모델설계는 입력층,은닉층,출력층으로 구성됩니다.
# 모델의 설정
model = Sequential()
model.add(Dense(30, input_dim=12, activation='relu'))
model.add(Dense(12, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
그리고 이때 model = Sequential()에서 시작되는 부분은 딥러닝의 구조를 짜고 층을 설정하는 부분입니다. 그리고 model.add()를 통해 중간에 은닉층을 여러개 만들고 맨 마지막 층은 결과를 출력하는 '출력층'이 됩니다. 그리고 각각의 층은 Dense라는 함수를 통해 구체적으로 그 구조가 결정됩니다.
그리고 "model.add(Dense(30, input_dim=12, activation='relu'))" 이 부분에서 30을 통해 30개의 노드가 존재한다는 것을 알 수 있고, input_dim=12로, 12개의 입력 값들이 있는 것을 알 수 있습니다.그리고 출력층에 해당하는 부분인 "model.add(Dense(1, activation='sigmoid'))"부분을 보면 알 수 있듯이 활성화 함수로 시그모이드를 사용하였습니다.
이후 모델 컴파일 부분에서는 아래 코드내용과 같이 진행되는데
# 모델 컴파일
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])위와 같습니다. 또한 이떄 오차 함수에는 교차 엔트로피 외에 mean_squared_error와 같은 함수가 있습니다. 교차엔트로피에 비해 평균 제곱 오차는 수렴하기까지 속도가 많이 걸리는 단점이 있습니다. 그에 비해 교차엔트로피는 오차가 커지면 수렴속도가 빨라지고 오차가 작아지면 속도가 감소하게끔 만든 것입니다.
그리고 위의 코드에서 사용한 이항 교차 엔트로피는 주로 분류문제 중 특별히 예측 값이 참과 거짓 둘 중 하나인 형식일 때 사용합니다. 그리고 지금 구하고자 하는 것은 생존(1)과 사망(0)둘 중 하나이므로 위 오차함수에 사용할 수 있는 좋은 예라고 할 수 있습니다. 그리고 위에서 진행한 것처럼 모델을 정의하고 컴파일하고 나면 이제 실행시키는 것만 남아있는데 이는
model.fit(X,Y,epochs=30,batch_size=10)위와 같은 함수로 주어진 데이터를 불러 실행시킵니다.
인자값을 하나씩 보면 학습 프로세스가 모든 샘플에 대해 한 번 실행되는 것을 1 epoch라고 합니다. 그리고 epochs=1000으로 지정한 것은 각 샘플이 처음부터 끝까지 1000번 재사용될 때 까지 실행을 반복하라는 뜻이며, batch_size는 샘플을 한 번에 몇개씩 처리할지를 정하는 부분인데 batch_size=10은 전체 470개의 샘플을 10개씩 끊어서 집어넣으라는 뜻입니다. 그리고 이 값이 너무 크면 학습속도가 너무 느려지고, 너무 작으면 각 실행 값의 편차가 생겨서 전체 결과값이 불안정해질 수 있습니다.
딥러닝과 머신러닝에 있어서 데이터는 성공과 실패여부에 크게 관여하는데 모델의 정확도를 향상시키기 위해서는 데이터의 추가 및 재가공이 필요할 수 있습니다. 그리고 이러한 이유로 딥러닝의 구동에 앞서 데이터의 내용과 구조를 잘 파악하는 것이 중요한데 가장 유용한 방법이 데이터를 시각화해서 눈으로 직접 확인해 보는 것입니다. panda라는 라이브러리를 사용해 데이터를 불러오고 관련된 정보를 출력해서 확인하면 다음과 같은 것들이 있습니다. 'df.head(5)'는 데이터의 첫 5줄을 불러오는 것이며 'df.info()'와 'df.describe()'는 그에 대한 정보를 출력하는 또 다른 함수이며 특정 속성정보에 대한 값을 보면 df[['pregnant','class']]와 같이 사용합니다. 그리고 이후에 데이터의 가공 또한 할 수 있는데,
이때
print(df[['pregnant','class']].groupby(['pregnant'],as_index=False).mean().sort_values(by='pregnant',ascending=True))위의 코드내용은 데이터를 가공하는 작업을 거친 후의 것인데, 모두 3가지 함수가 사용되었습니다.
groupby함수를 사용해 'pregnant'정보를 기준으로 하는 새 그룹을 만들었습니다. as_index=False는 pregnant 정보 옆에 새로운 index를 만들어 줍니다. 그리고 mean함수를 사용해 평균을 구하고 sort_values함수를 써서 pregnant 칼럼을 오름차순으로 정리하게끔 설정하였습니다. 그리고 이후에 matplotlib를 이용해 그래프로 표현한 것들에 대해서 알아보면 matplotlib는 파이썬에서 그래프를 그릴 때 가장 많이 사용되는 라이브러리이고 이를 기반으로 좀 더 정교한 그래프를 그리게끔 도와주는 seaborn 라이브러리를 사용해 각 정보끼리 어떤 상관관계가 있는지를 알아보면 seaborn 라이브러리 중 각 항목 간의 상관관계를 나타내 주는 heatmap 함수를 통해 그래프를 보면 heatmap함수는 두 항목씩 짝을 지은 뒤 각각 어떤 패턴으로 변화하는지를 관찰하는 함수 입니다. 이때 두 항목이 전혀 다른 패턴으로 변화하고 있으면 0을 서로 비슷한 패턴으로 변할수록 1에 가까운 값을 출력합니다.
다중 분류 문제에 대해서는 이전에 다루었던 데이터의 클래스가 2개가 아닌 3개이상일 경우를 의미합니다. 그리고 이때는 panda로 데이터를 불러와 X와 Y값을 구분해 주는데 keras.util의 np_utils.categorical()함수를 적용하는데 이때 array([1,2,3])가 다시 array([[1.,0.,0.],[0.,1.,0.],[0.,0.,1.]])로 바뀝니다. 그리고 이와 같은 과정을 원-핫 인코딩이라고 합니다. 그리고 이후 소프트맥스(softmax)함수를 보면 입력->가중합->소프트맥스->교차엔트로피의 과정을 거치는데 이때 소프트맥스를 거친 값을 보면 총합이 1인 형태로 바꿔서 계산해 주는 함수입니다.
그러하면 이 값들 중에 큰 값이 두드러지게 나타나고 작은 값은 더 작아집니다. 그리고 이 값이 교차 엔트로피를 지나 원핫인코딩의 결과값이 도출되게 됩니다.
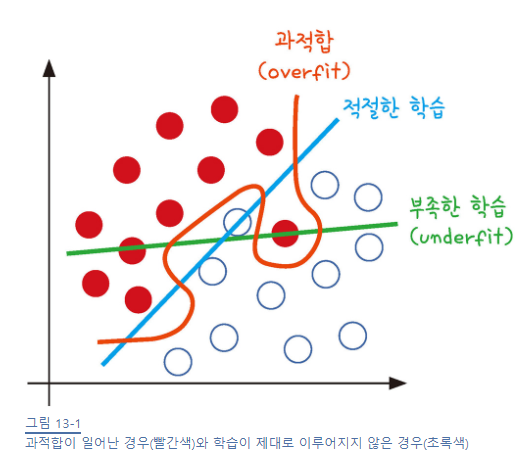
그리고 모델학습에 있어서 주의해야되는 상황들이 있는데 과적합 문제가 대표적입니다. 과적합 즉, overfitting이란 모델이 학습 데이터셋 안에서는 일정 수준 이상의 예측 정확도를 보이지만, 새로운 데이터에 적용하면 잘 맞지 않는 것을 말합니다. 이러한 과적합은 1)층이 너무 많거나 2)변수가 복잡해서 발생하기도 하고, 3) 테스트셋과 학습셋이 중복될 때 생기기도 합니다. 이처럼 과적합을 방지하려면 3)을 해결하는 방법으로 먼저 학습을 하는 데이터셋과 이를 테스트할 데이터셋을 완전히 구분한 다음 학습과 동시에 테스트를 병행하며 진행하는 것이 방법입니다.
from sklearn.model_selection import train_test_split
...
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=seed)그런데 학습셋만 가지고 평가할때, 층을 더하거나 에포크 값을 높여 실행 횟수를 늘리면 정확도가 계속해서 올라갈 수 잇는데 이 예측 성공률이 테스트셋에서도 그대로 나타나지는 않습니다. 즉, 학습이 깊어져거 학습셋 내부에서는 성공률은 높아져도 테스트셋에서는 효과가 없다면 과적합이 일어나고 있는 것입니다. 따라서 더 이상 좋아지지 않는 지점에서는 학습을 멈춰야 합니다.
또한 그 외에 발생하는 문제들 중 데이터가 그만큼 충분하지 않을 때 발생하는 경우가 있는데, 이 경우에는 'k겹 교차 검증'의 방법을 사용하여 데이터셋을 여러 개로 나누어 하나씩 테스트셋으로 사용하고 나머지를 모두 합해서 학습셋으로 사용하는 방법입니다.
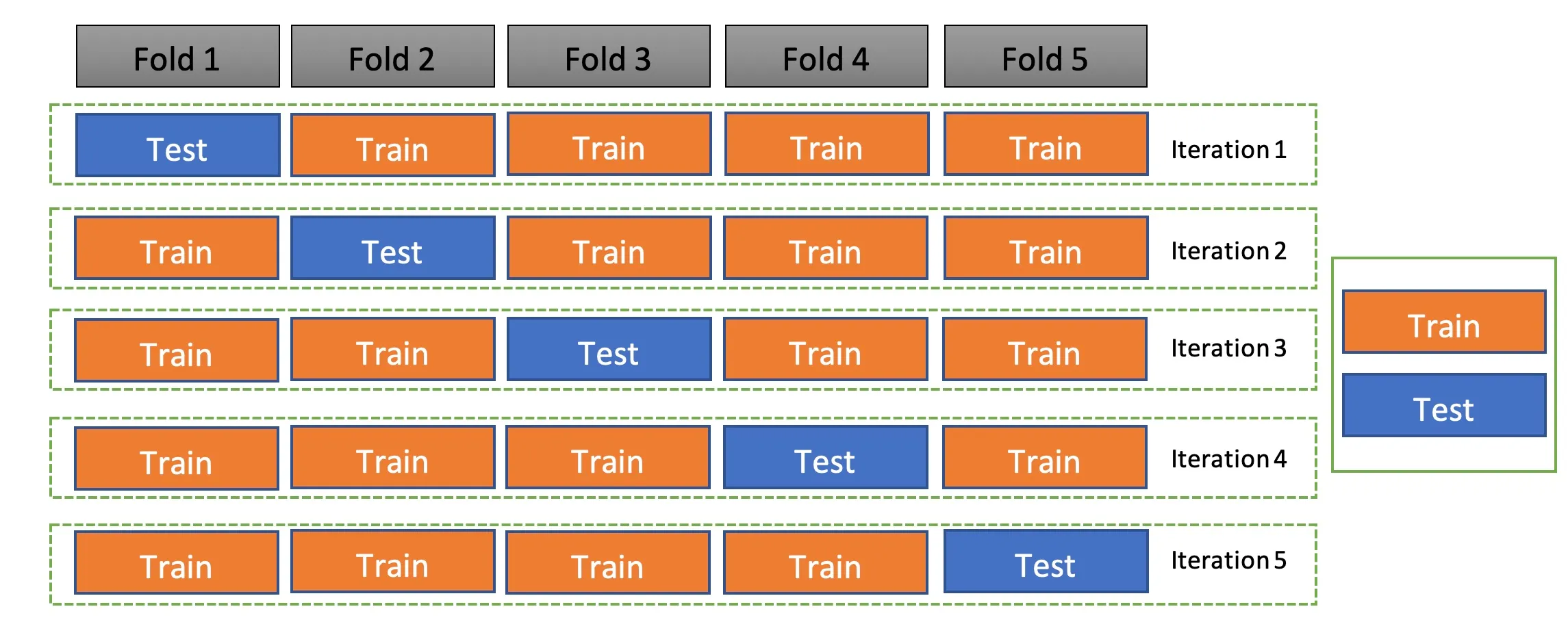
from sklearn.model_selection import StratifiedFold
n_fold =10
skf= StraitfiedFold(n_splits=n_fold,shuffle=True,random_state=seed)데이터의 확인과 실행은 df = df_pre.sample(frac=1)
위의 코드내용에서 df_pre라는 공간에 데이터를 불러옵니다. 그리고 sample()함수를 사용하여 원본 데이터의 몇 %를 사용할지를 1은 100%, 0.5는 50%를 의미합니다. 그리고 모델을 업데이트 하는 과정에서 모델을 저장하고 재사용하는 방법은 save()함수와 load_model()함수를 통해 실행할 수 있고,
from keras.callbacks import ModelCheckpoint,EarlyStopping
...
modelpath="./model/{epoch:02d}-{val_loss:.4f}.hdf5"
checkpointer = ModelCheckpoint(filepath=modelpath, monitor='val_loss', verbose=1, save_best_only=True)
...
history = model.fit(X_train, Y_train, validation_data=(X_test, Y_test), epochs=30, batch_size=200, verbose=0, callbacks=[early_stopping_callback,checkpointer])
위의 코드내용중 save_best_only=True 옵션값을 조정하는 것을 통해 더 나아졌을 떄만 저장할 수 있도록 합니다.
그리고 matplot함수를 이용해서 그 값을 보여줍니다.
# 그래프로 표현
x_len = numpy.arange(len(y_loss))
plt.plot(x_len, y_vloss, marker='.', c="red", label='Testset_loss')
plt.plot(x_len, y_loss, marker='.', c="blue", label='Trainset_loss')
# 그래프에 그리드를 주고 레이블을 표시
plt.legend(loc='upper right')
# plt.axis([0, 20, 0, 0.35])
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
그리고 학습이 진행될수록 학습셋의 정확도는 올라가지만 과적합으로 인해 테스트셋의 실험 결과는 점점 나빠지게 되는데 이때 테스트셋의 오차가 줄지 않으면 학습을 멈추게 하는 함수가 존재합니다.
from keras.callbacks import ModelCheckpoint,EarlyStopping
...
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=10)
...
# 모델의 실행
history = model.fit(X_train, Y_train, validation_data=(X_test, Y_test), epochs=30, batch_size=200, verbose=0, callbacks=[early_stopping_callback,checkpointer])선형 회귀를 적용하면 다음과 같습니다.
여러가지 요인을 모아서 환경과 집값의 변동을 보여주는 데이터셋을 만들었습니다. 그런데 이때까지와는 다르게 0과1을 맞히는 문제 혹은 여러 개의 보기 중 맞는 하나를 예측하는 문제외에 수치를 예측하는 문제에 대해서 보면 모델의 학습이 어느 정도 되었는지 확인하기 위해 예측 값과 실제 값을 비교하는 부분을 추가한 후, flatten()을 통해 데이터 배열이 몇 차원이든 모두 1차원으로 바꿔 읽기 쉽게 해주는 함수를 통해 그 과정을 수행합니다.
그림 출처
https://velog.velcdn.com/images/pppanghyun/post/2a39921c-be87-4c53-ba92-3e5c4c06699d/image.png
https://blog.kakaocdn.net/dn/b1HF7U/btqFBK5j2AX/bpnQAfkdMYwavefVUxj2K0/img.png
참고자료
<모두의 딥러닝>(길벗출판사)
{kind=link}
{kind=link}
