공부 정리를 위한 글입니다.
트랜스포머
트랜스포머는 자연어처리에서 자주 사용하는 딥러닝 아키텍처 중 하나다. 트랜스포머가 나온 이후로는 RNN과 LSTM를 사용한 태스크는 트랜스포머로 많이 대체되었다. 또한 BERT, GPT, T5 등과 같은 자연어 처리 모델에 트랜스포머 아키텍처가 적용됐다.
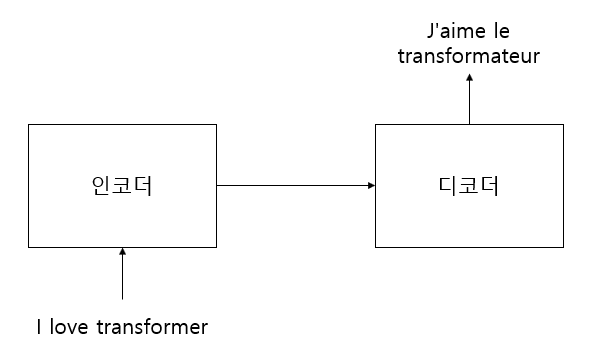
트랜스포머는 인코더-디코더로 구성된 모델이다. 인코더에 입력 문장을 입력하면 인코더는 표현 방법을 학습시키고 디코더 쪽으로 보낸다. 디코더는 인코더에서 학습한 표현 결과를 입력받아 사용자가 원하는 문장을 생성한다.
1. 인코더
1.1 인코더 개념
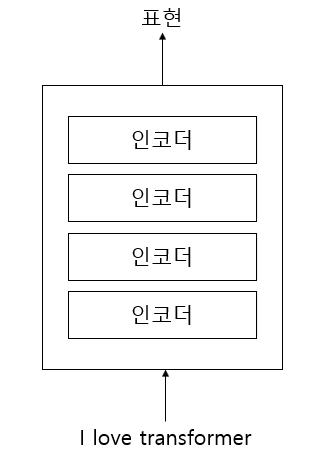
트랜스포머는 N개의 인코더가 쌓인 형태이며, 최종 인코더의 결과값으로 입력 문장의 따르는 표현 결과를 얻는다.
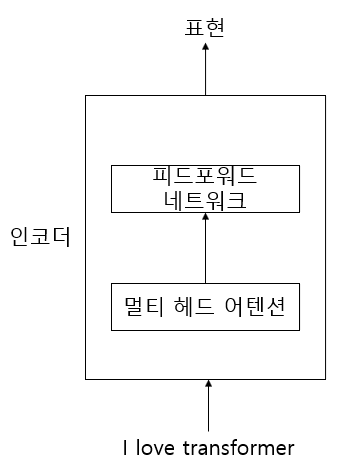
- 멀티 헤드 어텐션
- 피드포워드 네트워크
인코더는 크게 두 가지 요소로 구성되는대 멀티 헤드 어텐션과 피드포워드 네트워크이다.
1.2 셀프 어텐션
멀티 헤드 어텐션을 알기위해서는 셀프 어텐션의 개념을 알아야한다.
a dog ate the food because it was hungry위 문장에서 "it"이 "food"를 가르키는지 "dog"를 가르키는지 "it"라는 단어의 의미를 이해하기 위해 셀프 어텐션이 필요하다.
입력 문장이 "I love transformer"라고 했을 때 각 단어의 임베딩을 추출하면

위와 같은 형태가 된다. 위 문장의 단어 수는 3이고 임베딩 차원은 512라고 가정하면 입력 행렬은 [3 x 512]가 된다.
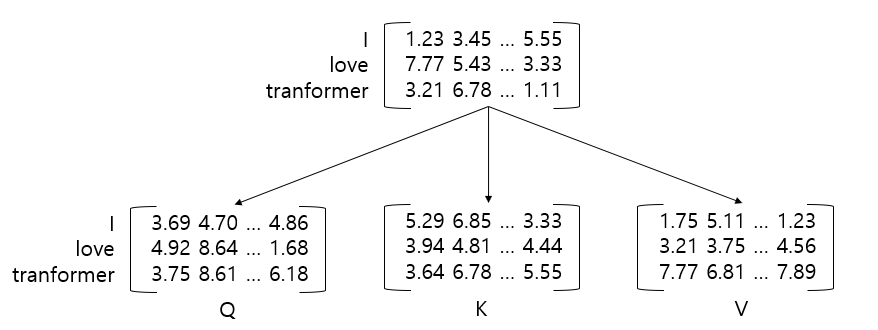
입력 임베딩을 통해 3개의 가중치 행렬을 입력 행렬과 곱해 쿼리 행렬, 키 행렬, 밸류 행렬을 생성하게 된다.
1단계
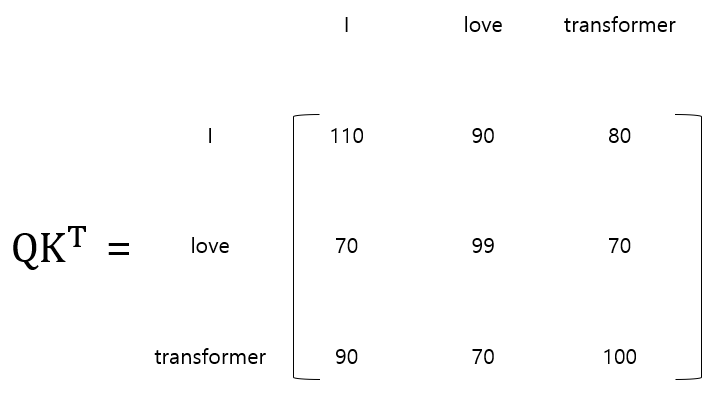
쿼리 행렬(Q)과 키 행렬(K)의 내적 연산을 취한다.
2단계

내적 행렬을 키 벡터 차원의 제곱근값으로 나눈다. 키 벡터의 차원은 64로 가정한다.
3단계

소프트맥스 함수를 사용하여 정규화를 진행한다. 이 행렬을 스코어 행렬이라고 한다.
4단계
스코어 행렬과 밸류 행렬을 곱하여 어텐션 행렬을 구한다.
이렇게 구해진 어텐션 값은 아까의 예제처럼 "it" 값이 "food"가 아닌 "dog"와 관련이 있다는 것을 알 수 있게한다.
이러한 셀프 어텐션은 스케일 닷 프로덕트 어텐션이라고도 부른다.
1.3 멀티 헤드 어텐션
어텐션의 정확도를 높이기 위해서 단일 헤드 어텐션 행렬이 아닌 멀티 헤드 어텐션을 사용한 후 그 결과값을 더하는 형태로 진행한다.

h개의 어텐션 행렬을 구한 후 연결한 후 가중치 행렬을 곱한다.
멀티 헤드 어텐션 코드
# multihead_attention.py
import torch
import torch.nn as nn
from einops import rearrange
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, n_heads) -> torch.Tensor:
super().__init__()
assert d_model & n_heads == 0
self.n_heads = n_heads
self.head_dim = d_model // n_heads
self.q = nn.Linear(d_model, d_model)
self.k = nn.Linear(d_model, d_model)
self.v = nn.Linear(d_model, d_model)
self.out = nn.Linear(d_model, d_model)
def forward(self, inputs):
q, k, v, mask = inputs['query'], inputs['key'], inputs['value'], inputs['mask']
batch_size = q.size(0)
# WQ, WK, WV
q = self.q(q)
k = self.k(k)
v = self.v(v)
# 헤드 나누기
q = rearrange(q, "bs seq_len (n_heads head_dim) -> bs n_heads seq_len head_dim", n_heads=self.n_heads)
k_T = rearrange(k, "bs seq_len (n_heads head_dim) -> bs n_heads head_dim seq_len", n_heads=self.n_heads)
v = rearrange(v, "bs seq_len (n_heads head_dim) -> bs n_heads seq_len head_dim", n_heads=self.n_heads)
score = torch.matmul(q, k_T)
# MASK
if mask is not None:
score = score.masked_fill(mask == 0, -1e-12)
# SCALED DOT PRODUCT
score = torch.softmax(score, dim=-1)
result = torch.matmul(score, v)
# CONCATE
result = rearrange(result, "bs n_heads seq_len head_dim -> bs seq_len (n_heads head_dim)")
output = self.out(result)
return output1.4 위치 인코딩
RNN에서는 단어 단위로 네트워크 문장을 입력하기 때문에 처음 단어가 입력으로 전달된 다음 다음 단어가 전달된다. 트랜스포머에서는 순환 구조를 따르지 않고 모든 단어를 병렬 형태로 입력한다. 병렬로 입력함으로써 학습 시간을 줄이고 RNN의 장기 의존성 문제를 해결하는데 도움이 된다.
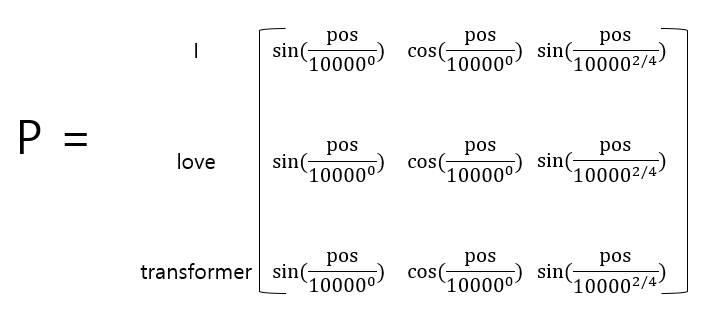
짝수인 경우 사인 함수, 홀수인 경우 코사인 함수를 사용하여 위치에 따른 가중치를 줄 수 있다.
# positional_encoding.py
import torch
import torch.nn as nn
import math
class PositionalEncoder(nn.Module):
def __init__(self, position, d_model) -> torch.Tensor:
super().__init__()
self.d_model = d_model
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
pos_encoding = torch.zeros(position, d_model).to(device)
pos = torch.arange(0, position).float().unsqueeze(1)
_2i = torch.arange(0, d_model, 2).float()
pos_encoding[:, 0::2] = torch.sin(pos / 10000 ** (_2i / d_model))
pos_encoding[:, 1::2] = torch.cos(pos / 10000 ** (_2i / d_model))
self.pos_encoding = pos_encoding.unsqueeze(0)
self.pos_encoding.requires_grad = False
def forward(self, x):
return math.sqrt(self.d_model) * x + self.pos_encoding[:, :x.size(1)]1.5 피드포워드 네트워크
피드 포워드네트워크는 2개의 덴스 레이어와 ReLu 활성화 함수로 구성된다.
# positionwise_feed_forward.py
import torch
import torch.nn as nn
class PositionwiseFeedForwad(nn.Module):
def __init__(self, d_model, hidden) -> torch.Tensor:
super().__init__()
self.fc_1 = nn.Linear(d_model, hidden)
self.fc_2 = nn.Linear(hidden, d_model)
self.relu = nn.ReLU()
def forward(self, x):
outputs = self.fc_1(x)
outputs = self.relu(outputs)
outputs = self.fc_2(outputs)
return outputs1.6 add와 norm
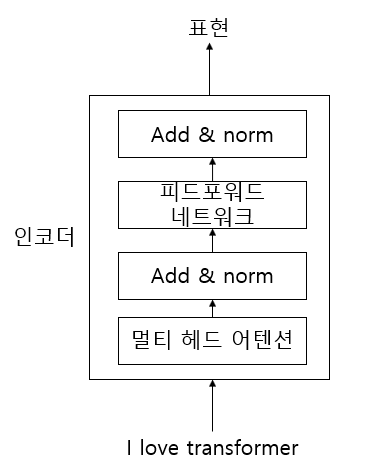
- 서브레이어에서 멀티 헤드 어텐션의 입력값과 출력값을 서로 연결
- 서브레이어에서 피드포워드의 입력값과 출력값을 서로 연결
add와 norm 요소는 레이어 정규화와 잔차 연결이다.
1.7 인코더
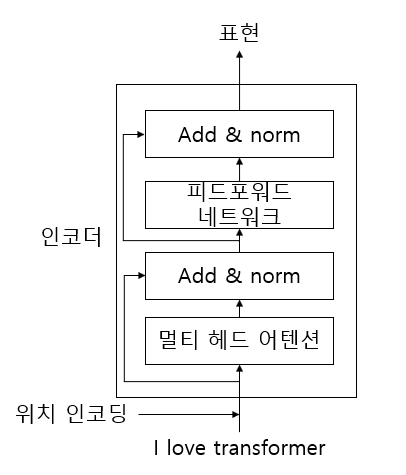
인코더의 구성 요소는 위 그림처럼 되어있고 N개의 인코더로 겹쳐져 있다. 마지막 인코더의 표현이 디코더의 입력값으로 사용한다.
# encoder_layer.py
import torch.nn as nn
from module.multihead_attention import MultiHeadAttention
from module.positionwise_feed_forward import PositionwiseFeedForwad
class EncoderLayer(nn.Module):
def __init__(self, d_model, n_heads, hidden, dropout) -> None:
super().__init__()
self.attention = MultiHeadAttention(d_model, n_heads)
self.ff = PositionwiseFeedForwad(d_model, hidden)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
def forward(self, inputs, mask=None):
# 멀티 헤드 어텐션
attention = self.attention(
{
"query" : inputs,
"key" : inputs,
"value" : inputs,
"mask" : mask
}
)
# 드롭아웃 + 잔차연결및 층 정규화
attention = self.dropout1(attention)
attention = self.norm1(inputs + attention)
# 포지션 와이즈 피드 포워드
outputs = self.ff(attention)
# 드롭아웃 + 잔차연결및 층 정규화
outputs = self.dropout2(outputs)
outputs = self.norm2(attention + outputs)
return outputs# encoder.py
import math
import torch.nn as nn
from module.encoder_layer import EncoderLayer
from module.postional_encoding import PositionalEncoder
class Encoder(nn.Module):
def __init__(self, vocab_size, num_layers, d_model, n_heads, hidden, max_len, dropout) -> None:
super().__init__()
self.d_model =d_model
self.embedding = nn.Embedding(vocab_size, d_model)
self.pos_embedding = PositionalEncoder(max_len, d_model)
self.enc_layers = nn.ModuleList([ EncoderLayer(d_model, n_heads, hidden, dropout) for _ in range(num_layers)])
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
embedding = self.embedding(x)
embedding *= math.sqrt(self.d_model)
embedding = self.pos_embedding(embedding)
outputs = self.dropout(embedding)
for layer in self.enc_layers:
outputs = layer(outputs, mask)
return outputs