학습 정리
결측치
- 데이터 셋에서 누락된 값을 이야기한다 (Null, NA, Nan 등)
- 분석 관점에서는 "데이터가 없다"라는 정보 자체에도 의미가 있다.
- 데이터가 있다 / 없다 로 구분지어 이진 변수 추가를 할 수 있다.
- 대다수 모델에는 공백으로 집어넣을 수 없다. (처리가 가능한 모델도 존재한다.)
- 0으로 채워넣으면 되지 않을까?
- 0 또한 값이기 때문에 결과에 악영향을 줄 수 있다.
- 다양한 가정을 통해 적절한 전략을 정해야 한다.
- 만약 결측치가 포함된 행을 제외 / 예측한다면 데이터의 편향이 강화되어 모델 성능에 타격이 있을 수 있다.
- 만약 결측치가 포함된 열을 제외 / 예측한다면 데이터의 종류에 따라서 결측치 포함열의 데이터가 매우 중요할 수 있다.
- 결측치 처리에는 2가지 종류가 있다.
- 제외
- 예측
- Missingno라는 라이브러리를 통해서 시각화 가능
결측치와 EDA
- 규칙 기반
- 도메인 지식이나 논리적 추론에 의한 방법
- 지나치게 복잡하거나 단순한 경우 잘못된 편향이 반영된다.
- 집단 대푯값
- 특정 집단의 대푯값(평균, 중앙값, 최빈값) 등으로 결측치를 대체한다.
- 집단 설계가 중요하며 이상치에 민감할 수 있다.
- 모델 기반
- 회귀모델을 포함한 다양한 모델을 통해 예측한다.
- 복잡한 패턴을 예측할 수 있으나 결측치를 예측하는 모델이 과적합될 가능성이 있다.
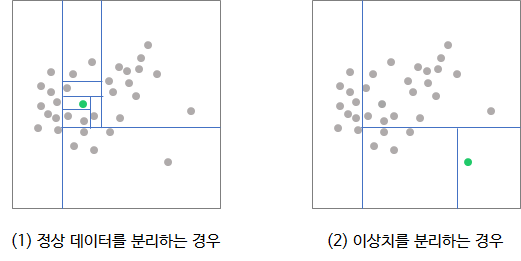
이상치 (Outlier)
- 관측된 데이터의 범위에서 과하게 벗어난 값을 의미한다.
- but, 명확한 기준은 없다. -> 어느 정도를 벗어나야지 이상치인지 기준이 없다는 뜻이다.
- 대표적으로 사용되는 기준
- 사분위수 (IQR)
- 표준편차 / z-score
- DBSCAN
- Isolation Forest
DBSCAN
- 밀도 기반 클러스터링 방법
- 주변 포인트의 개수 / 경계 / 노이즈 등을 설정하여 집단 자동 설정
- K-Mean과 유사하게 주변 데이터 거리 기반 개수를 세기에 정규화 작업이 필수적이다.
- 클러스터에 동떨어진 포인트가 생긴다면 자동적으로 이상치처리를 한다.
- 밀도가 어느정도 균일한 데이터에 대해서만 시행할 수 있다.
- 다양한 파라미터를 통해서 많은 시도를 해보아야한다.
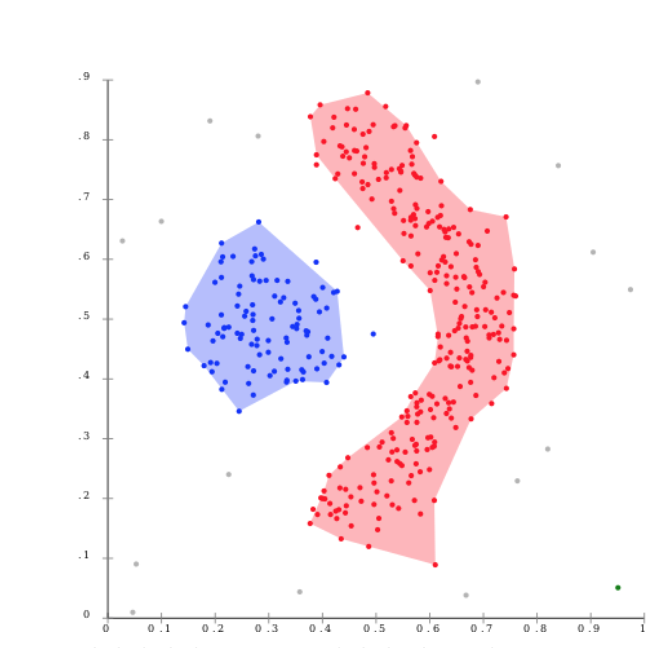
Isolated Forest
- Decision Tree와 같이 기준에 따라 그룹이 분리된다.
- 루트 노드와 거리를 통해 이상치 탐지가 이루어진다.
- 동일하게 거리 정규화는 필수 작업이다.
- 랜덤에 기반한 초기 분리에 따라 이상치가 존재한다.
- 이상치가 많은 경우에 대해서는 효과적이지 못한 모습을 보인다.
클러스터링
- 유사한 성격을 가진 데이터를 그룹으로 분류하는 것을 의미한다.
- 데이터 전 과정에서 유의미하게 사용될 수 있다.
- [관찰] EDA 작업에서 대략적인 그룹에 대한 확인
- [모델] 모델에 사용할 새로운 피쳐 (특성 추출)
- [해석 및 결정] 최종 그룹 구분 및 의사 결정
- 대표적인 방법
- K-Mean
- 데이터를 K개로 그룹화하여, 각 클러스터의 중심점을 기준으로 데이터 분리
- Hierarchical Clustering
- 데이터를 점진적으로 분류하는 방법
- DBSCAN
- 밀도 기반 클러스터링
- GMM
- 가우시안 분포가 혼합된 것으로 모델링한다.
- K-Mean
- 이러한 클러스터링 알고리즘에는 공통적인 주의사항이 있다.
- 거리 정의 방식을 사용한다.
- 대부분 유쿨리드 거리를 사용하여 거리를 측정하기 때문에 데이터 전처리가 중요하다.
- 클러스터 결과 기록과 해석이다.
- 개수가 정해진 것과 정해지지 않은 것
- 예외치에 대한 해석과 그룹에 대한 해석
- 시각화
- 거리 정의 방식을 사용한다.
차원축소
- 다차원 데이터를 이해하기 위한 대표적인 방법이다.
- 특성 추출 방법 중에 하나로 데이터의 특성을 N개에서 M개로 줄이는 방법이다.
- 고차원 데이터에서 차원을 줄임으로써 데이터의 복잡성을 감소시킬 수 있다.
- 시각화를 통해서 패턴을 발견하기에 좋고 이는 클러스터링과도 깊은 관련이 있다.
- 모델의 성능을 향상 시킬 수 있다.
- 방향점은 정보를 최대한 보유하고, 왜곡을 최소화해야 한다.
- 가까운 데이터는 더 가깝게, 먼 데이터는 더 멀게
- 대표적인 방법 소개
- PCA
- 데이터의 공분산을 계산하여 고유 벡터를 찾아 projection하는 방식이다
- lsomap
- 고차원에서 최단 경로 거리에 대한 정보를 저장하는 방식이다.
- Autoencoder
- 인코더 / 디코더 구조로 고차원 데이터의 정보를 최대한 저장한 저차원 공간을 이야기한다.
- PCA

기동코딩