학습 정리
CNN (Convolutional Neural Networks)
- iamge classification task에서 기존의 FCNN(Fully Connected Neural Network)는 작은 변화가 생긴 이미지가 입력으로 들어오면 제대로 예측을 하지 못하였다.
- 모든 픽셀에 대해서 weight이 존재하였기 때문에 변화에 민감하다.
- 이러한 문제를 완화할 수 있는 방법이 지역적 특성을 학습하고, 파라미터를 공유하는 CNN이다.
- CNN은 다양한 CV Tasks의 Backbone으로 활용된다.
Brief History
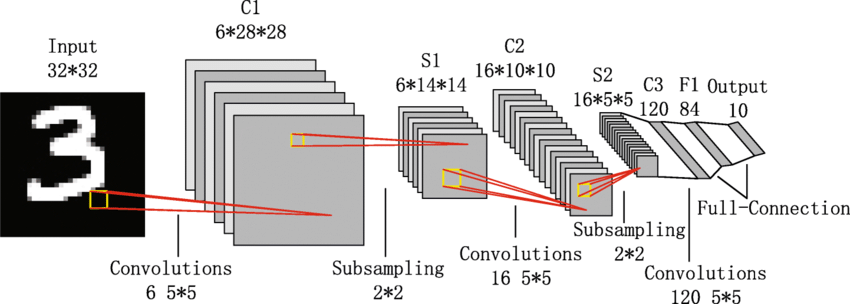
LeNet-5 (1998)
- 아주 간단한 CNN 구조
- Conv - Pool - Conv - Pool - FC - FC
- Convolution : filters with stride 1
- Pool : max pooling with stride 2
AlexNet (2012)
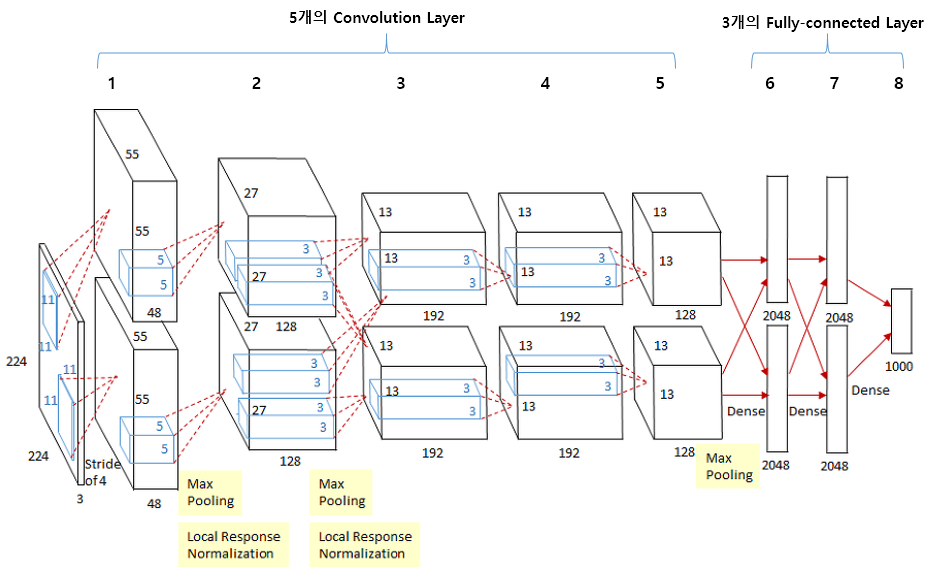
- CNN의 부흥에 아주 큰 역할을 한 구조이다.
- LeNet-5의 기본구조와 크게 다르지 않다.
- 7 Hidden Layer, 605k개의 neurons, 60 million parameters
- ImageNet을 활용하여 학습시켰다.
- 그당시 기울기 소실 문제를 해결하기 위해서 ReLU(Activation Function)을 사용하였다.
- 이를 기반으로 7 layer 학습
- 정규화 기술인 DropOut 사용
- 2개의 GPU를 활용하여 병렬연산을 수행하였다.
- Conv - Pool - LRN - Conv - Pool - LRN - Conv - Conv - Conv - Pool - FC - FC - FC
- LRN : Local Response Normalization
VGGNet (2015)
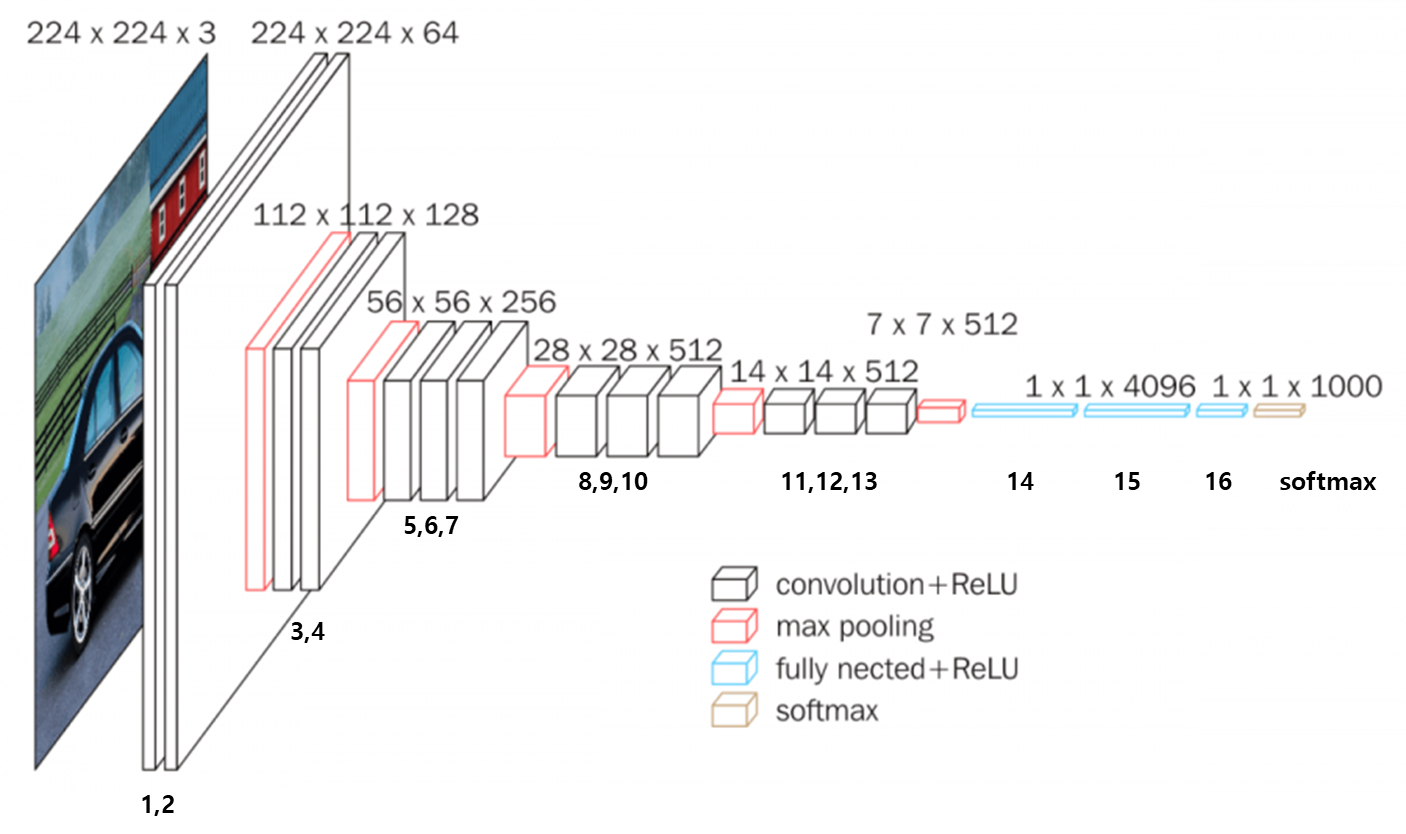
- AlexNet에서 사용된 LRN은 사용하지 않는다.
- 오직 conv filters와 max pooling을 사용한다.
- AlexNet에 비해서 상당한 성능향상을 보여준다.
- fine-tuning없이 다른 작업에 괜찮은 일반화 성능을 보인다.
- 많은 수의 conv layer를 사용하는게 적은 수의 큰 conv layer를 사용하는 것보다 좋은 점
- 충분히 큰 Receptive Field를 유지할 수 있다.
- 더 많은 비선형성으로 더 깊게
- 더 적은 파라미터
ResNet
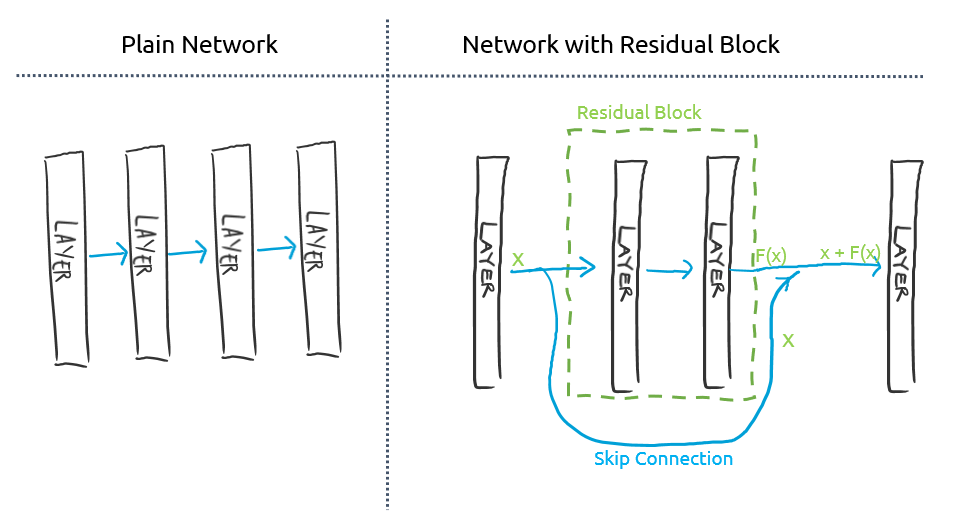
- 깊은 신경망이 더 많은 특성을 학습한다.
- Large Receptive fields
- 더 많은 비선형성과 수용력
- 하지만 깊은 신경망은 최적화에 어렵다.
- Gradient Vanishing / Exploding 문제가 있다.
- Degradation Problem : 성능이 약화되는 문제
- 이러한 문제를 해결한 Model이 Residual Block을 사용한 ResNet이다.
- Residual Block
- 한 layer의 결과값을 바로 다음 layer에만 넣어주는 것이 아니라 좀 더 뒤에 있는 layer에도 넣어주는 것이다.
- 이 연결을 skip connection이라 하고, 이 skip connection이 있는 레이어들을 Residual block이라고 한다.
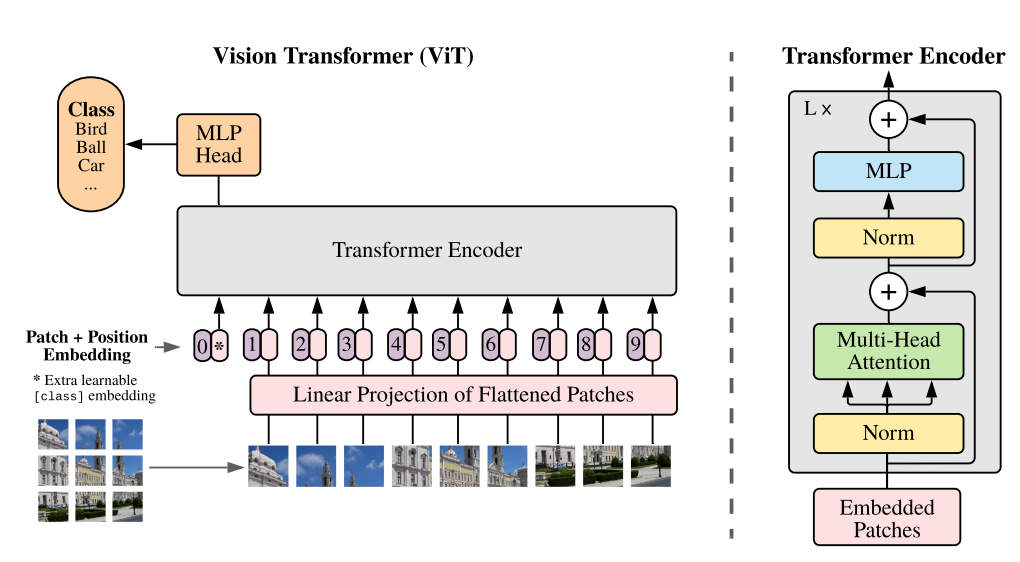
ViT (Vision Transformers)
- NLP 분야에서 성공적인 성과를 거둔 Transformer를 Image에 적용한 것이다.
- 기존의 Long-Term Dependency를 해결하며 Transformer 구조를 Vision 분야에 결합시킨 것이다.
- Overall Architecture
- 이미지를 고정된 크기의 patch로 나눈다.
- 는 기존 이미지의 해상도
- 는 채널의 수
- 는 고정된 patch의 해상도
- 은 patch의 수
- 나눠진 patch를 Linear Projection을 통해서 임베딩한다.
- 임베딩 결과에 학습 가능한 cls token을 추가해주고, position embedding을 더해준다.
- Transformer Encoder 과정을 거친다.
- MLP Head에서 cls token을 이용해 classification을 진행한다.
- 이미지를 고정된 크기의 patch로 나눈다.
Additional ViTs
Swin Transformer
- image patches를 합쳐 계층적 feature map을 만든다.
- 기존의 ViT의 경우 self-attention의 계산 복잡도가 이미지 크기의 제곱에 비례하기 때문에 고해상도 이미지에서 처리하기 어렵다. 하지만 Swin Transformer는 각 로컬 윈도우내에서만 self-attention을 계산하기 때문에 선형 계산 복잡도를 가진다.
- 중간 단계의 feature map은 고해상도가 필요한 segmentation, detection에 맞는 특징을 유도할 수 있도록 구성되어있다.
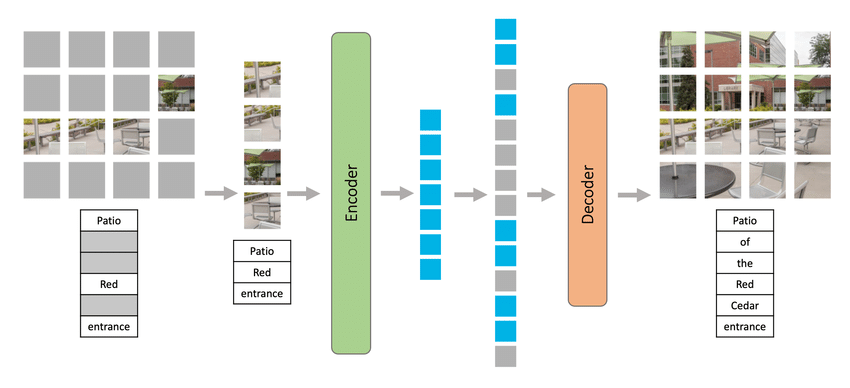
Masked Autoencoders (MAE)
- 학습 중에서 이미지 patch의 large random 하위 집합을 마스킹한다. ex) 75%
- 마스킹된 입력값으로부터 기존의 ground truth를 예측하는 모델이다.
- encoder 부분 이후에 masked token들을 추가하여 decoder를 통해서 masking된 부분의 이미지를 예측하는 과정이다.
- 마스킹된 부분에 대해서는 연산이 이루어지지 않기 때문에 굉장히 효율적이다.
- visual data의 구성과 생성에 대해서 이해하는 방식으로 학습이 된다고 볼 수 있다.
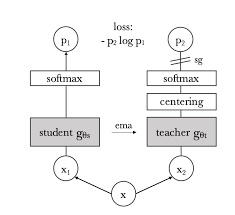
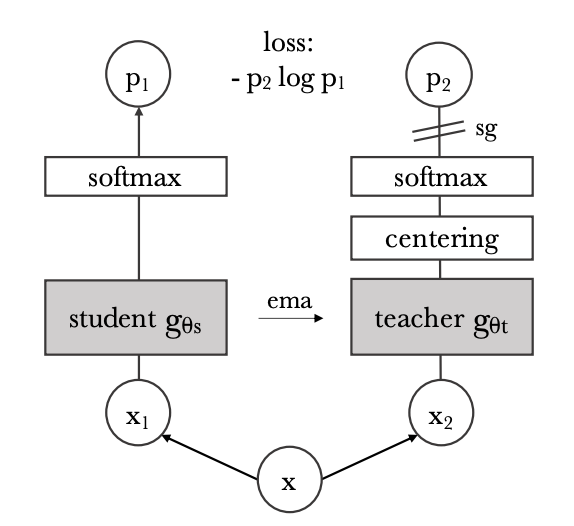
DINO
- knowledge-distillation을 이용한 방식이다.
- 는 두 가지 다른 무작위 변환을 적용한 입력 이미지
- 두 네크워크(student, teacher)는 동일한 아키텍처를 가지지만 서로 다른 파라미터를 가진다.
- 네트워크 출력의 유사성은 cross-entropy loss를 통해서 측정한다.
- student에게만 gradient가 전파되고, teacher에게는 stop-gradient
- teacher parameter는 student parameter의 지수 이동 평균으로 업데이트된다.
- teacher`s output은 centering과 sharpening을 통해서 collapse 현상을 피한다.

기동코딩