
👉 한국어 STT #1에 이어서 진행되는 내용에 대해 작성해보려 한다.
학습 실행 코드
-
Kospeech는 깃허브 README에 음성 파일과 해당 음성의 전사 파일만 있다면 feature를 추출하고 벡터화된 데이터를 학습까지 한번에 실행 해주는 명령어를 모델 별로 정리해 놓았다.
-
나는 그 중 Deep Speech2로 학습을 시켰고 실행 코드는 다음과 같다.
python ./bin/main.py model=ds2 train=ds2_train train.dataset_path=$DATASET_PATH
에러
🔥여기서 주의해야할 점은 뒤에 경로들을 잘 잡아주어도 에러가 뜨는데 알고 보면 실행 위치는 bin의 상위 폴더인 kospeech-latest임에 반해 실행 파일인 main.py를 뜯어보면 같은 레벨에 있는 Kospeech 폴더에 있는 애들을 요구하기 때문이었다. 따라서 bin과 동일 레벨에 있는 kopecch를 bin의 하위폴더로 이동시켜주고 실행하니 해당 에러가 뜨지 않았다!
🔥 참고로 dataset_path 같은 경우도 나는 처음부터 절대경로로 잡아주어 잘 됐었는데, 팀원 한명은 상대경로로 잡아주어서 계속 안됐었다.. 이유는 모르겠지만 절대경로로 바꿔주고 나니 실행이 잘 되긴 했었다!
학습 준비 및 전처리
데이터가 있는 dataset의 경로를 잡고 kospeech 폴더를 bin 폴더 하위로 이동시킨 후 실행을 해도 학습까지는 아직도 여러 튜닝이 필요하다. 특히 우리팀은 많은 길을 헤매고 돌다가 결국 제자리를 찾았다. 그래서 Kospeech 설명해주는 유튜브 영상을 잘 참고하면 처음부터 좋은 길을 갈 수 있을 것 같다..ㅋㅋ
학습 준비에 필요한 내용은 다음과 같다.
- 전처리 및 단어 사전 준비
- 전사 자료의 벡터화
한국어 STT 모델을 만들기 위해서 필요한 데이터는 크게 음성 데이터(wav, pcm 등)와 해당 음성 파일의 전사 데이터가 필요하다. 전사 데이터란, 해당 음성이 무엇을 말하는지 사람이 듣고 내용을 적은 텍스트를 말하고 label 값으로 사용된다.
우리는 외국인 발화 음성파일(wav)과 각각 음성의 메타데이터(json) 30만개를 받았고, 메타데이터 안에 전사 텍스트가 포함되어 있었다. 데이터를 공개하면 안돼서 올릴 수는 없지만, 전사파일의 예시를 들자면 다음과 같다.
오늘은 un/ 콜라+를/콜라를 먹었어 그런데 어디 sn/ 였지?
오늘은 콜라 를 콜라를 먹었어 근데 어디 였지
이렇게 보면 한글 말고도 '+, sn/, un/'등 문장 부호가 존재하는데 이는 전사파일을 만드는 기관이 정한 규칙으로 해당 상황에 전사 기호를 포함시킨 것이었다. 우리는 학습을 위해 한글과 띄어쓰기를 제외한 전사 기호들을 모두 제거해주는 전처리 과정을 거쳤고 해당 코드는 다음과 같다.
def rule(x):
# 괄호
a = re.compile(r'\([^)]*\)')
# 문장 부호
b = re.compile('[^가-힣 ]')
x = re.sub(pattern=a, repl='', string= x)
x = re.sub(pattern=b, repl='', string= x)
return x이제 음성을 통해 예측하고자 하는 문장을 깔끔하게 만들었고 본격적으로 전처리에 대해 설명하고자 한다.
우리는 이 전사 파일을 활용해서 단어사전을 만들고 단어사전을 바탕으로 한 정답 벡터(문장으로 복원되기 직전의 예측값)를 만들어 낼 것이다. Kospeech는 단어사전을 만들 때 크게 3가지 방식을 제공하고 관련 파일과 설명이 'kospeech-latest/datset/kspon'에 있다.
설명을 읽고 전처리 하기 전에 먼저 필요한 모듈을 설치해 주어야 한다.
pip install -r equirements.txt
마찬가지로 여러 충돌이 일어나지만 크게 상관없기 때문에 일단 직진하면 된다ㅋㅋㅋ
Kospeech는 3가지 방식의 전처리를 제공한다. 우리의 처음 계획은 3가지 방법을 각각 사용해서 단어사전을 만들고 학습시켜 성능을 비교하는 것이었는데 데이터는 용량이 크고, gpu는 버전 충돌 때문에 말을 안듣고, 그나마 되는 코랩 프로는 10시간(?) 정도의 텀을 두고 끊겨 버려서 결국은 character 방식으로만 학습할 수 있었다. 간단하게 애기하면 단어사전을 만들기 위해 문장을 토큰화 하는게 다르다고 할 수 있을 것 같다.

우리가 사용한 Character 방식을 사용해서 문장을 벡터화 하면 다음과 같다.
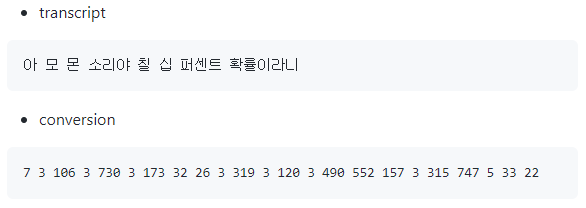
단어 사전 생성
여튼 위 방식 중 하나를 활용해서 단어 사전을 생성하는 코드는 다음과 같다.
경로: 'kospeech/dataset/kspon'
python main.py --dataset_path "(1)" --vocab_dest "(2)" --output_unit "(3)" --preprocess_mode '(4)'
✔️ 이 코드를 실행하게 되면 2가지 산출물이 만들어진다.
- 한글 전사자료가 포함하는 글자로 만들어진 단어사전
- 위에서 만들어진 단어 사전을 이용한 벡터화 된 전사자료를 포함하는 transcript.txt
("audio_path + 탭 + korean transcript + 탭 + (벡터화된) transcript"의 구조)
실행 코드의 (1) ~ (4)은 kspon/main.py에 던저 줘야 하는 args들로 각자가 하려는 방식에 맞게 집어 넣으면 되는데 이 내용은 kspon 폴더의 preprocess.sh 파일을 보면 알 수 있다.
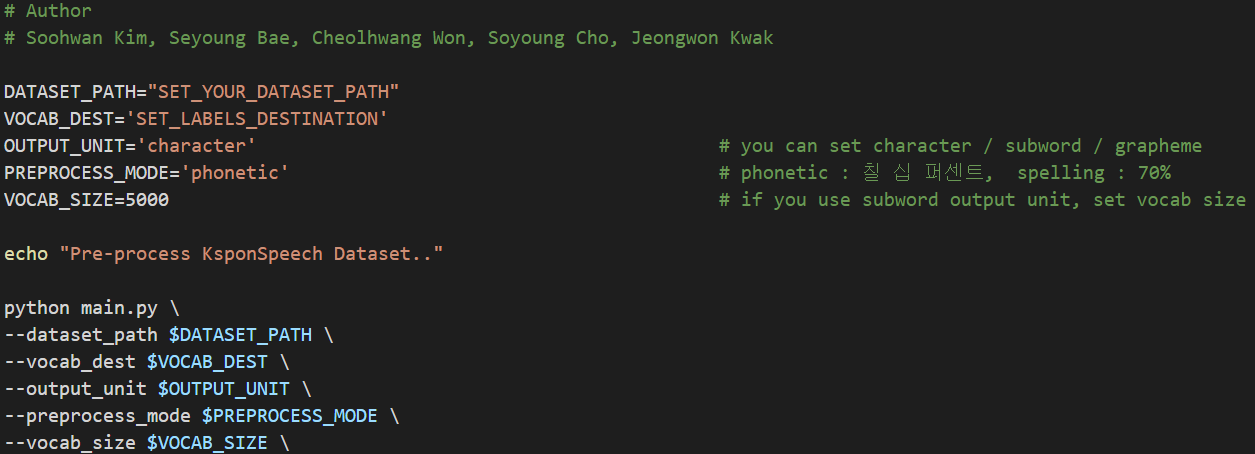
- dataset_path: 오디오 파일을 포함하는 폴더의 경로
- vocab_dest: 전처리의 단어 사전의 저장 경로
- output_unit: 사용할 전처리 방법 (우리는 Character-unit, 글자 단위 방법을 활용했다.)
- preprocess_mode: phonetic인지 spelling인지 원하는 것을 선택 (우리는 phonetic 선택)
- 70%을 읽을 때 사람마다 (칠 십 퍼센트 or 칠 십 프로 라고 읽기 때문에 각각의 방식을 구분지었음)
- vocab size: 단어 사전의 크기, 미입력시 5,000
시행착오(1)
python main.py --dataset_path "(1)" --vocab_dest "(2)" --output_unit "(3)" --preprocess_mode '(4)'
이 실행코드를 실행하기 위해(에러가 뜨니까...) main.py와 그 안에서 또 실행되는 preprocess.py들이 어떻게 짜여져 있는지 부장님(우리 팀장 ㅋㅋ)이랑 열심히 탐구했다. Kospeech 설명 영상을 보면 이해하는데 도움이 많이 되지만, 우리는 그런게 있는 줄도 모르고 추측하고 하나하나 다 찾아보았다. 그래서 우리가 이해한 바대로라면 kospeech가 사용한 kspon 데이터의 구조는 다음과 같다.
/오디오1(폴더)
ㄴ 오디오1.pcm
ㄴ 오디오1.txt/오디오2(폴더)
ㄴ 오디오2.pcm
ㄴ 오디오2.txt
이렇게 하나의 음성 파일과 해당 음성 파일의 전사 텍스트가 한 폴더 안에 비슷한 이름으로 존재하는 상황이었고, 해당 전사 자료가 '%'를 어떻게 읽었는지에 따라 .txt 파일의 제목에 어떤식으로 처리가 되어 있었던 것 같다. 그래서 preprocess.py 파일을 보면 preprocess라는 함수가 있다.
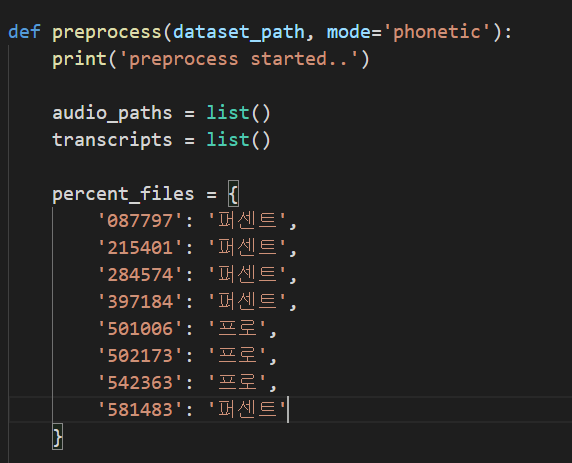
.txt 파일의 제목에 특정 부분([12:18])에 해당 숫자가 등장하면 전사 자료의 일부를 변환하며 그것을 리스트에 담아 반환하고, 해당 두 개의 리스트(audio_paths와 transcripts)는 transcript.txt를 만드는데 활용된다. 이 부분은 각자 보유하고 있는 데이터에 맞게, 변형이 필요한 부분이다.
우리는 앞서 정의한 rule() 함수를 이용해 전처리한 문장을 train.txt라는 파일에 'audio_path + 탭 + korean transcript'의 구조로 이미 저장해 둔 상태였기에, 아래와 같이 바꾸어 사용하였다. (상황이 다르다면 이 역시 각자의 상황에 맞게 변형이 필요하다.)
def preprocess(dataset_path, mode='phonetic'):
print('preprocess started..')
audio_paths = list()
transcripts = list()
with open("train.txt") as f:
for idx, line in enumerate(f.readlines()):
audio_path, transcript = line.split('\t')
transcript = transcript.replace('\n', '')
audio_paths.append(audio_path)
transcripts.append(transcript)
print("성공")
return audio_paths, transcripts시행착오(2)
두번째로 character.py를 보면(우리는 글자 단위로 토큰을 하기 때문에 이 파일을 수정했다!) 다음과 같은 부분이 있다.
def generate_character_labels(transcripts, labels_dest):
print('create_char_labels started..')
label_list = list()
label_freq = list()
for transcript in transcripts:
for ch in transcript:
if ch not in label_list:
label_list.append(ch)
label_freq.append(1)
else:
label_freq[label_list.index(ch)] += 1
# sort together Using zip
label_freq, label_list = zip(*sorted(zip(label_freq, label_list), reverse=True))
label = {'id': [0, 1, 2], 'char': ['<pad>', '<sos>', '<eos>'], 'freq': [0, 0, 0]}
for idx, (ch, freq) in enumerate(zip(label_list, label_freq)):
label['id'].append(idx + 3)
label['char'].append(ch)
label['freq'].append(freq)
label['id'] = label['id'][:2000]
label['char'] = label['char'][:2000]
label['freq'] = label['freq'][:2000]
label_df = pd.DataFrame(label)
label_df.to_csv(os.path.join(labels_dest, "aihub_labels.csv"), encoding="utf-8", index=False)
def generate_character_script(audio_paths, transcripts, labels_dest):
print('create_script started..')
char2id, id2char = load_label(os.path.join(labels_dest, "aihub_labels.csv"))
with open(os.path.join("transcripts.txt"), "w") as f:
for audio_path, transcript in zip(audio_paths, transcripts):
char_id_transcript = sentence_to_target(transcript, char2id)
audio_path = audio_path.replace('txt', 'pcm')
f.write(f'{audio_path}\t{transcript}\t{char_id_transcript}\n')각각 단어 사전과 그것을 바탕으로 한 transcript를 저장하는 부분인데, 이때 단어 사전의 이름("aihub_labels.csv") 부분은 자유롭게 변경하고 중간 부분의 2000을 각각 만들어진 단어 사전의 갯수에 맞춰 주어야 한다. 우리 같은 경우 30만개의 전사 텍스트 에서 총 1,000개 남짓의 단어 사전이 생성 되었고, 너무 적게 등장한 단어(빈도수 5회 이하)들을 제거하고 남은 986으로 설정해 주었다.
원 개발자 역시 임의로 2000이라는 숫자를 지정한 것이기 때문에, 각자 데이터를 잘 살펴보고 판단하여 정해야하는 부분이다. 그리고 아래에서 두번째 줄은 원래 데이터 셋의 형태 때문에 있는 코드 같은데, 없어도 될 것 같다. (왜냐면 우리는 'wav'를 사용 해주었기 때문..) 계속해서 이런 느낌으로, 각자 상황에 맞게 코드를 수정 보완해가며 사용할 수 밖에 없다.
이렇게 각자의 상황의 맞게 필요한 부분을 수정한 후 아래 예시처럼 형식에 맞에 명령어를 입력하면 된다.
경로: 'kospeech/dataset/kspon'
python main.py --dataset_path "D:\code\train wav" --vocab_dest "D:\kospeech-latest" --output_unit "character" --preprocess_mode 'phonetic'

실행이 끝나면, 지정한 경로에 지정한 이름으로 단어 사전이 만들어지고 학습에 필요한 transcript.txt 파일이 만들어지는 것을 알 수 있다. 우리는 kospeech-latest/dataset/kspon/'transcript.txt"
에 만들어져 있었다.
간단하게 transcript.txt 파일의 예시를 들어보자면,
| 오디오 파일 이름 | 한글 전사 | 숫자 전사 |
|---|---|---|
| audio1.wav | 점심 맛있게 먹었니 | 320 1 3 24 56 88 3 98 124 76 |
각각의 내용이 tab으로 구분되어져 있다. 여기서 3은 띄어쓰기를 의미한다.
💡
이제 음성 파일 수만큼 한글 전사와 이를 벡터화 한 숫자 전사가 txt 파일에 줄마다 적혀 있고 모델을 학습할 준비가 끝났다.
다음 포스팅에는
python ./bin/main.py model=ds2 train=ds2_train train.dataset_path=$DATASET_PATH
맨 처음 설명했던 이 실행코드를 실행하면서 생기는 시행착오에 대해 설명해보려 한다.
🙂


안녕하세요..선생님.
dataset_path: 오디오 파일을 포함하는 폴더의 경로
vocab_dest: 전처리의 단어 사전의 저장 경로
에서 dataset_path는 wav 파일을 넣어두면 된다고 말씀해주시는 것 같고 vocab_dest의 전처리 단어사전은 어떻게 구하면 되는걸까요..? 데이터를 어떻게 넣어야하는지를 모르겠습니다 ㅠㅠㅠ