데이터 백분율에 대한 25번째 백분위수(25%), 중앙값인 50번째 백분위수(50%), 75번째 백분위수(75%), 100번째 백분위수인 최대값(max)을 출력한다.
: wine.quality.unique() 함수를 사용하여 quality 속성값 중에서 유일한 값을 출력한다.
: 와인 품질 등급(quality)은 3,4,5,6,7,8,9의 7개 등급이 있다는 것을 알 수 있다.
: 6등급인 샘플이 가장 많고, 9등급인 샘플이 가장 적다.
# 데이터 모델링
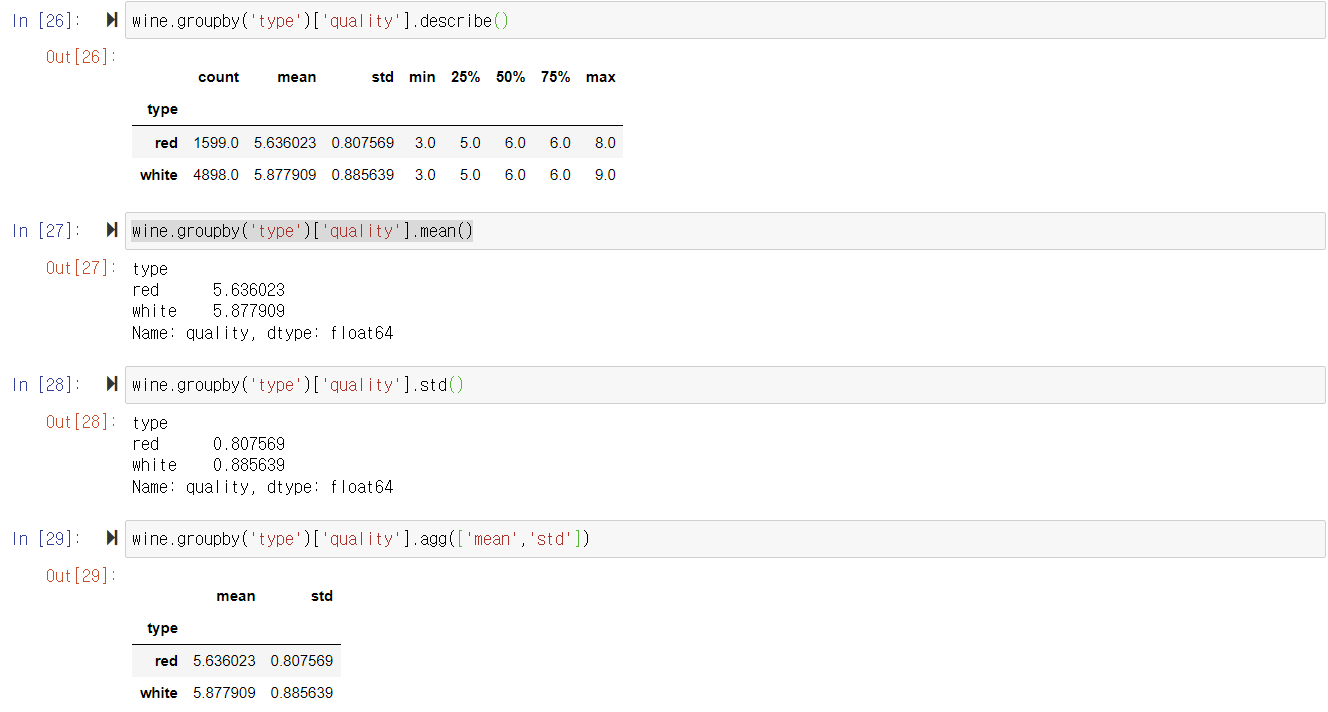
1. describe() 함수로 그룹 비교하기
: type에 따라 그룹을 나눈 뒤, 종속 변수인 quality에 describe() 함수를 사용하여 그룹별로 count, mean, std, min, 25%, 50%, 75%, max를 구하여 비교한다.
2. t-검정과 회귀 분석으로 그룹 비교하기
: t-검정을 사용하여 그룹 간 차이를 확인한다.
: 레드 와인 샘플의 quality 값만 찾아서 red_wine에 저장한다.
: 화이트 와인 샘플의 quality 값만 찾아서 white_wine에 저장한다.
: scipy 패키지의 stats.ttest_ind() 함수를 사용하여 t-검정을 하고 두 그룹 간 차이를 확인한다.
: 선형 회귀 분석식의 종속 변수(quality), 독립 변수(type과 quality를 제외한 11개 속성)를 구성한다.
: 선형 회귀 모델 중에서 OLS 모델을 사용한다.: 선형 회귀 분석과 관련된 통계값을 출력한다.
※ 실행 결과에 출력된 Warnings는 독립 변수값의 단위와 범위가 다른 것과 독립 변수 간의 높은 상관관계로 인해 다중공선성 문제가 발생한 것에 대한 경고이다.
3. 회귀 분석 모델로 새로운 샘플의 품질 등급 예측하기
- 예측에 사용할 첫 번째 샘플 데이터 만들기
: wine에서 quality와 type 열은 제외하고, 회귀 분석 모델에 사용할 독립 변수만 추출하여 sample1에 저장한다.
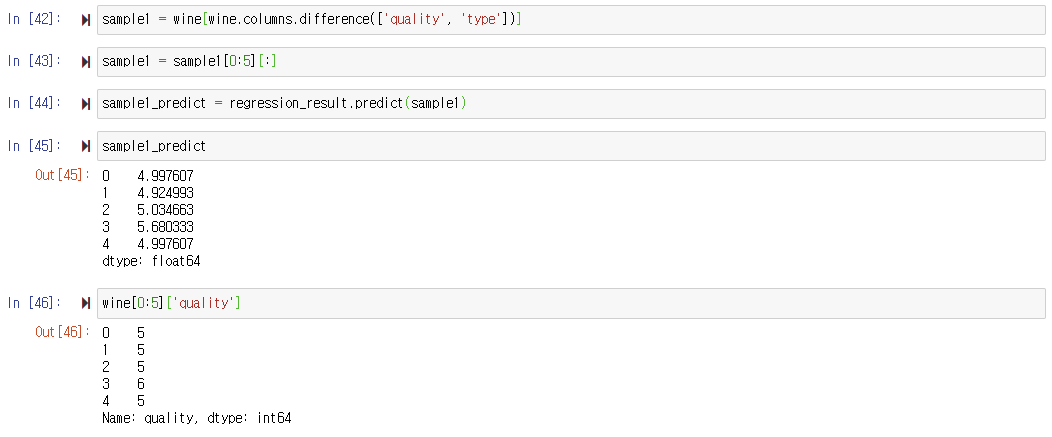
: sample1에 있는 샘플 중에서 0번부터 4번까지 5개 샘플만 추출하고, sample1에 다시 저장하여 예측에 사용할 샘플을 만든다.- 첫 번째 샘플의 quality 예측하기
: 샘플 데이터를 회귀 분석 모델 regression_result의 예측 함수 predict()에 적용하여 수행한 뒤 결과 예측값을 sample1_predict에 저장한다.
: sample1_predict를 출력하여 예측한 quality를 확인한다.
: wine에서 0번부터 4번까지 샘플의 quality 값을 출력하여 sample1_predict이 맞게 예측되었는지 확인한다.
- 예측에 사용할 두 번째 샘플 데이터 만들기
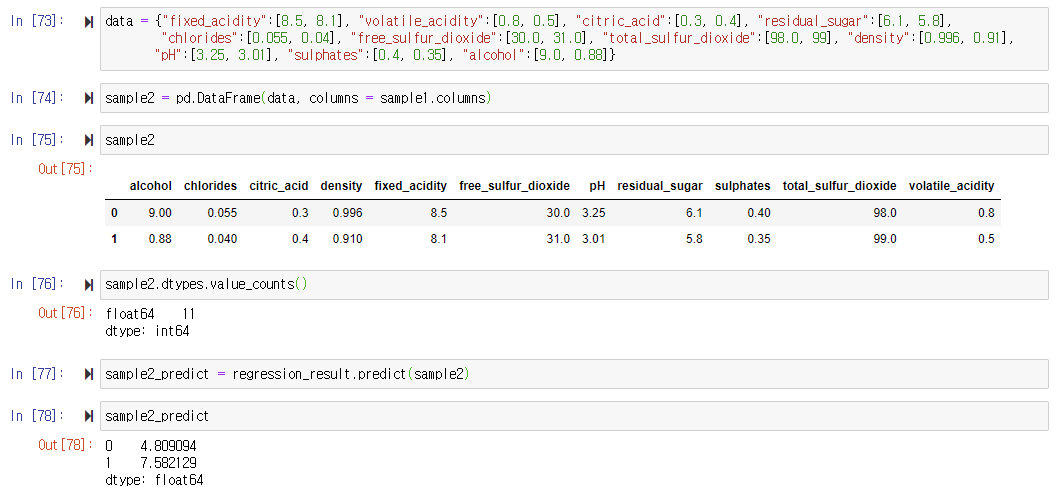
: 회귀식에 사용한 독립 변수에 대입할 임의의 값을 딕셔너리 형태로 만든다.
: 딕셔너리 형태의 값과 sample1의 열 이름만 뽑아 데이터프레임으로 묶은 sample2를 만든다.
: sample2를 출력하여 제대로 구성되었는지 확인한다.- 두 번째 샘플의 quality 예측하기
: 샘플 데이터를 회귀 분석 모델 regression_result의 예측 함수 predict()에 적용하여 수행한 뒤 결과 예측값을 sample2_predict에 저장한다.
: sample2_predict를 출력하여 예측한 quality를 확인한다.
# 결과 시각화
1. 와인 유형에 따른 품질 등급 히스토그램 그리기
: 커널 밀도 추정을 적용한 히스토그램 그리기
: 차트에서 x축은 quality이고 y축은 확률 밀도 함수값이다.
2. 부분 회귀 플롯으로 시각화하기
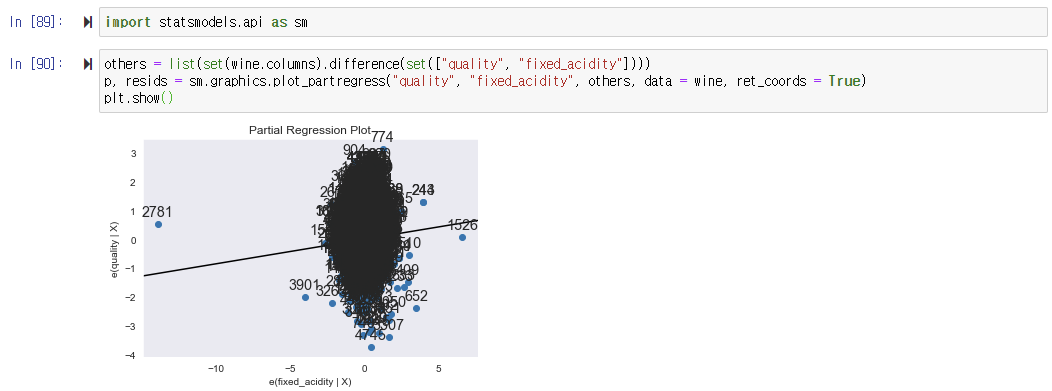
- fixed_acidity가 종속 변수 quality에 미치는 영향력을 시각화하기
: 부분 회귀에 사용한 독립 변수와 종속 변수를 제외한 나머지 변수 이름을 리스트 others로 추출한다.
: 나머지 변수는 고정하고 fixed_acidity가 종속 변수 quality에 미치는 영향에 부분 회귀를 수행한다.
: 부분 회귀의 결과를 플롯으로 시각화하여 나타낸다.
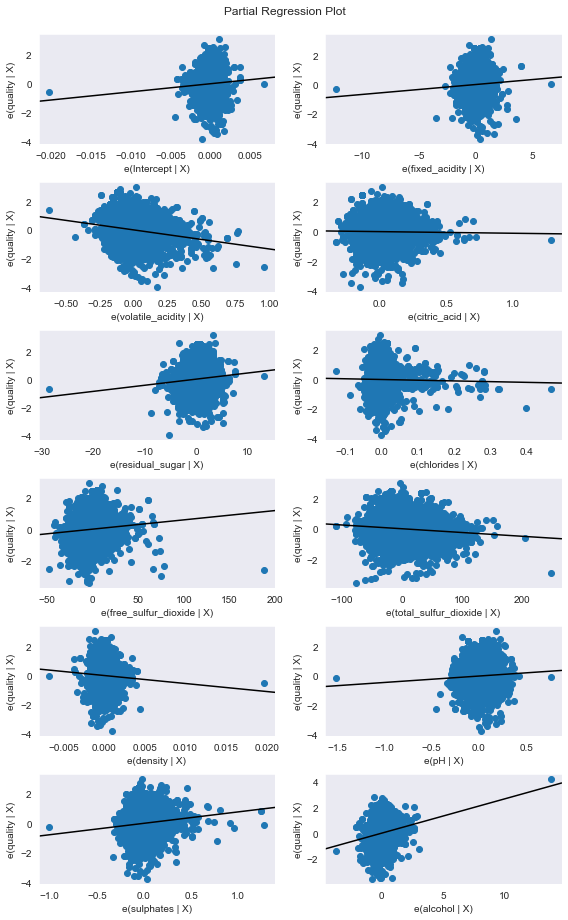
- 각 독립 변수가 종속 변수 quality에 미치는 영향력을 시각화하기
: 차트의 크기를 지정한다.
: 다중 선형 회귀 분석 결과를 가지고 있는 regression_result를 이용해 각 독립 변수의 부분 회귀 플롯을 구한다.
: 부분 회귀 결과를 플롯으로 시각화하여 나타낸다.