
지난 글 👉 한국어 STT #4
우리의 궁극적인 목표는 새로운 오디오 파일이 입력되면 그 오디오 파일의 전사가 출력이 되고 이를 총 10,000개의 테스트 케이스를 가지고 평가하는 것이었다. 음성인식에서 흔히 사용하는 CER과 WER로 평가가 이루어 졌는데, 이번 포스팅에서는 CER과 WER에 대한 설명, 그리고 Kospeech가 제공하는 하나의 음성파일에 대해 텍스트로 변환한 결과를 출력하는 inference.py을 실행하는 과정에 대해 작성해 보려 한다.
기본적으로 inference.py 파일을 실행하는 코드는 👉 Kospeech 깃허브에서 확인할 수 있다.
먼저 이 코드를 실행하다 보면 다양한 에러가 발생하기 때문에 수정해 주어야 할 사항에 대해 소개하겠다!
(1) require(x) -> required(0)

- 'kospeech-latest/bin/inference.py를 보면 require로 되어 있기 때문에 required로 수정해야 한다.
(2) greedy_search ??

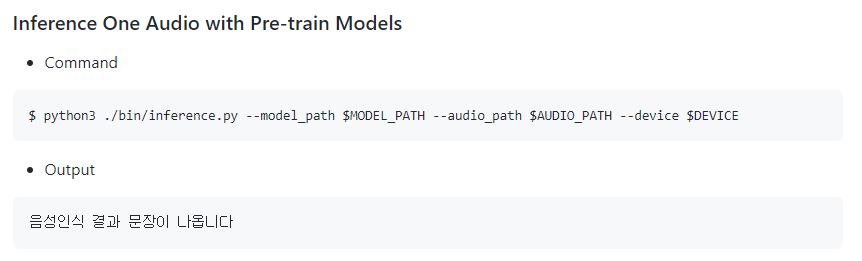
- 들어간 데이터가 NoneType라고 나오는데, 64~73 라인의 greedy_search 라는 함수 때문이다. 해당 함수는 실제로 존재하지 않기 때문에 동일한 역할을 실행하는 recognize로 바꾸어 주면 된다.
(3) recognize
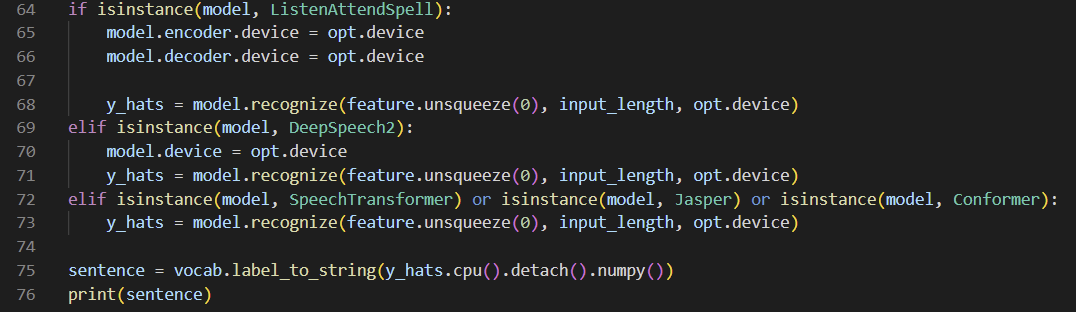
- greedy_search 함수 대신 recognize를 쓰면 'TypeError: recognize() takes 3 positional arguments but 4 were given' 이런 에러가 뜨게 된다.
- kospeech-latest/in/kospeech/models/model.py의 recognize() 함수를 보면 3개의 인자를 받는데, opt.device를 필요로 하지 않기 때문에 제거하면 된다.
- 이때 57번 라인의 경로에 우리의 글자 사전을 위치시키도록 했다.

- 참고로 학습시킬 때와 위치가 다르다!
- /kospeech-latest/data에 만든 글자 사전을 /kospeech-latest/bin/data/vocab으로 복사 붙여넣기 해주면 된다.
(4) 중복 음절 제거
이제 위에 언급한 예측 코드를 실행하면 아래와 같이 결과가 나온다.

내부적으로 CTC 알고리즘을 사용하기 때문인데, 자세한 내용은 👉 Kospeech 설명 영상을 참고하면 된다. 우리는 이를 해결하기 위해 다음과 같음 함수를 만들어서 inference.py와 같은 level에 tools.py로 저장하고, 이를 불러와 사용할 수 있도록 import 했다. 이후 출력하기 전에 revise 함수를 거치도록 했는데, 후처리가 없이 '스스로'를 전사하면 '스로'로 출력을 했기 때문이다. 따라서 revise 함수로 예외 사항을 두어서 '스스로'를 전사하면 그대로 '스스로'로 출력하도록 했다. 우리는 대회였기 때문에 성능 평가를 위해 이때만 예외처리를 해두었지만, 조심스럽게 접근해야 할 필요가 있다.
from tools import revise
def revise(sentence):
words = sentence[0].split()
result = []
for word in words:
tmp = ''
for t in word:
if not tmp:
tmp += t
elif tmp[-1]!= t:
tmp += t
if tmp == '스로':
tmp = '스스로'
result.append(tmp)
return ' '.join(result)
(5) 최종 결과
이때 진짜 기뻤는데....ㅋㅋㅋ

(6) WER, CER
음성 인식에서 WER과 CER은 정확도를 판별하는 지표이다. 우리가 참가한 대회도 WER과 CER로 평가를 했기 때문에 이에 대해 알 필요가 있었고 세계적으로(?) 음성인식을 평가하는 기준도 WER이나 CER로 평가를 하는 것 같다!
1) WER(Word Error Rate)
- D: 음성 인식된 텍스트에 잘못 삭제된 단어 수
- S: 음성 인식된 텍스트에 잘못 대체된 단어 수
- I: 음성 인식된 텍스트에 잘못 추가된 단어 수
- N: 정답 텍스트의 단어 수
- 단어 에러 비율(WER) = (S+D+I) / N
2) CER(Chatacter Error Rate)
- D: 음성 인식된 텍스트에 잘못 삭제된 음절 수
- S: 음성 인식된 텍스트에 잘못 대체된 음절 수
- I: 음성 인식된 텍스트에 잘못 추가된 음절 수
- N: 정답 텍스트의 음절 수
- 음절 에러 비율(CER) = (S+D+I) / N
아래 코드는 우리가 학습하면서 CER과 WER을 찍어보고 싶어서 만든 코드이다!
import Levenshtein as Lev
def wer(ref, hyp ,debug=False):
r = ref.split()
h = hyp.split()
#costs will holds the costs, like in the Levenshtein distance algorithm
costs = [[0 for inner in range(len(h)+1)] for outer in range(len(r)+1)]
# backtrace will hold the operations we've done.
# so we could later backtrace, like the WER algorithm requires us to.
backtrace = [[0 for inner in range(len(h)+1)] for outer in range(len(r)+1)]
OP_OK = 0
OP_SUB = 1
OP_INS = 2
OP_DEL = 3
DEL_PENALTY=1 # Tact
INS_PENALTY=1 # Tact
SUB_PENALTY=1 # Tact
# First column represents the case where we achieve zero
# hypothesis words by deleting all reference words.
for i in range(1, len(r)+1):
costs[i][0] = DEL_PENALTY*i
backtrace[i][0] = OP_DEL
# First row represents the case where we achieve the hypothesis
# by inserting all hypothesis words into a zero-length reference.
for j in range(1, len(h) + 1):
costs[0][j] = INS_PENALTY * j
backtrace[0][j] = OP_INS
# computation
for i in range(1, len(r)+1):
for j in range(1, len(h)+1):
if r[i-1] == h[j-1]:
costs[i][j] = costs[i-1][j-1]
backtrace[i][j] = OP_OK
else:
substitutionCost = costs[i-1][j-1] + SUB_PENALTY # penalty is always 1
insertionCost = costs[i][j-1] + INS_PENALTY # penalty is always 1
deletionCost = costs[i-1][j] + DEL_PENALTY # penalty is always 1
costs[i][j] = min(substitutionCost, insertionCost, deletionCost)
if costs[i][j] == substitutionCost:
backtrace[i][j] = OP_SUB
elif costs[i][j] == insertionCost:
backtrace[i][j] = OP_INS
else:
backtrace[i][j] = OP_DEL
# back trace though the best route:
i = len(r)
j = len(h)
numSub = 0
numDel = 0
numIns = 0
numCor = 0
if debug:
print("OP\tREF\tHYP")
lines = []
while i > 0 or j > 0:
if backtrace[i][j] == OP_OK:
numCor += 1
i-=1
j-=1
if debug:
lines.append("OK\t" + r[i]+"\t"+h[j])
elif backtrace[i][j] == OP_SUB:
numSub +=1
i-=1
j-=1
if debug:
lines.append("SUB\t" + r[i]+"\t"+h[j])
elif backtrace[i][j] == OP_INS:
numIns += 1
j-=1
if debug:
lines.append("INS\t" + "****" + "\t" + h[j])
elif backtrace[i][j] == OP_DEL:
numDel += 1
i-=1
if debug:
lines.append("DEL\t" + r[i]+"\t"+"****")
if debug:
lines = reversed(lines)
for line in lines:
print(line)
print("Ncor " + str(numCor))
print("Nsub " + str(numSub))
print("Ndel " + str(numDel))
print("Nins " + str(numIns))
return numCor, numSub, numDel, numIns, (numSub + numDel + numIns) / (float) (len(r))
def cer(ref, hyp):
ref = ref.replace(' ', '')
hyp = hyp.replace(' ', '')
dist = Lev.distance(hyp, ref)
length = len(ref)
return dist, length, dist/length최종적으로 테스트 오디오 파일 10,000개를 inference.py를 통해 전사 텍스트로 변환하고 제출한 뒤 주최측에서 받은 우리의 WER과 CER은,

2주 정도 팀원들이랑 매일 만나서 시행착오한 결과가 만족스럽게 나와서 정말 기뻤던 순간이었다.
참가한 29개 참여 팀 중 성능 부문 1위 였지만.. 아이러니하게 최종 평가에서 2위로 우수상을 수상했다..!! 그래도 대회 기간동안 2박 3일 합숙을 하면서 재밌게 놀기도 많이 놀았고, 사업화 아이디어 회의를 진행하고 때마다 학습이 잘 되어가고 있는지, 성능을 어떻게 하면 높일지, 성능은 어떻게 비교를 할지 등등 처음 참가해본 해커톤이라 하나부터 끝까지 쉬운게 없었지만 즐거웠던 기억이 많이 있어서 그런지 2021년 연말을 의미있게 보낸 것 같다!
💡
👉 깃허브에 들어가면 저희 팀이 정리한 파일을 확인할 수 있습니다.
🙂

4개의 댓글

저도 초기 Kospeech 사용할때는 좋지 않은 성능과 오류들로 인해 시간을 굉장히 많이 잡아먹었었는데 이렇게 잘 정리해주시니 다음에 한번 다시 시도해봐야겠네요 좋은 자료 감사합니다. 혹시 인풋 음성 데이터를 넣었을때 디코딩되는 속도는 어느정도였는지(실시간? or 생각보다 오래걸림) 말씀해주실 수 있을까요?

-
학습데이터를 중간에 추가할 수 있는 방법도 있을까요?
-
지금 데이터 12분할하여 50000개씩 100에폭 진행했는데 학습시에 loss가 0.8~1.0 정도에 머물러있고, CER값이 0.32~0.33정도에서 머물고 있습니다.
chanyeong kim님은 학습시에도 CER값이 잘 나오셨나요? 아니면 후처리한 결과가 좋은거였나요?
고생하셨습니다! 좋은 정보 너무감사드립니다!