머신러닝·딥러닝 문제해결 전략 책을 읽으면서
Kaggle 경진대회 코드와 문제해결 전략을 정리한 글
7장 범주형 데이터 이진분류 경진대회 - 베이스라인 모델
베이스라인 모델
- 베이스라인 모델이란 뼈대가 되는 가장 기본적인 모델을 의미
- 베이스라인 모델에서 출발해 성능을 점차 향상시키는 방향으로 모델링
- 이번 장에서는 모든 피처를 원-핫 인코딩한 뒤, 로지스틱 회귀 모델로 베이스라인 만들기
베이스라인 모델 전체 프로세스
1. 데이터 불러오기
2. (기본적인) 피처 엔지니어링 → 모든 피처 원-핫 인코딩
3. 평가지표 계산 함수 작성 → ROC AUC 사용 (사이킷런 제공)
4. 모델 훈련 → 로지스틱 회귀 (사이킷런 제공)
5. 성능 검증
6. 제출
# 훈련, 테스트, 제출 샘플 파일 불러오기
import pandas as pd
data_path = '/kaggle/input/cat-in-the-dat/'
train = pd.read_csv(data_path + 'train.csv', index_col='id')
test = pd.read_csv(data_path + 'test.csv', index_col='id')
submission = pd.read_csv(data_path + 'sample_submission.csv', index_col='id')피처 엔지니어링
데이터 합치기
- 머신러닝 모델은 문자 데이터를 인식하지 못하기 때문에 문자를 숫자로 바꿔줘야 함
- 이처럼 데이터의 표현 형태를 바꾸는 작업을
인코딩이라고 함 - 훈련 데이터와 테스트 데이터에 동일한 인코딩을 적용하기 위해 편의상 두 데이터셋을 합친 다음 타깃값 제거
- 피처와 타깃값은 따로 분리해서 모델링해야 하기 때문
all_data = pd.concat([train, test]) # 훈련 데이터와 테스트 데이터 합치기
all_data = all_data.drop('target', axis=1) # 타깃값 제거
all_data| bin_0 | bin_1 | bin_2 | bin_3 | bin_4 | nom_0 | ... | nom_9 | ord_0 | ord_1 | ord_2 | ord_3 | ord_4 | ord_5 | day | month | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | ||||||||||||||||
| 0 | 0 | 0 | 0 | T | Y | Green | ... | 2f4cb3d51 | 2 | Grandmaster | Cold | h | D | kr | 2 | 2 |
| 1 | 0 | 1 | 0 | T | Y | Green | ... | f83c56c21 | 1 | Grandmaster | Hot | a | A | bF | 7 | 8 |
| 2 | 0 | 0 | 0 | F | Y | Blue | ... | ae6800dd0 | 1 | Expert | Lava Hot | h | R | Jc | 7 | 2 |
| 3 | 0 | 1 | 0 | F | Y | Red | ... | 8270f0d71 | 1 | Grandmaster | Boiling Hot | i | D | kW | 2 | 1 |
| 4 | 0 | 0 | 0 | F | N | Red | ... | b164b72a7 | 1 | Grandmaster | Freezing | a | R | qP | 7 | 8 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 499995 | 0 | 0 | 0 | F | N | Green | ... | acc31291f | 1 | Novice | Lava Hot | j | A | Gb | 1 | 3 |
| 499996 | 1 | 0 | 0 | F | Y | Green | ... | eae3446d0 | 1 | Contributor | Lava Hot | f | S | Ed | 2 | 2 |
| 499997 | 0 | 1 | 1 | T | Y | Green | ... | 33dd3cf4b | 1 | Novice | Boiling Hot | g | V | TR | 3 | 1 |
| 499998 | 1 | 0 | 0 | T | Y | Blue | ... | d4cf587dd | 2 | Grandmaster | Boiling Hot | g | X | Ye | 2 | 1 |
| 499999 | 0 | 0 | 0 | T | Y | Green | ... | 2d610f52c | 2 | Novice | Freezing | l | J | ex | 2 | 2 |
500000 rows × 23 columns
훈련 데이터와 테스트 데이터를 합하면 행 개수가 50만 개이며, 타깃값이 빠져서 피처는 23개임
원-핫 인코딩
- 모델링에 사용하기 위해 모든 피처를 원-핫 인코딩
all_data에는 문자로 구성된 피처와 숫자로 구성된 피처가 섞여 있음. 문자로 구성된 피처는 반드시 인코딩해야 하지만 숫자로 구성된 피처는 모델링하는 데 지장을 주지 않아서 반드시 인코딩할 필요는 없음. 단, 모델 성능을 더 좋게 하려고 숫자로 구성된 범주형 피처도 인코딩하는 경우가 있음. 여기서는 편의상 모든 피처를 인코딩하고 모델 성능을 개선할 때 피처 특성에 따라 다른 인코딩을 적용할 것
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder() # 원-핫 인코더 생성
all_data_encoded = encoder.fit_transform(all_data) # 원-핫 인코딩 적용데이터 나누기
- 공통으로 적용할 인코딩이 끝났으니 훈련 데이터와 테스트 데이터를 다시 나누기
- 행 번호를 기준으로 다시 나눌 수 있음
num_train = len(train) # 훈련 데이터 개수
# 훈련 데이터와 테스트 데이터 나누기
X_train = all_data_encoded[:num_train] # 0 ~ num_train-1 행
X_test = all_data_encoded[num_train:] # num_train ~ 마지막 행
y = train['target'] # 타깃값 저장훈련 데이터에서 일부를 검증 데이터로 나누어 훈련 데이터는 모델 훈련에 사용하고, 검증 데이터는 모델 성능 검증에 사용하도록 함
이렇게 하면 검증 데이터를 이용해 제출 전에 모델 성능을 평가해볼 수 있음
from sklearn.model_selection import train_test_split
# 훈련 데이터, 검증 데이터 분리
X_train, X_valid, y_train, y_valid = train_test_split(X_train, y,
test_size=0.1,
stratify=y,
random_state=10)- train_test_split()은 전체 데이터를 훈련 데이터와 검증(혹은 테스트) 데이터로 나누는 함수
- 첫 번째 인수로는 피처(X_train)를, 두 번째 인수로는 타깃값(y)을 전달
test_size는 검증 데이터 크기를 지정하는 파라미터- 값이 정수면 검증 데이터 개수를, 실수면 비율을 의미
stratify는 지정한 값을 각 그룹에 '공정하게' 배분하는 파라미터- 여기서는 타깃값 y를 전달했으므로 타깃값이 훈련 데이터와 검증 데이터에 같은 비율로 포함되게끔 나눠줌
- stratify 파라미터를 지정하지 않으면 훈련 데이터와 검증 데이터에 타깃값이 불균형하게 분포될 수 있음
random_state는 시드값을 고정하여 다음에 실행해도 같은 결과가 나오게 해줌
모델 훈련
- 모델을 생성한 뒤, 준비한 데이터를 사용해서 훈련
- 선형 회귀 방식을 응용해 분류를 수행하는 로지스틱 회귀 모델 사용
from sklearn.linear_model import LogisticRegression
logistic_model = LogisticRegression(max_iter=1000, random_state=42) # 모델 생성
logistic_model.fit(X_train, y_train) # 모델 훈련LogisticRegression(max_iter=1000, random_state=42)베이스라인 모델이므로 모델의 파라미터는 간단하게 설정
- max_iter : 모델의 회귀 계수를 업데이트하는 반복 횟수
- random_state : 실행할 때마다 똑같은 결과가 나오도록 값을 지정
모델 성능 검증
- 사이킷런은 타깃값 예측 메서드를 두 가지 제공
predict(): 타깃값 자체(0이냐 1이냐)를 예측predict_proba(): 타깃값의 확률(0일 확률과 1일 확률)을 예측
# predict_proba()로 검증 데이터의 타깃값이 0 또는 1일 확률을 예측
logistic_model.predict_proba(X_valid)array([[0.23262216, 0.76737784],
[0.91407764, 0.08592236],
[0.83025174, 0.16974826],
...,
[0.24875927, 0.75124073],
[0.49441807, 0.50558193],
[0.95661255, 0.04338745]])# predict()로 타깃값을 0 또는 1로 예측
logistic_model.predict(X_valid)array([1, 0, 0, ..., 1, 1, 0])본 대회에서는 타깃값이 1일 '확률'을 예측해야 하므로 predict_proba() 메서드로 예측한 결과의 두 번째 열을 타깃 예측값으로 사용
# 검증 데이터를 활용한 타깃 예측
y_valid_preds = logistic_model.predict_proba(X_valid)[:, 1]타깃 예측값인 y_valid_preds와 실제 타깃값인 y_valid를 이용해 ROC AUC 구하기
from sklearn.metrics import roc_auc_score # ROC AUC 점수 계산 함수
# 검증 데이터 ROC AUC
roc_auc = roc_auc_score(y_valid, y_valid_preds)
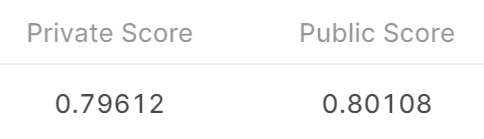
print(f'검증 데이터 ROC AUC : {roc_auc:.4f}')검증 데이터 ROC AUC : 0.7965예측 및 결과 제출
- 테스트 데이터를 활용해 타깃값이 1일 확률을 예측하고 결과를 제출
# 타깃값이 1일 확률 예측
y_preds = logistic_model.predict_proba(X_test)[:, 1]# 제출 파일 생성
submission['target'] = y_preds
submission.to_csv('submission.csv')