
지난 글 👉 한국어 STT #2
사실 몇시간 동안 작성했던 #3가... 임시저장을 안하고 순간 뒤로가기 하면서 다 사라져 버렸다...
모두 저장을 습관...화... 합시다......
이번 포스팅에서는 우리가 학습을 하면서 겪은 시행착오에 대해 작성해 보려 한다!
python ./bin/main.py model=ds2 train=ds2_train train.dataset_path=$DATASET_PATH
- 전처리를 통해 글사 사전을 만들고 다시 글자 사전을 이용해 transcript.txt 파일이 있다면, 위에 실행코드를 통해 학습을 진행할 수 있다.
- 그렇지만 이를 실행 하기 위해서는 디버깅을 거쳐야 하고 우리는 위의 코드를 무한 반복하면서 발생하는 에러들을 모두 수정해 주었다.
- 지난 포스팅에서도 설명했지만 먼저 /kospeech-latest/에 들어가서 pip install -e.를 통해 필요한 모듈을 설치했다는 가정 하에 진행해 보려 한다!!
(1) hydra

pip install hydra-core --upgrade
hydra라는 모듈이 없다..? 그냥 설치하면 된다!
(2) kospeech

- 이건 지난 포스팅에도 설명했기 때문에 간단하게 설명하면 모듈을 불러오는 경로가 잘못 잡혀 있는 문제로 kospeech 폴더 자체를 bin 폴더 안으로 넣어주면 해결!
(3) librosa

pip install librosa
(4) astropy

pip install astropy
(5) BeamDecoderRNN

- 에러 위치를 그대로 찾아 들어가서 /bin/kospeech/models/__ init __.py의 32번 라인을 보면,

- 우리는 LAS 모델을 사용하지 않았고 애초에 존재하지 않는 class를 import하고 있기 때문에 주석 처리해주었다.
(6) Levenshtein

pip install Levenshtein
(7) transcripts.txt
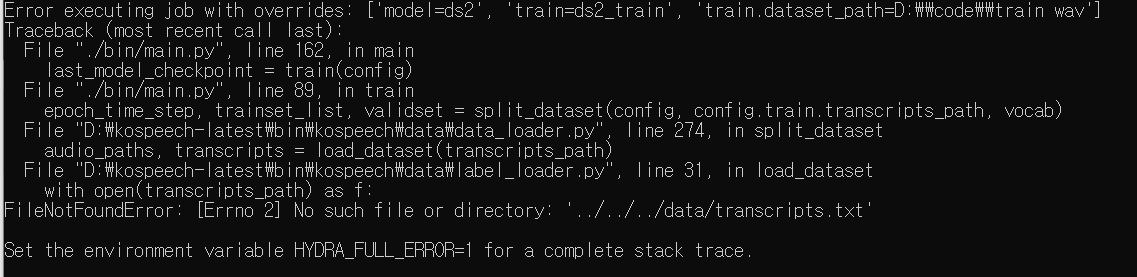
- 디렉토리에 transcripts.txt 파일이 없다고 뜨는데, 이전에 만들어준 transcripts.txt를 /data/ 폴더에 넣어주면 된다.
(8) torchaudio
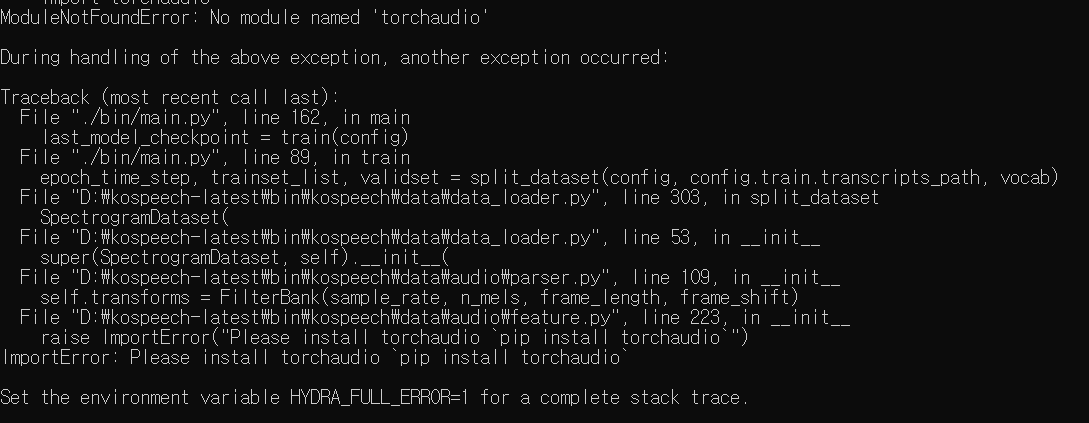
pip install torchaudio
🔥 드디어?
여기까지 오면 필요한 모듈을 모두 설치했고, layer을 깔면서 학습 직전까지 진행된 것을 알 수 있다.
우리도 설레는 마음으로 실행코드를 눌렀는데...
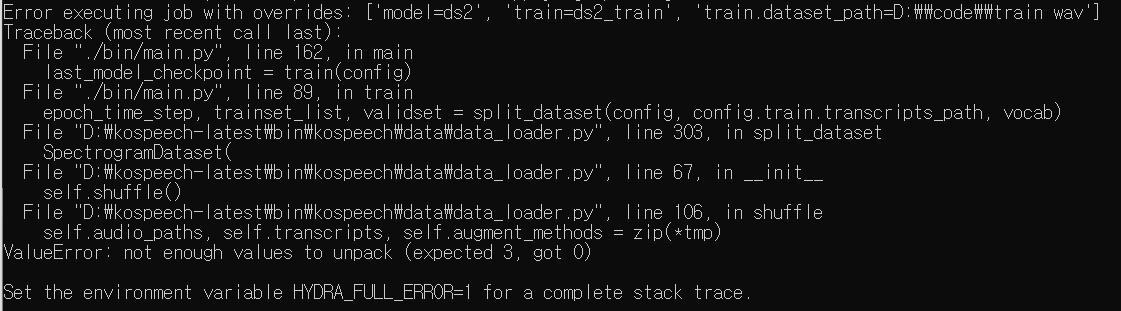
이제와는 전혀 다른 에러가 발생했다. 아무래도 우리 데이터에 맞게 수정하거나 삭제하는 작업 등이 필요했고 이를 위해서는 코드를 하나씩 까보면서 이해해야 할 필요가 있었다!
그럼 페이지 2로 가봅시닷!
데이터 갯수 선정 (+ augmentation 선택)
- 위 에러에 대해 설명하기 위해 에러 발생지인, /kospeech-latest/bin/kospeech/data_loader.py에 들어가면,

- 여기서 zip(*tmp)가 비어있다는 뜻이다.
- audio_path: 음성파일 이름
- transcripts: 전사
- augment_methods: 증강 여부 - kospeech에서는 데이터를 복제해서 붙인 후 shuffle하여 증강한다!
- 우리는 무한 print를 통해 문제 지점을 발견할 수 있었다.

- 266번 라인을 보면, train과 validation에 사용할 데이터의 수가 고정되어 있는데 이것이 맞지 않아서 에러가 발생한 것이다.
- 우리는 총 30만개의 데이터를 사용하는 상황이었기 때문에 train_num = 280000, valid_num = 20000으로 수정해 주었다.
- 각자 데이터의 수와 상황에 맞게 비율을 정해서 수정해주면 된다.
학습 기간이 정해져 있었기 때문에 augmentation을 통해 데이터를 확장하고 학습을 시켰을 때 정말 많은 시간이 걸렸고 우리는 상의 끝에 augmentation을 하지 않기로 했다.
따라서 학습 효율 등의 이유로 augmentation을 하고 싶지 않다면,
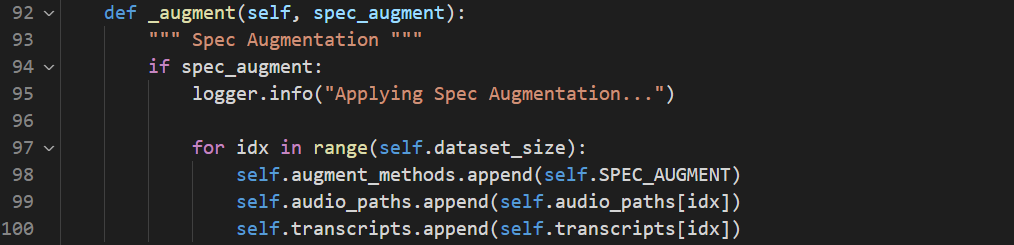
- 92번 라인에서 spec_augment 앞에 not을 붙여주거나 인자 자체를 False로 설정해 주면된다.
음성 파일 확장자 지정
-
Deepspeech2의 경우 음성 파일의 feature 추출 방식으로 fbank를 사용하기 때문에 인자들을 각자 상황에 맞게 변경해 줄 필요가 있었다.
-
먼저 /kospeech-latest/configs/audio/fbank.yaml/에 들어가 보면,
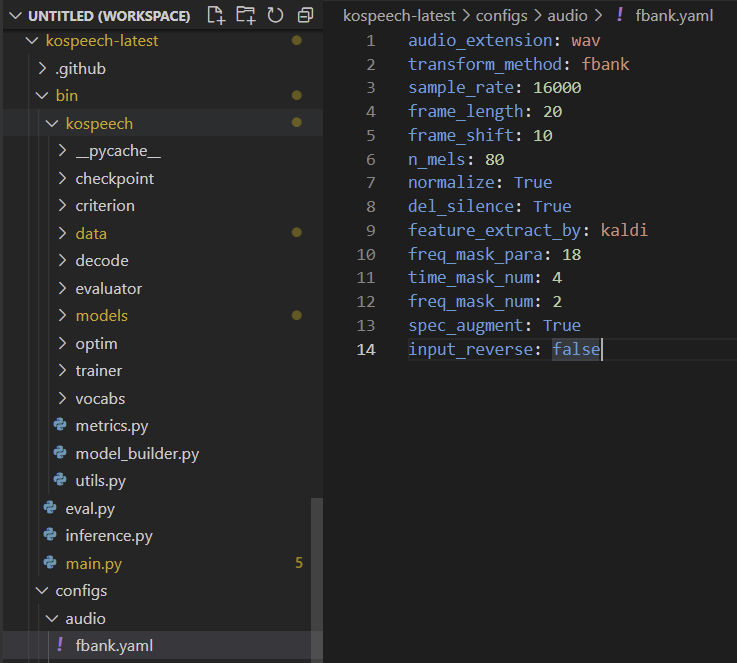
- 우리는 wav 파일을 사용했기 때문에 음성 파일이 pcm으로 설정되어 있는 부분들을 변경해주었다.
- pcm -> wav
- 위에 언급한 바와 같이 우리는 데이터를 확장하지 않았기 때문에 spec_augmentation 인자도 변경해주었다.
- spec_augmentation -> False
글자 사전 이름 변경
- 먼저 /kospeech-latest/bin/main.py에 들어가면,
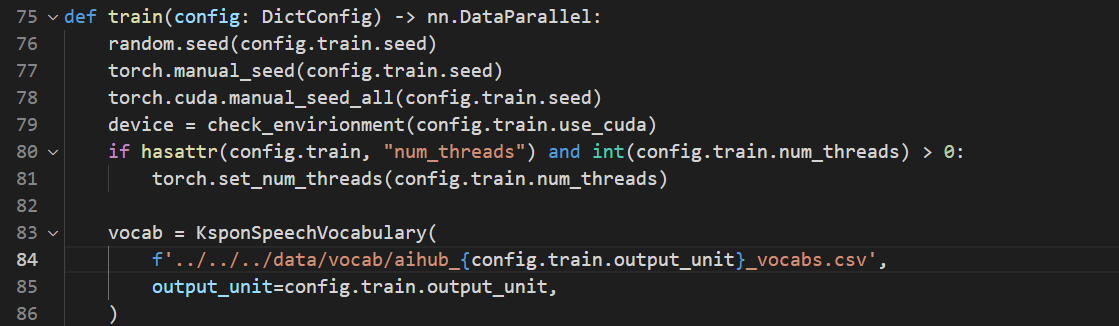
- 사용하는 글자 사전의 이름을 직접 지정해주어야 하기 때문에 84번 라인의 'aihub_'을 각자 전처리 과정에서 만든 글자 사전의 이름으로 바꾸어 주면 된다.
- 마찬가지로 같은 main.py와 같은 레벨에 있는 eval.py, inference.py에 있는 모든 글자 사전 파일 명을 동일하게 변경해주자!
학습 옵션 지정
여기까지 오면 진짜 거의 다 온거나 마찬가지다!
-
우리는 Deepspeech2 모델을 사용했기 때문에 우리 상황에 맞게 옵션들을 지정해 주었다.
-
먼저 /kospeech-latest/configs/train/ds2_train.yaml에 들어가면, 아래와 같이 Deepspeech2 모델의 들어가는 옵션의 인자들을 변경해 줄 수 있다.
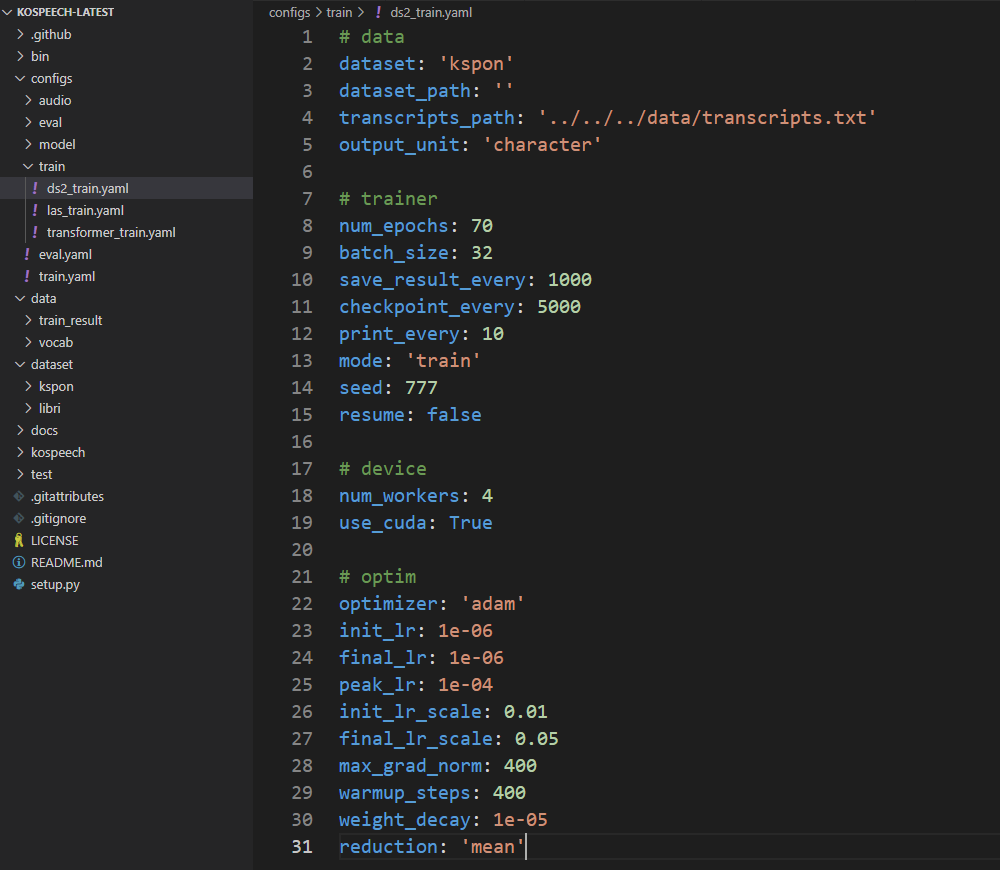
-
epoch과 batch_size 같은 경우 각자의 상황에 맞게 지정하면 되고 우리는 epoch은 20, batch_size는 32로 지정해 주었다.
-
save_result_every: 모델이 학습을 진행하면서 발생하는 loss, cer 등의 수치가 저장되는 주기를 뜻한다. (100으로 지정)
-
time_step: 데이터 길이와 연관되는 수치로 데이터의 크기와 batch_size의 크기로 결정된다.
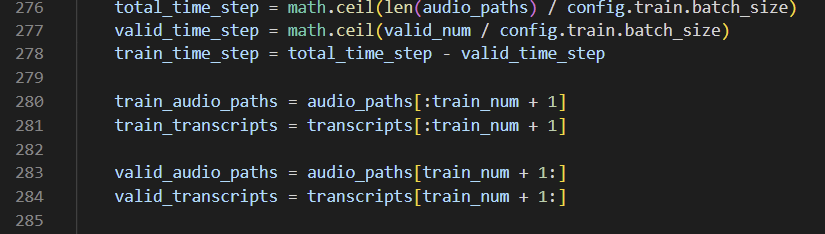
-
checkpoint.every: 학습 도중 model.py와 trainer_states.py를 저장하는 주기를 뜻한다.
- 구글 colab을 사용하면 지속해서 런타임이 끊기기 때문에 우리는 모델을 저장하고 가장 최신의 모델을 불러와 이어서 학습할 수 밖에 없었다.
- 결과적으로 save_result_every, checkpoint_every를 모두 100으로 지정하고 계속해서 로그를 찍어가면서 확인하고 런타임이 끊기면 다시 model.pt를 불러와서 이어서 학습하도록 했다.
-
resume: 이어서 학습할지 말지 선택할 수 있도록 함
- 우리 같은 경우 resume 조건을 활용하고 resume=True로 설정한 상태에서 알아서 최신의 파일을 가져오고 싶었기 때문에 코드를 변경해 주었다.
- /bin/kospeech/checkpoint/checkpoint.py를 보면,

- 기존의 코드를 아래와 같이 수정해 주었다.

💡
드디어 학습을 위한 준비가 모두 끝나고 아래 학습 코드를 (각자의 상황에 맞게 수정해서) 실행하면 학습이 시작된다!
python ./bin/main.py model=ds2 train=ds2_train train.dataset_path=$DATASET_PATH
기존에 작성했던 거를 더듬어가면서(기억 하나도 안남....), 팀장꺼 참고해 가면서 작성해 보았는데..너무 아쉽지만...오늘 아니면 도저히 안 쓸것 같아서 새벽까지 쓰고 잔다..
여튼 다음 포스팅에서는 학습 과정 중에 발생한 문제들과 우리가 어떻게 해결해 나갔는지 등에 대해 작성해보려 한다.
🙂
