
머신러닝은 이장래 강사님이 수업해주셨어요😊
처음 듣는 내용들이 많았는데 강사님께서 비유를 너무 잘해주셔서
이해하는 데에 많은 도움이 되었습니다!
예를 들면, K-Fold Validation와 같은 검증의 필요성을 설명해주실 때
데이터 Fitting > Model 생성 > 평가 단계만 거칠 때의 문제점
시험 공부를 하고 모의고사를 한 번도 보지 않은 상태에서 수능을 볼 때
수능 성적이 얼마나 나올지 예상 가능한가?
와 같은 비유들을 많이 해주셨는데 다음 내용을 배울 때마다 또 어떤 비유로 내용 이해에 도움을 주실지 기대되어서 들을수록 흥미로워지는 수업이었습니다👍
이번 주차에는 이런 내용을 배웠어요
- 머신러닝이란?
- 성능 평가
- 기본 알고리즘
- K-Fold Cross Validation
- Hyperparameter 튜닝
- 앙상블
(1) 학습용, 평가용 데이터 분리
데이터 가공 과정에서는 pandas, numpy 모듈을 사용하고,
데이터 분리, fitting, 평가 등의 모델링 과정에서는 sklearn 모듈을 사용하였습니다.
| 데이터 처리 모듈 | 데이터 모델링 과정 모듈 |
|---|---|
| Pandas | Skikit-Learn |
 numpy numpy |  |
# train, test set 분리
from sklearn.model_selection import train_test_splittest_size 파라미터에 값을 전달해서 전체 데이터 중 얼마만큼을 test로 분리할지 정할 수 있습니다.
Scikit-Learn 모델링 코드 구조
불러오기 > 선언하기 > 학습하기 > 예측하기 > 평가하기
(2) 성능 평가
회귀 모델 평가
회귀 모델에서의 성능 평가는 오차를 줄이는 것을 목표로 합니다.
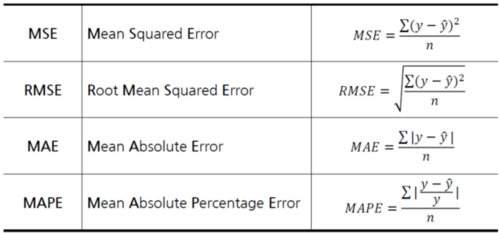
아래는 회귀 평가 지표이며, 그 값이 작을수록 모델 성능이 좋습니다.
y는 실제값, bar(y)는 평균값, hat(y)는 예측값을 의미해요.
[오차를 바라보는 관점]
- SST(Sum Squared Total): 전체 오차
- SSR(Sum Squared Regression): 전체 오차 중에서 회귀식이 잡아낸 오차
- SSE(Sum Squared Error): 전체 오차 중에서 회귀식이 잡아내지 못한 오차
따라서 SST = SSR + SSE 가 됩니다.
위 내용을 이용해서 결정 계수 R^2를 구할 수 있습니다.
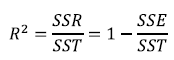
결정 계수는 전체 오차에서 회귀식이 잡아낸 오차 비율을 말합니다.
R2값이 0에 가까울 수록 모델이 데이터를 잘 학습했다고 할 수 있어요.
분류 모델 평가
분류 모델에서의 성능 평가는 정확도를 높이는 것을 목표로 합니다.
평가한 값은 혼동 행렬(Confusion Matrix)를 이용하여 이름을 붙여줄 수 있습니다.
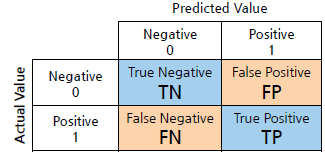
- 정확도(Accuracy) = (TN+TP) / (TN+FP+FN+TP)
- 정밀도(Precision) = TP / (FP+TP) #예측 관점
- 재현율(Recall) = TP / (FN+TP) #실제 관점
(3) 기본 알고리즘
기본 알고리즘은 아래 테이블에 나와있는 함수에 대해 설명을 듣고 직접 실습을 해보면서 익숙해지는 연습을 진행했습니다😊
분류와 회귀에 따른 함수 사용
| 함수 구분 | 분류 문제 | 회귀 문제 |
|---|---|---|
| 모델링 | ||
| ---------- | ----------------------------- | --------------------------------------- |
| 평가 | ||
(4) K-Fold Cross Validation
from sklearn.model_selection import cross_val_score모델을 선언한 후에 model, x_train, y_train, cv 값을 차례대로 입력해서 K-분할 교차 검증을 사용할 수 있습니다.
cv의 default값은 5이며, cross_val_score 함수를 통해 얻은 결과로 얻은 성능들의 평균을 모델의 성능으로 예측합니다.
(5) Hyperparameter 튜닝
KNN과 DecisionTree에서 하이퍼파라미터에 따른 결과의 차이를 알아보고 최적의 하이퍼파라미터를 찾는 방법을 생각하는 시간을 가졌습니다.
- Grid Search
- 파라미터값 범위 전체를 학습
- 넓은 범위와 큰 Step으로 설정 후 범위를 좁혀 나가며 시간 단축
- Random Search
- 파라미터값 범위에서 일부를 선택하여 학습
- n_iter에 수행 횟수를 입력해 임의로 선택할 파라미터 조합 수 지정
모델링의 목표는 완벽이 아닌 적절한 예측력이기 때문에 실제 평가 결과가 기대에 못 미치더라도 만족해야해요😅
(6) 앙상블
앙상블이란?
여러 개의 모델을 결합하여 훨씬 강력한 모델을 생성하는 기법
앙상블에서는
- 보팅(Voting)
- 배깅(Bagging)
- 부스팅(Boosting)
- 스태킹(Stacking)
에 대하여 알아보는 시간을 가졌습니다.
