
학습목표
- 조건부확률에서 이어지는 개념인
베이즈 정리와인과관계 추론에 대해 공부- 베이즈 정리는 데이터가 새로
추가되었을 때 정보를업데이트하는 방식에 대한 기반이 되므로 오늘날 머신러닝에 사용되는 예측모형의 방법론으로 많이 사용되는 방법론- 이 때 나오는
사전확률,사후확률,evidence등의 개념은 강의에서 나오는 예제를 활용해서 정확히 이해해야 함인과관계 추론의 경우, 조건부확률을 섣불리 사용해선 안 되는 이유와중첩효과를 제거함으로써 얻은 인과관계를 어떤 방식으로 활용할 수 있는지에 초점을 두고 학습
1. 조건부 확률
- 베이즈 통계학을 이해하기 위해 조건부확률의 개념을 이해해야 함

- 2개의 사건
A, B가 있을 때, 이 교집합이 일어날 확률은
조건부에 들어가는 사건의 확률 (특정사건)로 나눠주면 조건부확률을 구할 수 있음
- 위의 수식은 조건부 확률
P(A|B)에 확률P(B)를 곱했을 때, A와 B 교집합에 해당하는 사건의 확률 를 계산할 수 있다는 정의에서 출발
- 어떤
사건 B가 일어난다는 조건부 상황에서조건부 확률 P(A|B)를 계산하고 싶으면, 특정 사건B가 일어난 상황을 분모로 넣고,그 사건 B가 일어난 상황에서A가 발생할 확률, 즉교집합의 사건을 분자로 넣었을 때조건부확률 P(A|B)를 계산 가능→ P(A|B) =

- 이처럼 조건부 확률의 개념을 이용해 베이즈 정리를 유추할 수 있음
- 베이즈 정리는 조건부확률을 이용하여 정보를 갱신하는 방법을 알려주는 정리
- 위에서 계산한 조건부 확률은 B가 주어졌을 때 A가 일어날 조건부확률
P(A|B)을 계산하는 방법
- 이번에는 A가 주어졌을 때 B가 일어날 확률인
P(B|A)을 계산할 때,
을 A가 일어날 확률P(A)로 나누면P(B|A)계산가능→ P(B|A) =
- 그런데, 첫번째 수식에서는 교집합의 사건을 B가 주어져있는 경우 조건부확률로 표시할 수 있었는데, 첫 번째 수식에 B가 일어날 확률
P(B)xP(A|B)확률을 구해주면 조건부 확률을 대체할 수 있으니, 두 번째 수식처럼 베이즈 정리를 유도할 수 있음
- 즉, A가 조건부로 주어졌을 때 B의 사건을 구할 확률
P(B|A)은 B가 조건부로 주어졌을 때 A가 일어날 확률P(A|B)에P(A)를 나누고,P(B)를 곱하는 형태로 계산 가능→ P(B|A) = P(B)
- 위 수식에서
빨간색을 집중해서 보면, 처음 B가 일어날 확률P(B)이 주어져있을 때 B가 조건부로 주어져 있을 때 A가 일어날 확률P(A|B)과 A자체가 일어날 확률P(A)을 분모 분자에 해서 곱해주게 되면, A가 추가적으로 주어졌을 때 B가 일어날 확률P(B|A)계산 가능→ P(B|A) = P(B)
- A라는 정보가 새로 주어졌을 때,
P(B)로부터 P(B|A)를 계산하는 A가 조건으로 주어졌을 때,B라는 사건이 일어날 확률을 계산하는 방법이베이즈 정리의 공식의 의미
2. 베이즈 정리 예제

- : 새로 관찰한 데이터
- θ (theta) : 하이퍼데시스, 모델링하는 이벤트, 모델에서 계산하고싶은 파라미터, 모수
사후확률: 데이터가 주어졌을 때(관찰했을 떄), 이 파라미터가 성립할 확률
사전확률: 데이터가 주어지지 않은 상황에서 θ에 대한 모델링을 하기 이전에 사전에 주어진 확률, 데이터를 분석하기 전 모수나 하이퍼데시스, 가설 등 모델링하고자 하는 타겟에 대해 사전에 어떤 미리 가설을 가정을 깔아두고 확률분포에 대해 미리 찾아내 설정하는 확률 분포로, 사전확률에서 시작해서 데이터를 관찰하고나서 부터는 모델링 후 결과에 대해 사후확률을 계산할 때, 베이즈 공식을 이용해 업데이트 함
likelihood(가능도) : 주어진 파라미터 모수 또는 가정에서 이 데이터가 관찰될 확률을 계산하는 것이 원래 역할이며분자에 들어감evidence: 어떤 데이터들을 관찰할 때 데이터 자체분포를 evidence라고 함
θ(theta) : 데이터를 통해 어떤 모델을 학습 예측할 때,θ가 주어진 상황에서 이 데이터가 관찰될확률을 의미하는 것이기 때문에, likelihood과 evidence를 통해 사전확률을 사후확률로 업데이트 가능하고 많은 데이터 분석에 이용할 수 있음

- 이 문제는
사전확률과Recall(민감도),False alarm(오탐률)을 통해,
실제 이 테스트의Precision(정밀도)를 계산하는 문제
사전확률: 발병률 10%
θ: 실제 걸렸을 확률가능도(테스트의 효과) : 검진될 확률 99%, 오검진률 1%
- :검진될 확률
- 가능도 (likelihood)
- θ가 조건부로 주어졌을 때, 가 발견될 확률 (코로나에 걸렸을 때 검진될 확률)
→- θ가 아닌 상황(부정)에서 가 발견될 확률 (코로나에 걸리지 않았을 때 검진으로 나올 확률)
→- 추가로 evidence를 계산해야 계산이 가능

evidence 계산방법
- 가능도를 가지고 계산할 수 있음 (가능도 : 테스트의 효과) : 검진될 확률 99%, 오검진률 1%)
- θ (실제 걸렸을 확률)가 일어날 확률
0.1와 θ의 여집합이 일어날 확률 = 0.1을 뺀0.9를 가능도에 각각 곱해서 더해주게 되면,evidence의 확률을 계산할 수 있음
→ (0.99 x 0.1) + (0.01 x 0.9) = 0.108
- 만약, θ를 부정했을 때 가 일어날 확률, 즉 가능도를 하나도 모르게 된다면 이 문제는 풀기 어려움
- 이제, 사전확률 θ와 가능도, evidence를 가지고 있기 때문에
사후확률을 계산 가능

- 사전확률(θ) 0.1에 θ가 주어졌을 때 가 관찰될 확률인 실제 코로나에 걸렸을 때 검증될 확률, 즉
P(D|θ)인 0.99를 분자로 곱해주고 evidence에 해당하는 0.108을 분모에 넣어 계산을 하면0.916이 계산이 되고 이것이 문제에서 구하고자 하는질병에 걸렸을 때, 실제로 코로나에 걸렸을 확률=
→ 0.916 = 0.1 x
- 실제 검진될 확률이 99%이고, 오검진확률이 1%였기 때문에
높은 신뢰도가 있는 것인데,
💡 만약 오검진률이 10%로 오르면, 테스트 신뢰도는 어떻게 될까?

- 이 때, 2번째 가능도(θ)를 부정했을 때 D가 나올 확률 인 오탐률의 확률이 0.1로 오르기 때문에 다시 계산 해야함
- 이 경우 빨간색에 해당하는 부분을 반영해 계산했을 때, 0.524 (52.4%) 라는 훨씬 낮은 확률이 나오게 됨
- 이 베이즈 정리를 통해 알 수 있는 것은
오탐률이 오르게 되면테스트의정밀도가 떨어지게 됨- 이 병에 실제로 걸렸을 때 99%라고 하더라도, 걸리지 않았을 때 오검진될 확률이 10%가 되기 때문에
발병률과 결합이 되어서 실제 양성이 나왔을 때 이 병에 걸렸을 확률은 52.4%라는낮은 테스트 효과가 나오게 됨
3. 조건부 확률의 시각화
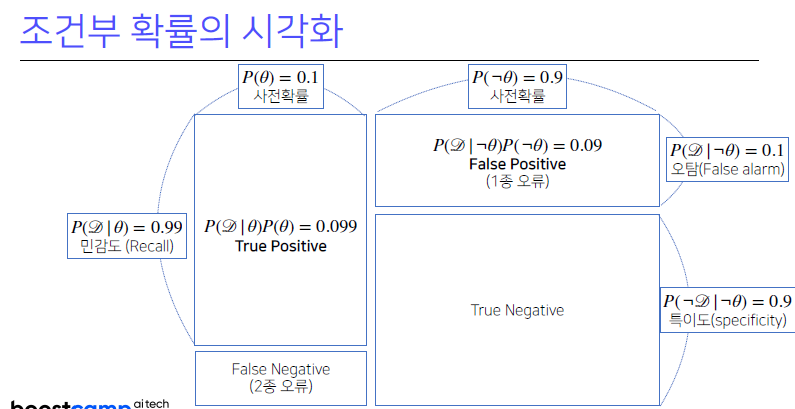
Confusion matrix (혼돈행렬)
- 조건부 확률이 계산이 되는 각각의 경우, 즉
양성이 나왔을 때 진짜 양성일 경우, 혹은음성이 나왔을 때 진짜 음성일 경우 혹은양성이 나왔을 때 실제와는 다른경우,음성이 나왔을 때 실제와 다른경우와 같이 4가지로 나올 수 있음
True Positive: 양성이 나왔을 때 진짜 양성일 경우True Negative: 음성이 나왔을 때 진짜 음성일 경우False Positive (1종 오류): 양성이 나왔을 때, 실제와는 다른 경우False Negative (2종 오류): 음성이 나왔을 때, 실제와 다른 경우
- 데이터 분석의 성격에 따라, 1종 오류 혹은 2종 오류를 줄일지 결정이
민감함
- 가령
암환자를 진단할 때, 조직검사의 효과가 1종 오류나 2종 오류나에 따라 다르게 됨- 2종 오류는 의료계에서 심각한 반면, 1종 오류는 심각도가 상대적으로 떨어질 것임
- 따라서, 1종 오류를 희생하더라도
2종 오류를 줄이는 방식으로 테스트를 설계함- 지금까지 계산한 방식으로는 '질병에 실제로 거렸을 때 데이터가 관찰될 확률'을 계산하는 것은
민감도 (Recall)에 해당하는 값이며,사전확률(θ)에 해당하는 것이 상단의가로 축에 해당하는 지표, 사전확률이 실제질병의 발생률이 되는 것이며 이는 데이터 분석을 하기 전 사전에 주어진 정보라고 보면 됨
사전확률없이 베이즈 통계학에서 분석을 하기 어렵고, 만약 사전확률을 모르는 경우에는 보통 임의로 설정하는 경우도 있겠으나, 이 경우는 베이즈 통계학에서 분석의 효과가 신뢰도가 떨어질 수 있기 때문에 주의해야 함
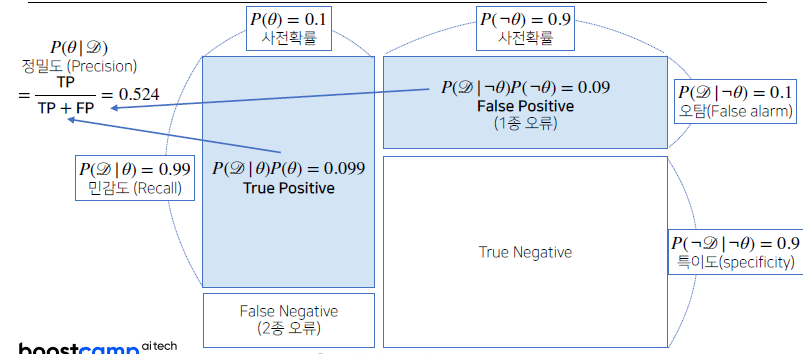
- 위 Confusion matrix는
사전확률이 0.1이고오탐지율이 0.1이었을 때 1종 오류와 2종 오류를 가지고정밀도를 계산했을 때,52.4%라는 수치가 나왔다는 것
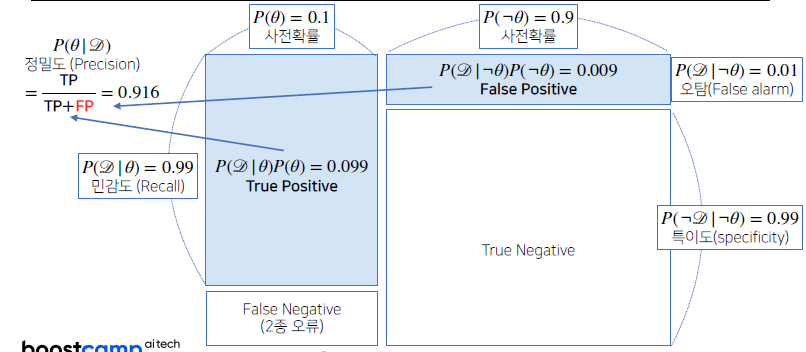
- 만약
오탐지율을 줄이게 되면 분모에 들어가는False Positive (1종 오류)의 텀이 적어지고, 오탐율이 0.1에서 0.01로 줄게 되면정밀도 계산이 높아지게 됨=
→ 0.916 =
- 분모에 들어가는 숫자가 작아지기 때문에 전체 숫자는 높아지므로,
정밀도를 계산할 때True Positive와False Positive로 계산하기 때문에오탐지율과민감도가 반영 돼, 계산할 수 있게 됨
4. 베이즈 정리를 통한 정보의 갱신

- 새로운 데이터가 들어왔을 때, 사전확률로 이용해
갱신된 사후확률로 계산 가능
- 데이터가 새로 들어오면, 정보를 갱신하는 것이 가능하다는 의미
- 우측 상단에 있는 베이즈 정리는 앞에서 계산한 사전확률에 의해 주어진 데이터를 가지고
사후확률을 계산한 것
사후확률: =
- 왼쪽 하단은 사후확률을 사전확률에 대입을 해서 가능도와 evidence를 다시 활용해
갱신된 사후확률을 계산
갱신된 사후확률: =→ =
사후확률: =
- 이 프로세스를 반복해서 데이터를 새로 관측할 때, θ를 점점 업데이트 하는 형태로 사후확률을 계산해서 모델링을 하면 모델링의 정확도, 예측력을 향상시킬 수 있음

오탐지율이 10% 라서, 이 테스트의 신뢰도는 52.4% 밖에 안나왔던 상황에서,
💡 과연 양성이 2번 나왔을 때 진짜 걸렸을 확률은 얼마가 될까?
💡 신뢰도가 52.4%이니까, 두 번째 판정도 믿을 수 없을까?

- 앞에서 계산한
사후확률 52.4%를사전확률 0.1대신 대입하게 됨

- 이 때, evidence를 갱신해서 계산할 수 있는데, 가능도는 그대로 두고 사전확률에서 계산했던 evidence를 앞에서 계산한 사후확률을 통해 evidence를 새로 계산하면, 다른 evidence가 관찰됨
= (0.99 x 0.524) + (0.1 x 0.476) = 0.566

- 이 evidence를 통해 새롭게 계산된 evidence를 활용하면 91.7%라는 높은 확률이 나옴
= 0.524 x = 0.917
- 베이즈의 장점은 데이터가 새로 들어올 때마다, 사후확률을 업데이트할 수 있고 이럴 때마다 업데이트된 정보를 가지고 모델링을 할 수 있기 때문에 실제로 유효한 테스팅을 할 수 있음
- 만약 이 테스트를 3번 받았을 때는 99.1%까지 정확도가 오르게 됨
5. 조건부 확률 → 인과관계?

- 인과관계는 실제 2개의 사건 A, B가있을 때 A가 B의 원인인가의 문제를 판단할 때 조건부 확률로 많이 하는데, 조건부확률을 가지고 계산은 가능하지만 실제 A가 B의 원인일 때 가능한 것이고, 인과관계 추론 시 조건부 확률을 만능으로 생각하면 안 됨
- 데이터가 아무리 많아져도 해결될 문제는 아니며,
조건부확률로 인과관계를 추론하는 것이 불가능하기 때문
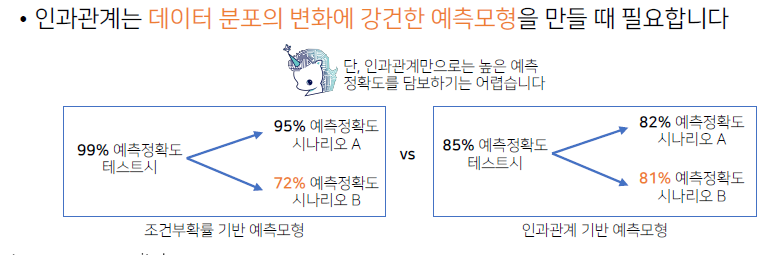
인과관계를 예측모델에서 고려해야하는 이유는 데이터 분포의 변화에강건한 예측모형을 만들 때 필요하기 때문- 2가지 예측 모형의 비교를 보면, 조건부 확률 기반의 예측모형을 보고 할 때 인과관계를 고려하지 않고 하게 되면 테스트 시 실제로 높은 정확도를 갖는 모델을 얻을 수 있음
문제는 이러한 상황이 데이터분포(evidence)가 바뀌게 되는 경우, 데이터가 유입되는 상황이 바뀌거나 새로운 정책의 도입, 새로운 치료법이 도입 됐을 때 등 유입되는 데이터 분포가 변화되는 경우는 매우 많음- 이런 경우,
조건부 확률만가지고 예측모형을 만들었을 때시나리오에 따라 예측확률이 크게 변할 수 있기 때문에, 데이터 분포의 변화에강건한 예측모형을 만들고 싶을 때는인과관계 기반 예측모형을 만드는 것이 필요
- 단지 조건부확률 기반으로만 만들었다면, 어떤 시나리오에서는 정확도가 유지되지만 어떤 시나리오에서는 낮게 나올 수 있음
💡 그러면, 인과관계를 도입했을 때 예측 정확도를 조건부확률 기반 예측모형만큼 가져올 수 있느냐?
- 높은 예측정확도를 담보하기는 어려움
다만,데이터분포의 변화에 강건한 예측모형을 만드는 것이 가능하기 때문에 여러 시나리오가 발생했을 때예측 정확도가 크게 변화하지 않는 상황을 보장하는 것이 가능
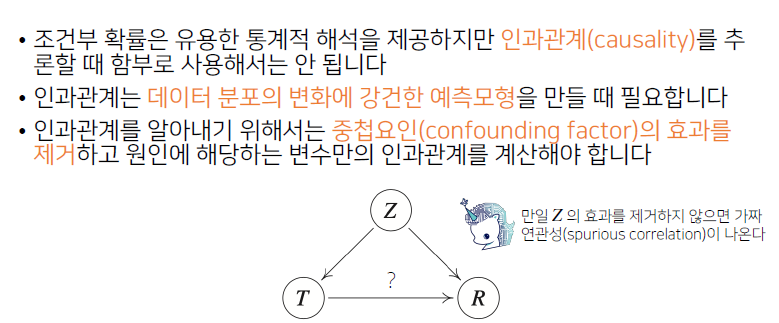
- 인과관계를 실제로 알아내기 위해 조건부 확률을 가지고만 해서는 안 됨
- 2개의 변수가 있을 때 2개의 변수에 동시에 영향을 주는
중첩요인 (Z)의 효과를 제거해야만 T를 원인으로 했을 때 결과 R에 인과관계를 계산할 수 있음
- 즉, 원인과 결과에 해당하는 인과관계
물음표에 해당하는 관계를 계산할 때, Z의 효과가 T와 R에 동시에 영향을 주기 때문에 Z의 중첩효과를 제거하지 않으면가짜 연관성이 계산될 수 있고, 예측 모델에서 데이터 분포에 변화가 생겼을 때 예측 모델의 정확도를 떨어뜨리는 가장 큰 요인이 될 수 있음
- 가령 R을
지능지수라고 가정하고 T를키라고 했을 때, '키에 따른 지능지수의 상관관계'를 분석한다고 했을 때, 일반적 상식으로는 키와 지능지수는 관계가 없을 것 같지만 데이터 분석을 해보면 키가 클수록 지능지수가 높다는 결과의 분석이 가능- 하지만 이는
연령이라는중첩효과를 제거하지 않았기 때문
- 어른은 어린이보다 키가 크기 때문에
나이에 따른 키의 효과를 제거하지 않게 되면, 보통 어린아이가 지능지수를 테스트할 때와 어른이 테스트할 때 당연히 어른이 문제를 풀 확률이 높기 때문에, 연령이 높을수록 지능이 높게 나오는 효과가 있음- 이것이
중첩 요인이 되어 키가 크면 지능지수가 높다라는 결과가 나올 수 있음
- 실제로
연령이라는 중첩요인을 제거하지 않고 키와 지능지수 간의 예측 모형을 분석하게 되면잘못된 가짜 연관성을 관찰하게 될 확률이 높아짐
- 따라서,
중첩요인을 제거하는 방법을 알아야만 인과관계를 통한 정확한 예측모델의 구조를 알 수 있게 되고 이를 통한 예측 모델의 강건한 모형을 만드는 것이 가능
6. 인과관계 추론 예제

- T{a (개복수술), b (주사시술)} 중에서 어떤 치료법이 신장결석이 발생했을 때 완치비율이 더 높은지에 대한 분석하고자 함
- 즉, 치료법에 따른 완치율의 원인과 결과를 분석
물음표: 원인결과 분석을 하고 싶은 것이 데이터 분석의 목적에 해당치료법에 따른 통계치는 우측의 표를 보면 알 수 있는데, 어떤 환자군이 작은 신장결석을 가질 때와 큰 결석을 가지고 있을 때, 치료법 a와 b를 선택한 것에 따른 완치율을 기록한 것이 우측 표
전체적으로봤을 때 마치치료법 b가 더 높은 완치율을 가지고 있는 것 같은데, 각각의환자군에 따라보게되면 small stone일 때도a를 선택했을 때 완치율이 높고 large stone도a를 선택했을 때도 완치율이 높음
💡 전체적으로 봤을 땐 치료법 b가 더 높은데 각각의 환자군으로 봤을 때는 a가 더 높은 것은 왜 이럴까?
역설문제를 해결하기 위해 조건부확률을 가지고a를 조건부로 했을 때 완치율과b를 조건부로 했을 때 완치율을 가지고만계산해서는 안 됨신장결석 크기에 따른 a, b의 조정효과(중첩효과)를제거해야만 실제 정확한 치료법에 따른 완치율을 계산하는 것이 가능
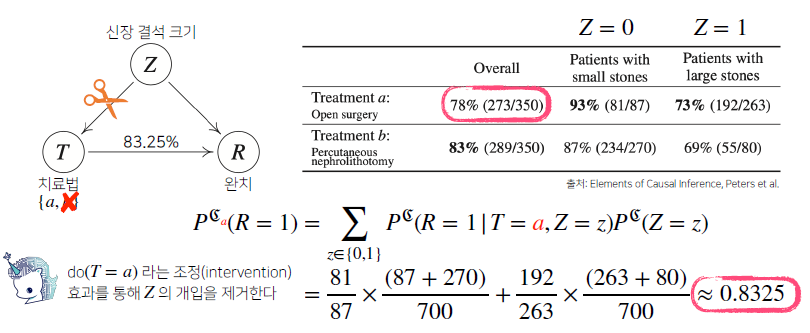
- 중첩효과를 제거하는 방식의 계산은 만약 모든 환자가 small stone이나 large stone
상관없이모든 환자들이 치료법a(개복수술)를 선택했을 때 완치율을 선택한 것과b(주사시술)를 선택했을 때 완치율을 계산하면 됨- 이와 같이
조정효과를 통해 z라는 중첩효과를 제거해z의 개입을 제거하는 방식으로 계산을 해주면, 베이즈 정리를 통해 계산하는 것과는 조금 다른 공식이 필요
do(T=a)라는 조정효과를 통해 Z의 개입을 제거
중첩효과 제거 후 a치료법을 선택했을 때,
(93% x ) + (73% x ) = 0.8325
중첩효과 제거 후 b치료법을 선택했을 때,
(87% x ) + (69% x ) = 0.7789

- 이 때, 본래 조건부로 계산했을 때 78%로 나왔던 완치율은 치료법 a를 선택했을 때 83.25%라는 더 높은 완치율로 계산되고, 만약 크기 상관없이 b를 선택하면 77.89%라는 효과와 같이 잘 나오게 됨
- 즉 치료법 a의 선택 혹은 b 선택에 따른 인과관계 분석을 했을 때, 앞에서 계산한 조건부확률을 계산했을 때와 달리
중첩효과를 제거한 인과관계를 계산한 확률이기 때문에 훨씬 믿을만한 결과가 나오게 됨
- 이렇게
인과관계를 고려해서 중첩효과를 제거한 데이터 효과를 했을 때, 좀 더 안정적인 정책분석 혹은 예측모형의 설계가 가능해짐
- 그래서, 단순 조건부 확률로 데이터 분석을 하는 것은 위험하며, 이렇게 데이터에서 실제로 추론할 수 있는 사실관계들, 데이터가 생성되는 관계들, 도메인 지식을 활용해서
이 변수들끼리의 관계를 실제로 파악해야만 인과관계의 추론이 가능하기 때문에, 실제 데이터분석을 할 때 혹은 강건한 예측모형을 만들 때인과관계를 고려하는 것이 굉장히 중요할 것임

세상을 이롭게하는 AI Engineer