공부 정리를 위한 글입니다.
트랜스포머
2. 디코더
2.1 디코더 개념
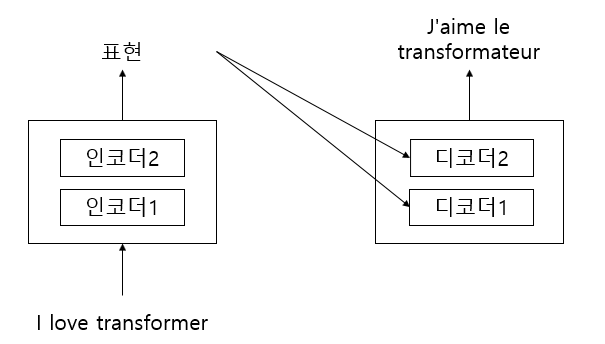
앞선 글에서 인코더는 N개를 누적하여 쌓을 수 있다는 것을 확인했다. 디코더도 인코더와 동일하게 쌓을 수 있다. N = 2로 예를 들면 인코더가 2개 디코더가 2개로 이루어진 트랜스포머 모델이 만들어진다.
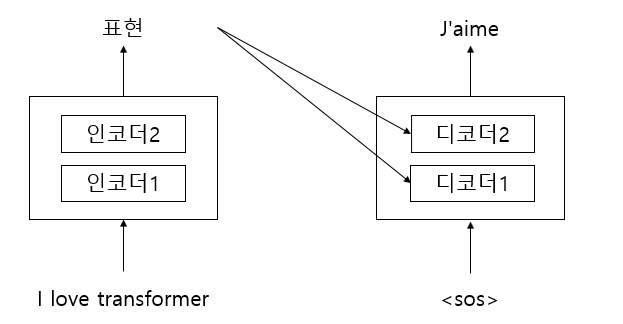
디코더에서는 시간 스텝 t = 1이면 디코더의 입력값은 문장의 시간을 알리는 <sos>를 입력한다. 이 입력값을 받은 디코더는 타깃 문장의 첫번째 단어 "J'aime"을 생성한다.
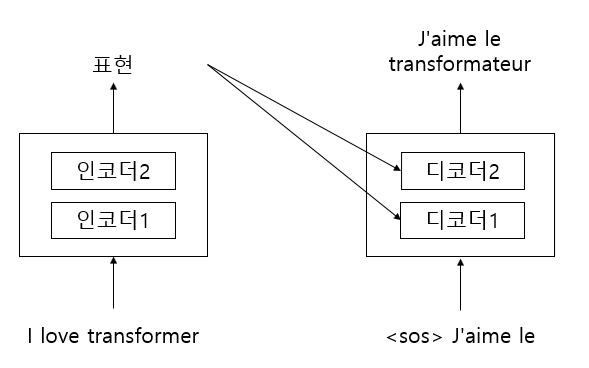
이와 같이 시간 스텝 t = 3이면 이전 단계와 동일한 방법으로 진행한다. 이때 입력은 <sos>, "J'aime", "le"이고 위 그림과 같은 단어를 생성한다.
이런식으로 모든 단계에서 디코더는 이전 단계에서 새로 생성한 단어를 조합해 입력값을 생성하고 이를 이용해 다음 단어를 예측하는 방법으로 진행한다. 이러한 반복은 문장의 끝을 알리는 <eos>를 생성할때까지 진행된다.
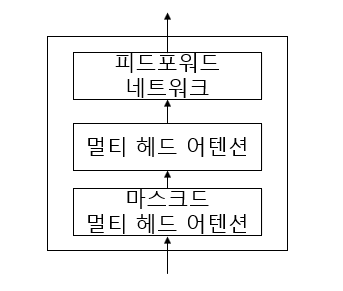
디코더는 크게 3가지 요소로 구성된다.
- 마스크드 멀티 헤드 어텐션
- 멀티 헤드 어텐션
- 피드포워드 네트워크
2.2 마스크드 멀티 헤드 어텐션
디코더에서는 생성한 단어를 조합해 입력값을 생성하는 형태로 동작을 한다. 그렇기 때문에 <sos> 가 입력 됐을 시점에는 "J'aime"에 단어를 볼 수 없어야한다. 단어의 입력 시간에 맞춰 뒤의 단어들을 가려 입력된 단어에만 집중해 단어를 생성하게 한다.
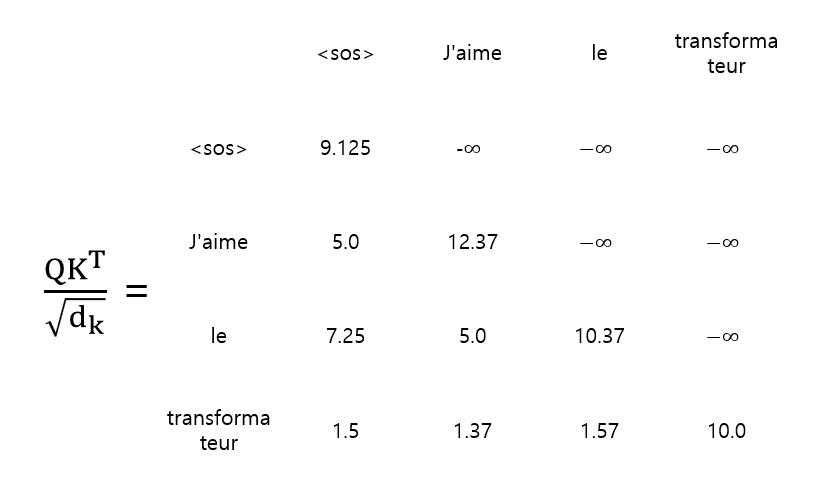
멀티 헤드 어텐션에서 사용하는 것과 같이 계산하는 것에서 t 시점에 따라 값을 가려두어 마스킹 한다.
# utils.py
import torch
from einops import rearrange, repeat
def make_mask(tensor: torch.tensor, option: str) -> torch.Tensor:
"""
Args:
tensor (torch.tensor): 입력 텐서
option (str): padding 옵션
Returns:
torch.Tensor: 마스크된 텐서
"""
if option == 'padding':
tmp = torch.full_like(tensor, fill_value=0)
mask = (tensor != tmp).float()
mask = rearrange(mask, 'bs seq_len -> bs 1 1 seq_len')
elif option == 'lookahead':
padding_mask = make_mask(tensor, 'padding')
padding_mask = repeat(padding_mask, 'bs 1 1 k_len -> bs 1 new k_len', new=padding_mask.shape[3])
mask = torch.ones_like(padding_mask)
mask = torch.tril(mask)
mask = mask * padding_mask
return mask2.3 멀티 헤드 어텐션
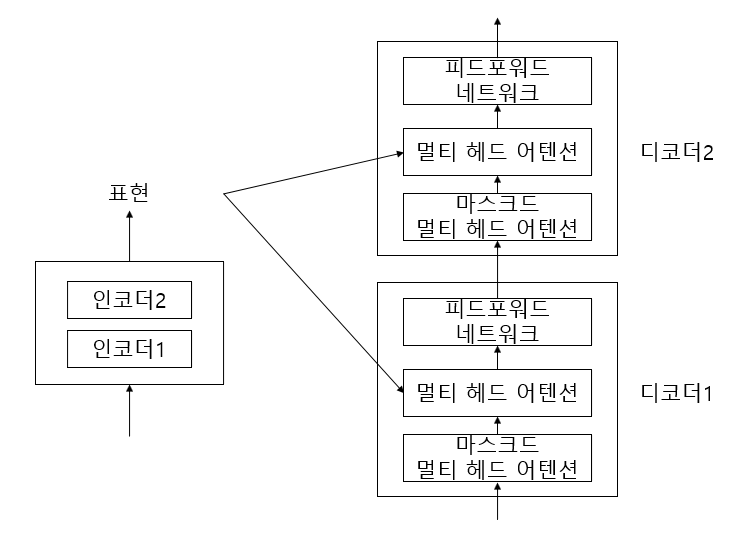
디코더의 멀티 헤드 어텐션은 입력 데이터를 2개 받는다. 하나는 이전 서브레이어의 출력값이고, 다른 하나는 인코더의 표현이다. 인코더의 결과와 디코더의 결과 사이에 상호작용이 일어나는대 인코더-디코더 어텐션 레이어라고 한다.
인코더의 표현값을 R, 이전 서브레이어에서 나온 어텐션 해렬을 M이라고 하면 어텐션 행렬 M을 사용해 쿼리 행렬 Q 를 만들고, R을 활용해 키, 밸류 행렬을 생성한다.
그렇게 생성된 쿼리 행렬과 키 행렬간의 내적을 구하고 밸류 행렬을 곱해 스코어 행렬을 만든다. 그 다음 소프트맥스를 취해 어텐션 행렬 Z를 얻는다.
# decoder_layer.py
import torch.nn as nn
from module.multihead_attention import MultiHeadAttention
from module.positionwise_feed_forward import PositionwiseFeedForwad
class DecoderLayer(nn.Module):
def __init__(self, d_model, n_heads, hidden, dropout) -> None:
super().__init__()
self.attention1 = MultiHeadAttention(d_model, n_heads)
self.attention2 = MultiHeadAttention(d_model, n_heads)
self.ff = PositionwiseFeedForwad(d_model, hidden)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
def forward(self, inputs, enc_outputs, padding_mask, look_ahead_mask):
"""
Args:
inputs : 입력 데이터
enc_outputs : 인코더의 표현값(R)
padding_mask : 패딩 마스크
look_ahead_mask : 마스크
Returns:
outputs : 디코더의 표현값
"""
# 마스크드 멀티 헤드 어텐션 (M)
attention1 = self.attention1({'query': inputs, 'key': inputs, 'value': inputs, 'mask': look_ahead_mask})
attention1 = self.norm1(inputs + attention1)
# 멀티 헤드 어텐션 (R, M) : 인코더-디코더 어텐션 레이어
attention2 = self.attention2({'query': attention1, 'key': enc_outputs, 'value': enc_outputs, 'mask': padding_mask})
# 드롭아웃 + 잔차연결및 층 정규화
attention2 = self.dropout1(attention2)
attention2 = self.norm2(attention1 + attention2)
# 피드포워드
outputs = self.ff(attention2)
# 드롭아웃 + 잔차연결및 층 정규화
outputs = self.dropout3(outputs)
outputs = self.norm3(attention2 + outputs)
return outputs# decoder.py
import math
import torch.nn as nn
from module.postional_encoding import PositionalEncoder
from module.decoder_layer import DecoderLayer
class Decoder(nn.Module):
def __init__(self, vocab_size, num_layers, d_model, n_heads, hidden, max_len, dropout) -> None:
super().__init__()
self.d_model =d_model
self.embedding = nn.Embedding(vocab_size, d_model)
self.pos_embedding = PositionalEncoder(max_len, d_model)
self.dec_layers = nn.ModuleList([DecoderLayer(d_model, n_heads, hidden, dropout) for _ in range(num_layers)])
self.dropout = nn.Dropout(dropout)
def forward(self, enc_output, dec_input, padding_mask, look_ahead_mask):
embedding = self.embedding(dec_input)
embedding *= math.sqrt(self.d_model)
embedding = self.pos_embedding(embedding)
outputs = self.dropout(embedding)
for layer in self.dec_layers:
outputs = layer(outputs, enc_output, padding_mask, look_ahead_mask)
return outputs