
딥러닝 강의는 이숙번 강사님께서 진행해주셨어요!
activation과 loss에서 종류가 바뀌는 점을 제외하면 코드가 비슷한 형태를 띄는 것 같았는데 제 생각처럼 되지 않더라고요,,🥲
1. 실습 환경
| colab |
|---|
 |
2. 예측하기
예측하기는 아래와 같은 과정을 거쳐 학습했습니다.
- 데이터 준비
- 데이터 구조 생성
- 데이터로 모델 학습(fit)
- 모델 이용
(1) 레모네이드 판매 예측
레모네이드는 예측에 사용될 열이 하나일 경우를 학습하기 위해 실습해보았어요.
import pandas as pd
import tensorflow as tf
#1. 데이터 준비
data = pd.read_csv('파일명.csv')
train_x = data[['컬럼명']]
train_y = data[['예측할 컬럼명']]
#2. 구조 생성
X = tf.keras.layers.Input(shape=[1])
Y = tf.keras.layers.Dense(1)(X)
model = tf.keras.models.Model(X,Y)
model.compile(loss='mse')
#3. 모델 학습
model.fit(train_X, train_y, epochs=1000)
#4. 모델 이용
print(model.predict(train_y))(2) 보스턴 집값 예측
집값 예측은 예측에 사용되는 열이 여러 개일 경우를 학습하기 위해 실습해보았어요.
import pandas as pd
import tensorflow as tf
#1. 데이터 준비
data = pd.read_csv('파일명.csv')
train_x = data[['컬럼명1', '컬럼명2', '컬럼명3', '컬럼명4', '컬럼명5', '컬럼명6', '컬럼명7', '컬럼명8', '컬럼명9', '컬럼명10', '컬럼명11', '컬럼명12', '컬럼명13']]
train_y = data[['예측할 컬럼명']]
#2. 구조 생성
X = tf.keras.layers.Input(shape=[13]) #shape값은 train_x의 개수를 따라감
Y = tf.keras.layers.Dense(1)(X)
model = tf.keras.models.Model(X,Y)
model.compile(loss='mse')
#3. 모델 학습
model.fit(train_X, train_y, epochs=1000)
#4. 모델 이용
print(model.predict(train_y))3. 아이리스 분류하기
아이리스는 종류가 3개로 나누어지기 때문에 예측에 사용되는 열과 예측해야 하는 종류가 모두 여러 개인 경우를 학습하기 위해 실습해보았어요.
import pandas as pd
import tensorflow as tf
#1. 데이터 준비
data = pd.read_csv('파일명.csv')
data = pd.get_dummies(data)
train_x = data[['꽃잎길이', '꽃잎폭', '꽃받침길이', '꽃받침폭']]
train_y = data[['품종_setosa', '품종_versicolor', '품종_virginica']]
#2. 구조 생성
X = tf.keras.layers.Input(shape=[4]) #shape값은 train_x의 개수를 따라감
Y = tf.keras.layers.Dense(3, activation='softmax')(X)
model = tf.keras.models.Model(X, Y)
model.compile(loss='categorical_crossentropy')
#3. 모델 학습
model.fit(train_X, train_y, epochs=1000)
#4. 모델 이용
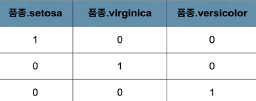
print(model.predict(train_y))4. 원핫인코딩
one-hot encoding은 표현하고 싶은 단어의 인덱스에 1의 값을 부여하고, 다른 인덱스에는 0을 부여하는 단어의 벡터 표현 방식입니다.
아이리스 분류하기에서는 원핫인코딩 방식으로 pd.get_dummies() 함수를 사용하였습니다.
만약 각 품종을 1, 2, 3으로 구분했다면 학습 과정에서 더 높은 숫자를 가진 품종을 더 높은 중요도로 생각할 수 있습니다.
따라서 각 품종을 각각의 다른 열로 두고 하나의 품종값이 1일 때 나머지 품종값이 0을 나타내면 공정하게 중요도가 부여될 수 있습니다.
5. softmax & crossentropy
이번 수업에서 분류 문제에 대한 모델의 구조를 생성할 때,
activation 함수는 'softmax', loss함수는 'categorical_crossentropy'를 사용했습니다!
분류지표의 보조지표로는 metrics='accuracy' 속성을 추가하여 사용해주었습니다.
6. Hidden Layer
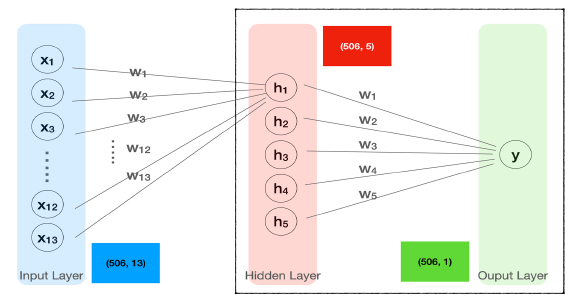
코드를 작성해보면서 hidden Layer을 구현해보았습니다.
# 2. 모델 구조 생성
X = tf.keras.layers.Input(shape=[13])
H = tf.keras.layers.Dense(5, activation='swish')(X)
Y = tf.keras.layers.Dense(1)(H)
model = tf.keras.models.Model(X,Y)
model.compile(loss='mse')
# 모델 구조 생성2
X = tf.keras.layers.Input(shape=[13])
H = tf.keras.layers.Dense(5, activation='swish')(X)
H = tf.keras.layers.Dense(5, activation='swish')(H)
H = tf.keras.layers.Dense(3, activation='swish')(H)
Y = tf.keras.layers.Dense(1)(H)
model = tf.keras.models.Model(X,Y)
model.compile(loss='mse')7. Regression
Regression파트에서는 4주차와 비슷한 내용들을 배우면서 복습하고 더 자세한 내용들을 배울 수 있었어요!
(1) Linear Regression
(2) Logistic Regression
8. Optimizer
- Gradient Descent (경사하강법)
함수의 경사를 구해서 함수의 극값에 이를 때까지 기울기가 낮은 쪽으로 반복 이동 / ex) SGD(batch학습)
- Momentum(관성)
이전에 이동했던 방향을 기억해서 다음 이동 방향에 반영 / ex) NAG
- Adagrad(Adaptive Gradient)
많이 이동한 변수는 최적값에 근접했을 것이라는 가정하에 변수를 기억해서 다음 이동 거리 감소 / ex) RMSprop
- Adam(RMSprop + Momentum)
9. activation(활성화 함수)
- Sigmoid
- tanh
- ReLU
- Leaky ReLU
- Maxout
- ELU
10. 딥러닝 앱 만들기
| gradio | Hugging Face |
|---|---|
 |  |
gradio를 사용해서 앱을 만들어보고
Hugging Face에서 openai api를 사용하여 글에서 감정을 분석하거나 새로운 글을 생성하는 등의 실습을 진행해보았습니다!
위 내용 외에도 Chain Rule & Back Propagation, Fit함수의 동작 과정, Flatten 함수, Conv2D, MaxPool2D, LeNet-5 등에 대해 알아보았습니다 :)

잘 보고 갑니다