손실함수(Loss function)
- 예측값과 실제값의 차이 = loss
- 모델 성능의 '나쁨'을 나타내는 지표(0에 가까울수록 정확도가 높음)
- 실제 y값에 비해 가정한 모델 의 예측값이 얼마나 잘 예측했는지 판단하는 함수이다.
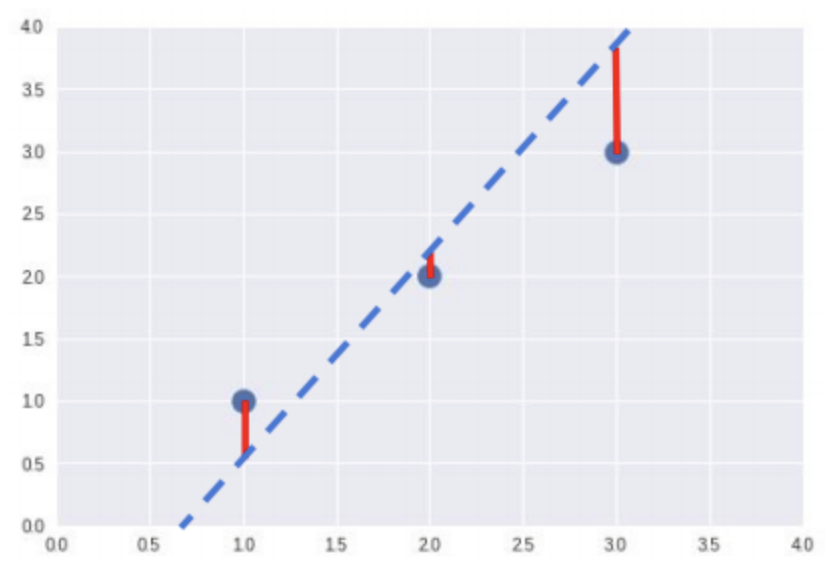
- 빨간 선의 총합이 최소화되었을 때 최적의 결과값 도출 가능하다.
-회귀 타입 사용: 평균 제곱 오차(Mean Squared Error, MSE)
- (가장 많이 쓰임) 예측값과 실제값 사이의 평균을 제곱하여 평균낸 값
-분류(classification)에 사용되는 손실함수: Cross-Entropy
Cross-Entropy: 실제 분포 q를 알지 못하는 상태에서 모델링을 통해 구한 분포인 p를 통해 q를 예측하는 것
- 실제값과 예측값의 차이를 줄이는 방식
- 는 softmax(x)를 한 값
- 은 one-hot encoding으로 생김
비용함수(Cost Function)
- 비용함수: 최적화 알고리즘(GD)에서 최대값 최소값 찾는 함수 = 최적화 알고리즘의 목적함수
- 목적함수로 손실함수의 평균 사용()이유?
- 전체 데이터(Full-batch) 또는 부분 데이터(batch) 를 한번에 학습(1epoch)에 사용
- 목적함수로 손실함수의 평균 사용()이유?
참고: https://brunch.co.kr/@mnc/9,
https://velog.io/@cha-suyeon/손실함수loss-function-Cross-Entropy-Loss,
https://velog.io/@regista/비용함수Cost-Function-손실함수Loss-function-목적함수Objective-Function-Ai-tech
