3D reconstruction using deep learning : a survey
3D reconstruction 분야에 관심이 생겨 이 분야에 대해 알아보기 위해 2020년 Communications in Information and Systems 에 개제된 survey 논문을 읽고 정리하려 한다.
(요약 형식으로 정리하여 생략한 부분도 있음을 미리 언급합니다.)
본 서베이 논문은 deep learning 기반의 3D reconstruction 분야의 classical, latest works를 모두 다루며, all surveyed method들을 input modality에 따라 아래 3가지 카테고리로 나눠 설명한다.
1. single RGB image based
2. multiple RGB images based
3. sketch based또한, output 3D shape의 표현과 구체적인 목표도 함께 다룬다. 더하여, current works에서 주로 사용되는 datasets과 evaluation metrics을 소개하고, 마지막으로 future research의 잠재적 방향에 대해 이야기한다.
논문의 개요는 아래와 같다.
- Introduction
- Overview
- Single Image reconstruction
- Multiple image reconstruction
- Sketch reconstruction
- Conclusion
1. Introduction
3D reconstruction이란 주어진 inputs의 3D shape을 표현하는 것이다. 이는 Remote sensing, navigation, 3D animation, medical assisting 등 광범위한 애플리케이션에서 해결해야하는 문제이다.
전통적으로, single image 3D reconstruction의 주류 방법은 조명과 반사율의 특정 가정에 기초하고 있기 때문에, input의 반사율, 빛, texture 에 매우 민감하다.
딥러닝 기술의 발달로 3D reconstruction의 성능과 효율성이 모두 크게 향상되었다. 초기 딥러닝 기반 방법에서는 3D ground-truth를 supervision으로 사용하였다. 하지만, 3D ground-truth는 labor-intensive하고 구하기 어렵습니다. 따라서 3D supervision을 대신하기 위해 3D 정보를 2D 공간에 투영하는 weaker supervision이 제안되었다.
더 나아가, reconstruction 결과의 2d projection과 Input image와의 차이를 최소화하는 self-supervision methods가 제안되었다. 그리고 몇 연구가 GAN(Generative Adversarial Networks)을 기반으로 unsupervised 방법으로 3D shape reconstruction을 가능하게 했다. multi-view 3D construction에 관해서는, 다양한 view로 부터 input image를 align하기 위해 photometric stereo와 SFM(shape from motion) 기술이 사용되곤 했다. 하지만, 이 방법은 free view에서 객체를 효율적이고 정확하게 reconstruction 하기에는 오히려 제한이 있었다.
Neural networks는 처음에는 alignment를 돕기 위해 사용되었지만, 나중에는 input image로부터 직접적으로 full shape를 reconstruct하는데에 사용되었다.
추가로, non-rigid object (비정형 객체) reconstruction을 다루기 위해, SFM, NRSFT(non-rigid shape from template)과 이전 모델들이 frameworks에 사용되었다.
대체로, 3D reconstruction 기술이 긴 시간동안 연구되어 왔음에도 불구하고, 성능과 일반화 가능성이 만족할 정도는 아니다.
3D reconstruction 연구의 분류법에는 몇 crucial 한 variation이 있다 : input modality, shape representation, network architecture.
기본적으로 input은 두 가지로 나뉜다 : RGB image와 sketch.
Depth도 다른 문헌들에서 input modality 중 하나로 여겨지기도 한다. 하지만, depth 기반 방법들은 depth를 추가적인 input, an intermediate of networks로 여기거나 혹은 segmentation 이나 missing part와 같은 다른 tasks에 집중한다. 따라서 본 논문에서는 RGB image와 sketch 기반 방법들만을 다룬다.
RGB image의 실생활에서의 높은 availability 때문에, RGB image input이 커뮤니티에서 깊게 연구 되어왔다. RGB input 기반의 방법들 중에서 몇 방법은 single image를, 다른 몇 방법은 비디오 프레임 형태의 image sequence와 다양한 viewpoints의 image를 network의 입력으로 한다. 그 동안, 초기 sketch-based 방법들은 대개 edge maps이나 표준화된 line-drawings를 사용했고, end-to-end 프레임워크의 발전으로, 비전문가들이 다루기 쉬운 hand-painted sketch들이 최근 연구되고 있다. sketch 입력의 정보 손실을 다루기 위해, 사전 지식과 GAN이 사용된다.
입력 뿐만 아니라, 3D shape의 표현도 reconstruction task에 있어 중요하다. representation은 네트워크 구조 설계와 성능에 영향을 미친다. Volumetric 방법은 3D shape을 3D grid에서 voxels로 표현한다. 2D 이미지의 pixels와 비슷하게, volumetric 네트워크는 2D convolution으로부터 쉽게 확장될 수 있다. 하지만, volumetric 방법은 메모리 소비가 크다.
Points cloud는 메모리를 절약하는 3D shape 표현 방법이다. Point cloud 기반의 방법은 3차원 좌표의 교점으로 shape를 표현한다. Point cloud로 매핑을 구현하고, 점들을 면으로 나누면, point cloud를 mesh로 변형할 수 있다. Mesh 기반 방법들은 topology와 계산 이슈에도 불구하고, 매핑을 통해 입력으로부터 직접적으로 mesh를 일반화한다. 또한, occupancy grids, oc-tree, parameters 와 signed distance field (SDF)도 3D shape를 reconstruct하기 위한 네트워크의 표현으로 선택된다.
네트워크 구조에 관하여, MLP(Multi-Layer Perceptron)은 신경망 기반의 초기 방법으로 흔히 사용된다. CNN(Convolutional Neural Networks)은 2D 정보를 다루는 적합성 때문에 reconstruction 작업에 널리 이용된다. RNN(Recurrent Neural Networks)은 입력의 순차적 특징을 파악하기 위해 특별히 이용되며, GAN(Generative Adversarial Netwokrs)은 누락된 정보를 예측하고, 네트워크의 일반화 능력을 향상시키는 데에 기여한다. 또한, 최근의 연구들은 non-Euclidean 구조 데이터를 처리하는 적합성으로 인해 일부 특정 문제(e.g. face reconstruction)에서 GCN(Graph Convolutional Networks)를 사용한다.
이 paper에서는 딥러닝을 사용하는 3D reconstruction의 종합적인 survey을 발표한다. 네트워크의 input modality에 따라 reconstruction 방법들을 조사하였으며, 각 section을 internal logic 하에 구성하였다.
2. Overview
2.1 Common datasets
당시 논문에 기재된 대로 정리한 것이며, 현재는 업데이트 되었을 수 있습니다. 1. ShapeNet
ShapeNet은 55개 클래스로 구성된 50,000개 이상의 CAD 모델을 포함하는 shape repository이다. semantic 카테고리와 특성의 annotation을 제공한다.
2. Pascal 3D+
https://cvgl.stanford.edu/projects/pascal3d.html
Pascal 3D+는 12개 클래스의 3D 정형 객체를 포함하며, 각 클래스에는 3,000개 이상의 객체가 포함되어 있다. 주로 3D object detection과 pose estimation에 사용된다. 또한, 커뮤니티에서 baseline으로 사용되곤 한다.
3. ObjectNet3D
https://cvgl.stanford.edu/projects/objectnet3d/
ObjectNet3D은 100개 카테고리와 90,127개 이미지로 구성되어 있다. 이미지 내의 각 2D object에 대해 3D pose와 shape annotation이 제공된다. proposal generation, 2D object detection, 3D pose estimation에 주로 사용된다.
4. KITTI
http://www.cvlibs.net/datasets/kitti/
KITTI는 시골 지역과 고속도로에서 두 개의 카메라와 하나의 laser scanner로부터 획득한 raw data를 포함한다. stereo, optical flow, visual odometry, 3D object detection, 3D tracking video에서 real-world 컴퓨터 비전 benchmarks로 사용되고있다.
5. 그 외
BU-3DFE, Bosphorus, MICC, AFLW2000-3D가 human face task에 사용되며, HumanEva와 Human3.6M이 human body task에 사용된다.
2.2 Metrics
1. MSE (Mean Square Error)
2. Voxel IoU
3. Average Euclidean Distance
4. Champer Distance
5. EMD (Earth Mover's Distance)
6. F-score
3. Single image reconstruction
3.1 Voxel representation
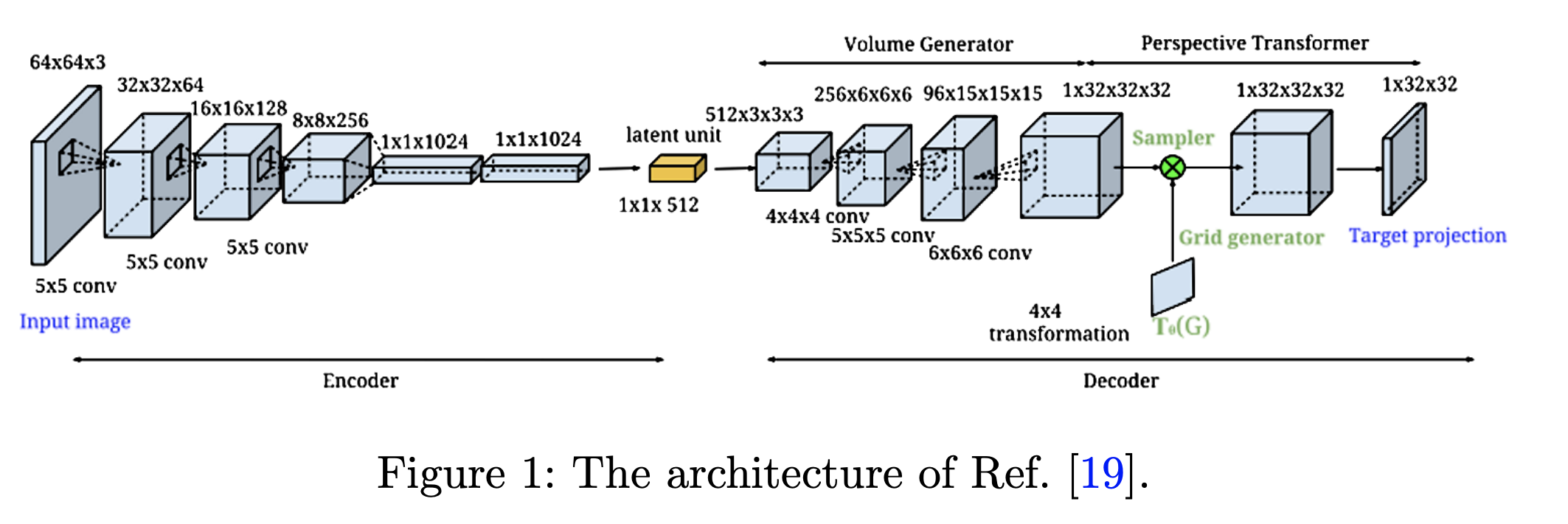
3.2 Point cloud representation
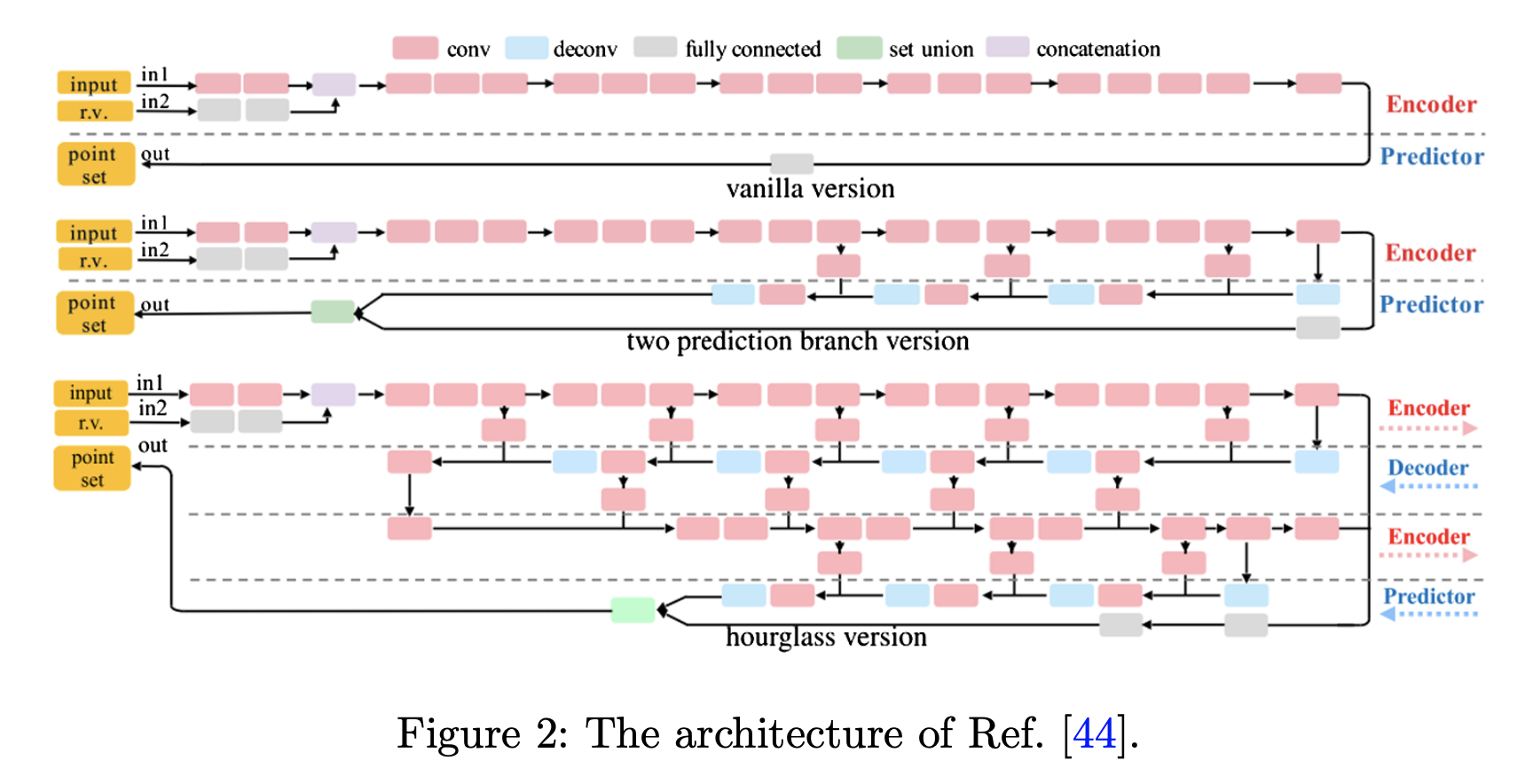
3.3 Mesh representation
3.4 Other representation
4. Multiple image reconstruction
4.1 Rigid reconstruction
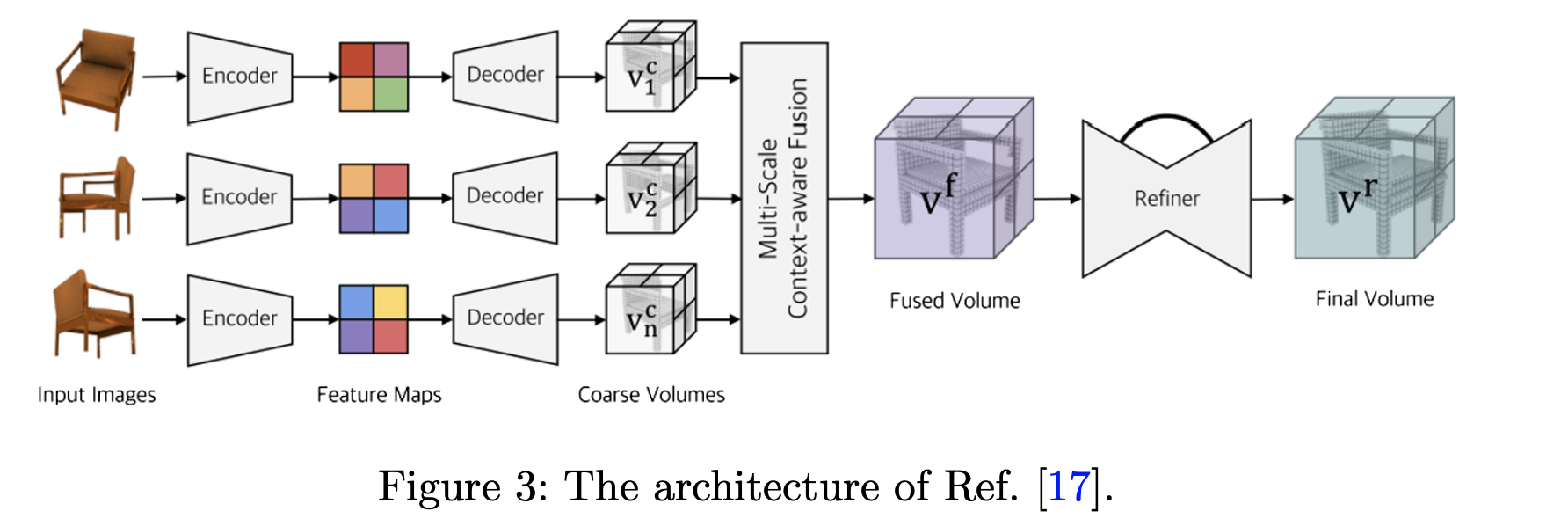
4.2 Non-rigid reconstruction
5. Sketch reconstruction
6. Conclusion
Jin, Yiwei, Diqiong Jiang, and Ming Cai. "3d reconstruction using deep learning: a survey." Communications in Information and Systems 20.4 (2020): 389-413.