
지난 글 👉 한국어 STT #3
이때까지 학습을 위해 전처리, 글자 사전 생성, transcript.txt 파일 생성, 모듈설치 및 코드 수정을 통해 아래 실행 코드를 실행하면 학습이 실행된다!
python ./bin/main.py model=ds2 train=ds2_train train.dataset_path="각자의 데이터 경로"
나는 노트북에 내장 GPU가 있었기 때문에 로컬에서 학습을 하고자 했지만...음성 파일이 30만개.. 용량만 110기가 넘었기 때문에 메모리 부족으로 학습을 할 수가 없었다. 그래도 다른 팀원(조대리)이 3070ti의 GPU가 탑재되어 있는 데스크탑이 있어서 믿고 있었다! 그런데 웬걸 cuda 버전에 따라 충돌이 발생하면서 조대리는 필요한 모듈 설치가 안되는 이슈가 발생했다.. 동시에 주최측에서 구글 colab을 제공해주긴 했지만, 학습 코드를 실행할 때마다 구글 colab에 110기가의 데이터를 올려야했고 시간도 너무 많이 잡아먹어서 우리는 다른 방법을 찾아야만 했다.
그래서 우리는 따로 구글 colab 프로와 구글 드라이브 용량 확대를 결제했다. 코랩에서 구글드라이브 연동이 되었기 때문에 구글드라이브에 110기가의 데이터를 저장하고(이것만 해도 3일정도 걸렸다..ㄷㄷ) colab 프로에서 학습을 돌렸다. 구글 colab이 12시간 주기로 런타임이 끊긴다고 하는데, 실제로는 10시간 정도 걸리는 것 같다(때에 따라 다른 것 같기도...) 그래서 런타임이 끊기면 최신 모델을 가져와서 다시 학습시키는 식으로 진행을 했고, 데이터도 6분할 해서 돌리는 등 시행착오가 많았는데.. 여튼 이번 포스팅은 학습하면서 생겼던 일들에 대해 작성해보려 한다.
(1) 구글 드라이브 연동
먼저 구글드라이브에 있는 데이터, 학습 코드 등을 colab으로 연동하기 위해서 다음과 같은 코드를 실행해 주어야 한다.
from google.colab import drive
drive.mount('/content/drive') #mount안에 경로를 던져준다.
colab은 기본적으로 working directory가 /content로 지정되어 있고, mount() 안에 던지는 인자를 각자의 상황에 맞게 바꾸어 저장만 하면된다. 또한 이 방법을 이용하면, colab에 접속하고 있는 아이디의 구글 드라이브가 아니라 다른 아이디의 구글 드라이브와도 연동이 가능하다.

이렇게 링크가 나오면 일단 링크를 클릭해보자!
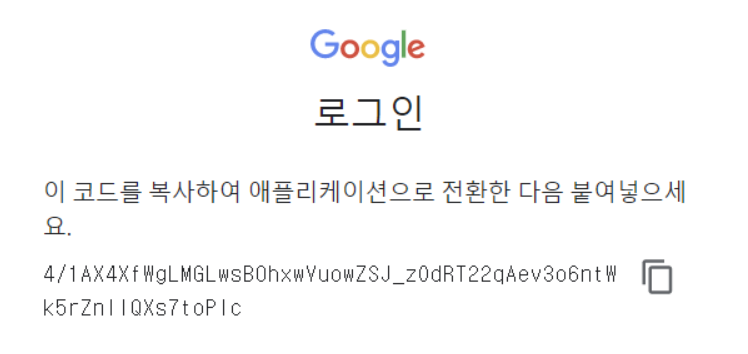
이 코드를 복사해서 위에 'Enter your authorization code:' 에 입력해주면 된다! 그리고 왼쪽 files를 새로고침 해보면,
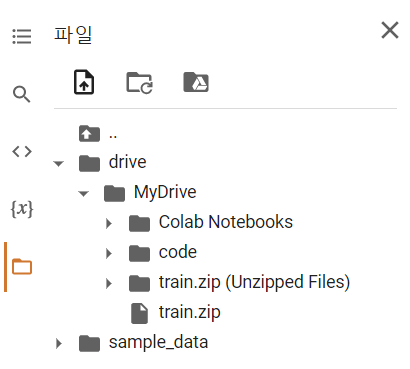
이렇게 /content/drive/MyDrive 안에 있는 파일들에 접근할 수 있게 된다!
여기서 고민..
이렇게 우리는 구글 드라이브에 학습을 위해 필요한 모든 파일을 업로드 하고 colab과 구글 드라이브를 연동해서 학습을 시작했다. 확실히 로컬에 비해 빠르게 학습하는 걸 느낄 수 있었지만, (이때까지만 해도 우리는 colab pro가 아닌 그냥 colab을 사용했었다!!) 30만 개의 데이터는 colab한테도 부담이었던 것 같다. 1epoch도 돌아가지 못하고 런타임이 계속해서 끊기는 문제가 발생했다.
일단 우리는 최소 1epoch은 돌아간 다음에 저장되는 모델의 성능을 보고 싶었기 때문에 2가지를 가지고 고민했다.
(1) 빠르게 학습을 해서 런타임 끊기기 전에 1epoch을 돌리는 방법을 찾자 (데이터 6분할 해서 나누어 학습)
(2) 그냥 colab 프로 결제를 해서 런타임을 12시간 까지 늘려보자
결론적으로는 (1)번 (2)번 둘다 선택했다ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ
학습 과정에서 찍히는 로그에 근거하면 약 1/4epoch이 학습이 되고 런타임이 끊겼기 때문에 안전하게 저장되게 하기 위해서 데이터를 6등분하여 학습을 진행했었다. 데이터를 6등분한 코드는 아래와 같다.
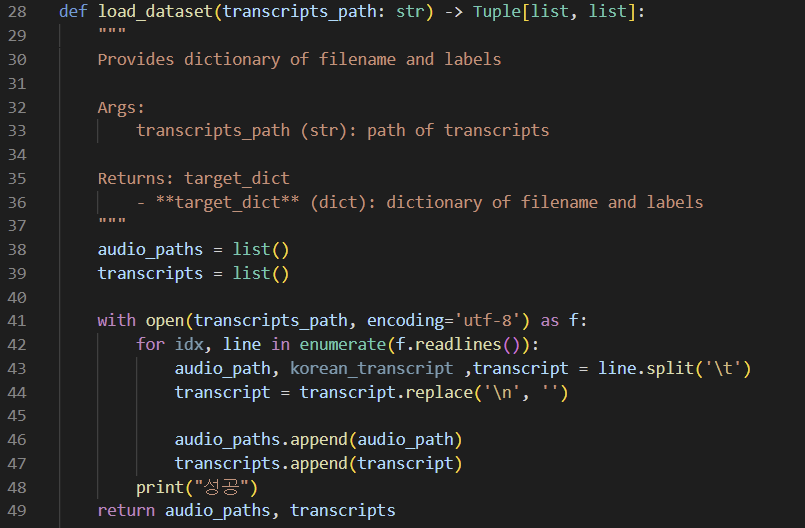
/kospeech-latest/bin/kospeech/data/label_loader.py에서 load_dataset 함수를 보면, 생성한 transcript.txt 파일로부터 오디오 파일명과 글자 사전을 이용해 숫자로 전사한 숫자 전사를 불러오는 코드가 있다. 이 부분의 idx를 이용해서 'if idx % 6 == k (k=0~5)'의 조건문을 부여해서 5만개씩만 리스트에 담도록 했다. 여기서 전체 데이터 갯수를 수정했기 때문에 이전에 수정했던 /kospeech-latest/bin/kospeech/data_loader.py의 train_num과 valid_num 역시 수정해야 한다!
(48000/2000 이렇게 수정했던 것 같다)
(2) 구글 Colab pro를 통한 학습
- 학습할 모든 준비를 마쳤으니 학습을 진행하면 되는데, 구글 pro를 사용하도록 따로 설정해야 한다.
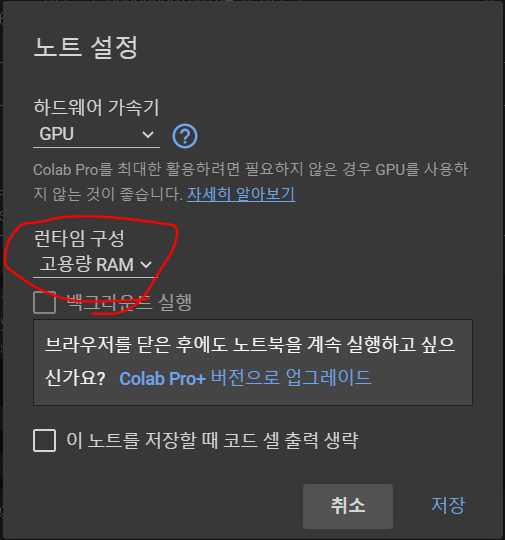
런타임 -> 런타임 유형 -> 런타임 구성: 고용량 RAM 으로 설정해주어야 한다.
- 그리고 아래와 같은 코드를 사용해서,
gpu_info = !nvidia-smi
gpu_info = '\n'.join(gpu_info)
if gpu_info.find('failed') >= 0:
print('Not connected to a GPU')
else:
print(gpu_info)
from psutil import virtual_memory
ram_gb = virtual_memory().total / 1e9
print('Your runtime has {:.1f} gigabytes of available RAM\n'.format(ram_gb))
if ram_gb < 20:
print('Not using a high-RAM runtime')
else:
print('You are using a high-RAM runtime!')- 이런 결과가 나오면 구글 pro가 연동(?)된 걸 알 수 있다.

(3) 드디어 학습 시작!
이제 아래 코드를 실행하면,
%cd "/content/drive/MyDrive/폴더명/kospeech-latest"
!pip install -e .
!python ./bin/main.py model=ds2 train=ds2_train train.dataset_path="/content/drive/MyDrive/code/train wav"- 구글 colab pro를 설정하고, 구글드라이브와 연동한 뒤 kospeech-latest 폴더로 들어가서 필요한 모듈을 설치 해준다.
- 참고로 colab은 리눅스 환경 + 자체적으로 갖추어져 있는 환경 덕분인지 'pip install -e .' 만으로 필요한 모듈이 모두 설치된다.
성공적으로 GPU를 할당받고,
학습을 진행하며 로그가 찍히는 것을 볼 수 있다!!

- 위 예시는 30만개 데이터 전체를 할당하여 진행 중인 모습이고, 데이터를 6분할 하여 학습을 시키면 1/6의 시간보다 덜 걸리는 빠른 속도로 학습이 진행된다!
- 지정한 checkpoint_every의 step 마다 모델을 outputs 폴더에 저장하게 된다.
- 모델을 불러와 학습을 진행하고 싶을 경우, configs에서 resume=True(이전 글에서 언급)로 설정하면 가장 최신 모델을 읽어와 이어서 학습을 진행한다. (우리는 이렇게 진행을 했음)
이제 이렇게 학습해 만들어진 모델을 이용해 예측을 진행하는 것만 남았다!
💡
다음 포스팅에서는 (아마 마지막 포스팅일 것 같다) 학습된 모델을 이용해서 새로운 오디오 파일을 예측을 진행하는 것과 성능 기준(cer, wer) 등에 대해서 작성할 것 같다!
🙂
