# 동적 웹 페이지 크롤링 준비
- Selenium 라이브러리 설치하기 -
: WebDriver 모듈을 이용하면 웹 브라우저에 대한 원격 제어 가능
: 자바스크립트 함수를 실행시키고 결과 데이터를 가져올 수 있다.
pip install selenium-
WebDriver 다운로드하기
: 다운로드 사이트(https://www.selenium.dev.downloads/)에 접속한다.
: Browsers 항목을 클릭한 후 Chrome의 documentation을 클릭한다. -
ChromeDriver-WebDriver for Chrome 페이지가 나타나면 다운로드 링크를 클릭한다.
- 다운로드 페이지가 나타나면 시스템 운영체제에 맞는 ChromeDriver를 선택하여 다운로드한다.
-
My_Python 폴더 하위에 WebDriver 폴더를 만든다. 다운로드한 압축 파일을 풀고 'chromedriver.exe' 파일을 WebDriver 폴더로 옮긴다.
-
Selenium 라이브러리의 WebDriver를 임포트한다.
>>> from selenium import webdriver- 크롬 WebDriver 객체를 생성한다.
>>> wd = webdriver.Chrome('./WebDriver/chromedriver.exe')- 파이썬 셸 창에서 다음과 같이 입력하여 Selenium이 제어하는 크롬 창에서 웹 페이지를 열어 확인한다.
>>> wd.get("http://www.hanbit.co.kr")# 동적 웹 페이지 크롤링 실습
1. 웹 페이지 분석하기
-
매장 정보 찾기
: 커피빈 홈페이지에서 매장 정보가 있는 페이지를 찾는다.
: Store - 매장 찾기 -
자바스크립트의 stoneLocal2() 함수 확인하기
: 지역 검색 - 서울
: 'javascript:storeLocal2('서울') -
HTML 소스 확인하기
: Ctrl + U 눌러 HTML 소스를 확인한다.
: HTML 소스에는 조회된 매장 목록이 없다.
-> 시/도를 선택하면 store.Local2() 함수를 호출하여 선택한 지역의 매장 목록을 표시하는 동적 웹 페이지 구조이기 때문
: Selenium/WebDriver를 이용하여 파싱 -
버튼에 연결된 자바스크립트 확인하기
: 자세히보기 버튼을 클릭하면 자바스크립트의 storePop2('363') 함수가 호출되어 매장 정보가 팝업으로 나타나는 형식
: '363'은 매장코드
2. 파이썬 셸 창에서 크롤링하기
- Selenium 패키지의 WebDriver를 임포트한다.
>>> from bs4 import BeautifulSoup
>>> from selenium import webdriver- 크롬 WebDriver 객체를 생성한다.
>>> wd = webdriver.Chrome('./WebDrvier/chromedriver.exe')- 웹 페이지를 연결한다.
>>> wd.get("https://www.coffeebeankorea.com/store/store.asp")- 자바스크립트 함수 호출해 매장 정보 페이지 열기
>>> wd.execute_script("storePop2(1)")- 자바스크립트 함수가 수행된 페이지의 소스 코드를 저장한다.
>>> html = wd.page_source- BeautifulSoup 객체를 생성한다.
>>> soupCB1 = BeautifulSoup(html, 'html.parser')- HTML 소스 코드 형태로 출력하여 확인한다.
>>> print(soupCB1.prettify())- 매장 정보 추출하기
>>> store_name_h2 = soupCB1.select("div.store_txt > h2")
>>> store_name_h2
>>> store_name = store_name_h2[0].string
>>> store_name- 매장 주소를 추출한다.
>>> store_info = soupCB1.select("div.store_txt > table.store_table > tbody > tr > td")
>>> store_info
>>> store_address_list = list(store_info[2])
>>> store_address_list
>>> store_address = store_address_list[0]
>>> store_address- 매장 전화번호를 추출한다.
>>> store_phone = store_info[3].string
>>> store_phone3. 파이썬 파일을 작성하여 크롤링하기
from bs4 import BeautifulSoup
import urllib.request
import pandas as pd
import datetime
from selenium import webdriver
import time
#[CODE 1]
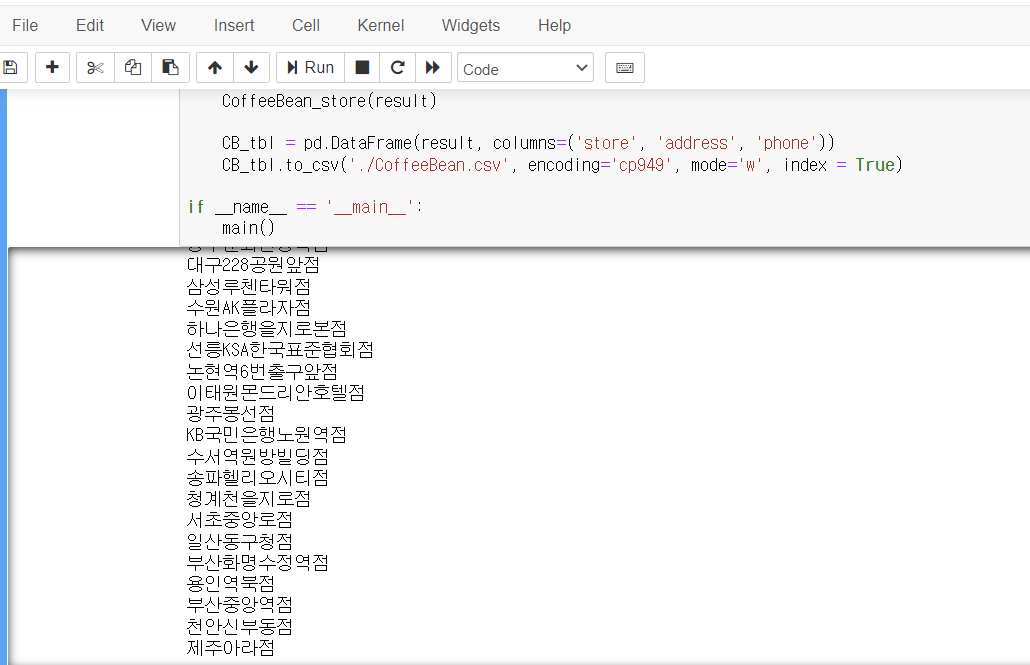
def CoffeeBean_store(result):
CoffeeBean_URL = "https://www.coffeebeankorea.com/store/store.asp"
wd = webdriver.Chrome('WebDriver설치경로/Chromedriver.exe')
for page in range(1,370): # 매장 수만큼 반복
wd.get(CoffeeBean_URL)
time.sleep(1) # 웹페이지 연결할 동안 1초 대기
try:
wd.execute_script("storePop2(%d)" %i)
time.sleep(1) # 스크립트 실행할 동안 1초 대기
html = wd.page_source
soupCB = BeautifulSoup(html, 'html.parser')
store_name_h2 = soupCB.select("div.store_txt > h2")
store_name = store_name_h2[0].string
print(store_name) # 매장 이름 출력하기
store_info = soupCB.select("div.store_txt > table.store_table > tbody > tr > td")
store_address_list = list(store_info[2])
store_address = store_address_list[0]
store_phone = store_info[3].string
result.append([store_name]+[store_address]+[store_phone])
except:
continue
return
#[CODE 0]
def main():
result = []
print('CoffeeBean store crawling >>>>>>>>>>>>>>>>>>')
CoffeeBean_store(result) #[CODE 1]
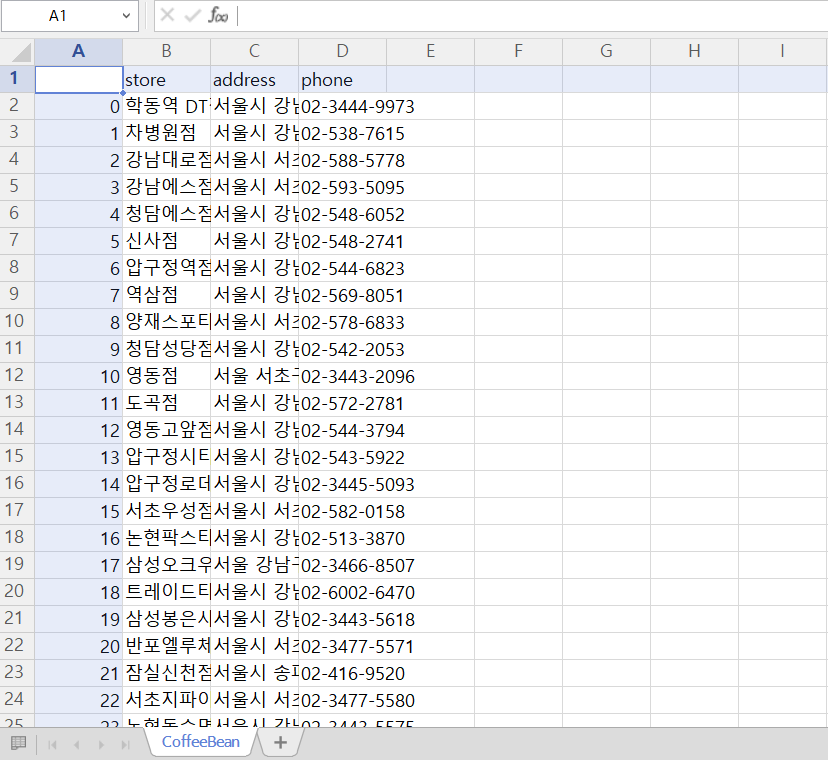
CB_tbl = pd.DataFrame(result, colums=('store', 'address', 'phone'))
CB_tbl.to_csv('./CoffeeBean.csv', encoding='cp949', mode='w', index=True)
if __name__ = '__main__':
main()