
학습목표
- 선형모델은 단순한 데이터를 해석 시 유용하지만, 분류문제나 복잡한 패턴의 문제를 풀 때는 예측성공률이 높지 않음
- 이를 개선하기 위한 비선형 모델인
신경망 (Neural network)을 공부- 신경망의 구조와 내부에서 사용되는
softmax,활성함수 (activation function),역전파 알고리즘에 대해 학습- 딥러닝은 여러 층의 선형모델과 활성함수에 대한 합성함수로 볼 수 있으며, 이 합성함수의 gradient를 계산하기 위해서
연쇄법칙을 적용한 역전파 알고리즘을 사용
1. 신경망 (비선형모델)을 수식으로 분해
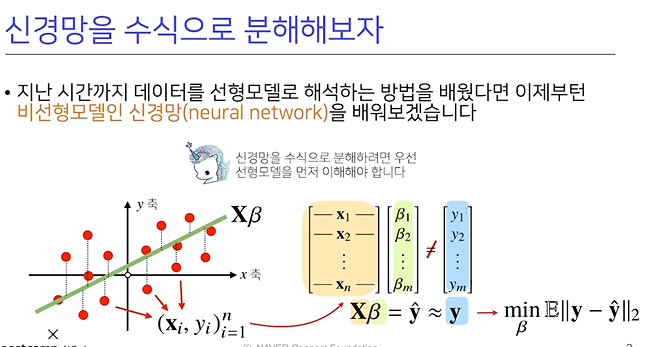
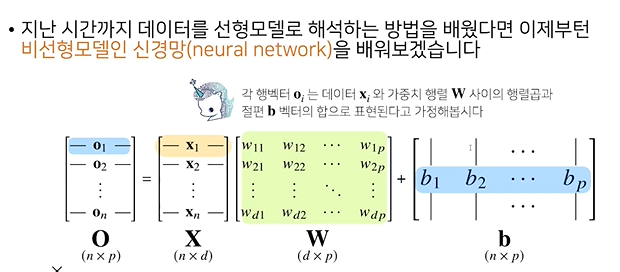
X: 데이터들의 포인트 (점)W: 다른 벡터공간으로 이동해주는가중치 행렬b:y절편에 해당하는 행렬 (행들이 같은 값을 가짐)O= X * Y + B
n*d= X행렬은 데이터가 n개- W=(dp)를 곱했기 때문에 두 행렬의 결과 값이, b=(np)행렬이 출력에 해당하는
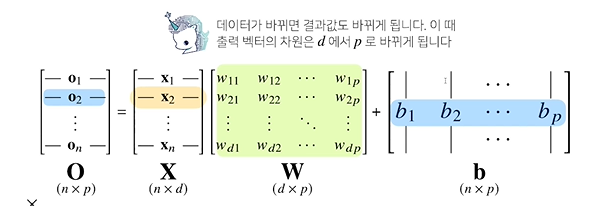
O행렬의 차원- 차원에 해당하는 것이 열에 들어가는 차원의 개수가 바뀐다는 사실을 기억해야함
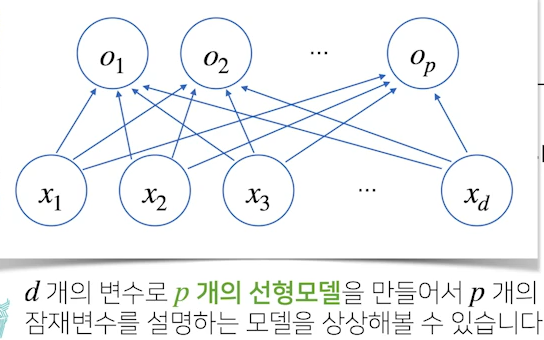
- x1 ~xd (행벡터에 들어있는 d개의 개수)가 , o1~op 출력으로 연결되는
도식화살표: w행렬(가중치행렬)들의 역할- 동작방식은 x라는 행벡터가 주어졌을 때, x라는 행벡터를 O라는 행벡터로 연결하게 될 때,
- 연결방식이 x라는 변수들을 O라는 변수들로 각각
선형연결하게 될 때
p개의 모델을 만들어야하는데 X1~Op까지 연결되는화살표는 p개만들어지게 되고,
화살표의 개수는 총p*d개(w행렬)
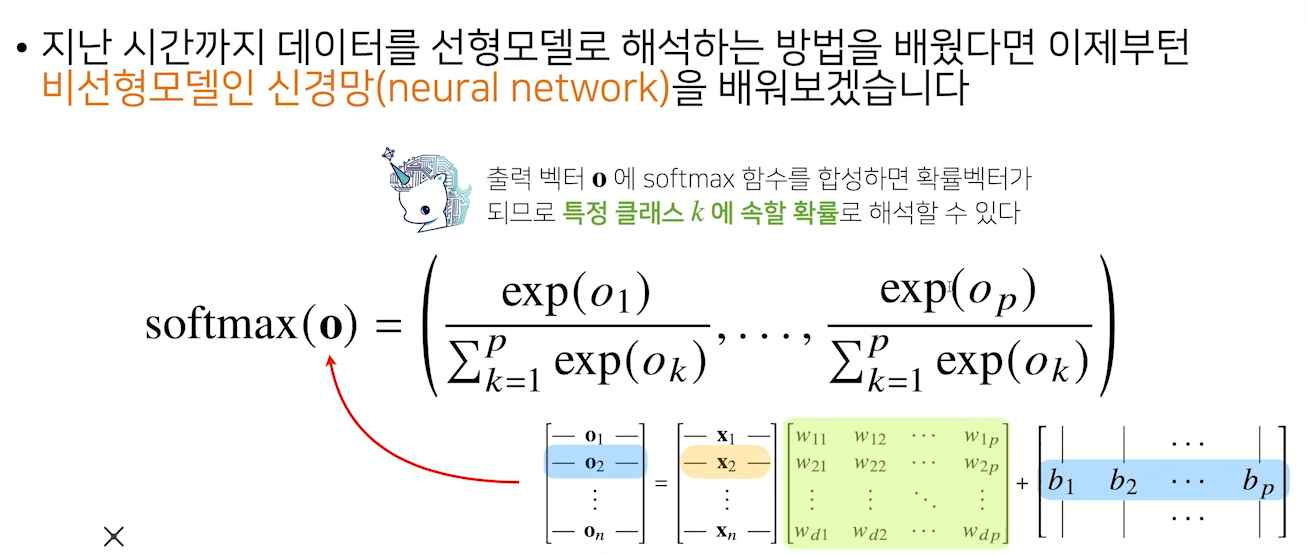
- 분류문제를 풀 때, 학습을 시키려면
softmax라는 연산을 사용해야 함
exp(지수함수)를 통해 계산
2. 소프트맥스 연산

- 현재 주어진 모델에서 특정 클래스에 속할
확률을 계산할 수 있기 때문에, 분류 문제 시 출력 값 활용max는오버플로우를 방지하기 위함- 소프트맥스로 확률 벡터로 변환하고 이걸 이용해 해석하고 학습 때 사용
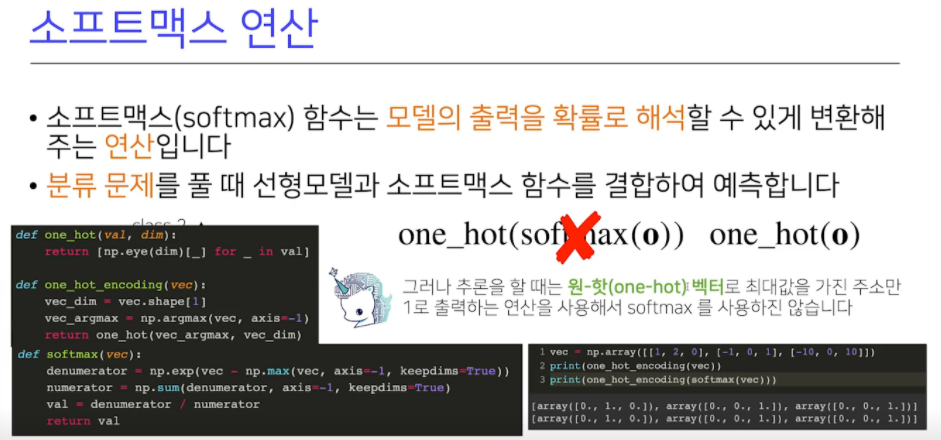
추론할 때는 one_hot벡터사용
3. 신경망 : 선형모델과 활성함수를 합성한 함수

활성함수(activation function) → 잠재벡터 생성- 이를 이용해 딥러닝에서 선형모델의 출력물을 비선형 모델로 변형시킬 수 있고,
이렇게 변형시킨 벡터를잠재벡터 (Hidden vector)라고 하며,
이를뉴런이라고 하며 뉴런으로 이뤄진 것을신경망(뉴런 네트워크)라고 함
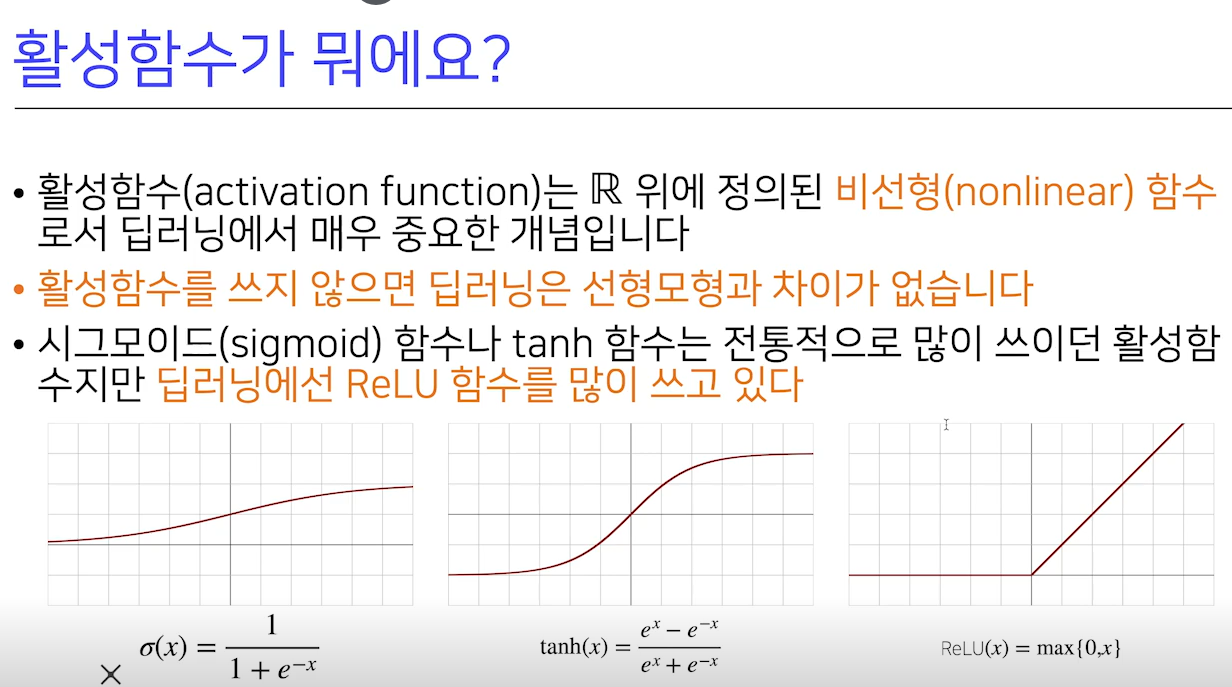
4. 활성함수
- 활성함수는 R위에 정의된 비선형 함수로 딥러닝에서 매우 중요한 개념
- 활성함수를 쓰지 않으면, 딥러닝은 선형모형과 차이가 없음
- sigmoid 함수나 tanh함수는 전통적으로 많이 쓰던 활성함수이지만, 현재 딥러닝에서는 ReLU를 많이 사용
- 순서대로 →
sigmoid함수 /tanh(탄젠트) 함수 /ReLU함수ReLU: 전형적인 비선형 함수
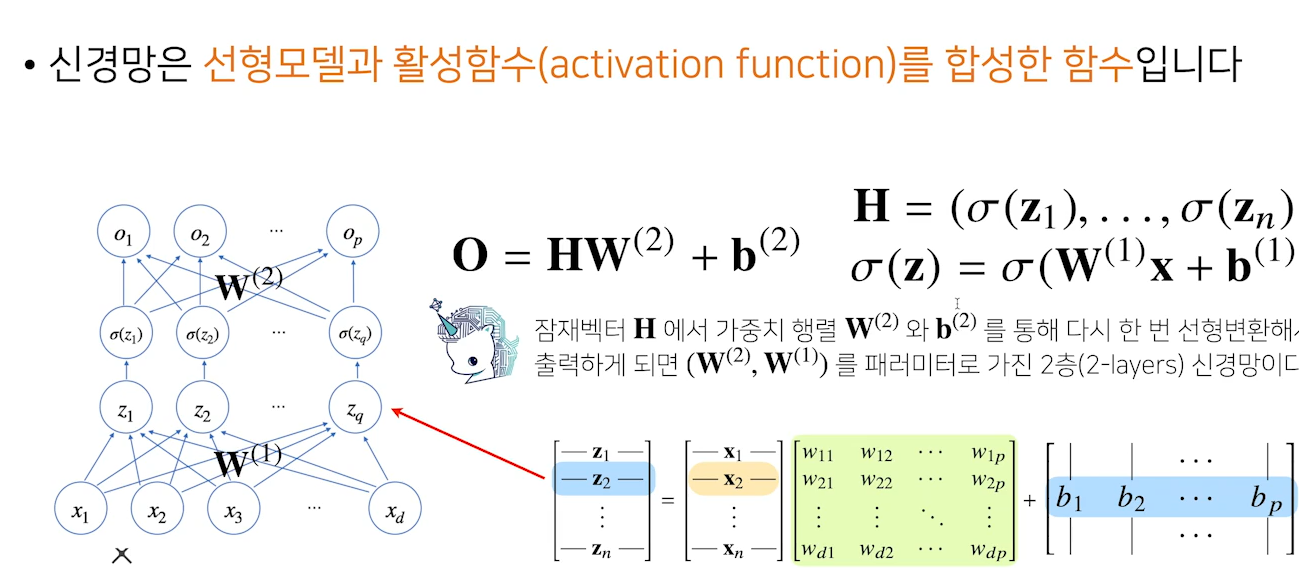
이층 신경함수(2-layer 신경망)활성함수를 쓰는 것이 핵심 포인트
5. 다층(multy-layer) 퍼셉트론(MLP)는 신경망이 여러층 합성 함수

- 딥러닝의 기본적인 모형
x(입력)에w(가중치 행렬)로z로 보내고, z에활성함수 (sigmoid)를 씌우면H(hidden vector)활성함수(sigmoid)를 씌울 때각 벡터에 개별적으로 적용- z에 해당하는 모든 변수에 sigmoid를 씌운 행렬은 z라는 행렬이 들어왔을 때 그 구성함수에 활성함수를 씌운 행렬로 해석
- H라는 행렬은 z라는 행렬과
모양은 같고,
H에 있는 모든 구성성분들은z 의 구성성분에 활성함수를 씌운 차이가 있음

y절편에 해당하는b1~ bL까지의 절편 파라미터로 이뤄져 있다.

- 주어진 입력이 왔을 때 출력물을 내뱉은 과정을 표현하는 연산
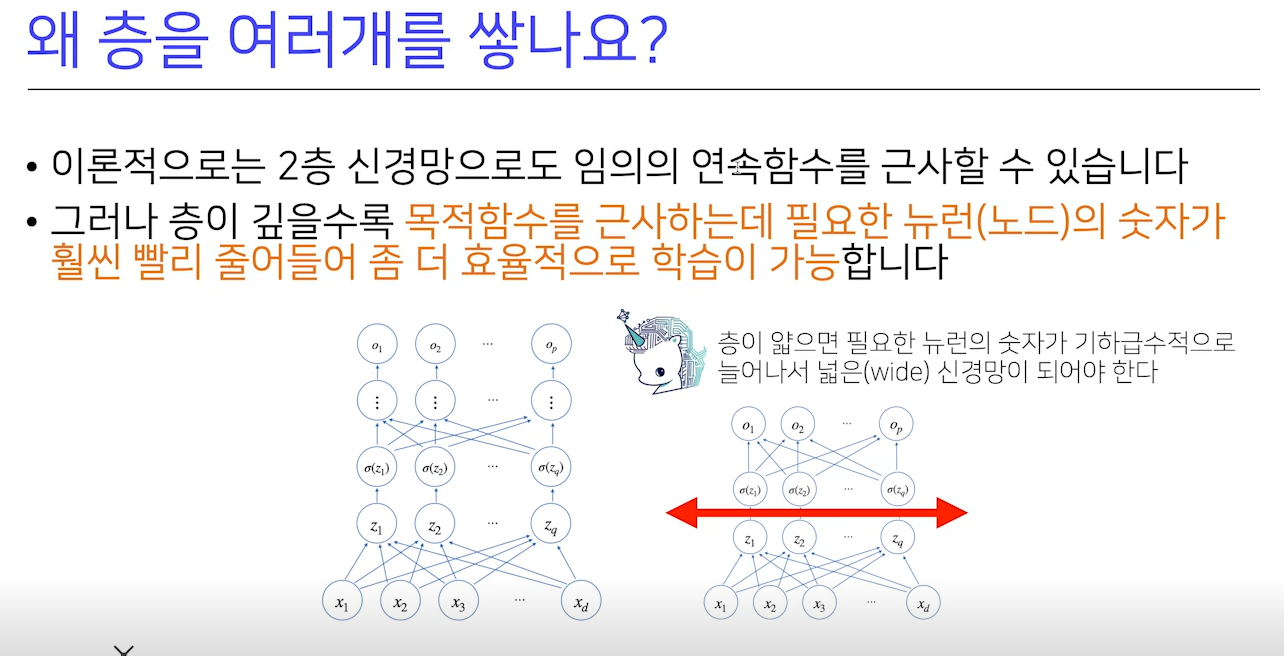
6. 왜 층을 여러 개 쌓을까?
- 이론적으로 2층 신경망으로도 임의의 연속함수를 근사할 수 있음
- 목적함수를 근사하는데 필요한 뉴런(노드)의 숫자가 훨씬 빨리 줄어 좀 더 효율적 학습이 가능
- 층이 앏으면 필요한 뉴런의 숫자가 기하급수적으로 늘어나, 넓은 신경망이 되어야 함
7. 역전파 알고리즘
7-1. 역전파 알고리즘 개요
💡
역전파 알고리즘:사슬 규칙을 이용하는 기울기 기반최적화 알고리즘에 따라 인공신경망(ANN)을 효율적으로 훈련하는데 사용되는 방법
- 역전파의 주요 특징은 학습 중인 작업을 수행할 수 있을 때까지 네트워크를 개선하기 위해 가중치 업데이트를 계산하는 반복적이고 재귀적이며 효율적인 방법으로, 네트워크 설계 시 활성화 함수의 파생물을 알아야 하며, 자동 미분은 파생물을 훈련 알고리즘에 자동 및 분석적으로 제공할 수 있는 기술
7-2. 역전파 알고리즘 배경
- 역전파는 XOR 문제를 해결하기 위해 1986년이 되어서야 등장
- 엄밀히 따지면 1974년도에 처음 해결책이 제시되었는데, 그 출처는 당시 하버드 대학원생이었던 폴 웨어보스(Paul Werbos)의 박사 논문
다층 퍼셉트론(MLP) 구조를 통해어떤 결과가 예측되었을 때,그 예측이 틀린다면 퍼셉트론의 Weight와 Bias 값을 조정해야하는 것을학습이라 말하며, 이 과정을반복할수록최적의 Weight와 Bias 값을 찾을 수 있음- 기존의 문제는 이 다층 퍼셉트론을 이루는 수많은 퍼셉트론 각각의 Weight와 Bias 값을 구조가 어렵다는 이유로 수정할 방법이 없었으나 이 문제에 대해 폴 웨어보스가 역전파 알고리즘을 제시했으나, 이 폴 웨어보스의 혁신적인 논문은 처음부터 주목받지 못했는데 그만큼 분위기가 침체되어 있었기 때문
- 그러다 1986년 제프리 힌턴(Geoffrey Hinton) 교수가 XOR 문제의 해결책을 제시하는데, 그 방법은 폴 웨어보스 박사의 역전파 알고리즘과 동일했으며, 서로 다른 두 사람이 동일한 방법을 생각해낸 것이지만, 엄밀히 따지면 제프리힌턴 교수가 해결책을 재발견했다고 말할 수 있음
7-3. 역전파 알고리즘 구동방식
- 임의의 초기 가중치()를 준 뒤 결과 ()를 계산
계산 결과와 원하는 값 사이의오차를 구함경사하강법을 이용해 바로 앞가중치를 오차가 작아지는 방향으로 업데이트- 위 과정을 더는 오차가 줄어들지 않을 때까지
반복- 여기서 '오차가 작아지는 방향으로 업데이트한다'는 의미는
미분 값이 0에 가까워지는 방향으로 나아간다는 의미- 즉,
'기울기가 0이 되는 방향'으로 나아가야 하는데, 이 말은가중치에서 기울기를 뺐을 때가중치의 변화가 전혀 없는 상태를 의미- 즉,
가중치에서 기울기를 빼고값의 변화가 없을 때까지계속해서 가중치 수정 작업을반복하는 것
- 이를 수식으로 표현하면,
즉,새 가중치는현 가중치에서 '가중치에 대한기울기'를 뺀 값
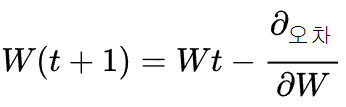

- 앞서 나온 것은 x(입력)를 최종 출력할 때
선형모델과 활성함수를 반복 적용하는 연산이라면,역전파는경사하강법을 적용해, 각각의 가중치 행렬들을 학습 시킬 때, 각각가중치에 대한 gradient 벡터를 계산해야 경사하강법을 적용할 수 있음
- 이는 선형회귀 분석에서 경사하강법을 적용할 때,
선형모델의 계수에 해당하는 Beta에 해당하는gradient 벡터를 계산해서 파라미터를 업데이트했는데 딥러닝 또한 같음- 각 층에 존재하는
파라미터들에 대한 미분을 계산한 것으로 파라미터를업데이트해야하는데, 경사하강법에서 가중치 업데이트할 때 행렬의원소의 모든 개수만큼 경사하강법 적용- 선형모델에서 경사하강법을 적용하는 것보다 훨씬 많은 파라미터에 대해서 경사하강법을 적용
- 문제는 선형모델의 경우, 경사하강법을 적용할 때 한 층에서만 계산하는 원리이기 때문에 gradient 벡터를 동시에 계산할 수 있지만
딥러닝의 경우순차적으로 계산을 하기 때문에 gradient 계산을 할 때 한 번에 할 수 없음
- 이 때,
역전파 알고리즘을 통해역순으로 계산을 함
- 역전파 알고리즘은
위 층에서 gradient 벡터를 계산하고,밑으로 가며 업데이트 하는 방식- 빨간색 화살표는 각 층에서 계산된 gradient를
밑으로 전달하는 흐름으로 볼 수 있는데,이는 밑에 층에서 gradient 벡터를 계산할 때 저층에서위층에 있는 gradient 벡터가 필요하기 때문

- 역전파 알고리즘의 원리는 각 층 파라미터의 그라디언트 벡터를 계산한 다음에, 역순으로 전달을 하며 계산을 하는 원리로, 이 원리를 사용할 때
합성함수의 미분법인연쇄법칙을 통해 그라디언트 벡터를 전달
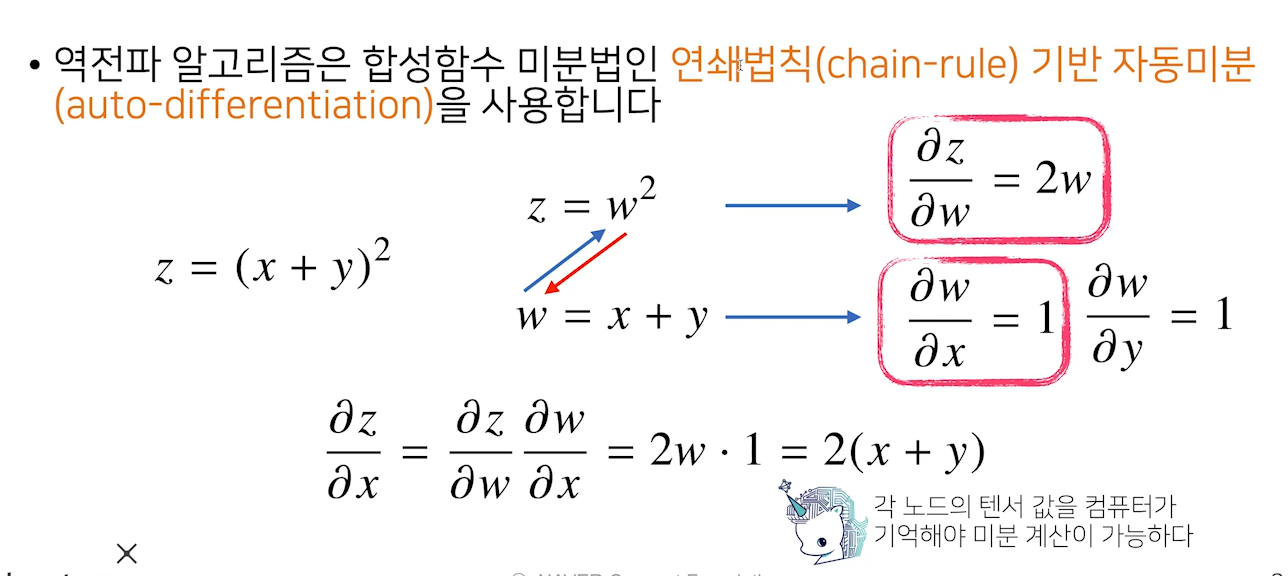
- 딥러닝에서 각 뉴런 값을
tensor라고 표현 →메모리로 저장해야만 역전파 알고리즘 가능- x에 대한 미분을 계산하고 싶다면, x와 y값을 알아야만 사용 가능
- 각 노드에 대항하는 tensor 값을 알아야하고 이는 메모리에 저장되어야 함
8. 2층 신경망

- 2개의 가중치
- 입력 x, 선형모델로 변형된 z에 활성함수를 씌운 h라는 hidden vector
- h를 다시 출력으로 연결시켜 다시 선형모델을 써서 2층 신경망을 구현

💡 이 때, 첫번째 해당하는 w1 행렬에 대해 경사하강법을 쓰고 싶다면?
- 빨간색이
역전파


세상을 이롭게하는 AI Engineer