💡 Cost Function
-
Cost/Loss function: data set과 가설함수(h(x))의 오차를 계산하는 함수, 궁극적인 목표는 Global Minimum을 찾는 것 -
Mean-square Cost Function: 전체 Cost의 평균을 구하는 식(이 기준으로 param을 최적화 시켜야함)!
최적화를 시키는 방법 Gradient 사용
💡 Gradient Descent
-
gradient: 편미분한 값을 vector로 표현

-
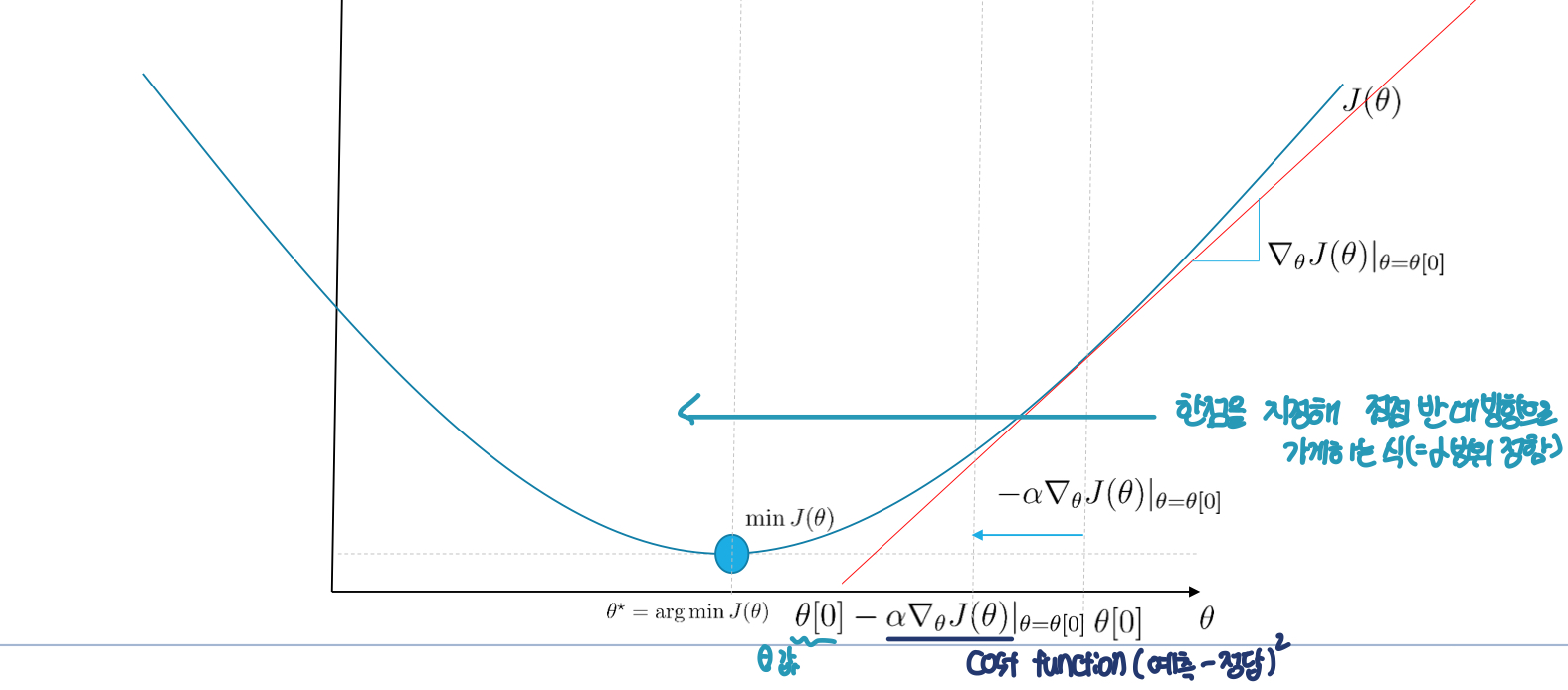
Gradient Descent Algorithm 방식:
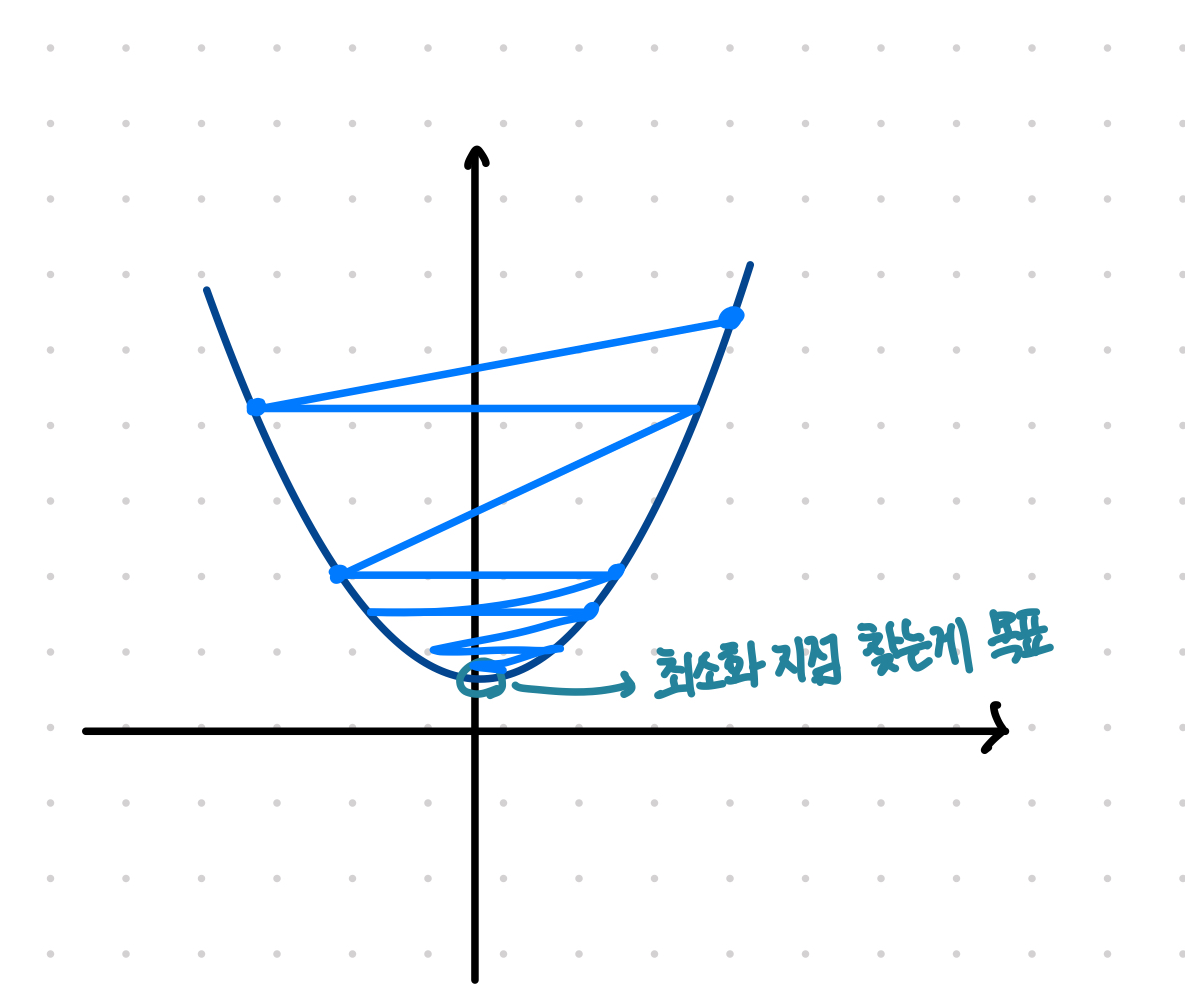
1차 미분계수를 이용해 함수의 최솟값을 찾아가는 iterative한 방법- -> 그러나 일반적으로 이차함수의 형태를 띄지 않음: 최소점을 찾는 문제가 복잡해짐
- -> 그러나 일반적으로 이차함수의 형태를 띄지 않음: 최소점을 찾는 문제가 복잡해짐
-
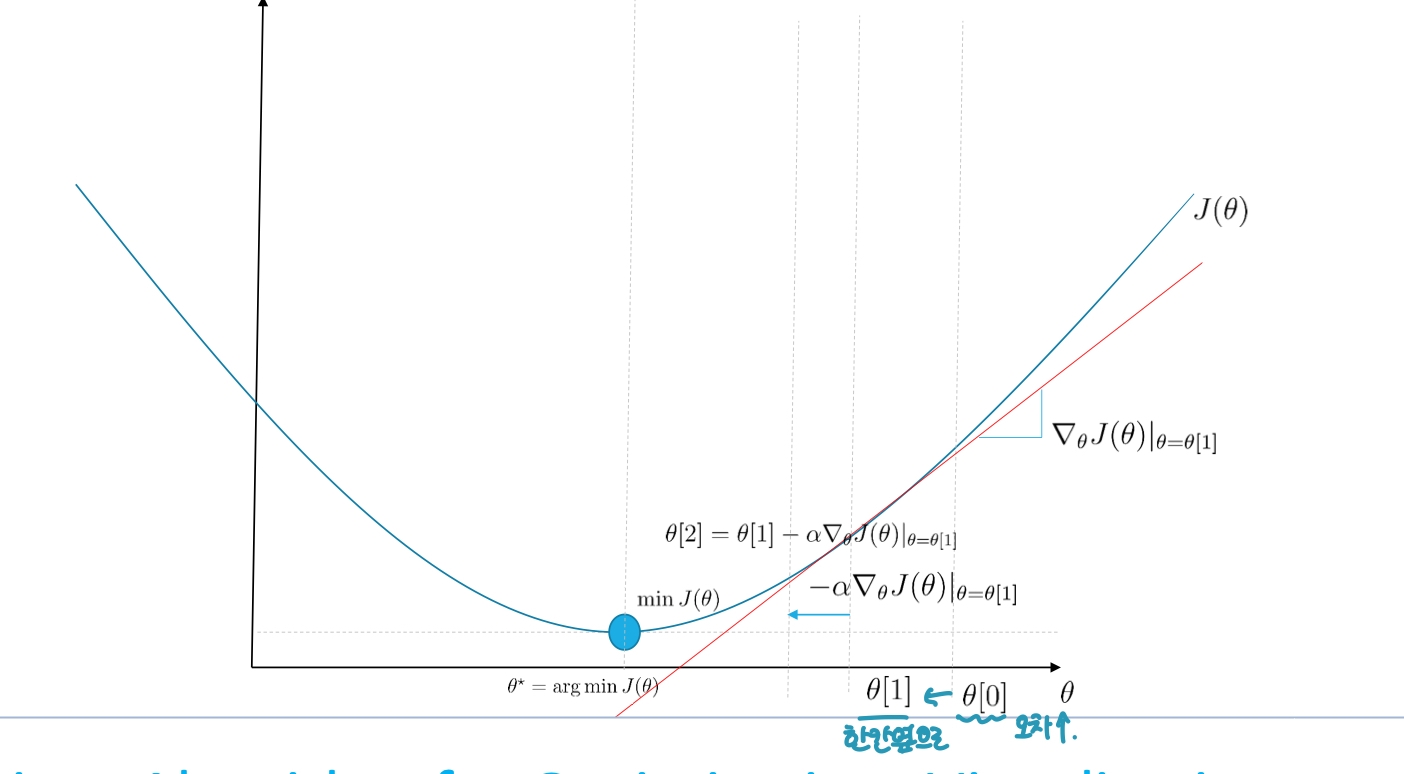
를 효과적으로 구하기 위해 Loss Function의 값을 최소화 하기 위해 기울기 반대 방향으로 일정 크기만큼 이동하는 것을 반복, 의 변화식은 아래와 같다
- (는 learning rate)
- 종류
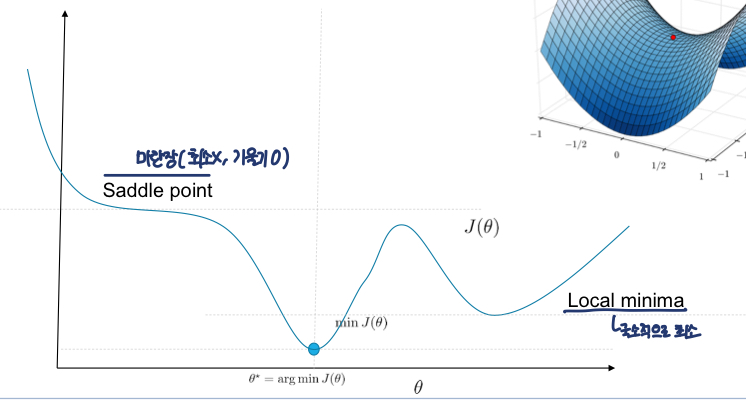
Grdient Descent:- 줄이고 싶은 전체 sample의 변곡점을 찾는 알고리즘
- 단점: 연산량⇡, Saddle Point, Local minimal 발생위험
Stochastic Gradient Descent:- 전체 sample 대신 일부 데이터모음을 사용해 최적 파라미터를 찾음
- 정확도 떨어질 수 있지만, 속도가 빨라 여러번 반복하면 된다.
- 전체 sample 대신 일부 데이터모음을 사용해 최적 파라미터를 찾음
- ★
Mini-batch SGD:- sample B를 길이가 m으로 인덱싱한 후 Gradient Descent값(=오차)를 모두 합함
- B개의 sample의 오차만 구하기 때문에 속도⇡
SGD vs GDGD Time steps: dataset의 batch에서 Epoch이 한번씩 발생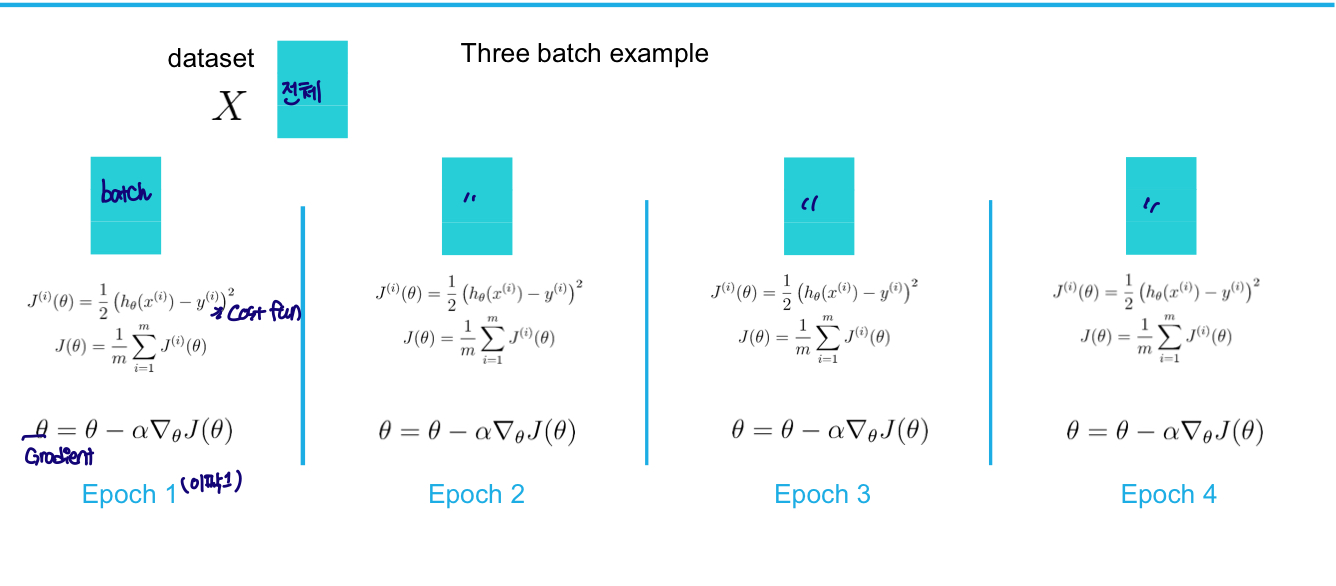
-SGD Time steps: dataset의 batch와 epoch의 횟수가 맞지않다.
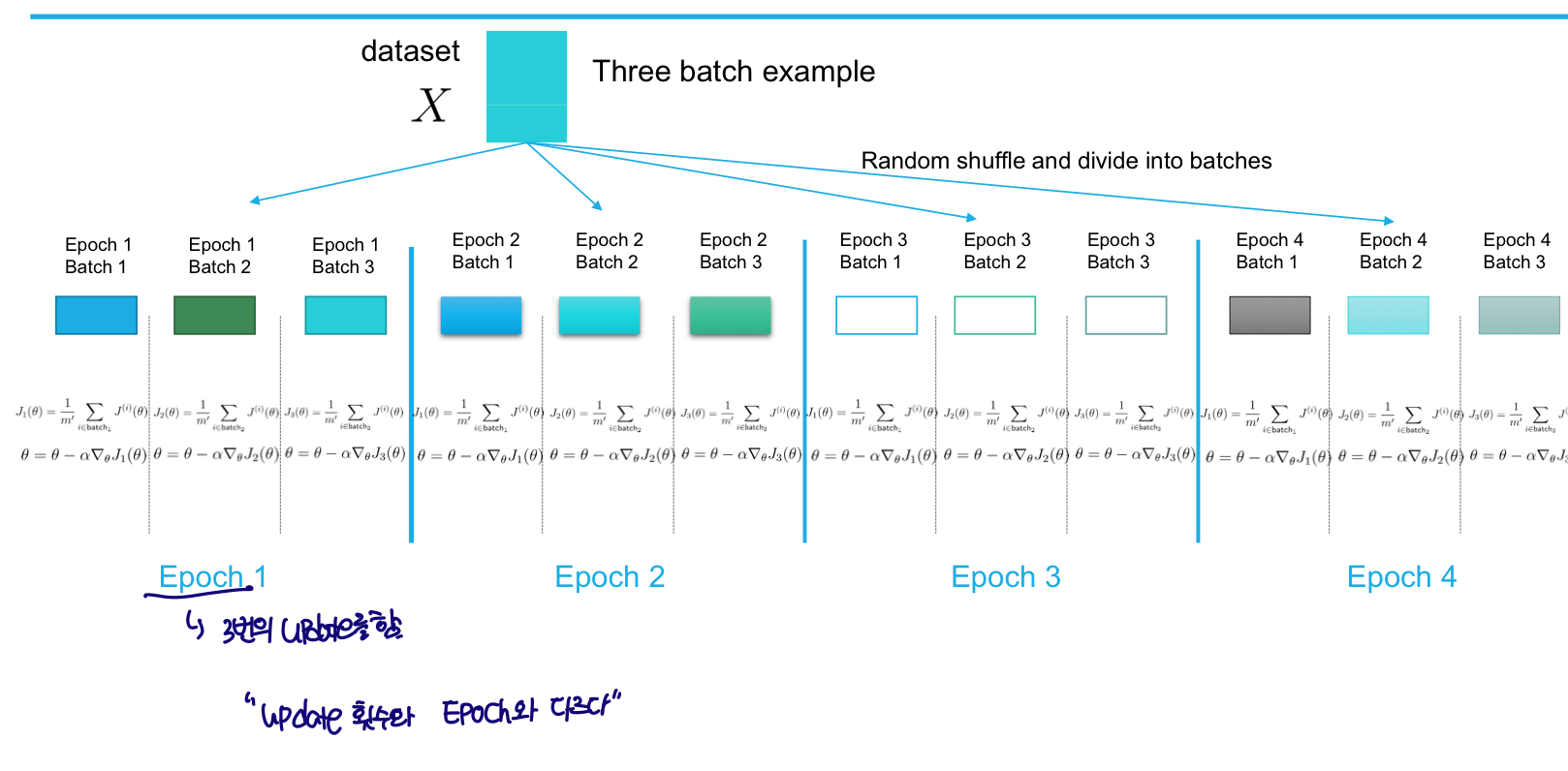
- "Cost/Loss function을 구한 후 Gradient한 것과 Mean-square Cost Function을 구한 후 Gradient한 값은 같지않다
""
- (는 learning rate)
참고: https://mangkyu.tistory.com/62
https://angeloyeo.github.io/2020/08/16/gradient_descent.html
https://deeppago.tistory.com/m/67
