학습 내용
Generative Modele
- 주어진 학습 데이터를 학습하여 학습 데이터의 분포를 따르는 유사한 데이터를 생성하는 모델이다.
- 이러한 생성모델에도 여러가지 방식이 존재한다.
- Explicit Density Model
- 학습 데이터의 분포를 기반으로 생성
- Implicit Density Model
- 이러한 분포를 알지못하더라도 생성
- Approximate Density Model
- 이러한 분포를 추정하는 방법
- Generative Adversarial Network(GAN)
- 적대적 생성모델
- Explicit Density Model
Explicit Density
- 체인룰을 활용하여 이전 픽셀들의 값을 통해 현재 픽셀의 값을 결정하는 것이다.
- 이미지 전체에 대해서 데이터를 생성할 수 있다.
- 위의 함수를 최대화하는 것이 목표이다.
- 이전 픽셀을 어떻게 정의할 것인가가 문제이다.
PixelRNN
- 왼쪽 상단의 픽셀부터 오른쪽 하단의 픽셀 방향으로 진행된다.
- 체인룰을 통해서 직접적으로 학습데이터의 분포를 구하는 것이다.
- RNN(LSTM)과 같은 모델을 사용하여 이전 픽셀에 대한 의존도를 모델링한다.
- 동일하게 위의 함수를 최대화하는 것이 훈련 목표이다.
- 특징
- 심플한 생성형 모델이다.
- 해당 모델이 과거의 데이터(이전 pixel value)를 기반으로 현재의 데이터를 결정하기 때문에, 속도적인 측면에서 느리다.
Approximate Density
- 데이터 X를 보고 확률 분포를 추정하는 방법이다.
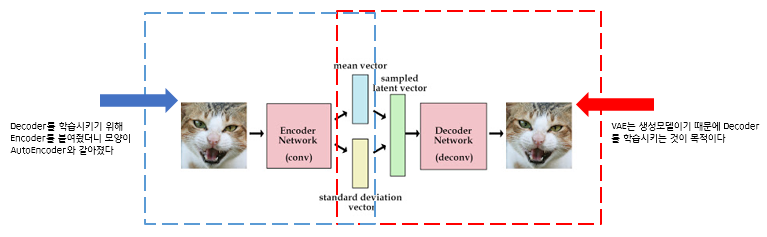
Variational Autoencoder (VAE)
- 원본 데이터의 특성을 압축해서 복원하는 Encoder-Decoder 관계를 응용한 모델이다.
- Auto-Encoder와의 차이점
- AE는 동일한 구조에서 원본 데이터와 복원된 데이터의 차이(reconstruction loss)를 최소화 시키기 위해서 학습된다. 즉, x에서 압축된 latent vector에서 다시 x를 만드는 것을 학습한다.
- VAE는 입력 데이터를 latent vector로 압축할 때 확률적인 접근을 사용한다. 일반적으로 정규분포를 따른다.
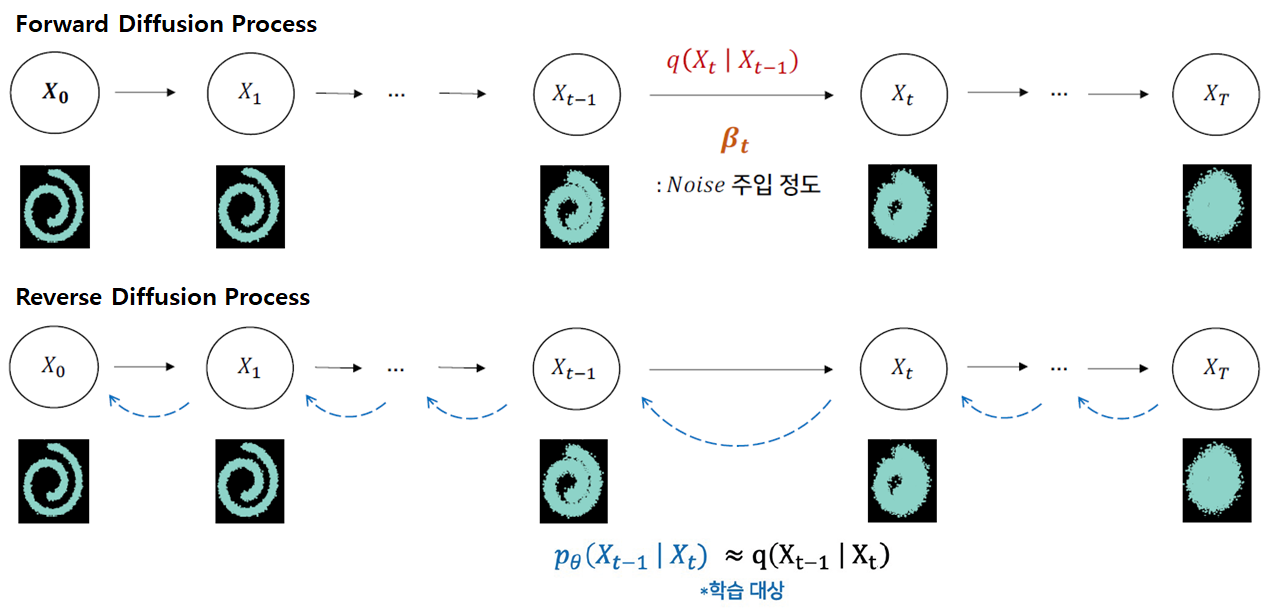
Denoising Diffusion Probabilistic Models (DDPM)
- DDPM은 Markovian 순서의 순방향 및 역방향 과정을 통해 점진적으로 이미지를 노이즈 제거하는 방법을 학습하는 생성 모델이다.
- Encoder 부분에서 각 timestep마다 기존의 이미지에 가우시안 분포를 따르는 noise를 추가해준다. 여기서 학습을 하는 부분은 noise가 추가된 이미지에서 noise를 제거하는 Denoising 과정에서 이루어진다. 즉, t시점의 noise가 추가된 이미지가 들어가면 t - 1시점의 이미지가 결과로 나오는 것이다.
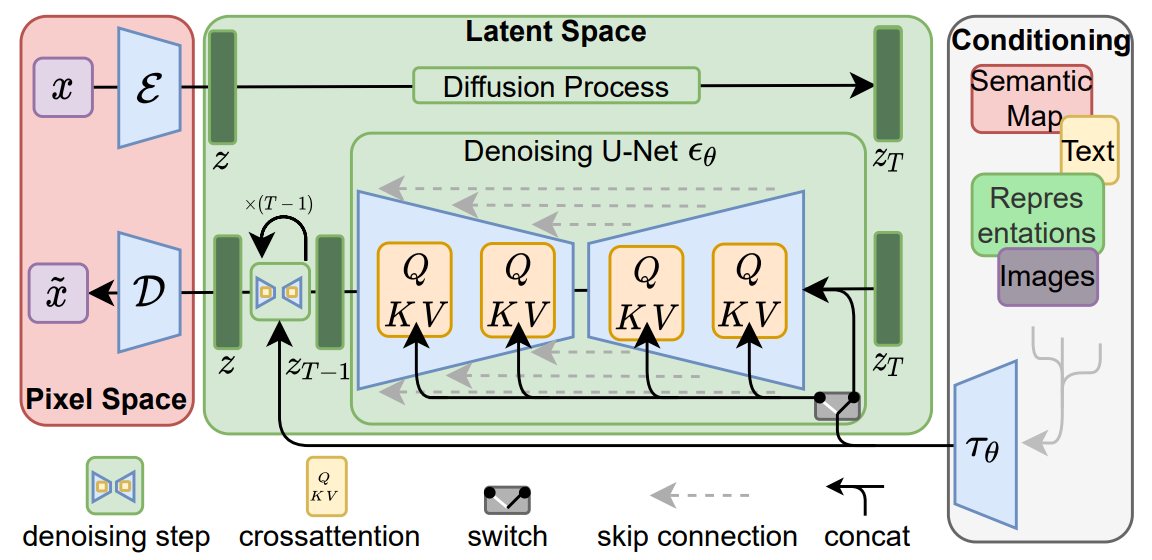
Latent Diffusion Model (Stable Diffusion)
- 이전의 DDPM은 최적화를 위한 비용이 엄청났고, 순차적으로 과정이 진행되기 때문에 비효율적인 추론이 이루어지는 문제가 발생하였다.
- 이러한 문제를 해결하기 위해서 등장한 모델이다.
- latent vector를 이용하여 계산 비용이 훨씬 적고, 높은 효율로 학습이 가능하다.
그 외의 더 많은 것
- ControlNet
- Canny Edge, Human Pose와 같은 것들을 condition으로 넣어줄 수 있다.
- condition의 집합도 가능
- LoRA (Low - Rank Adaptation)
Generative models 활용사례
추가 예정

기동코딩