# 목표 설정
- 타이타닉호의 생존자와 관련된 변수의 상관관계를 찾아보고 생존과 가장 상관도가 높은 변수는 무엇인지 분석
# 핵심 개념 이해
-
상관 분석
두 변수가 어떤 선형적 관계에 있는지를 분석하는 방법이다. 두 변수의 관계가의 강도를 상관관계라고 한다.
- 단순 상관 분석
두 변수가 어느정도 강한 관계에 있는지 측정한다. - 다중 상관 분석
세 개 이상의 변수 간 관계의 강도를 측정한다.
이때 다른 변수와의 관계를 고정하고 두 변수 간 관계의 강도를 나타내는 것을 편상관 분석이라고 한다.
- 단순 상관 분석
-
상관 계수 p
변수 간 관계의 정도(0~1)와 방향(+,-)을 하나의 수치로 요약해주는 지수로 -1에서 +1사이의 값을 가진다. 상관 계수가 +이면 양의 상관관계이며 한 변수가 증가하면 다른 변수도 증가한다. 상관 계수가 -이면 음의 상관계수이며 한 변수가 증가할 때 다른 변수는 감소한다.
- 0.0 ~ 0.2: 상관관계가 거의 없다.
- 0.2 ~ 0.4: 약한 상관관계가 있다.
- 0.4 ~ 0.6: 상관관계가 있다.
- 0.6 ~ 0.8: 강한 상관관계가 있다.
- 0.8 ~ 1.0: 매우 강한 상관관계가 있다.
-
피어슨 상관 계수
상관 계수 중에서 많이 사용하는 것으로 r로 표현한다.
-
상관 분석 결과의 시각화
상관 분석 결과를 시각화할 때는 두 변수의 관계를 보여주는 산점도나 히트맵을 많이 사용한다.
# 데이터 수집
파이썬의 seaborn 라이브러리 패키지에서 제공하는 타이타닉 데이터 사용
>>> import seaborn as sns
>>> import pandas as pd
>>> titanic = sns.load_dataset("titanic")
>>> titanic.to_csv('C:/Users/이유빈/My_Python/7장_data/titanic.csv', index = False)# 데이터 준비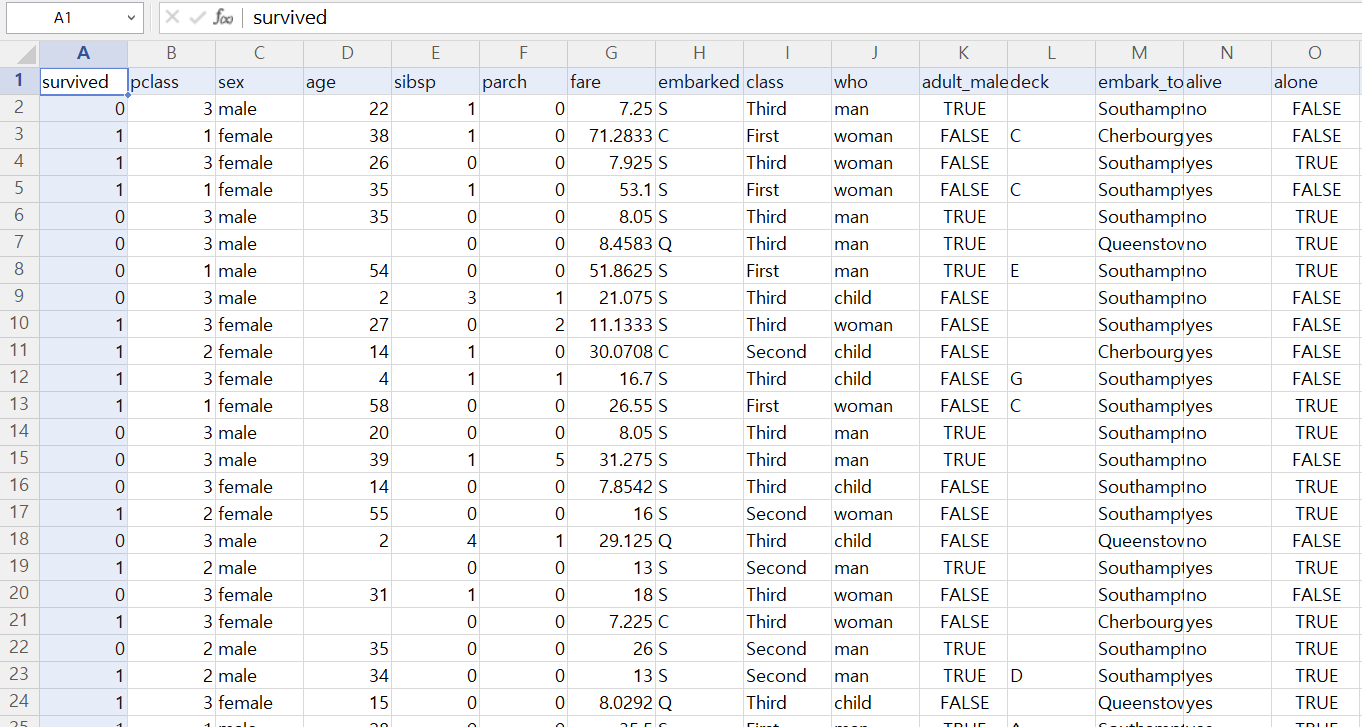
👉 titanic.csv
: age, embarked, deck, embark_town 항목 중에 결측값(누락된 값)이 있다.
: age의 결측값은 중앙값으로 치환
: embarked, embark_town은 최빈값으로 치환
: deck는 형식이 category이므로 최빈 category로 바꾸어 채워 넣음
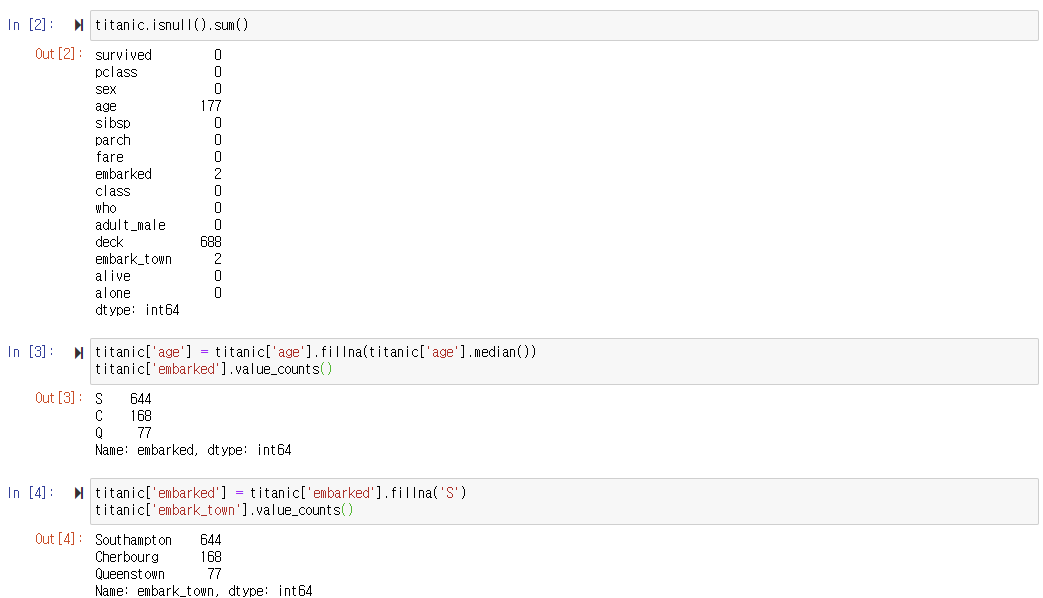
- 결측값 확인하기
: 타이타닉 데이터에 결측값이 있는지 확인한다. -> age, embarked, deck, embark_town
: age 열의 결측값을 중앙값으로 치환한다.- embarked 열의 결측값을 최빈값으로 치환하기
: embarked 열에서 최빈값이 'S'임을 확인한다.
: embarked 열에서 결측값을 'S'로 치환한다.- ebmark_town 열의 결측값을 최빈값으로 치환하기
: embark_town 열에서 최빈값이 'Southampton'임을 확인한다.
: embark_town 열에서 결측값을 'Southampton'으로 치환한다.
- deck 열의 결측값을 최빈값으로 치환하기
: deck 열에서 최빈값이 'C'임을 확인한다.
: deck 열에서 결측값을 'C'로 치환한다.
: 타이타닉 데이터에 결측값이 다 채워졌는지 확인한다.
# 데이터 탐색
1. 기본 정보 확인하기
: 전체 샘플 - 891개
: 속성 - 15개
: 샘플 891명 중 생존자 342명
: 샘플 891명 중 사망자 549명
| 데이터 | 의미 |
|---|---|
| pclass, class | 객실 등급 |
| sibsp | 함께 탑승한 형제자매와 배우자 수 |
| parch | 함께 탑승한 부모/자식 수 |
| embarked, embark_town | 탑승 항구 |
| adult_male | 성인 남자 여부 |
| alone | 동행 여부를 True/False로 나타냄 |
2. 차트를 그려 데이터를 시각적으로 탐색하기
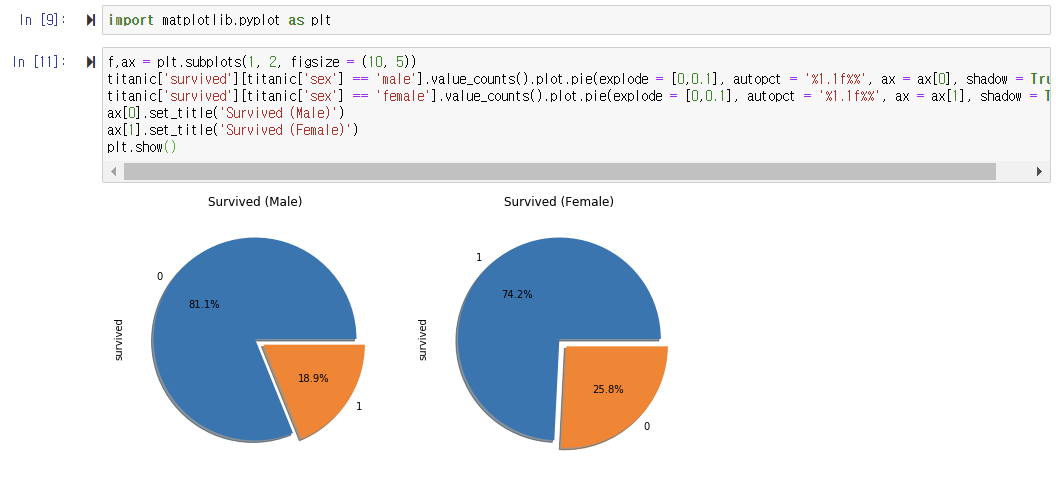
- 남자 승객과 여자 승객의 생존율을 pie 차트로 그리기
: 한 줄에 두 개의 차트를 그리도록 하고 크기를 설정한다.
: 첫 번째 pie 차트는 남자 승객의 생존율을 나타내도록 설정한다.
: 두 번째 pie 차트는 여자 승객의 생존율을 나타내도록 설정한다.
👉 남자 승객의 생존율 - 18.9%
👉 여자 승객의 생존율 - 74.2%
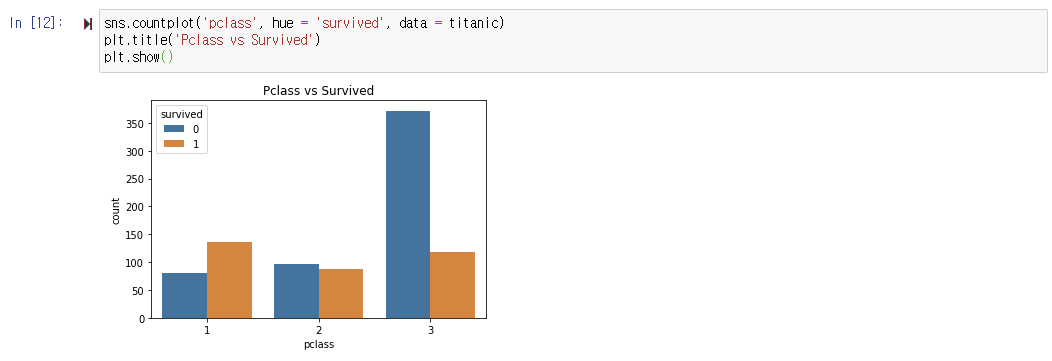
3. 등급별 생존자 수를 차트로 나타내기
- 객실 등급(pclass) 카테고리별 생존자(survived) 수를 계산하여 차트 그리기
: pclass 유형 1,2,3을 x축으로 하고 survived=0과 survived=1의 개수를 계산하여 y축으로 하는 countplot을 설정한다.
👉 생존자(1)는 1등급에서 가장 많음
👉 사망자(0)는 3등급에서 월등히 많음
# 데이터 모델링
1. 상관 분석을 위한 상관 계수 구하고 저장하기
: 상관 계수는 연속형 데이터에서만 구할 수 있으므로 데이터 형식이 int64, float64, boolean인 속성 8개에 대해서만 상관 분석 진행
: 피어슨 상관 계수를 적용하여 상관 계수를 구한다.
2. 상관 계수 확인하기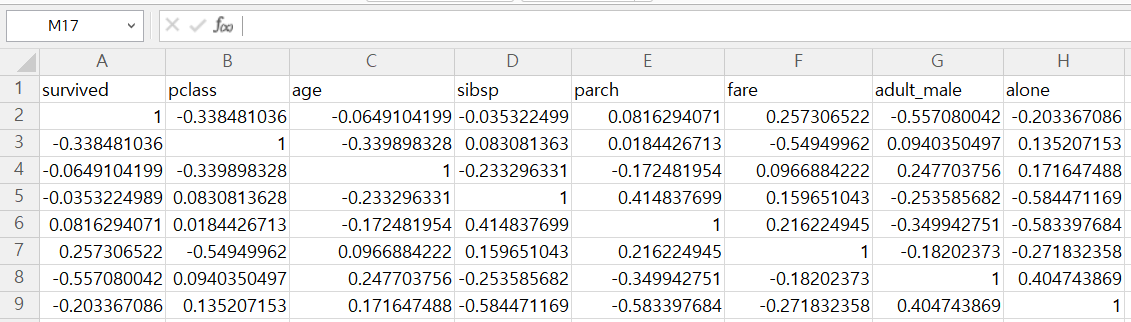
👉 titanic_corr.csv
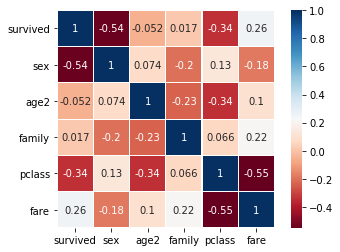
: 남자 성인(adult_male)은 생존(survived)과 음의 상관관계
: 객실 등급(pclass)은 생존(survived)과 음의 상관 관계
: 객실 요금(fare)은 생존(survived)과 양의 상관 관계
: 동행 없이 혼자 탑승한 경우(alone)에 생존율이 떨어짐
3. 특정 변수 사이의 상관 계수 구하기
- 두 변수 사이의 상관 계수 구하기
: survived와 adult_male 변수 사이의 상관 계수를 구한다.
: survived와 fare 변수 사이의 상관 계수를 구한다.

# 결과 시각화
1. 산점도로 상관 분석 시각화하기
: pairplot() 함수를 사용하여 타이타닉 데이터의 차트를 그린다. hue는 종속 변수를 지정한다.
: pclass, sibsp, parch, alone 변수에 대해 종속 변수 값을 나타내는 점이 퍼지지 않고 세로 또는 가로로 일정 지점에만 있다.
-> 연속되는 실수형 값이 아니라 개수를 나타내는 정수형이거나 True/False를 나타내는 boolean형이기 때문이다.

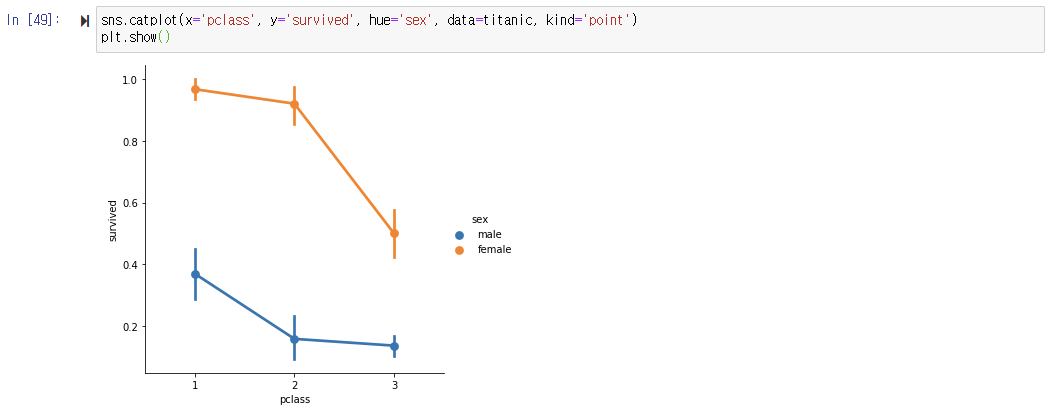
2. 두 변수의 상관관계 시각화하기
- 생존자의 객실 등급과 성별 관계를 catplot()로 그리기
: catplot() 함수를 사용하여 pclass와 survived 변수의 관계를 차트로 그린다. hue 인자를 이용하여 종속 변수를 sex로 지정한다.
3. 변수 사이의 상관 계수를 히트맵으로 시각화하기
- age를 카테고리 값으로 바꾸어 age2 변수로 추가하기
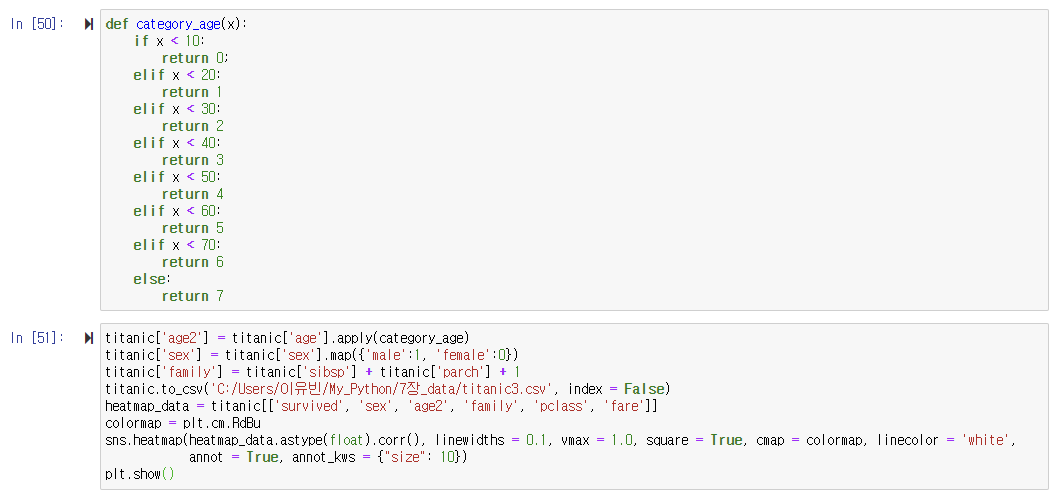
: 10살 단위로 등급을 나누어 0~7의 값으로 바꿔주는 category_age 함수를 작성한다.
: category_age 함수를 적용하여 새로운 age2 열을 만들어 추가한다.
: 성별을 male/female에서 1/0으로 치환한다.
: 가족의 수를 구하여 family 열을 추가한다.- 상관 분석 결과를 히트맵으로 나타내기
: 히트맵을 사용할 데이터를 추출한다.
: 히트맵에 사용할 색상맵을 지정한다.
: corr() 함수로 구한 상관 계수로 히트맵을 생성한다.