 [그림-1] 논문 Abstract
[그림-1] 논문 Abstract
아래 내용을 확인해보시면 본 논문 이해에 도움이 될 수 있습니다.
- ResNet
- Swin Transformer
Abstract
-
Hierarchical Transformer(e.g., Swin Transformers)는 바닐라 ViT(Vision Transformer)의 문제를 깨고 일반적인 CV(Computer Vision) Task에 실질적으로 적용될 수 있도록 함.
-
하지만 이는 convolution에 내재된 inductive bias가 아닌 Transformer 자체의 우수성에 기인한 결과임.
-
이 논문의 목표는 ConvNet의 한계를 시험하는 것임에 따라, 표준 ResNet을 ViT의 방향으로 점진적으로 현대화(modernize)시키면서 성능 차이를 야기하는 핵심 요소를 파악하고자 함.
-
그 결과가 순수 ConvNet 구조인 ConvNeXt.
1. Introduction
1) ImageNet moment
-
2010년대에 ImageNet moment라고도 불리우는 AlexNet의 등장 이후로 시각 인식(visual recognition) 분야는 특징 추출(engineering features) 중심에서 아키텍쳐 설계(ConvNet 기반) 중심으로 이동함.
-
특히 고해상도 이미지에서의 시각처리에 필수적인 sliding window 전략과 ConvNet에 내장된 inductive bias가 잘 맞음.
2) Transformer
-
NLP(자연어 처리) 분야에서 Transformer가 RNN 구조를 대체하고 주류 backbone 구조로 자리잡고, 이후 2020년 ViT의 등장으로 NLP와 CV의 흐름이 수렴함.
-
이미지를 일련의 patch들로 분할하는 ViT의 첫 patchify 레이어를 제외하면 ViT에는 이미지에 특화된 inductive bias도 없고 기존 Transformer에서의 큰 변경점도 없음.
-
ViT의 주목할만한 점은 확장성인데, 모델과 데이터셋 규모가 커질수록 Transformer는 ResNet보다 훨씬 좋은 성능을 낼 수 있음.
-
하지만 ConvNet의 inductive bias가 없는 상황에서 가장 큰 문제점은, ViT의 global attention 구조가 input size에 대해 이차적 복잡성(quadratic complexity)를 지닌다는 것이고, ImageNet 수준에서는 괜찮았어도 고해상도 이미지에서는 극복할 수 없는 문제가 됨.
3) Hierarchical Transformer
-
이 문제를 해소하기 위해 하이브리드 접근법을 도입함. 예를 들어, sliding window(e.g. local window 내에서의 attention) 전략이 Transformer에 도입되었음.
-
그 흐름의 초석인 Swin Transformer가 Image Classification 외 일반적인 CV Task에서도 SOTA 성능을 기록하는 것을 보고 convolution의 존재가 사라지긴 커녕, 오히려 필요함을 확인함.
-
하지만, sliding window 자체에 대한 단순한 구현은 큰 비용을 요구할 수 있음. 가령 cyclic shifting과 같은 고수준의 접근법을 사용하면 속도가 최적화될 수 있지만, 시스템 설계가 매우 복잡해짐.
4) Modernize ResNet
-
ConvNet이 밀리는 것처럼 보이게 하는 핵심 요인으로써 Transformer의 확장성에 크게 기여하는 MHSA(Multihead self-attention)가 있음.
-
시스템 단계에서의 비교를 하자면, ResNet과 Swin Transformer는 공통적으로 유사한 inductive bias를 지니고 있지만, 학습 절차와 거시적인(macro)/미시적인(micro) 단계에서의 아키텍쳐 설계가 크게 다름.
-
이에 표준 ResNet을 개선된 절차로 학습시킨 후, 점진적으로 hierarchical ViT 구조의 방향으로 현대화(modernize)시키면서 "Transformer 내 어떤 설계 결정이 ConvNet 성능에 영향을 끼칠 것인가?"라는 질문의 답을 찾고자 함.
-
그 결과 몇가지 핵심 요소를 찾아 적용한 ConvNeXt는 순수 ConvNet 구조임에도 불구하고 accuracy, 확장성 및 견고함 측면에서 모두 Transformer를 뛰어넘음.
2. Modernizing a ConvNet: a Roadmap
 [그림-2] 논문 내 Figure2
[그림-2] 논문 내 Figure2
ResNet이 Transformer와 유사한 ConvNet 구조로 이동하는 기록이 위 표에 담겨있으며, 성능 비교는 각각 ResNet-50과 Swin-T(tiny 모델로 추정), ResNet-200과 Swin-B(base 모델로 추정)에 대해 진행함. 후술되는 내용은 ResNet-50과 Swin-T의 비교에 대한 것임.
2.1 Training Techniques
최신 학습 기법을 적용하면 ResNet-50의 성능을 끌어올릴 수 있다는 최근 연구에 입각하여, DeiT와 Swin Transformer와 유사한 학습 방식을 적용함.
| 항목 | 표준 ResNet | 논문 |
|---|---|---|
| Epoch | 90 | 300 |
| Optimizer | SGD | AdamW |
| Augmentation |
- scale augmentation - random cropping - horizontal flip - standard color augmentation |
- Mixup - Cutmix - RandAugment - Random Erasing |
| Regularization |
- Stochastic Depth - Label Smoothing |
2.2 Macro Design
-
Swin Transformer의 거시적인 네트워크 구조(block 및 네트워크 단위)를 분석해보면, ConvNet을 따라 여러 stage를 구성했고, 각 단계(stage)는 각기 다른 feature map 크기(resolution)을 지님.
-
이때 흥미로운 점은 단계에 대한 연산 비율(stage compute ratio)과 줄기세포 구조(stem cell structure)임.
1) Changing stage compute ratio
-
Swin-T는 ResNet의 기본적인 원칙은 따르나, 각 단계의 연산 비율은 1:1:3:1로, ResNet-50의 3:4:6:3과 다름.
-
따라서 ResNet-50도 (3, 3, 9, 3)으로 수정하여 Swin-T에 맞춰 FLOPs를 조정함.
Changing stem to "Patchify"
-
Swin-T는 patchify 전략으로, 처음에 큰 커널 크기(e.g. kernel size = 14 or 16)와 non-overlapping convolution을 사용함.
-
이에 맞춰 ResNet 스타일의 stem cell((7 X 7), stride 2 convolution, max pool)을 patchify stem((4 X 4), stride 4 convolution)으로 변경함.
2.3 ResNeXt-ify
-
ResNeXt가 바닐라 ResNet보다 더 나은 FLOPs/accuracy trade-off를 지닌다는 점에 착안하여 그 구조를 참조함.
-
핵심 요소는 grouped convolution으로, ResNeXt에서는 3 X 3 conv layer에 grouped convolution을 사용함.
-
여기서는 depthwise convolution(그룹 수 = 채널 수)을 사용함. 이는 채널 단위로 수행되는 self-attention의 가중합 연산과 유사함(공간 차원의 정보만 혼합).
-
이어서 1 X 1 conv와 조합하면 공간과 채널의 혼합으로 분리되는데, ViT처럼 공간 및 채널 차원에 대해 정보를 혼합하되 둘 모두에 대해서 혼합하지는 않는 특성을 지닌다(depthwise conv에서 공간 정보를 혼합한 뒤 1X1 conv로 채널 정보 혼합).
-
ResNeXt의 전략대로 네트워크의 너비를 증가시키되, Swin-T에 맞춰 채널 수를 64 -> 96으로 변경
2.4 Inverted Bottleneck
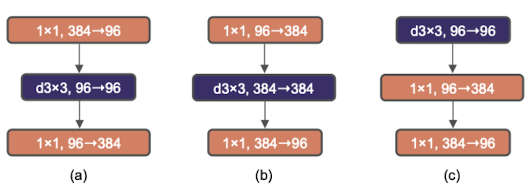 [그림-3] 논문 Figure3
[그림-3] 논문 Figure3
(a) ResNeXt block,
(b) inverted bottleneck,
(c) depthwise conv layer 위로 이동
- 채널 수를 줄였다가 늘리는 기존의 bottleneck과 달리 채널 수를 늘렸다가 줄이는 방식이 inverted bottleneck이며, 확장 비율은 4배([그림-3]의 (b) 참고).
- MobileNetV2에 의해 대중화된 방법이며, 모든 Transformer block은 이 inverted bottleneck을 만들어낸다고 함.
- depthwise conv의 FLOPs가 상승했지만, downsampling하는 residual block의 shortcut 1X1 conv layer의 FLOPs가 대폭 감소하여 전체 네트워크의 FLOPs가 감소함. 하지만 성능은 약간 향상됨(80.5% -> 80.6%).
2.5 Large Kernel Sizes
- ViT의 가장 도드라지는 특징 중 하나는 바로 non-local self-attention이며, 이는 각 layer가 global receptive field를 지니도록 함.
- Swin-Transformer가 비록 self-attention block에 local window 개념을 다시 가져오긴 했지만, 그래도 window size는 최소 7 X 7로, ResNe(X)t의 3 X 3에 비하면 매우 큰 차이임.
- 따라서 VGGNet에 의해 ConvNet의 황금율이 된 kernel size 3 X 3을 깨고 다시 큰 kernel size를 살펴보고자 함.
1) Moving up depthwise conv layer
- 우선 depthwise conv layer를 위로 올림(그림-3에서 (c)로 변경). 이는 MSA block이 MLP block 이전에 위치하는 Transformer를 근거로 함.
- 복잡하고 효과적이지 않은 모듈(MSA, large-kernel conv)의 채널 수는 적게 할당하면서 효과적인 1 X 1 layers에는 힘을 줄 수 있음.
2) Increasing the kernel size
- kernel size는 7 X 7일 때가 가장 효과적.
- 3, 5, 7, 9, 11에 대해 시험을 해봤으며, 더 큰 커널 크기의 이점은 7 X 7일 때가 최대 수준이었음.
2.6 Micro Design
앞서 Macro Design이 block 및 네트워크 단위에서의 이야기였다면, 여기서는 layer 단위의 분석이 진행되며, activation function과 normalizaion layer에 초점을 맞춤.
1) Replacing ReLU with GELU
- NLP와 CV 아키텍쳐의 한 가지 차이점은 사용하는 activation function이 다르다는 점.
- 수많은 activation function의 발전이 있었음에도 불구하고, ConvNet에서는 단순하면서 효과적인 ReLU를 사용함.
- 하지만 BERT, GPT-2, ViT 등 최근의 진보된 Transformers에서는 모두 GELU(Gaussian Error Linear Unit)를 사용함.
- 변경해도 성능의 차이는 없으며, 적용해도 문제 없음을 확인함.
2) Fewer activation functions
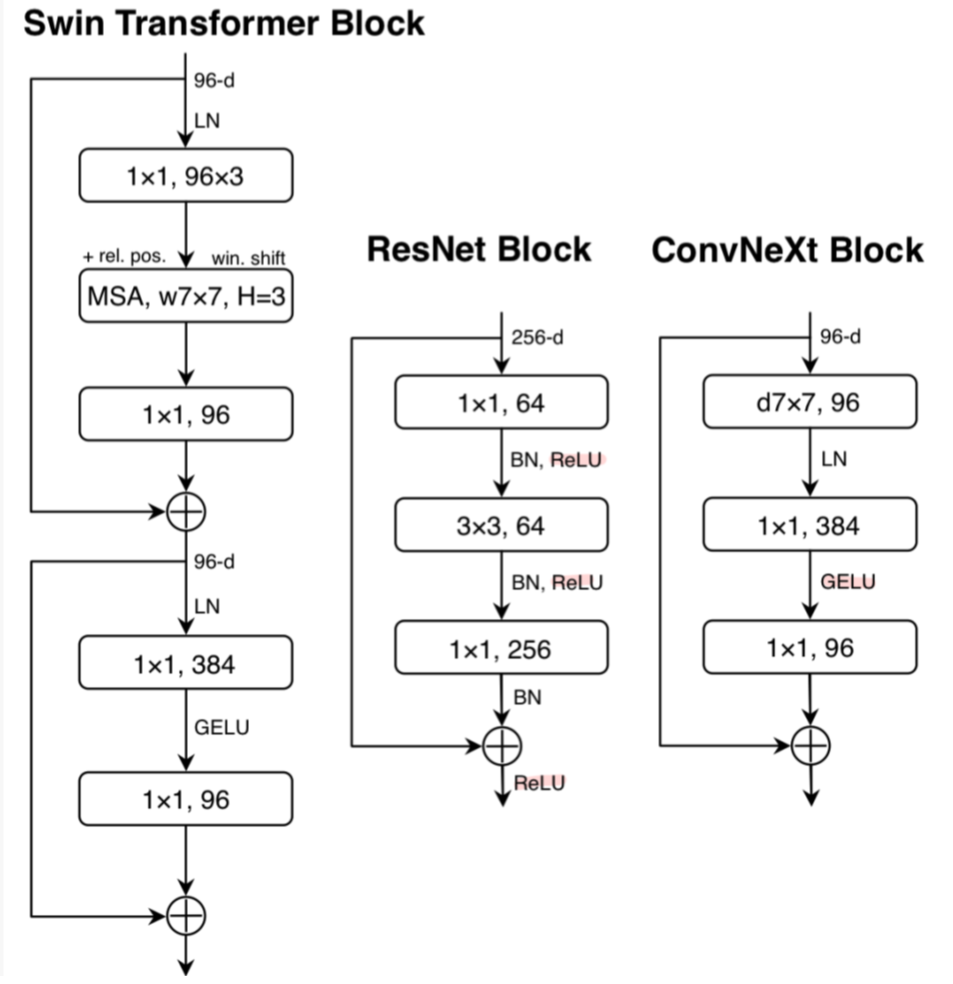 [그림-4] 논문 Figure4 (activation function 마킹)
[그림-4] 논문 Figure4 (activation function 마킹)
Swin Transformer, ResNet, ConvNeXt의 block 구조.
Transformer의 MLP block은 편의상 "1X1 convs"로 표기함.
-
Transformer는 MLP block 통틀어서 activation function이 하나만 있는 반면에 ConvNet은 1X1를 포함한 모든 conv 레이어마다 activation function이 할당되어 있음.
-
따라서 두 1X1 conv layer 사이에 하나를 제외한 residual block 내 모든 GELU 레이어를 없앰.
3) Fewer normalization layers
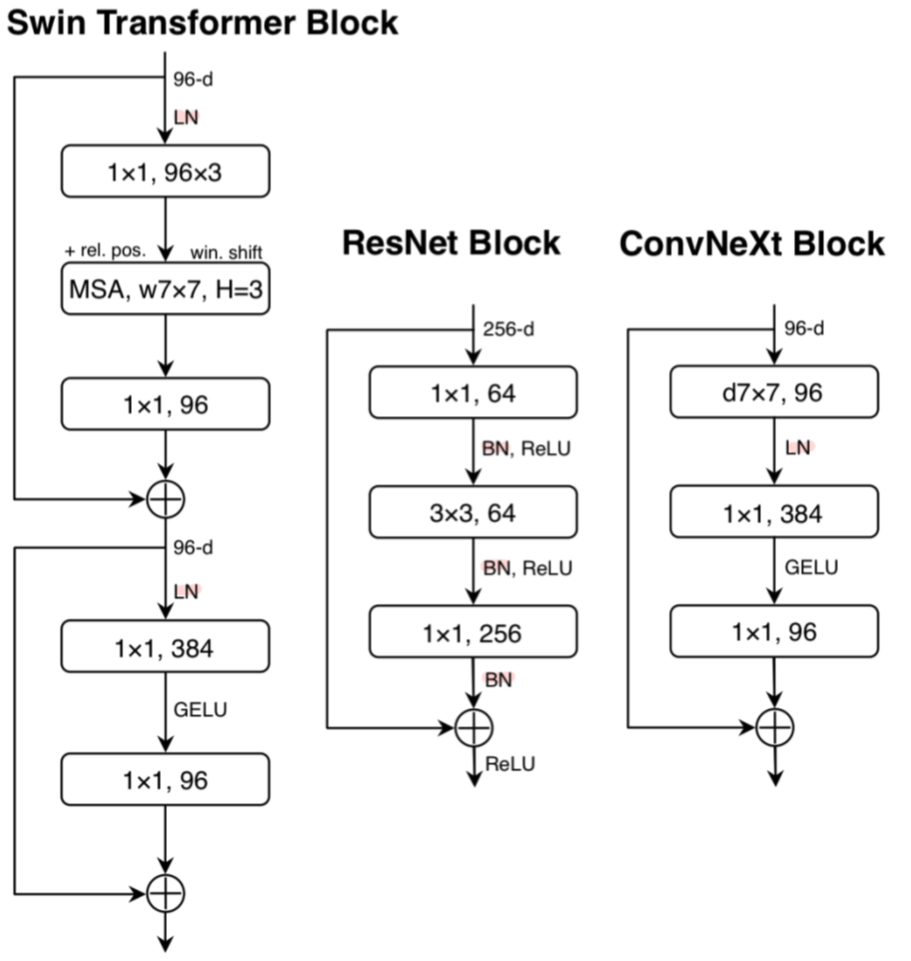 [그림-5] 논문 Figure4 (normalization layer 마킹)
[그림-5] 논문 Figure4 (normalization layer 마킹)
- 마찬가지로 noramalization layer도 ResNet에 비해 Swin Transformer가 더 적음.
- 따라서 1X1 conv 레이어 이전에 1개의 BN(Batch Normalization) 레이어만 배치하고 나머지는 제거함.
- 이때 성능은 Swin Transformer를 뛰어넘었으며, normalizaion layer의 개수도 더 적음.
- 경험적으로, block 시작 전에 BN 레이어를 하나 더 두는 것은 성능 개선에 기여하지 않음을 확인함.
4) Substituting BN with LN
- BN(Batch Normalization)은 ConvNet에서 수렴을 개선하고 과적합을 줄여준다는 점에서 애용하는 normalization 방법이나, Transformers에서는 더 단순한 LN(Layer Normalization)을 사용하고 더 나은 성능을 보임.
- 표준 ResNet에서 BN을 LN으로 직접 바꾸는 것에는 무리가 있겠으나, 이 모델(ConvNeXt)의 경우, 직접 바꿨을 때 성능이 소폭 향상함.
5) Separate downsampling layers
- Swin Transformer에서 downsampling layer를 각 단계와 분리시킨 아이디어를 차용함.
- 2X2 conv layers(stride 2)를 spatial downsampling에 사용하며, 앞에 LN이 선행되었을 때 더 안정적인 학습이 가능했음.
- 추가적으로 Swin Transformer를 따라 LN을 추가 배치하였으며, 위치는 다음과 같음.
- 각 downsampling layer 앞, stem 이후, global average pooling 이후.
3.1. Settings
아래의 데이터셋에 대해 훈련을 진행함
- ImageNet-1K (1000 클래스, 1.2M 훈련 이미지)
- ImageNet-22K (21841 클래스(ImageNet-1K 클래스의 슈퍼셋), 14M 사전학습 이미지, ImageNet-1K로 fine-tune)
1) Training on ImageNet-1K
| 항목 | 설명 |
|---|---|
| Epoch | 300 |
| Optimizer | AdamW |
| learning rate | 4e-3 |
| scheduler |
- 20-epoch linear warmup - cosine decay |
| batch size | 4096 |
| weight decay | 0.05 |
| augmentation |
- Mixup - Cutmix - RandAugment - Random Erasing |
| regularization |
- Stochastic Depth - Label Smoothing |
| Layer Scale | 1e-4 |
- EMA(Exponential Moving Average)가 더 큰 모델의 과적합을 완화시키는 것을 확인함.
2) Pre-training on ImageNet-22K
| 항목 | 설명 |
|---|---|
| Epoch | 90 |
- warmup은 5epoch만 진행
- EMA 미사용
- 그 외는 ImageNet-1K 때와 동일.
3) Fine-tuning on ImageNet-1K
| 항목 | 설명 |
|---|---|
| Epoch | 30 |
| Optimizer | AdamW |
| learning rate | 5e-5 |
| scheduler |
- no warmup - cosine decay |
| batch size | 512 |
| weight decay | 1e-8 |
- pre-training, fine-tuning, test 시 기본 해상도는 224 X 224.
- 추가적으로, 384 X 384의 해상도로 fine-tune 진행(ImageNet-22K와 ImageNet-1K pretrained models).
- ViTs/Swin Transformers와 비교했을 때 ConvNeXt는 다양한 해상도에 대해 fine-tune하기 훨씬 단순함. Fully-convolutional하고, input patch size를 맞추거나 position biases에 대해 보간(interpolate)할 필요도 없기 때문.
6. Conclusions
- 제시된 방법들은 완전히 새로운 것이 아니며, 다만 개별적으로 확인된 각 선택들을 종합적으로 고려한 것일 뿐임.
- 단순하면서도 효과적인 ConvNeXt를 제안함.
