lab_14) RNN
———————————preview———————————
RNN은 (Recurrent Neural Network)은 시간적으로 연속성이 있는 데이터를 처리하려고 고안된 인공 신경망입니다.
Recurrent 이라는 것은 이전 은닉층이 현재 은닉층의 입력이 되면서 반복되는 순환 구조를 갖는다는 의미입니다.
RNN이 기존 네트워크와 다른 점은 ‘기억’을 갖는 다는 것인데 이때 말하는 기억은 현재까지 입력 데이터를 요약한 정보라고 생각하면 됩니다.
따라서 새로운 입력이 네트워크로 들어올 때마다 기억은 수정되고, 결국 최종적으로 남겨진 기억은 모든 입력 전체를 요약한 정보가 됩니다.
RNN의 종류는 input과 output에 따라서 유형이 다양한데
일대일, 일대다, 다대일 ,다대다 , 동기화 다대다 와 같은 종류가 존재합니다.
RNN 구조는 다음 그림과 같이 볼 수 있습니다.
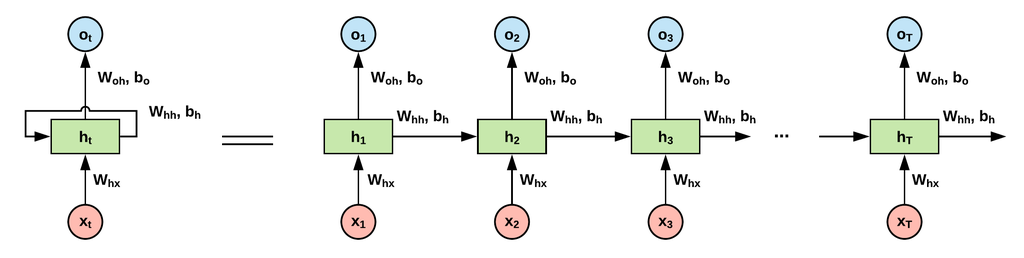
————————————————————————————
Motivation
모든 problems가 fixed length inputs and outputs도 아닐 뿐 더러
Speech Recognition or Timeseries prediction이 필요한 경우,
그리고 hard to choose a fixed context window인 경우 이에 대한 해결 방안으로 feedback with previous results.
Recurrent Neural Network
One to one -> Vanila network와 같이 초기에 고안된 형태
One to many -> image captioning(sequence 즉, 순서가 있는 출력)
Many to one -> sentiment analysis
Many to many -> translator
RNN Computation
이전 state와 현재 입력을 받아서 새로운 state를 정의 하는 것으로
중간 은닉층에서 쓰이는 tanh와 같은 경우는 평균이 0이되어
계속 loop를 도는데 유리한 상황을 만들 수 있는 non-linear를 위한 함수라고 볼 수 있고,
출력층에 존재하는 softmax함수는 probability를 위한 것이라고 볼 수 있습니다.
Representation of the RNNs
Fully connected network != unrolled view network
각 node 는 vector라고 볼 수 있고 각 dimension을 갖고 있음
그리고 RNN의 장점과 단점을 보면
장점으로는
input으로 들어오는데 길이의 제한이 없다는 점이고
Model size가 고정되어있다는 점
과거의 정보를 이용한다는점
weight는 유일하나 시간에 따라 저장되는 Weight의 장소가 다르다고 볼 수 있음.
단점으로는
시간순 계산을 진행하므로 병렬처리 할 수 없고 따라서 오래걸림
아주 옛날거에 대해서는 흔적이 남지 않음
Future input을 기대하는 것은 아님
Vanishing Gradient Problem
시간적으로 오래된 것들에 대해서는 vanishing(tanh를 사용하므로)
만약에 렐루를 넣으면 값이 터지므로 그런식으로 해결 할 수는 없음.(loop를 돌아야 하므로)
backpropagation할때 gradient error가 생김
1.이전시간 것을 next로 보내는게 어렵
2.시간이 갈 수록 vanish,loss는 어디까지 계산?(모든 loss 계산)loss가 변하는 모든 과정이 gradient
Backpropagation Through Time(BPTT)
과거쪽으로 포함하여 계산 한다.
loss부터 계산, class에 대해 전부, 시간 순으로 나타난 loss 전부 포함.
시간순으로 전개되는 만큼 그동안의 정보를 보관해야해서 메모리가 많이 필요하다는 단점이 있음.
(Backpropagation 계산을 위함.)
Solution to the Vanishing Gradient Problem
Gradient problem을 보면 터지는 경우와 사라지는 경우를 볼 수 있는데
숫자가 터지는 경우의 해결방법은 다음과 같습니다.
숫자를 크게하면 터지고 숫자를 작게하면 사라집니다.
1. 따라서 backpropagation 할 때 특정 수준에서 멈추게 하는 TBPTT을 사용
2. gradient를 줄이거나 penalize하는 형태의 방식을 사용하는데 그 예로는 clipping gradients를 통해 gradient가 일정 이상 커지지 않게 하는 방식을 사용합니다.
숫자가 사라지는 경우의 해결방법은 다음과 같습니다.
1. Orthogonal initialization. 즉, weight들끼리 independent하게 하는 방식을 쓰는 것인데 이 방법은 원하는 feature의 dimension 보다 작아지면 orthogonal불가하다는 특징이 있습니다.
2. Echo State Networks 안쪽 network를 랜덤하게 하여서 자기들끼리 state 연결하도록
3. 셀을 추가해서 LSTMs 혹은 GRU와 같이.
Truncated Backpropagation Through Time(TBPTT)
Feed forward쪽과 back 쪽으로 둘다 길이를 미리 정합니다,
Data Dimension in RNN
네모하나하나가 특정 dimension을 의미하며 서로 시작 시점과는 관계 없고 batchsize만 존재하는데 각각의 병렬처리만 가능하므로 data quality가 중요하다는 특징이 있습니다.
Data Dimensions in RNN
Batchsize = loss 즉, 평균을 낼 때 서로 관계가 없을 때(independent), 계산해서 gradient에 반영(back propagation)
T 즉, timesteps만큼 진행해 나갈 때 batch size만큼 각 timestep에서 계산한 다음 그 값을 반영합니다. 또한 특징 중에서
Input과 output의 dimension을 같게하여서 RNN이 출력을 다시 입력으로 하는 형태가 자주있는 것을 알 수 있습니다.
PreProcessing for natural Language Processing
RNN이 많이 사용하는 데 쓰이는 NLP와 같은 경우는 그냥 text인 corpus애서 preprocessing(pre-processing->Tokenization->Token-id Mapping)->inputs
Sparse Vector and Dense Vector
inputs단계에서 one-hot encoding 보다도 주로 dense vector를 주로 사용하는데 one-hot을 사용하면 sparse vector라는 단점이 존재하므로 dimension이 자꾸 커지는 단점이 존재. 따라서 이를 극복하기 위해 dense vector를 이용하여 dimension을 안 키우고 새로운 벡터를 만드는 방법
Tokenization and Sequence Analysis
적당한 Sequence lenght를 만들고 그것보다 작으면 나머지 공간을 0으로 채웁니다.
Word Embeddings
dimension의 개수를 줄인다는 목적으로 one-hot vector로는 내적이 0이어서 similarity 계산이 되지 않는데, dimension을 줄이면 (word embedding을 통해) similarity 걔선아 거눙헙나더,
Embedding Layer:word2vec
문맥을 사용해서 단어를 찾는 것으로 CBOW와 skipgram과 같은 방식이 있는 word embedding 방식입니다.
CBOW 하나만 빼서 출력,하나는 입력 순서하고는 상관이 없으나 전후 관계는 존재합니다.
Word2vec- Continuous Bag of Word
수업자료 확인
Some Interesting Results
embedding을 통해 원하는 feature dimenstion안에 작은 dimension을 보낼 때 사용합니다. 관련성이 높아서 붙어있는 것을 볼 수 있습니다. 관련성이 높은 단어끼리 붙어있는 것을 확인 할 수 있음.
