
머신러닝·딥러닝 문제해결 전략 책을 읽으면서
Kaggle 경진대회 코드와 문제해결 전략을 정리한 글
7장 범주형 데이터 이진분류 경진대회 - 탐색적 데이터 분석
경진대회 이해
- 본 대회의 목표는 범주형 피처 23개를 활용해 해당 데이터가 타깃값 1에 속할 확률을 예측하는 것
- 본 경진대회는 특이점 세 가지가 있음
- 인위적으로 만든 데이터 제공
- 각 피처와 타깃값의 의미를 알 수 없음
- 활용할 수 있는 배경 지식이 없으므로 순전히 데이터만 보고 접근
- 제공되는 데이터는 모두 범주형
- 값이 두개로만 두성돈 데이터부터 순서형 데이터, 명목형 데이터, 날짜 데이터까지 다양
bin_로 시작하는 피처는 이진 피처,nom_로 시작하는 피처는 명목형 피처,ord_로 시작하는 순서형 피처
- 타깃값도 0과 1 두 개로 구성된 범주형 데이터
- 이 대회를 통해 범주형 데이터 인코딩 방법을 숙달
데이터 둘러보기
import pandas as pd
# 데이터 경로
data_path = '/kaggle/input/cat-in-the-dat/'
train = pd.read_csv(data_path + 'train.csv', index_col='id')
test = pd.read_csv(data_path + 'test.csv', index_col='id')
submission = pd.read_csv(data_path + 'sample_submission.csv', index_col='id')- index_col은 불러올 DataFrame의 인덱스를 지정하는 파라미터
- 열 이름을 전달하면 해당열을 인덱스로 지정하며, 명시하지 않으면 0부터 시작하는 새로운 인덱스 열을 생성
- 이번 대회의 데이터셋에는 타깃값을 예측하는 데 어떠한 정보도 제공하지 않고 단지 각 행을 구분하는 역할만 하는
id열이 있으므로 이를 인덱스로 지정함
train.shape, test.shape((300000, 24), (200000, 23))# 훈련 데이터 확인 - T 메서드를 이용하여 행과 열의 위치를 바꿔 생략된 피처를 표시
train.head().T| id | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| bin_0 | 0 | 0 | 0 | 0 | 0 |
| bin_1 | 0 | 1 | 0 | 1 | 0 |
| bin_2 | 0 | 0 | 0 | 0 | 0 |
| bin_3 | T | T | F | F | F |
| bin_4 | Y | Y | Y | Y | N |
| nom_0 | Green | Green | Blue | Red | Red |
| nom_1 | Triangle | Trapezoid | Trapezoid | Trapezoid | Trapezoid |
| nom_2 | Snake | Hamster | Lion | Snake | Lion |
| nom_3 | Finland | Russia | Russia | Canada | Canada |
| nom_4 | Bassoon | Piano | Theremin | Oboe | Oboe |
| nom_5 | 50f116bcf | b3b4d25d0 | 3263bdce5 | f12246592 | 5b0f5acd5 |
| nom_6 | 3ac1b8814 | fbcb50fc1 | 0922e3cb8 | 50d7ad46a | 1fe17a1fd |
| nom_7 | 68f6ad3e9 | 3b6dd5612 | a6a36f527 | ec69236eb | 04ddac2be |
| nom_8 | c389000ab | 4cd920251 | de9c9f684 | 4ade6ab69 | cb43ab175 |
| nom_9 | 2f4cb3d51 | f83c56c21 | ae6800dd0 | 8270f0d71 | b164b72a7 |
| ord_0 | 2 | 1 | 1 | 1 | 1 |
| ord_1 | Grandmaster | Grandmaster | Expert | Grandmaster | Grandmaster |
| ord_2 | Cold | Hot | Lava Hot | Boiling Hot | Freezing |
| ord_3 | h | a | h | i | a |
| ord_4 | D | A | R | D | R |
| ord_5 | kr | bF | Jc | kW | qP |
| day | 2 | 7 | 7 | 2 | 7 |
| month | 2 | 8 | 2 | 1 | 8 |
| target | 0 | 0 | 0 | 1 | 0 |
# 제출 샘플 데이터 확인
submission.head()| target | |
|---|---|
| id | |
| 300000 | 0.5 |
| 300001 | 0.5 |
| 300002 | 0.5 |
| 300003 | 0.5 |
| 300004 | 0.5 |
- target 열은 0.5로 일괄 입력되어 있음
- 타깃값 0과 1 두 가지 중에서 타깃값이 1일 확률을 예측해 저장
피처 요약표 만들기
- 피처 요약표는 피처별 데이터 타입, 결측값 개수, 고윳값 개수, 실제 입력값 등을 정리한 표
피처 요약표를 만드는 과정
1. 피처별 데이터 타입 DataFrame 생성
2. 인덱스 재설정 후 열 이름 변경
3. 결측값 개수, 고윳값 개수, 1~3행 입력값 추가
피처별 데이터 타입 DataFrame 생성
# DataFrame 객체에서 dtypes를 호출하면 피처별 데이터 타입을 반환
train.dtypes[:5]bin_0 int64
bin_1 int64
bin_2 int64
bin_3 object
bin_4 object
dtype: object# 위의 값을 입력으로 DataFrame을 생성하면 피처별 데이터 타입이 입력된 DataFrame이 만들어짐
summary = pd.DataFrame(train.dtypes, columns=['데이터 타입'])
summary.head()| 데이터 타입 | |
|---|---|
| bin_0 | int64 |
| bin_1 | int64 |
| bin_2 | int64 |
| bin_3 | object |
| bin_4 | object |
인덱스 재설정 후 열 이름 변경
# reset_index()를 호출하면 현재 인덱스를 열로 옮기고 새로운 인덱스를 만듦
summary = summary.reset_index()
summary.head()| index | 데이터 타입 | |
|---|---|---|
| 0 | bin_0 | int64 |
| 1 | bin_1 | int64 |
| 2 | bin_2 | int64 |
| 3 | bin_3 | object |
| 4 | bin_4 | object |
# 피처 이름이 포함된 열 이름이 index이므로 rename() 함수를 활용해 열 이름을 '피처'로 변경
summary = summary.rename(columns={'index': '피처'})
summary.head()| 피처 | 데이터 타입 | |
|---|---|---|
| 0 | bin_0 | int64 |
| 1 | bin_1 | int64 |
| 2 | bin_2 | int64 |
| 3 | bin_3 | object |
| 4 | bin_4 | object |
결측값 개수, 고윳값 개수, 1~3행 입력값 추가
# 피처별 결측값 개수
summary['결측값 개수'] = train.isnull().sum().values
# 피처별 고윳값 개수
summary['고윳값 개수'] = train.nunique().values
# 1~3행에 입력되어 있는 값
summary['첫 번째 값'] = train.loc[0].values
summary['두 번째 값'] = train.loc[1].values
summary['세 번째 값'] = train.loc[2].values
summary.head()| 피처 | 데이터 타입 | 결측값 개수 | 고윳값 개수 | 첫 번째 값 | 두 번째 값 | 세 번째 값 | |
|---|---|---|---|---|---|---|---|
| 0 | bin_0 | int64 | 0 | 2 | 0 | 0 | 0 |
| 1 | bin_1 | int64 | 0 | 2 | 0 | 1 | 0 |
| 2 | bin_2 | int64 | 0 | 2 | 0 | 0 | 0 |
| 3 | bin_3 | object | 0 | 2 | T | T | F |
| 4 | bin_4 | object | 0 | 2 | Y | Y | Y |
반환 타입 Series는 인덱스(bin_0, bin_1 등)와 값(0 등)의 쌍으로 이루어져 있음
Series 객체에서 값만 추출하려면 values를 호출하면 됨
전체 코드
# 스탭 1 : 피처별 데이터 타입 DataFrame 생성
summary = pd.DataFrame(train.dtypes, columns=['데이터 타입'])
# 스탭 2 : 인덱스 재설정 후 열 이름 변경
# 2-1 : 인덱스 재설정
summary = summary.reset_index()
# 2-2 : 열 이름 변경
summary = summary.rename(columns={'index': '피처'})
# 스탭 3 : 결측값 개수, 고윳값 개수, 1~3행 입력값 추가
# 피처별 결측값 개수
summary['결측값 개수'] = train.isnull().sum().values
# 피처별 고윳값 개수
summary['고윳값 개수'] = train.nunique().values
# 1~3행에 입력되어 있는 값
summary['첫 번째 값'] = train.loc[0].values
summary['두 번째 값'] = train.loc[1].values
summary['세 번째 값'] = train.loc[2].values피처 요약표 생성 함수
import pandas as pd
def resumetable(df):
print(f'데이터셋 형상: {df.shape}')
summary = pd.DataFrame(df.dtypes, columns=['데이터 타입'])
summary = summary.reset_index()
summary = summary.rename(columns={'index': '피처'})
summary['결측값 개수'] = df.isnull().sum().values
summary['고윳값 개수'] = df.nunique().values
summary['첫 번째 값'] = df.loc[0].values
summary['두 번째 값'] = df.loc[1].values
summary['세 번째 값'] = df.loc[2].values
return summaryresumetable(train)데이터셋 형상: (300000, 24)| 피처 | 데이터 타입 | 결측값 개수 | 고윳값 개수 | 첫 번째 값 | 두 번째 값 | 세 번째 값 | |
|---|---|---|---|---|---|---|---|
| 0 | bin_0 | int64 | 0 | 2 | 0 | 0 | 0 |
| 1 | bin_1 | int64 | 0 | 2 | 0 | 1 | 0 |
| 2 | bin_2 | int64 | 0 | 2 | 0 | 0 | 0 |
| 3 | bin_3 | object | 0 | 2 | T | T | F |
| 4 | bin_4 | object | 0 | 2 | Y | Y | Y |
| 5 | nom_0 | object | 0 | 3 | Green | Green | Blue |
| 6 | nom_1 | object | 0 | 6 | Triangle | Trapezoid | Trapezoid |
| 7 | nom_2 | object | 0 | 6 | Snake | Hamster | Lion |
| 8 | nom_3 | object | 0 | 6 | Finland | Russia | Russia |
| 9 | nom_4 | object | 0 | 4 | Bassoon | Piano | Theremin |
| 10 | nom_5 | object | 0 | 222 | 50f116bcf | b3b4d25d0 | 3263bdce5 |
| 11 | nom_6 | object | 0 | 522 | 3ac1b8814 | fbcb50fc1 | 0922e3cb8 |
| 12 | nom_7 | object | 0 | 1220 | 68f6ad3e9 | 3b6dd5612 | a6a36f527 |
| 13 | nom_8 | object | 0 | 2215 | c389000ab | 4cd920251 | de9c9f684 |
| 14 | nom_9 | object | 0 | 11981 | 2f4cb3d51 | f83c56c21 | ae6800dd0 |
| 15 | ord_0 | int64 | 0 | 3 | 2 | 1 | 1 |
| 16 | ord_1 | object | 0 | 5 | Grandmaster | Grandmaster | Expert |
| 17 | ord_2 | object | 0 | 6 | Cold | Hot | Lava Hot |
| 18 | ord_3 | object | 0 | 15 | h | a | h |
| 19 | ord_4 | object | 0 | 26 | D | A | R |
| 20 | ord_5 | object | 0 | 192 | kr | bF | Jc |
| 21 | day | int64 | 0 | 7 | 2 | 7 | 7 |
| 22 | month | int64 | 0 | 12 | 2 | 8 | 2 |
| 23 | target | int64 | 0 | 2 | 0 | 0 | 0 |
피처 요약표 해석하기
- 이진(binary) 피처:
bin_0~bin_4
- 이진 피처이므로 고윳값이 모두 2개
- bin_0, bin_1, bin_2는 데이터 타입이 int64고 실젯값이 0 또는 1로 구성되어 있음
- bin_3, bin_4는 object 타입이고, 실젯값은 T 또는 F(bin_3), Y 또는 N(bin4)
- 머신러닝 모델은 숫자만 인식하기 때문에 모델링할 때 T와 Y는 1로, F와 N은 0으로 인코딩
- 이진 피처에 결측값은 없음
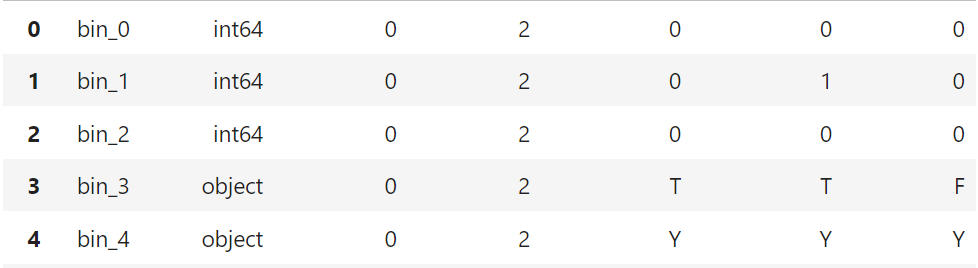
- 명목형(nominal) 피처 :
nom_0~nom_9
- 명목형 피처는 모두 object 타입이고 결측값은 없음
- nom_0부터 nom_4는 고윳값이 6개 이하인데, nom_5부터 nom_9는 고윳값이 많음
- 또한 nom_5부터 nom_9 피처에는 의미를 알 수 없는 값이 입력되어 있음
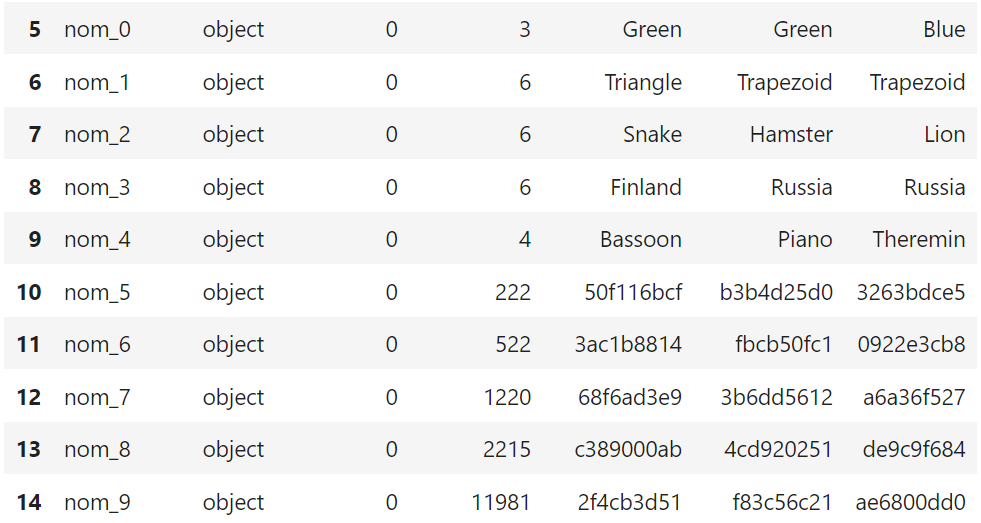
- 순서형(ordinal) 피처 :
ord_0~ord_5
- ord_0 피처만 int63 타입이고 나머지는 object 타입
- 명목형 데이터와 다르게 순서형 데이터는 순서가 중요함 → 순서에 따라 타깃값에 미치는 영향이 다르기 때문
- 그래서 순서에 유의하며 인코딩해야 함
# 순서를 파악하기 위해 순서형 피처의 고윳값 출력 - 고윳값 개수가 적은 ord_0, ord_1, ord_2
for i in range(3):
feature = 'ord_' + str(i)
print(f'{feature} 고윳값: {train[feature].unique()}')ord_0 고윳값: [2 1 3]
ord_1 고윳값: ['Grandmaster' 'Expert' 'Novice' 'Contributor' 'Master']
ord_2 고윳값: ['Cold' 'Hot' 'Lava Hot' 'Boiling Hot' 'Freezing' 'Warm']- ord_0 피처의 고윳값은 모두 숫자이므로 숫자 크기에 순서를 맞춤
- ord_1 피처의 고윳값은 캐글 등급이므로 등급에 따라 Novice, Contributor, Expert, Master, Grandmaster 순으로 맞춤
- ord_2 피처의 고윳값은 춥고 더운 정도를 나타내므로 Freezing, Cold, Warm, Hot, Boiling Hot, Lava Hot 순서로 맞춤
# 순서를 파악하기 위해 순서형 피처의 고윳값 출력 - 고윳값 개수가 많은 ord_3, ord_4, ord_5
for i in range(3, 6):
feature = 'ord_' + str(i)
print(f'{feature} 고윳값: {train[feature].unique()}')ord_3 고윳값: ['h' 'a' 'i' 'j' 'g' 'e' 'd' 'b' 'k' 'f' 'l' 'n' 'o' 'c' 'm']
ord_4 고윳값: ['D' 'A' 'R' 'E' 'P' 'K' 'V' 'Q' 'Z' 'L' 'F' 'T' 'U' 'S' 'Y' 'B' 'H' 'J'
'N' 'G' 'W' 'I' 'O' 'C' 'X' 'M']
ord_5 고윳값: ['kr' 'bF' 'Jc' 'kW' 'qP' 'PZ' 'wy' 'Ed' 'qo' 'CZ' 'qX' 'su' 'dP' 'aP'
'MV' 'oC' 'RL' 'fh' 'gJ' 'Hj' 'TR' 'CL' 'Sc' 'eQ' 'kC' 'qK' 'dh' 'gM'
'Jf' 'fO' 'Eg' 'KZ' 'Vx' 'Fo' 'sV' 'eb' 'YC' 'RG' 'Ye' 'qA' 'lL' 'Qh'
'Bd' 'be' 'hT' 'lF' 'nX' 'kK' 'av' 'uS' 'Jt' 'PA' 'Er' 'Qb' 'od' 'ut'
'Dx' 'Xi' 'on' 'Dc' 'sD' 'rZ' 'Uu' 'sn' 'yc' 'Gb' 'Kq' 'dQ' 'hp' 'kL'
'je' 'CU' 'Fd' 'PQ' 'Bn' 'ex' 'hh' 'ac' 'rp' 'dE' 'oG' 'oK' 'cp' 'mm'
'vK' 'ek' 'dO' 'XI' 'CM' 'Vf' 'aO' 'qv' 'jp' 'Zq' 'Qo' 'DN' 'TZ' 'ke'
'cG' 'tP' 'ud' 'tv' 'aM' 'xy' 'lx' 'To' 'uy' 'ZS' 'vy' 'ZR' 'AP' 'GJ'
'Wv' 'ri' 'qw' 'Xh' 'FI' 'nh' 'KR' 'dB' 'BE' 'Bb' 'mc' 'MC' 'tM' 'NV'
'ih' 'IK' 'Ob' 'RP' 'dN' 'us' 'dZ' 'yN' 'Nf' 'QM' 'jV' 'sY' 'wu' 'SB'
'UO' 'Mx' 'JX' 'Ry' 'Uk' 'uJ' 'LE' 'ps' 'kE' 'MO' 'kw' 'yY' 'zU' 'bJ'
'Kf' 'ck' 'mb' 'Os' 'Ps' 'Ml' 'Ai' 'Wc' 'GD' 'll' 'aF' 'iT' 'cA' 'WE'
'Gx' 'Nk' 'OR' 'Rm' 'BA' 'eG' 'cW' 'jS' 'DH' 'hL' 'Mf' 'Yb' 'Aj' 'oH'
'Zc' 'qJ' 'eg' 'xP' 'vq' 'Id' 'pa' 'ux' 'kU' 'Cl']ord_3, ord_4, ord_5 피처는 알파벳순으로 정렬되어 있으므로 추후 알파벳순으로 인코딩
- 그 외 피처 : day, month, target
- day, month, target 피처 모두 int64 타입이고 결측값은 없음

print('day 고윳값:', train['day'].unique())
print('month 고윳값:', train['month'].unique())
print('target 고윳값:', train['target'].unique())day 고윳값: [2 7 5 4 3 1 6]
month 고윳값: [ 2 8 1 4 10 3 7 9 12 11 5 6]
target 고윳값: [0 1]- day 피처의 고윳값이 7개로 요일을 나타낸다고 볼 수 있음
- month 피처의 고윳값은 1부터 12로 월을 나타냄
- target 피처는 0 또는 1로 구성되어 있음
데이터 시각화
import seaborn as sns
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline타깃값 분포
- 타깃값 분포를 알면 데이터가 얼마나 불균형한지 파악하기 쉬움
- 그래야 부족한 타깃값에 더 집중해 모델링을 수행할 수 있음
- 이를 위해 분포도 중 하나인 카운트플롯(countplot)으로 타깃값 0과 1의 개수를 파악
- 수치형 데이터의 분포를 파악할 땐 주로 distplot()을 사용하고 범주형 데이터의 분포를 파악할 땐 countplot()을 사용
mpl.rc('font', size=15) # 폰트 크기 설정
plt.figure(figsize=(7, 6)) # figure 크기 설정
# 타깃값 분포 카운트플롯
ax = sns.countplot(x='target', data=train)
ax.set_title('Target Distribution')Text(0.5, 1.0, 'Target Distribution')
각 값의 비율을 그래프 상단에 표시하기
# ax.patches : ax축을 구성하는 그래프 도형 객체 모두를 담은 리스트
print(ax.patches)[<matplotlib.patches.Rectangle object at 0x7fc0449e7a90>, <matplotlib.patches.Rectangle object at 0x7fc069fbdfd0>]앞의 카운트플롯을 그린 ax축의 patches는 Rectangle 객체 두 개를 포함하는 리스트 (막대 도형 두 개가 그려졌기 때문)
# 타깃값 비율을 표시할 위치 찾기
rectangle = ax.patches[0] # 첫 번째 Rectangle 객체
print('사각형 높이:', rectangle.get_height())
print('사각형 너비:', rectangle.get_width())
print('사각형 왼쪽 테두리의 x축 위치:', rectangle.get_x())사각형 높이: 208236
사각형 너비: 0.8
사각형 왼쪽 테두리의 x축 위치: -0.4# 텍스트 입력 위치
print('텍스트 위치의 x좌표:', rectangle.get_x() + rectangle.get_width() / 2.0)
print('텍스트 위치의 y좌표:', rectangle.get_height() + len(train) * 0.001)텍스트 위치의 x좌표: 0.0
텍스트 위치의 y좌표: 208536.0# 비율을 표시해주는 코드를 함수로 구현
def write_percent(ax, total_size):
'''도형 객체를 순회하며 막대 상단에 타깃값 비율 표시'''
for patch in ax.patches:
height = patch.get_height() # 도형 높이(데이터 개수)
width = patch.get_width() # 도형 너비
left_coord = patch.get_x() # 도형 왼쪽 테두리의 x축 위치
percent = height/total_size*100 # 타깃값 비율
# (x, y) 좌표에 텍스트 입력
ax.text(x=left_coord + width/2.0, # x축 위치
y=height + total_size*0.001, # y축 위치
s=f'{percent:1.1f}%', # 입력 텍스트
ha='center') # 가운데 정렬
plt.figure(figsize=(7, 6))
ax = sns.countplot(x='target', data=train)
write_percent(ax, len(train)) # 비율 표시
ax.set_title('Target Distribution')Text(0.5, 1.0, 'Target Distribution')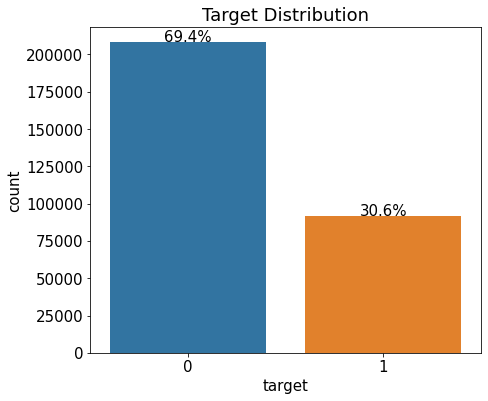
이진 피처 분포
- 이진 피처의 분포를 타깃값별로 따로 그리기
- 범주형 피처의 타깃값 분포를 고윳값별로 구분해 그려보면 특정 고윳값이 특정 타깃값에 치우치는지 확인할 수 있음
import matplotlib.gridspec as gridspec # 여러 그래프를 격자 형태로 배치
# 3행 2열 틀(Figure) 준비
mpl.rc('font', size=12)
grid = gridspec.GridSpec(3, 2) # 그래프(서브플롯)를 3행 2열로 배치
plt.figure(figsize=(10, 16)) # 전체 Figrue 크기 설정
plt.subplots_adjust(wspace=0.4, hspace=0.3) # 서브플롯 간 좌우/상하 여백 설정
# 서브플롯 그리기
bin_features = ['bin_0', 'bin_1', 'bin_2', 'bin_3', 'bin_4'] # 피처 목록
for idx, feature in enumerate(bin_features):
ax = plt.subplot(grid[idx]) # 격자(grid)에서 이번 서브플롯을 그릴 위치를 ax축으로 지정
# ax축에 타깃값 분포 카운트플롯 그리기
sns.countplot(x=feature, # 피처
data=train, # 전체 데이터셋
hue='target', # 세부적으로 나눠 그릴 기준 피처
palette='pastel', # 그래프 색상 설정
ax=ax) # 그래프를 그릴 축
ax.set_title(f'{feature} Distribution by Target') # 그래프 제목 설정
write_percent(ax, len(train)) # 비율 표시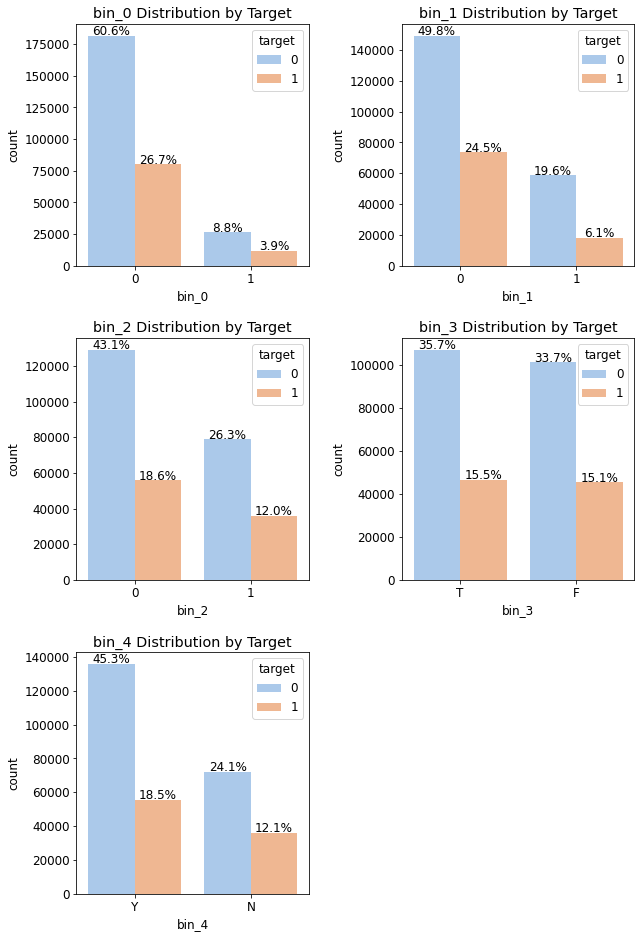
고윳값별로 나눠봐도 타깃값 0, 1의 분포가 대체로 7:3 수준
즉, 이진 피처들은 특정 타깃값에 치우치지 않았음을 확인할 수 있음
명목형 피처 분포
- 명목형 피처 분포와 명목형 피처별 타깃값 1의 비율 확인
- nom_5부터 nom_9 피처까지는 고윳값 개수가 많고 의미를 알 수 없는 문자열이 입력되어 있으니
- 여기서는 nom_0부터 nom_4 피처까지만 시각화
스탭 1 : 교차분석표 생성 함수 만들기
- 교차표(cross-tabulation) 혹은 교차분석표는 범주형 데이터 2개를 비교 분석하는 데 사용되는 표
- 각 범주형 데이터의 빈도나 통계량을 행과 열로 결합해놓은 표
- 여기서 교차분석표를 만드는 이유는 명목형 피처별 타깃값 1 비율을 구하기 위해서임
# 판다스의 crosstab() 함수로 교차분석표 만들기
pd.crosstab(train['nom_0'], train['target'])| target | 0 | 1 |
|---|---|---|
| nom_0 | ||
| Blue | 72914 | 23252 |
| Green | 85682 | 41659 |
| Red | 49640 | 26853 |
# 정규화 후 비율을 백분율로 표현 - normalize 파라미터에 'index'를 전달하면 인덱스를 기준으로 정규화함
crosstab = pd.crosstab(train['nom_0'], train['target'], normalize='index') * 100
crosstab| target | 0 | 1 |
|---|---|---|
| nom_0 | ||
| Blue | 75.820976 | 24.179024 |
| Green | 67.285478 | 32.714522 |
| Red | 64.894827 | 35.105173 |
# 인덱스 재설정
crosstab = crosstab.reset_index()
crosstab| target | nom_0 | 0 | 1 |
|---|---|---|---|
| 0 | Blue | 75.820976 | 24.179024 |
| 1 | Green | 67.285478 | 32.714522 |
| 2 | Red | 64.894827 | 35.105173 |
# 교차분석표 생성 함수 만들기
def get_crosstab(df, feature):
crosstab = pd.crosstab(df[feature], df['target'], normalize='index') * 100
crosstab = crosstab.reset_index()
return crosstabcrosstab = get_crosstab(train,'nom_0')
crosstab| target | nom_0 | 0 | 1 |
|---|---|---|---|
| 0 | Blue | 75.820976 | 24.179024 |
| 1 | Green | 67.285478 | 32.714522 |
| 2 | Red | 64.894827 | 35.105173 |
# nom_0 피처의 고윳값별 타깃값 1 비율
crosstab[1]0 24.179024
1 32.714522
2 35.105173
Name: 1, dtype: float64스텝 2 : 포인트플롯 생성 함수 만들기
- 스텝 1에서 구한 교차분석표를 사용하여 타깃값 1의 비율을 나타내는 포인트플롯을 그리는 함수 만들기
- 함수 이름은
plot_pointplot()이며 다음의 세 파라미터를 받음ax : 포인트 플롯을 그릴 축
feature : 포인트플롯으로 그릴 피처
crosstab : 교차분석표 plot_pointplot()은 이미 카운트플롯이 그려진 축에 포인트플롯을 중복으로 그려줌
def plot_pointplot(ax, feature, crosstab):
ax2 = ax.twinx() # x축은 공유하고 y축은 공유하지 않는 새로운 축 생성
# 새로운 축에 포인트플롯 그리기
ax2 = sns.pointplot(x=feature, y=1, data=crosstab,
order=crosstab[feature].values, # 포인트플롯 순서
color='black', # 포인트플롯 색상
legend=False) # 범례 미표시
ax2.set_ylim(crosstab[1].min()-5, crosstab[1].max()*1.1) # y축 범위 설정
ax2.set_ylabel('Target 1 Ratio(%)')- 축 하나에 서로 다른 그래프를 그리려면 x축을 공유해야 함
- ax.twinx()로 x축은 공유하지만 y축은 공유하지 않는 새로운 축 ax2를 만듦
ax는 카운트플롯을 그리기 위한 축이고,ax2는 포인트플롯을 그리기 위한 축
스텝 3 : 피처 분포도 및 피처별 타깃값 1의 비율 포인트플롯 생성 함수 만들기
get_crosstab()과plot_pointplot()함수를 활용해 최종적인 그래프를 그리는 함수 만들기
def plot_cat_dist_with_true_ratio(df, features, num_rows, num_cols,
size=(15, 20)):
plt.figure(figsize=size) # 전체 Figure 크기 설정
grid = gridspec.GridSpec(num_rows, num_cols) # 서브플롯 배치
plt.subplots_adjust(wspace=0.45, hspace=0.3) # 서브플롯 좌우/상하 여백 설정
for idx, feature in enumerate(features):
ax = plt.subplot(grid[idx])
crosstab = get_crosstab(df, feature) # 교차분석표 생성
# ax축에 타깃값 분포 카운트플롯 그리기
sns.countplot(x=feature, data=df,
order=crosstab[feature].values,
color='skyblue',
ax=ax)
write_percent(ax, len(df)) # 비율 표시
plot_pointplot(ax, feature, crosstab) # 포인트플롯 그리기
ax.set_title(f'{feature} Distribution') # 그래프 제목 설정plot_cat_dist_with_true_ratio()함수는 인수로 받는 features 피처마다 타깃값별로 분포도를 그림- num_rows, num_cols는 각각 서브플롯 행과 열 개수를 의미하고 size는 전체 Figure 크기를 의미
- 이번에도 서브플롯들을 격자 형태로 배치하기 위해 GridSpec을 사용하였고
- for문으로 features를 순회하며 서브플롯을 하나씩 그림
- 각각의 서브플롯에 대해 해당 피처와 타깃값의 교차분석표를 만들고
- 카운트플롯을 그리고
- 카운트플롯에 비율을 표시
- 마지막으로 카운트플롯과 같은 축에 포인트플롯을 덧그린 뒤
- 제목 추가
nom_features = ['nom_0', 'nom_1', 'nom_2', 'nom_3', 'nom_4'] # 명목형 피처
plot_cat_dist_with_true_ratio(train, nom_features, num_rows=3, num_cols=2)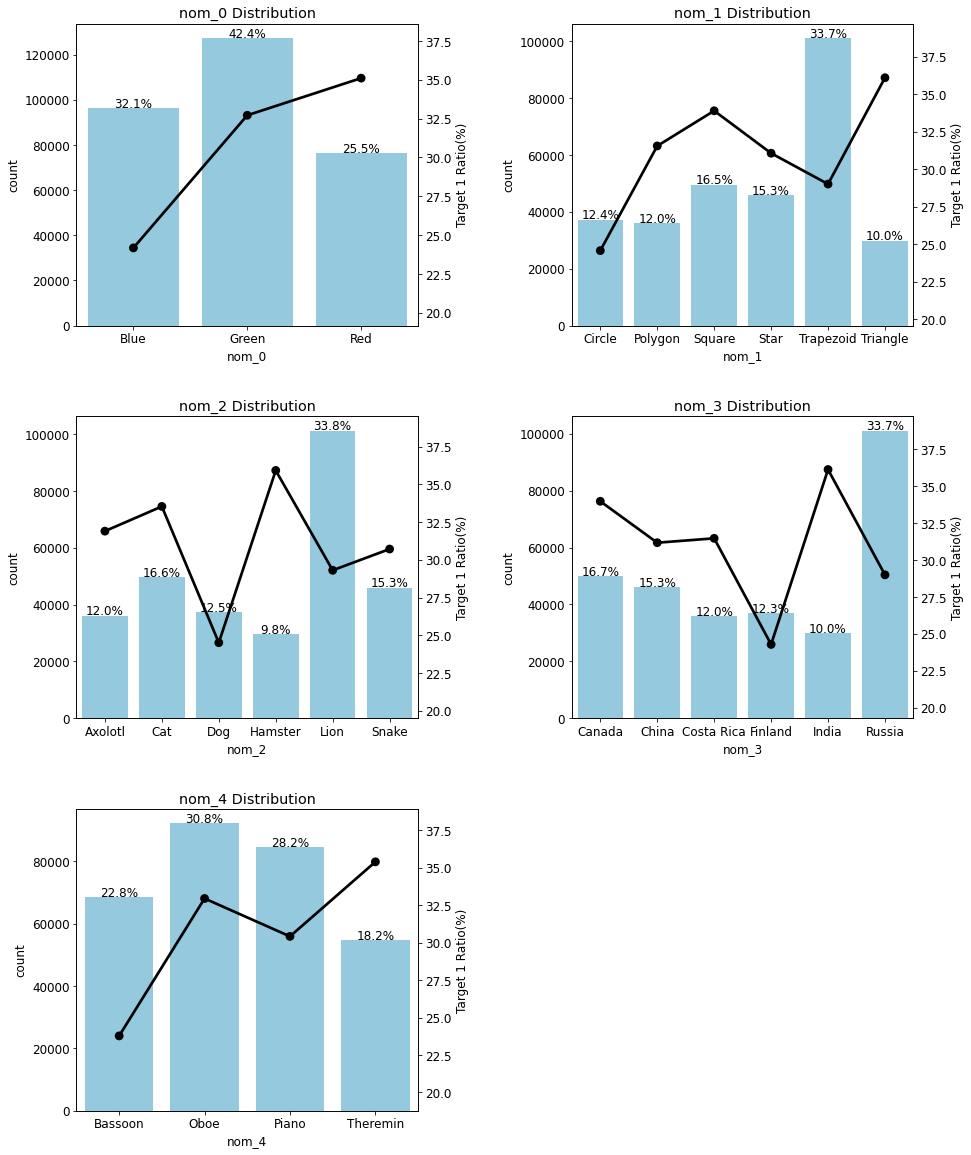
카운트플롯은 피처별 고윳값의 비율이며포인트플롯(꺾은 선 그래프)은 해당 고윳값 중 타깃값이 1인 비율- nom_0부터 nom_4 피처는 고윳값별로 타깃값 1 비율이 서로 다름
- 이는 '타깃값에 대한 예측 능력이 있음'을 뜻함
- 따라서 nom_0부터 nom_4 피처 모두 모델링에 사용하도록 함
- 또한 명목형 피처는 순서를 무시해도 되고 고윳값 개수도 적으니 추후 원-핫 인코딩함
- 한편 nom_5부터 nom_9 피처는 고윳값 개수가 너무 많기도 하고, 의미 없는 문자로 이루어져 있어 시각화하기 어려움
- 데이터를 살펴보지 않아 모델링에 필요한 피처인지 파악하기 어렵지만 우선 필요한 피처라고 가정하고 모델링에 사용
- 이 피처들도 원-핫 인코딩할 예정
- 고윳값 개수가 많지만 피처들의 의미를 몰라 그룹화하기도 어렵고, 전체 데이터 양이 별로 많지 않기 때문
순서형 피처 분포
plot_cat_dist_with_true_ratio()함수를 사용해서 순서형 피처 분포도 확인- 순서형 피처는 총 6개이며, ord_0부터 ord_3까지는 고윳값 개수가 15개 이하인 반면 ord_4와 ord_5는 고윳값이 훨씬 많음
- 따라서 ord_0부터 ord_3까지는 2행 2열로 그래프를 그리고 ord_4와 ord_5는 2행 1열로 그래프를 따로 그림
ord_0부터 ord_3 피처의 분포
ord_features = ['ord_0', 'ord_1', 'ord_2', 'ord_3'] # 순서형 피처
plot_cat_dist_with_true_ratio(train, ord_features,
num_rows=2, num_cols=2, size=(15, 12))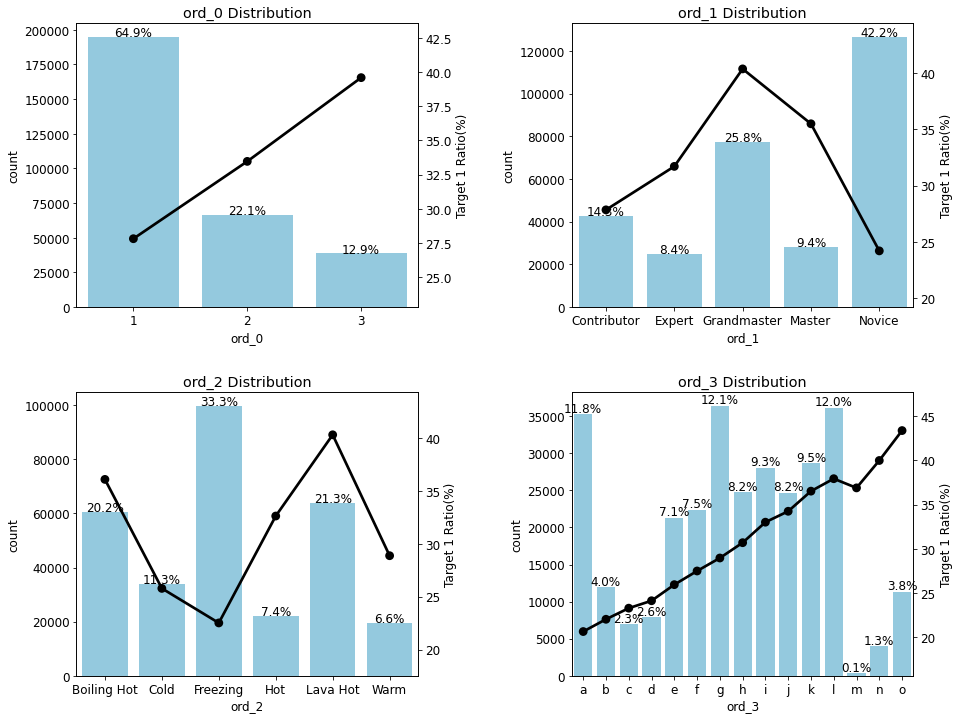
- ord_1 과 ord_2는 피처 값들의 순서가 정렬되지 않음
- ord_1 피처는 'Novice', 'Contributor', 'Expert', 'Master', 'Grandmaster' 순으로 정렬
- ord_2 피처는 'Freezing', 'Cold', 'Warm', 'Hot', 'Boiling Hot', 'Lava Hot' 순으로 정렬
CategoricalDtype()을 이용하면 피처에 순서를 지정할 수 있음
- categories : 범주형 데이터 타입으로 인코딩할 값 목록
- ordered : True로 설정하면 categories에 전달할 값의 순서가 유지됨
from pandas.api.types import CategoricalDtype
ord_1_value = ['Novice', 'Contributor', 'Expert', 'Master', 'Grandmaster']
ord_2_value = ['Freezing', 'Cold', 'Warm', 'Hot', 'Boiling Hot', 'Lava Hot']
# 순서를 지정한 범주형 데이터 타입
ord_1_dtype = CategoricalDtype(categories=ord_1_value, ordered=True)
ord_2_dtype = CategoricalDtype(categories=ord_2_value, ordered=True)
# 데이터 타입 변경
train['ord_1'] = train['ord_1'].astype(ord_1_dtype)
train['ord_2'] = train['ord_2'].astype(ord_2_dtype)plot_cat_dist_with_true_ratio(train, ord_features,
num_rows=2, num_cols=2, size=(15, 12))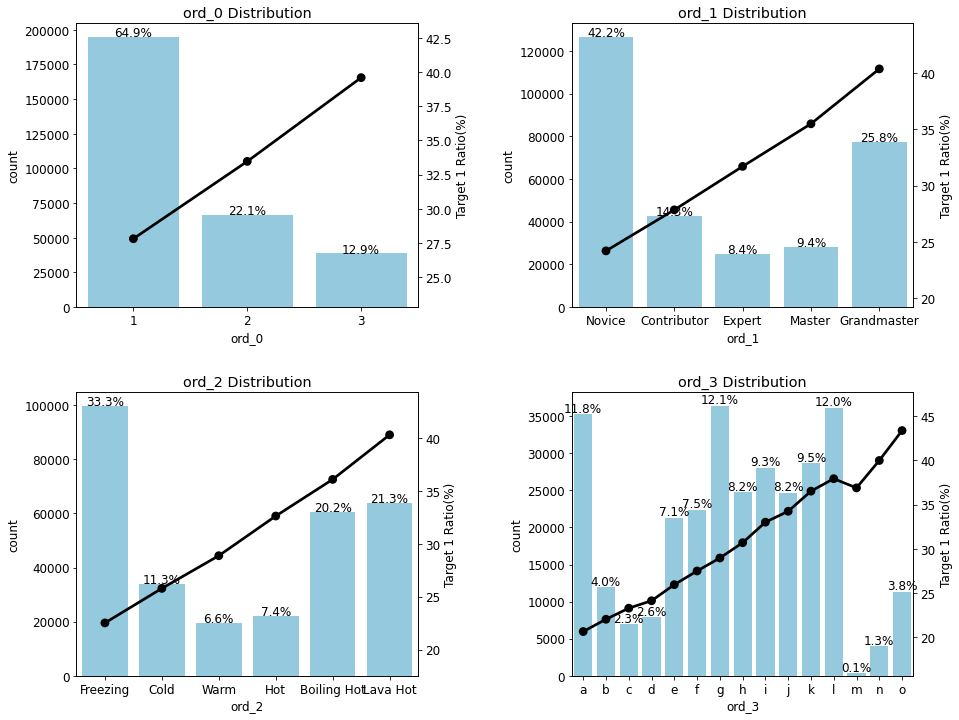
- ord_0는 순자 크기 순으로 ord_1과 ord_2는 지정된 순서대로, ord_3는 알파벳 순으로 정렬됨
- 이 결과로부터 고윳값 순서에 따라 타깃값 1 비율도 비례해서 커진다는 것을 확인할 수 있음
ord_4와 ord_5의 분포
plot_cat_dist_with_true_ratio(train, ['ord_4', 'ord_5'],
num_rows=2, num_cols=1, size=(15, 12))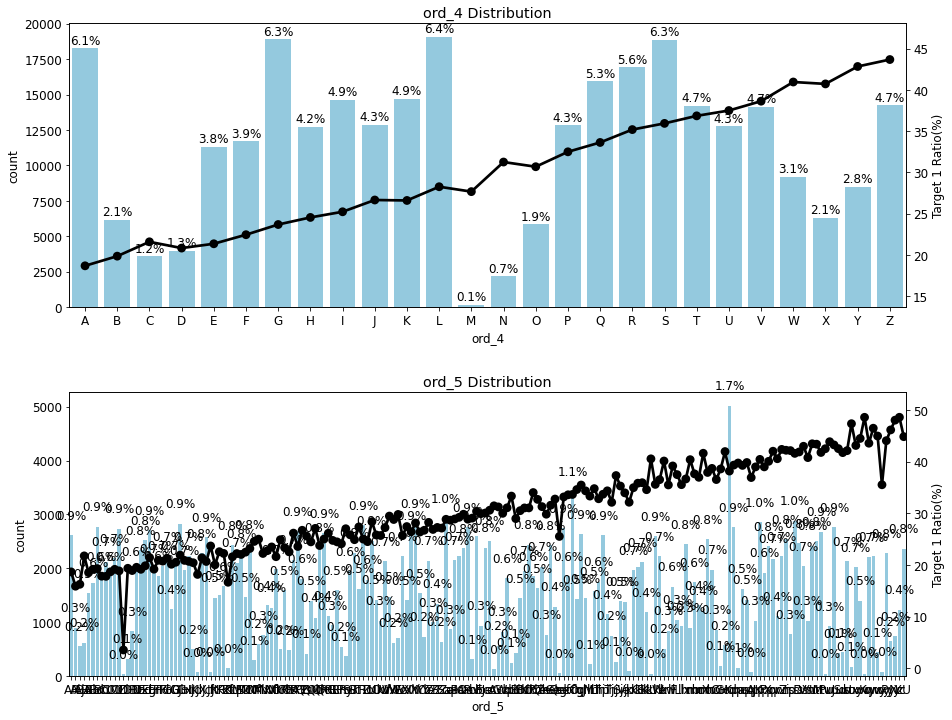
- ord_5는 고윳값 개수가 많다 보니 x축 라벨이 겹쳐졌지만 타깃값 1 비율의 전체적인 양상을 보는 데는 지장 없음
- ord_4와 ord_5 모두 고윳값 순서에 따라 타깃값 1 비율이 증가함
이상으로 순서형 피처 모두 고윳값 순서에 따라 타깃값이 1인 비율이 증가한다는 사실을 알 수 있음
모든 그래프에서 순서와 비율 사이에 상관관계가 있으므로 순서형 피처 모두 모델링 시 사용
날짜 피처 분포
date_features = ['day', 'month']
plot_cat_dist_with_true_ratio(train, date_features,
num_rows=2, num_cols=1, size=(10, 10))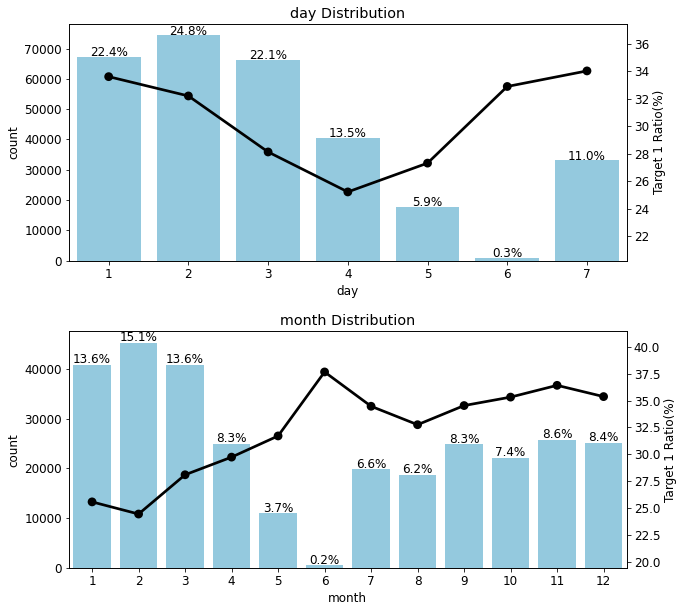
- day 피처는 1에서 4로 갈수록 타깃값 1 비율이 줄어들고, 다시 4에서 7로 갈수록 비율이 늘어남
- month 피처는 day 피처와 다소 반대되는 양상을 보임
머신러닝 모델은 숫자 값을 가치의 크고 작음으로 해석함. 가령 1월은 3월보다 2월과 더 가까운(비슷한) 데이터라고 여김. 하지만 12월과 다음해 1월, 그리고 1월과 2월의 차이는 둘 다 한 달 차이지만 머신러닝 모델은 차이가 같다고 보지 않음(12와 1의 차이는 11이나 되기 때문). 이럴 때 삼각함수(sin, cos)를 사용해 인코딩하면 시작과 끝이 매끄럽게 연결되어 문제가 해결됨. 이렇게 매년, 매월, 매주, 매일 반복되는 데이터를 순환형 데이터(cyclical data)라고 부르며 계절, 월, 요일, 시간 등이 이에 속함.
- 본 경진대회에서는 요일, 월 피처에 원-핫 인코딩을 적용하는 게 오히려 성능이 더 좋았음
- 데이터가 그리 크지 않아서 삼각함수 인코딩이 제대로 효과를 발휘하지 못했을 수도 있음
- 따라서 명목형 피처를 인코딩할 때와 마찬가지로 요일과 월 피처에도 원-핫 인코딩을 적용
분석 정리 및 모델링 전략
분석 정리
- 결측값은 없음
- 모든 피처가 중요하여 제거할 피처를 찾지 못함
- 이진 피처 인코딩 : 값이 숫자가 아닌 이진 피처는 0과 1로 인코딩
- 명목형 피처 인코딩 : 전체 데이터가 크지 않으므로 모두 원-핫 인코딩
- 순서형 피처 인코딩 : 고윳값들의 순서에 맞게 인코딩 (이미 숫자로 되어 있다며 인코딩 필요 없음)
- 날짜 피처 인코딩 : 값의 크고 작음으로 해석되지 못하도록 원-핫 인코딩
모델링 전략
이번 장의 목표는 데이터 특성에 따른 맞춤형 인코딩 방법 익히기이므로 머신러닝 모델은 기본적인 로지스틱 회귀 모델을 계속 사용하면서 피처 엔지니어링에 집중
- 베이스라인 모델: 로지스틱 회귀 모델
- 피처 엔지니어링 : 모든 피처를 원-핫 인코딩
- 성능 개선 : 추가 피처 엔지니어링과 하이퍼파라미터 최적화
- 피처 엔지니어링 : 피처 맞춤 인코딩과 피처 스케일링
- 하이퍼파라미터 최적화 : 그리드서치
- 추가 팁 : 검증 데이터를 훈련에 이용
