🚨 Application Layers
쿠키와 세션을 사용하는 이유가 뭘까?
HTTP 프로토콜의 무상태한 특성을 보완하고, 사용자의 상태정보를 유지하기 위함입니다.
HTTP 프로토콜의 특징
1. Conncetionless protocol
클라이언트가 서버에 요청을 했을 때, 그 요청에 맞는 응답을 보낸 후 연결을 끊는다. TCP가 구현 된 이후로 논란이 있었지만, 네트워크의 관점에서 keep-aliv는 옵션으로 두고, 현재의 개념을 유지하는 것을 선택했다.
- Stateless protocol
커넥션을 끊는 순간 클라이언트와 서버의 통시 끝나며 상태정보를 유지하지 않는 특성이 있습니다.
쿠키와 세션에 대해서 설명해주세요.
위의 Stateless 함에 의해서 접속할 때 마다 모든 정보를 불러와야 하는 점을 보완하고자 쿠키와 세션이라는 개념이 나오게 되었습니다.
Cookie는 사용자를 식별하고 세션을 유지하는 방식 중에서 현재까지 가장 널리 사용하는 방식입니다. 그 사이트가 사용하고 있는 서버에서 사용자의 컴퓨터에 저장하는 작은 기록 정보 파일이라고 할 수 있습니다. 간단한 예시로는 크롬이라는 브라우저를 통해서 로그인을 할 때 아이디와 비밀번호를 저장하시겠습니까??라는 팝업창에 예를 누르면 해당 아이디 비밀번호에 대한 쿠키가 생성되는 경우입니다.
쿠키는 크게 Session Cookie , Persistence Cookie 로 나뉩니다.
- Session Cookie : 사용자가 사이트를 탐색할 때, 관련한 설정과 선호 사항들을 저장하는 임시 쿠키입니다. 하지만, 이러한 정보들은 브라우저를 닫으면 삭제됩니다. Session Cookie는 Session Id를 저장하기 위해서 사용이 됩니다.
- Persistence Cookie : 디스크에 저장되어, 브라우저를 닫거나 컴퓨터를 재시작하더라고 삭제되지 않 고 더 길게 유지될 수 있습니다. 지속 쿠키는 사용자가 주기적으로 방문하는 사이트에 대한 설정 정보나 로그인 이름을 유지하는데 사용합니다.
쿠키의 특징
1. 이름, 값, 만료일, 경로 정보로 구성되어 있습니다.
2. 클라이언트에 총 300개까지 저장할 수 있습니다.
3. 하나의 도메인 당 20개의 쿠키를 가질 수 있습니다.
4. 하나의 쿠키는 4KB까지 저장 가능합니다.
5. 서버에 모든 클라이언트에 대한 요청이 쿠키로 저장되는 것이 아닌 동일한 Origin 혹은 CORS를 허용하는 Origin에만 쿠키를 보냅니다. 즉, 유튜브 서버에서 받은 쿠키는 유튜브 이용을 할때만 받을 수 있는 것을 의미합니다.
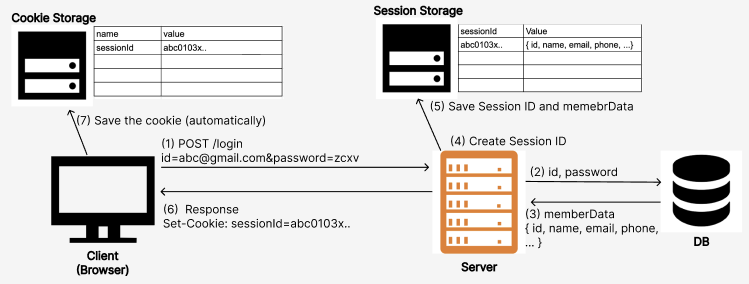
동작 순서
- 클라이언트가 서버에 페이지 요청
- 웹 서버가 쿠키를 생성
- 응답에 생성한 쿠키에 정보를 담아 클라이언트에게 서버가 전달
- 크키를 가지고 있다가(로컬에 경로에 저장) 다시 요청이 필요할 경우 쿠키를 같이 전송한다.
- 클라이언트의 PC에 쿠키가 있는 경우,HTML과 같이 쿠키를 전송합니다.
Session은 서버 측에서 관리되는 상태 정보입니다. 세션은 서버 메모리나 데이터베이스에 저장되며, 사용자의 브라우저에는 세션을 식별할 수 있는 세션 ID만 저장됩니다. 이 세션 ID는 일반적으로 세션 쿠키를 통해 브라우저에 저장되는데, 이는 세션을 식별하기 위한 키로서만 기능합니다. 서버는 이 ID를(이러한 ID는 Session Cookie가 저장) 사용하여 해당 사용자의 세션 데이터에 접근하여 각 개인 사용자의 요청에 맞는 서비스를 제공합니다. 세션은 사용자가 로그아웃하거나 일정 시간 동안 활동이 없을 경우 만료되며, 이 경우 서버에서 해당 세션 데이터가 삭제됩니다. 세션은 우리가 여러개의 창을 띄워 놓고 다른 작업을 하고 있다가 다시 돌아갔음에도 사이트가 우리가 마지막으로 했던 작업이 유지되는 것이 세션의 예시라고 할 수 있습니다.
세션의 특징
1. 웹 서버에 HTML의 상태를 유지하기 위한 정보를 저장합니다.
2. 세션 쿠키를 가진다.(웹 서버에 저장 되는 쿠키를 말합니다.)
3. 커넥션이 끊어 졌거나 세션이 만료가 되었을 경우에만 삭제가 되기 때문에 쿠키보다 비교적 보안성이 좋습니다.
4. 저장 데이터에 제한이 없습니다.
5 각 클라이언트에 고유 Session Id 를 부여해, 각 요청에 맞는 서비스를 제공합니다.
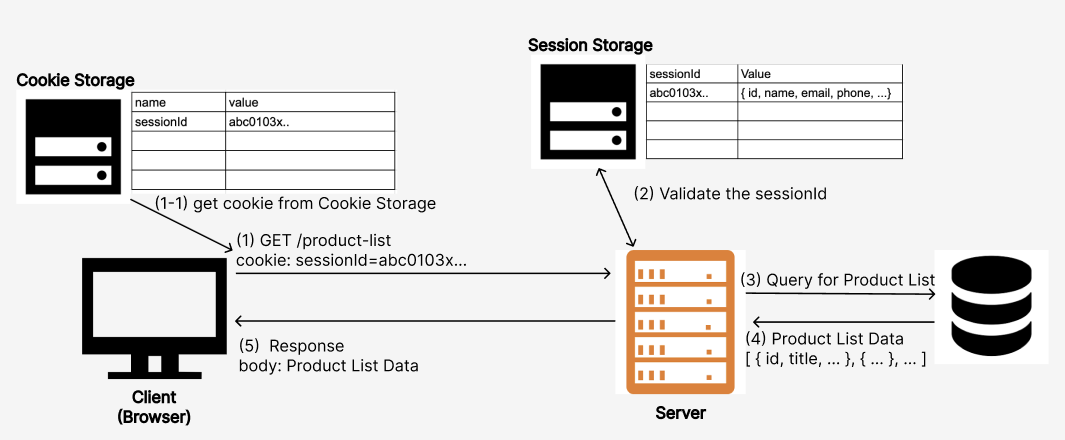
동작 순서
1. 클라이언트의 페이지 요청
2. 클라이언트의 요청 헤더 필드인 쿠키를 확인하여, Session id를 보냈는지 확인
3. Session id가 없다면, 서버는 생성하여 다시 보낸다.
4. 클라이언트는 해당 정보를 쿠키에 저장
5. 클라이언트가 서버에 요청 시 Session Cookie를 통해 Session id를 같이 전달
6. 위의 과정 처럼 id 확인 후 요청에 맞는 응답 진행
웹 보안과 인증 🔐
일단 토큰이란 뭔지에 대해서 말씀드리고 JWT Token에 대해서 말씀드리겠습니다.
- Token : 시스템이 사용자를 식별하기 위한 임시적인 정보입니다. 로그인 후에 서버는 토큰을 생성하여 클라이언트에게 전달하게 되고, 클라이언트는 이 토큰을 사용하여 서버에 요청을 보낼 때 자신을 인증합니다. 그렇기 때문에 쿠키와 비슷하게 서버의 부담을 줄여주는 인증 수단 이라고 할 수 있습니다.
이러한 Token-Based Authentication(토큰 기반 디지털 인증)은 다음과 같은 이유로 널리 사용되고 있습니다.
1. 상태 유지 불필요 : 서버는 토큰이 유호한지만 확인하면 되므로, 전통적인 세션 기반 인증보다 메모리 사용량이 줄어듭니다.
2. 확장성 : 로드 밸런서나 여러 서버 사이에서도 쉽게 인증 정보를 공유할 수 있습니다.
3. 보안 : 토큰은 일정 시간이 지나면 만료되기 때문에, 도난당할 위험이 상대적으로 낮습니다.
JWT 토큰에 대해서 설명해주세요.
JWT(JSON Wen Token)는 Token-Based Authentication은 한 종류 입니다. JWT는 웹 표준으로서, 헤더, 페이로드, 시그니처로 세 부분으로 구성이 되어 있습니다. 헤더는 토큰의 타입과 해싱 알고리즘 정보를 담고 있으며, 페이로드에는 실제 인증에 필요한 데이터를 담게 됩니다. 마지막으로, 시그니처는 서버에서 비밀키를 사용하여 생성되며, 이를 통해 토큰의 무결성을 검증할 수 있습니다.
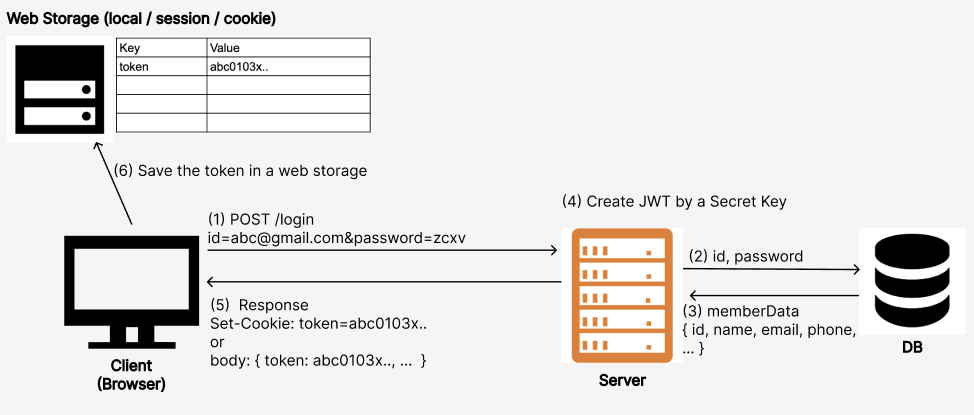
위의 Header, Payload, Signature를 이용해서 사용자의 정보를 암호화하고 해당 payload를 토큰화할때 signature에 secret key가 필요하고, secrey key는 복호화가 아니라 토큰이 유효한 지를 검증하는데 사용됩니다.
SOP와 CORS에 대해서 설명해주세요.
- Cross-Origin Resource Sharing는 서버와 브라우저의 주소가(오리진이) 다를 때 브라우저가 보낸 리소스 요청을 처리하는 메커니즘입니다. 기본적으로 보안 상의 이유로 SOP를 원칙으로 합니다. 즉, 브라우저와 서버의 오리진이 다르다면 브라우저는 서버가 보낸 리소스를 사용할 수 없습니다. 브라우저가 요청을 보내고, 이에 대해 서버가 보낸 응답의 http 헤더 중 ACAO에 오리진이 포함되어 있는지를 확인 합니다.
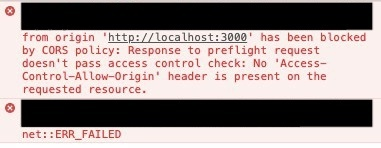
서로 다른 오리진인지를 확인하기 위해서, 해당 경우에는 request header에 자신의 오리진을 포함하여 보내게 됩니다. 그리고 이런 CORS가 필요한 경우 브라우저에서 간단한 요청을 제외하고 Prelight request를 먼저 서버 측으로 보내서 유효한 응답이 오는지 확인을 하게 됩니다. 확인은 응답 헤더의 ACAO를 확인하는 등의 방법을 취하게 되고, 이 헤더에 현 브라우저의 오리진이 명시되어 있다면 유효한 요청으로 판단하여 실행 가능해집니다.
Preflight Request란?
브라우저의 요청이 안전하고 유효한지를 확인하기 위해 브라우저가 실제 요청을 보내기 전에OPTIONS메서드로 사전 요청을 보내는 것입니다.
- Same-Origin Policy는 웹 브라우저에 내장된 보안 기능으로, 스크립트가 다른 출처의 리소스에 접근하는 것을 제한합니다. 기본적으로 오리진이 다를 경우, 스크립트의 실행을 제한합니다. 쉽게 말해서, 실수로 잘못 들어간 사이트에서 멋대로 코드를 실행하여 쿠키 같은 개인정보나, 다른 사이트의 DOM 조작을 하지 못하도록 막을 수 있는 것입니다. 그리고 동시에 브라우저와 서버가 오리진이 다를 경우에도 리소스 사용이 차단됩니다.
🗂️ Origin 이란?
리소스가 있는 장소를 명시하는 것으로, URL의 세가지 구성 요소인 프로토콜, 호스트 그리고 포트 번호를 조합하여 정의됩니다. 이 세 가지가 모두 일치해야 같은 오리진으로 간주됩니다.
REST에 대해서 설명해주세요. Restful API는 뭘까요?
REST는 Representational State Transfer의 약어로, 현재 애플리케이션의 상태간의 상태를 요청을 할때마다 관련 Expression을 제공함으로써 복잡한 네트워크에서 통신을 관리하기 위해서 만들어진 지침입니다. 이러한 동작 방식은 Survivability와 Resilience(회복탄력성)를 향상 시킵니다.
RESTful API는 주로 HTTP Method를 기반으로 하는 두 컴퓨터 시스템이 인터넷을 통해 정보를 안전하게 교환하기 위해 사용하는 인터페이스입니다. 기본 기능은 인터넷 브라우징과 동일합니다.
REST API 호출 단계
- 클라이언트가 서버에 요청을 전송한다. 클라이언트가 API 문서에 따라 서버가 이해하는 방식으로 요청 형식을 지정합니다.
- 서버가 클라이언트를 인증하고 해당 요청을 수행할 수 있는 권한이 클라이언트에 있는지 확인합니다.
- 서버가 요청을 수신하고 내부적으로 처리합니다.
- 서버가 클라이언트에 응답을 반환합니다. 응답에는 요청이 성공했는지 여부와 요청한 정보를 클라이언트에 알려주는 정보가 포함됩니다.
💡API란?
Application Programming Interface의 약자로 다른 소프트웨어 시스템과 통신하기 위해 따라야 하는 규칙을 정의합니다. API를 통해서 다른 애플리케이션이 프로그래밍 방식으로 통신할 수 있도록 표시하거나 생성합니다. 웹 API는 클라이언트와 웹 리소스 사이의 게이트웨이라고 생각할 수 있습니다.
일반적인 작업
- post
- get
- put
- patch
- delete
추가적인 작업
- options
- head
RESTful API 클라이언트 요청 구성요소
고유 리소스 식별자, 메서드(GET, POST, PUT, DELETE, HTTP HEADER), DATA, PARAMS 등을 요청으로 받습니다.
REST 제약 조건에 대해 설명해주세요.
위의 복잡한 네트워크 통신을 파악하고 관리하기 위해 만들어진 REST는 아래와 같은 몇가지 아키텍쳐 스타일의 원칙이 존재합니다.
-
균일한 인터페이스
균일한 인터페이스는 모든 RESTful API 웹 서비스 디자인의 기본으로, 서버가 표준 형식으로 정보를 전송함을 나타냅니다. 형식이 지정된 리소스를 REST에서 표현이라고 부릅니다. 이 형식은 서버 APP에 있는 리소스의 내부 표현과 다를 수 있습니다. 또한 균일한 인터페이스에는 4라지 아키텍쳐 제약 조건이 있습니다.
ex ) Server data : .txt but sending data with HTML.
1. 요청은 리소스를 식별해야 합니다. 이를 위해 균일한 리소스 식별자를 사용합니다.
2. 클라이언트는 원하는 경우 리소스를 수정하거나 삭제하기에 충분한 정보를 리소스 표현에서 가지고 있습니다. 서버는 리소스를 자세히 설명하는 메타데이터를 전송하여 이 조건을 충족합니다.
3. 클라이언트는 표현을 추가로 처리하는 방법에 대한 정보를 수신합니다. 이를 위해 서버는 클라이언트가 리소스를 적절하게 사용할 수 있는 방법에 대한 메타데이터가 포함된 명확한 메시지를 전송합니다.
4. 클라이언트는 작업을 완료하는 데 필요한 다른 모든 관련 리소스에 대한 정보를 수신합니다. 이를 위해 서버는 클라이언트가 더 많은 리소스를 동적으로 검색할 수 있도록 표현에 하이퍼링크를 넣어 전송합니다.
-
Stateless
REST구조에서 Stateless는 서버가 이전의 모든 요청과 독립적으로 모든 클라이언트 요청을 완료하는 통신 방법을 나타냅니다. 클라이언트는 임의의 순서로 리소스를 요청할 수 있스며 모든 요청은 무상태이거나 다른 요청과 분리 됩니다. -
계층화 시스템
계층화된 시스템 구조에서 클라이언트는 클라이언트와 서버 사이의 다른 승인된 중개자에게 연결할 수 있으며 여전히 서버로부터도 응답을 받습니다. 서버는 요청을 다른 서버로 전달 할 수도 있습니다. 여러 계층으로 여러 서버에서 실행되는 로직을 RESTful 웹 서비스를 설계하여 클라이언트에 보이지 않는 상태로 유지됩니다. -
캐시 가능성
RESTful 웹 서비스는 서버 응답 시간을 개선하기 위해 클라이언트 또는 중개자에 일부 응답을 저장하는 프로세세인 캐싱을 지원합니다. 예를 들어 모든 페이지에 공통 머리글 및 바닥글 이미지가 있는 웹사이트를 방문한다고 가정했을때, 계속 동일한 리소스를 반복해서 전송하는 것을 피해 리소스들을 캐싱하여 저장한 다름 캐시에서 직접 이미지를 사용합니다. -
온디맨드 코드
REST 아키텍쳐 스타일에서 서버는 소프트웨어 프로그래밍 코드를 클라이언트에 전송하여 클라이언트 기능을 일시적으로 확장하거나 사용자 지정할 수 있습니다. 해당 조건은 유일하게 선택적인 제약조건입니다.
URL, URI, URN 차이가 뭘까요?
여기서 URL은 Uniform Resource Locator의 약자로 인터넷의 리소스를 가르키는 표준 이름입니다. 해당 정보를 통하여 그것이 어디에 있고 어덯게 접근할 수 있는지 알려주는 역할을 합니다. URL의 첫 부분은 schem이라고 부르고, 해당 부분은 리소스에 접근하기 위해 사용되는 프로토콜을 서술합니다.(https://, mailto:// , ftp:// etc ..) 또한 필요에 따라 포트번호를 추가하여 사용하기도 합니다.

위의 파일명은 따로 쓰지 않는 이유는 서버에 미리 해당 웹의 리소스와 html 변형된 도메인 뒤에 붙이는 형식입니다. 그리고 웬만한 생략 즉, 도메인 까지만 입력을 해도 index.html(초기화면)으로 접근할 수 있도록 허용하고 있습니다.
URI는 인터넷의 우편물 주소 같은 것으로, 클라이언트에서 서버를 향해 리퀘스트 메세지를 보내는데, 해당 리퀘스트 메시지에는 무엇을, 어떻게 할 것인지에 대한 정보가 들어 있습니다. 여기서 무엇을에 해당하는 것이 URI 입니다. 보통 페이지 데이터를 저장한 파일의 이름이나 CGI Program의 파일명을 사용합니다.(/dir1/file3.html , /dir3/index.html etc ...)
반면 URN은 Uniform resource Name의 약자로 콘텐츠를 이루는 한 리소스에 대해, 그 리소스의 위치에 영향 받지 않는 유일무이한 이름 역할을 합니다. 아직은 통상적으로 쓰이는 방법은 아닙니다.
XSS 공격이 무엇이고, 방어하는 방법을 설명해주세요.
Cross-Site Scripting이라고 해서 XSS 공격은 공격자가 웹 페이지에 악의적인 스크립트를 삽입하고, 다른 사용자의 브라우저가 그 스크립트를 실행하게 만드는 공격입니다. 이 스크립트는 사용자의 세션 쿠키를 탈취하거나, 웹 사이트를 변조하거나, 악의적인 행위를 수행할 수 있습니다.
예방법
1. 이를 예방하기 위해서는 사용자 입력을 적절히 이스케이프 처리하여 브라우저가 이를 스크립트로 인식하지 못하게 합니다.
- 입력으로 오는 이스케이프 문자들을 변환하여 검증합니다.(괄호, 특정 이스케이프 문자 등)-
CSP(Content Security Policy, 컨텐츠 보안 정책)를 설정해서 외부 스크립트의 실행을 제한합니다.
- 스크립트가 로드될 수 있는 출처를 제한하거나 인라인 스크립트와 eval()의 사용을 금지하는 방법을 사용할 수 있습니다.
-
안전한 프로그래밍 방법을 사용합니다.
- innerHTML 대신 textContent를 사용하여 DOM을 조작합니다. 이런식으로 만들어 사용하여 스크립트를 동적으로 생성하지 않습니다.
CSRF 공격이 무엇이고, 방어하는 방법을 설명해주세요.
Cross-Site Request Forgery는 사용자의 웹 브라우저를 이용하여 사용자가 의도하지 않은 요청을 웹 애플리케이션에 보내는 공격입니다. 이는 사용자가 로그인한 상태에서 악성 웹사이트를 방문할 때, 백그라운드에서 실제 웹 사이트로 위조된 요청을 보내는 방식으로 이뤄집니다.
해당 공격은 이미 인증된 다른 사이트에 대한 요청을 생성 후, 그 해당 사이트에 들어가 있는 동안 송금 요청을 위조하는 방식을 사용할 수 있습니다.
CSRF 공격을 예방하기 위해서는 아래의 방법을 사용해야 합니다.
- Anti-CSRF 토큰 사용
- 웹 애플리케이션은 폼을 제출할 때마다 서버에서 생성한 고유한 토큰을 폼에 포함시킵니다.
- 서버는 사용자가 폼을 제출할 때 이 토큰을 검증하여 요청의 유호성을 확인합니다.
- SameSite 쿠키 속성 설정
- SameSite 쿠키 속성을 Strict 또는 Lax로 설정하여 동일 출처에서만 쿠키를 전송하도록 합니다.
- 사용자 인증 요구
- 중요한 작업(비밀번호 변경, 계정 설정 등)에 대해 사용자에게 비밀번호를 다시 입력하게 하거나, 이중 인증을 요구합니다.
SQL Injection 공격이 무엇이고, 방어하는 방법을 설명해주세요.
SQL Injection은 데이터베이스를 조작하는 애플리케이션의 취약점을 이용하여, 공격자가 애플리케이션의 SQL 쿼리에 악의적인 SQL 코드를 삽입하는 공격입니다. 이를 통해 데이터베이스에서 데이터를 읽거나 수정, 삭제할 수 있습니다.
💡 Simple examples
SQL Injection of NOMALTIC
SQL Injection은 애플리케이션이 사용자 입력을 그래도 SQL 쿼리에 포함시킬 때 발생합니다. 예를 들어, 로그인 폼에서 "OR1=1" 같은 입력을 통해 인증 과정을 우회할 수 있습니다. 이러한 공격을 막기 위해서는 다음 3가지의 방법을 고려하면 좋습니다.
- Parameterized Queries(Prepared Statements) 사용
- 사용자 입력을 쿼리의 파라미터로 전달하고, 데이터베이스가 쿼리를 안전하게 실행하도록 합니다. 예를 들어, JDBC의 PreparedStatement나 JPA TypedQuery는 사용자 입력을 파라미터로 받아 SQL Injection을 방지합니다.
String userId = request.getParameter("userId");
PreparedStatement statement = connection.prepareStatement("SELECT * FROM users WHERE id = ?");
statement.setString(1, userId);
ResultSet resultSet = statement.executeQuery();- ORM 사용
- Object-Relational Mapping은 객체 지향 프로그래밍 언어를 사용하여 데이터베이스의 데이터를 객체로 변환하는 프로그래밍 기술입니다. ORM을 사용하면 SQL 쿼리를 직접 작성하는 대신, 객체의 메서드를 통해 데이터를 조작할 수 있습니다.
String userId = request.getParameter("userId");
User user = session.get(User.class, userId);- Principle of Least Privilege (DB Access 권한 최소화)
- 말 그대로 애플리케이션의 DB 사용자로 하여금 권한을 최소한으로 권한을 부여하는 것입니다.
🚨 Object-Relational Mapping
- ORM의 주요 기능
- 객체-테이블 매핑 : DB의 테이블을 클래스로, 레코드를 객체로 매핑합니다.
- 데이터 쿼리 및 조작 : DB Query를 작성하는 대신 객체의 메서드를 사용하여 데이터를 쿼리하고 조작합니다.
- 데이터베이스 추상화 : 데이터베이스의 세부 사항을 추상화하여, 개발자가 SQL 쿼리를 직접 작성하는 대신 객체와 메서드로 데이터 작업을 수행할 수 있게 합니다.
- 트랜잭션 관리 : 데이터베이스 작업을 트랜잭션 단위로 묶어, 일관성을 유지하고 데이터 무결성을 보장합니다.
웹 캐시에 대해 설명해주세요.
Web Cash는 자주 쓰이는 문서의 사본을 자동으로 보관하는 HTTP 장치입니다. 웹 요청이 캐시에 도착했을 때, 캐시된 로컬 사본이 존재한다면, 그 문서는 원 서버가 아니라 그 캐시로부터 제공이 됩니다. 이러한 캐시를 사용함으로써 얻을 수 있는 것은 아래와 같습니다.
- 캐시는 불필요한 데이터 전송을 줄여서, 네트워크 요금으로 인한 비용을 줄여 준다.
- 캐시는 네트워크 병목을 줄여준다. 대역폭을 늘리지 않고도 페이즈를 빨리 불러 올 수 있게 됩니다.
- 캐시는 원 서버에 대한 요청을 줄여줍니다. 서버는 부하를 줄일 수 있으며 더 빨리 응답을 할 수 있게 됩니다.
- 페이지를 먼 곳에서 불러올수록 시간이 많이 걸리나, 캐시는 거리로 인한 지연을 줄여줍니다.
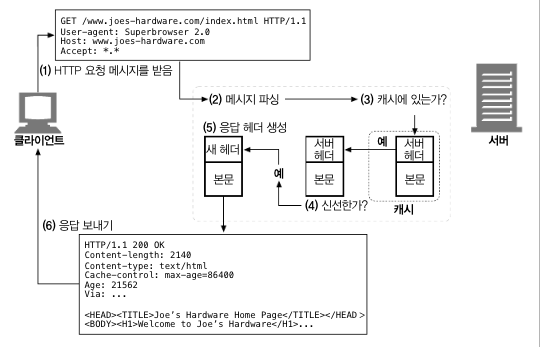
캐시의 처리 과정
-
요청 받기
네트워크 커넥션에서의 활동을 감지하고, 들어오는 데이터를 읽어들이고, 고성능 캐시는 여러 개의 들어오는 커넥션들로부터 데이터를 동시에 읽어들이고 메시지 전체가 도착하기 전에 트랜잭션 처리를 시작합니다.
-
파싱
요청 메시지를 여러 부분으로 파싱하여 헤더 부분을 조작하기 쉬운 자료 구조에 담습니다. 이는 캐싱 소프트웨어가 헤더 필드를 처리하고 조작하기 쉽게 만듭니다. -
검색
URL을 알아내고 그에 해당하는 로컬 사본이 있는지 검사합니다. 로컬 복사복은 메모리에 저장되어 있을 수도 있고, 아니면 디스크나 심지어 근처의 다른 컴퓨터에 있을 수도 있습니다. 만약 문서를 로컬에서 가져올 수 없다면, 캐시는 상황이나 설정에 따라서 그것을 원 서버나 부모 프락시에서 가져오거나 혹은 실패를 반환 합니다.캐시된 객체는 서버 응답 본문과 원 서버 응답 헤더를 포함하기에 캐시 적중(사본 있는 상태) 동안 올바른 서버 헤더등의 다양한 메타데이터가 반환 될 수 있습니다.
-
신선도 검사
일정 기간 동안 서버 문서의 사본을 보유할 수 있도록 해줍니다. 이 기간 동안, 문서는 신선한 것으로 간주되고 서버와의 접촉 없이 해당 문서를 제공할 수 있습니다. 그러나 해당 기간이 지나면, 서버와 재검사를 진행합니다.
-
응답 생성
캐시를 원 서버에서 온 것처럼 보이게 하기 위해서 응답 헤더를 토대로 응답 헤더를 생성합니다. 이 기저 헤더들은 캐시에 의해 수정되고 늘어납니다. 단, Date 헤더는 캐시가 조정을 해서는 안되는 규칙이 있습니다.
-
전송
일단 응답 헤더가 준비되면, 캐시는 응답을 클라이언트에게 돌려줍니다. 모든 프락시 서버들과 마찬가지로, 프락시 캐시는 클라이언트와의 커넥션을 유지할 필요가 있습니다. -
로깅
대부분의 캐시는 로그 파일과 캐시 사용에 대한 통계를 유지합니다. 각 캐시 트랜잭션이 완료된 후, 캐시는 통계 캐시 적중과 부적중 횟수에 대한 통계를 갱신하고 로그 파일에 요청 종류, URL 그리고 무엇이 일어났는지를 알려주는 항목을 추가합니다. 제일 빈번하게 쓰이는 캐시 로그 포맷은 Squid log format, Netscape extended common log format이지만 Custom log format 또한 허용합니다.
Network Bottleneck(네트워크 병목)
데이터 전송 과정에서 네트워크 트래픽이 한정된 대역폭을 통과하면서 발생하는 지연을 의미합니다. Bottleneck 현상은 네트워크의 특정 부분에서 처리 능력이나 전송 속도가 나머지 네트워크의 성능에 비해 상대적으로 낮을 때 발생하며, 이로 인해 전체 시스템의 처리량이 저하될 수 있습니다.Network Bottleneck의 주요 원인
- 대역폭 부족 : 네트워크의 특정 구간이나 Component(ex. Router, Switch)가 충분한 대역폭을 제공하지 못할 때 발생합니다.
- 하드웨어 한계 : 네트워크 장비의 처리 능력이 높은 트래픽을 감당하지 못할 경우 병목이 발생할 수 있습니다.
- 네트워크 구성 : 부적절한 라우팅 구성이나 네트워크 디자인으로 인해 트래픽이 비효율적으로 분산될 수 있습니다.
- 서버 성능 문제 : 서버 자체의 CPU, 메모리, 스토리지 성능이 요구사항을 충족하지 못하면 처리 지연이 발생할 수 있습니다.
- 네트워크 공격 : DDos(분산 서비스 거부) 공격과 같은 악의적인 트래픽이 네트워크 리소스를 과다하게 사용하면 병목 현상이 발생할 수 있습니다.
프록시 서버에 대해서 설명해주세요.
Proxy Server는 클라이언트의 입장에서 트랜잭션을 수행하는 중개인입니다. 이러한 중개인이 없는 상황에서 Client는 HTTP Server와 직접 이야기를 하게 되는 것 입니다. 이러한 특징에 의해 프록시 서버는 웹 서버이자 웹 클라이언트가 되는 것입니다.
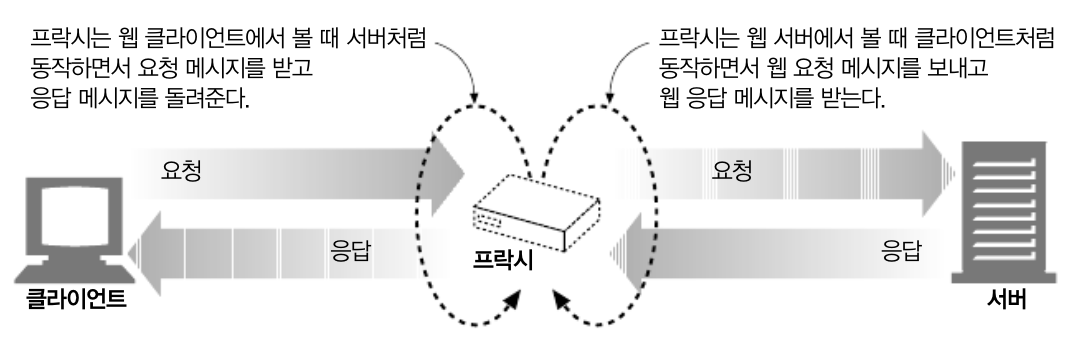
프록시 서버는 실용적이고 유용한 것이라면 무슨 일이든 합니다. 보안을 개선하고, 성능을 높여 주며, 비용을 절약하는 등의 동작을 말합니다. 또한 프록시 서버는 HTTP 트래픽을 들여다보고 건드릴 수 있기 때문에, 프록시는 부가적인 가치를 주는 여러 유용한 웹 서비스를 구현하기 위해 트래픽을 감시하고 수정할 수 있습니다.
Examples
1. 어린이 필터
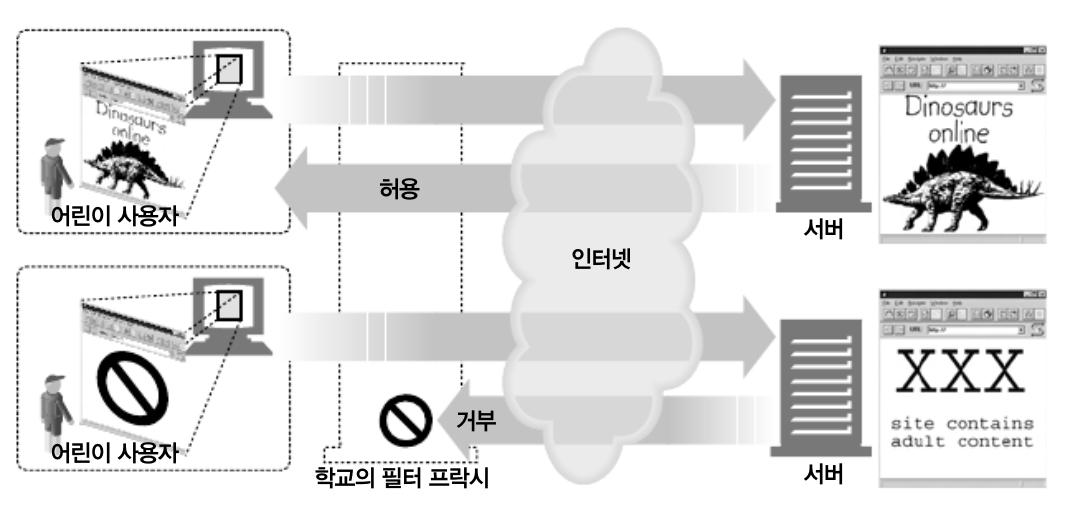
-
문서 접근 제어자
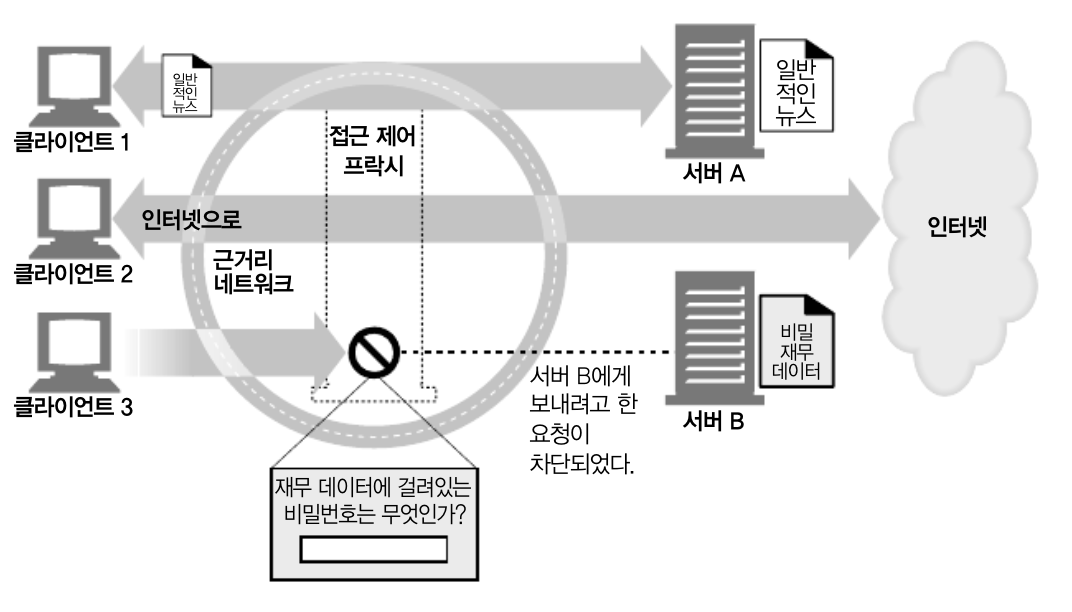
-
보안 방화벽
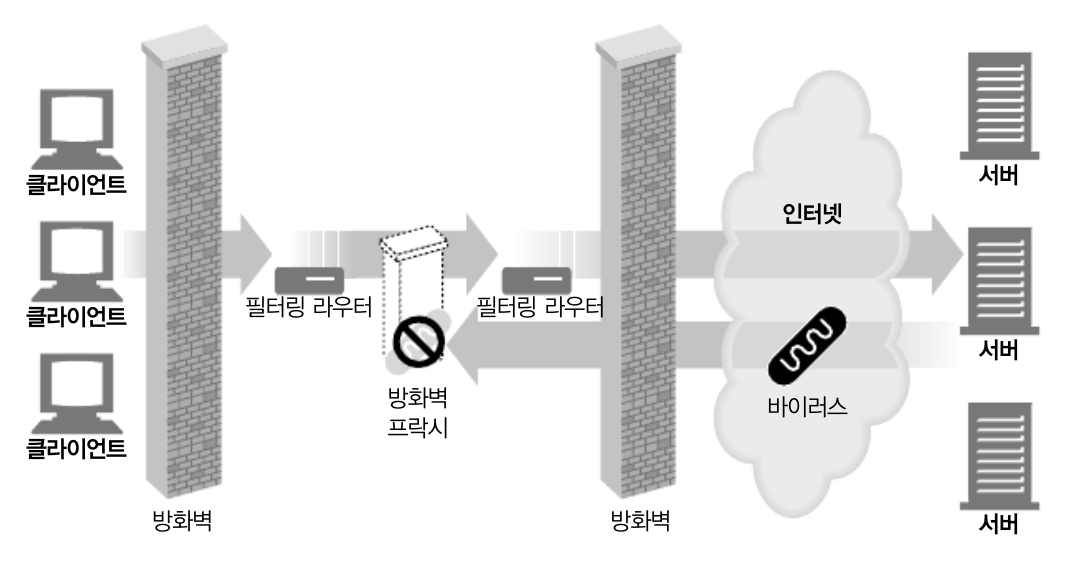
-
웹 캐시
-
대리 프록시, 콘텐츠 라우터, 트랜스 코더 등등
프록시는 어떻게 사용할지에 다라서 어디에든 배치할 수 있습니다. 이때 포워드 프록시와 리버스 프록시는 위치와 역할에 따라 다르게 운영됩니다.
포워드 프록시에 대해서 설명해주세요.
Forward Proxy는 클라이언트가 인터넷에 접속할때 중간에 위치하여 클라이언트의 요청을 서버에 전달하고, 서버의 응답을 다시 클라이언트에게 전달합니다. 클라이언트의 IP 주소를 숨기고, 콘텐츠 접근을 제어하며, 캐싱을 통해 네트워크 효율을 개선할 수 있습니다.
이를 응용해서 회사에서 인터넷 사용 정책을 시행하기 위해 모든 회사의 웹 트래픽이 프록시 서버를 거치도록 설정하여, 부적절한 접근을 차단하고 웹 페이지의 캐싱을 통해 네트워크 대역폭 사용을 줄이며 직원의 인터넷 사용을 모니터링 할 수 있습니다.
리버스 프록시에 대해서 설명해주세요.
Reverse Proxy는 앞에 위치하여 클라이언트의 요청을 받아 내수 서버에 전달하고, 그 응답을 클라이언트에게 다신 보냅니다. 이는 서버의 보안을 강화, 부하 분산, SSL 암호화 종단, 캐싱과 같은 기능을 제공합니다.
한번에 많은 트래픽이 많은 시간대에 갑자기 몰릴 수 있는 온라인 쇼핑몰 같은 경우는 리버스 프록시를 사용하여 사용자의 요청이 먼저 리버스 프록시 서버에 도착하고, 이러한 요청을 Rever Proxy Server에서 웹 서버에 균등하게 분배할 수 있도록 만들 수 있습니다. 또한 리버스 프록시 서버는 SSL 암호화를 처리함으로써 개별 웹 서버의 부하를 줄이고 보안을 강화할 수 있습니다.
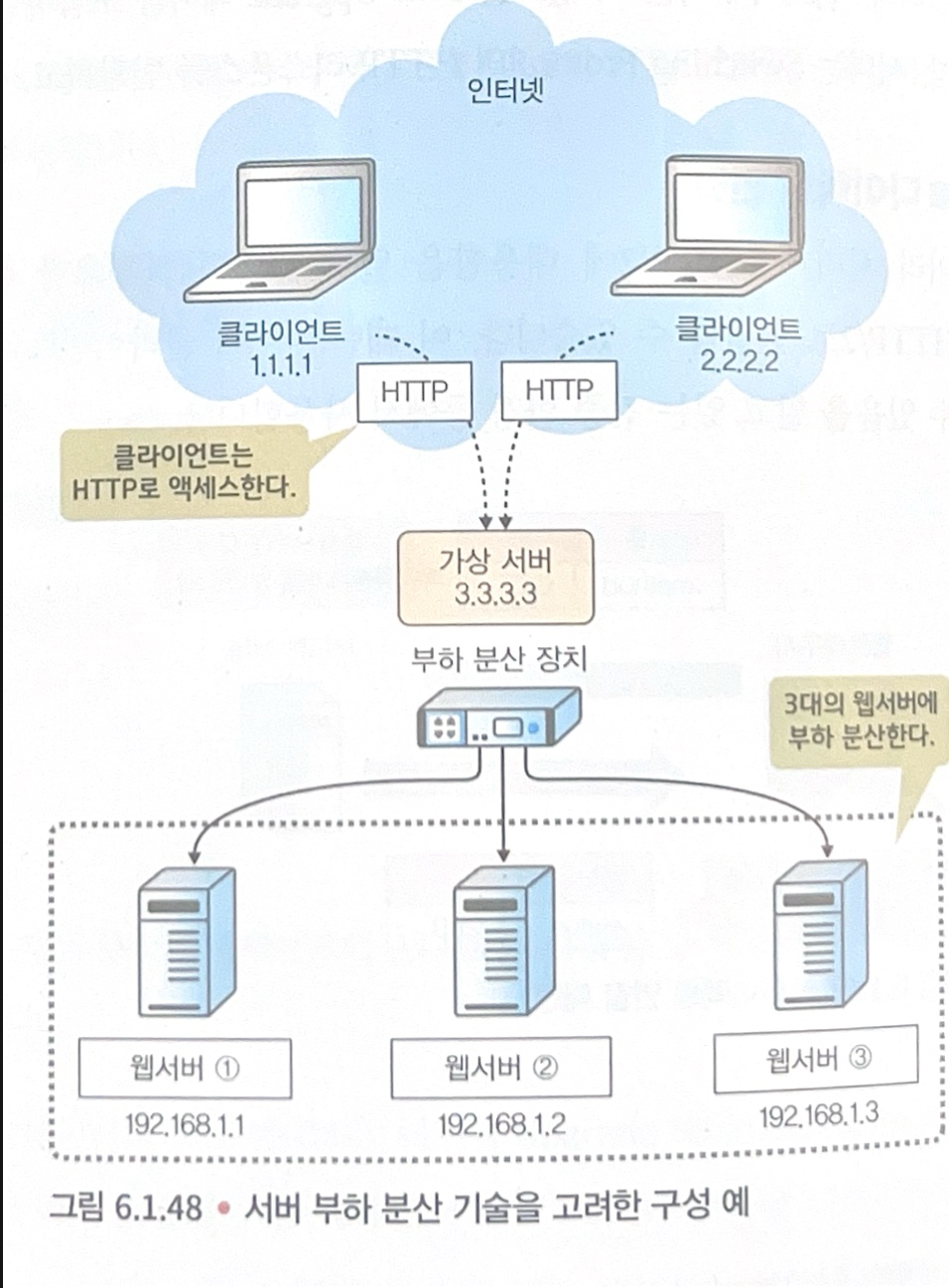
🚦Load Balancing ⚖️
Load Balancing이라는 것은 복수의 서버를 사용하여 분담 처리를 해 한 대당 처리량을 줄이는 것을 말합니다. 이러한 기능을 하는 장치를 Load Balancer라고 합니다.
부하 분산 장치는 네트워크 계층(L3)이나 트랜스포트 계층(L4), 애플리케이션 계층(L7)의 정보를 이용해, 여러 서버에 커넥션을 할당하는 기능입니다. 보는 것처럼 OSI 7계층 중 어떤 계층을 기준으로 분산 작업을 하느냐에 따라 그 타입이 나뉘게 됩니다.
- 수신지 NAT(Network Address Translation)
서버 부하 기술의 기본은 수신지 NAT입니다. 수신지 NAT는 NAT의 중에 하나로, 패키지의 수신지 IP 주소를 변환하는 기술 입니다. 클라이언트로부터 패킷을 받으면 서버의 살아 있는 상태나 커넥션의 상태를 확인하고, 최적의 서버의 IP 주소로 수신지 IP를 변환합니다.
이러한 수신지 NAT는 Connection Table을 기반으로 수행 되는데, 어느 커넥션을 어느 IP주소에 수신지 NAT할 것인지를 파악합니다.
Connection Table 기반으로 하는 Load Balancer의 동작 원리
- 가상 서버로 부터 클라이언트의 커넥션은 받고 이때, 수신지 IP 주소는 가상 서비의 IP주소로 바뀌게 됩니다. 받은 커넥션은 커넥션 테이블로 관리가 됩니다.
- 가상 서버의 IP 주소로 된 수신지 IP주소를 Load Balancing의 대상의 IP로 변환합니다.(변환한 IP도 Conncetion Table에 보관합니다.) 변환한 IP 주소를 서버의 상태나 커넥션 상태 등 다양한 상태에 따라 동적으로 바꿔 커넥션은 분산합니다.
- 커넥션을 받은 서버는 애플리케이션 처리 후 기본 게이트웨이로 있는 Load Balancer에 반환 통신을 보냅니다. 이때 로드 밸런서는 가야할 수신 NAT와 반대인 송신지 IP를 NAT 합니다.
이 같은 로드 밸런서의 기능은 아래와 같습니다.
- 부하 분산 : 여러 서버에 걸쳐 들어오는 트래픽을 분산시켜 각 서버의 부하를 줄입니다.
- 건강 검사 : 서버의 건강 상태를 주기적으로 확인하여, 문제가 있는 서버에는 트래픽을 보내지 않습니다.
- 세션 지속성 : 사용자의 세션을 유지하기 위해 특정 사용자의 요청을 항상 같은 서버로 보내는 기능을 제공합니다.
- SSL 종단 : SSL/TLS 암호화를 로드 밸런서에서 처리하여, 서버의 부담을 줄입니다.

로드 밸런싱의 방식과 중요도에 따라서 L3,L4,L7 중 어떤 것을 채택해서 사용할지가 나뉘게 됩니다.
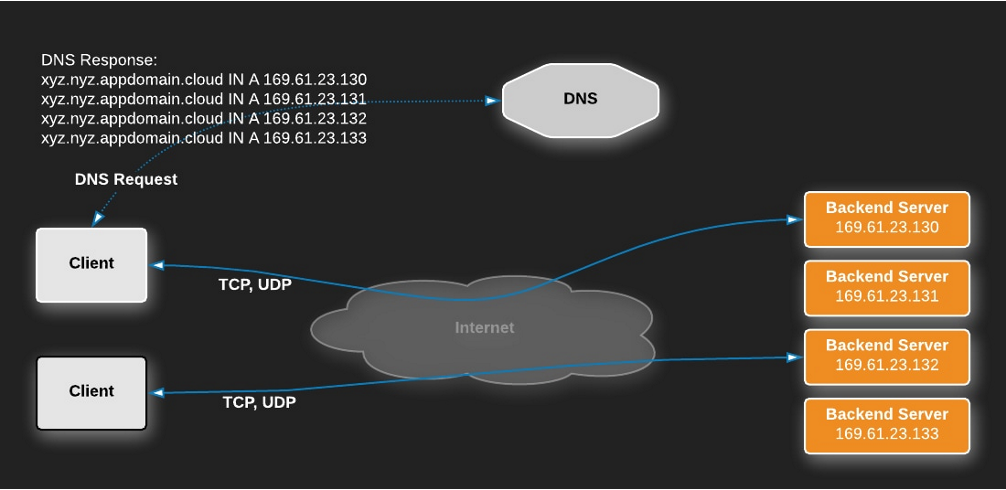
L3 로드 밸런서(네트워크 계층)
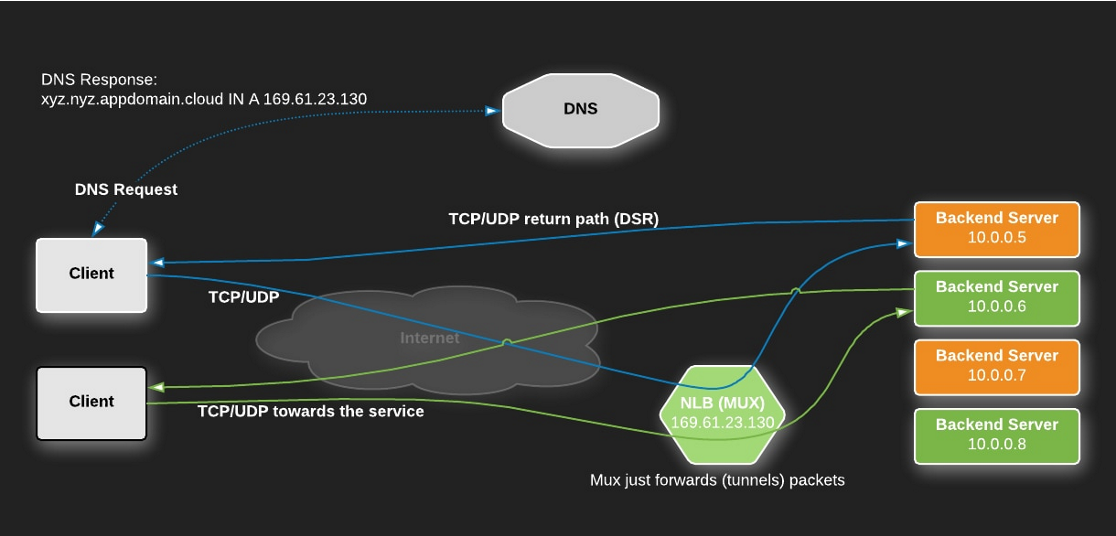
- IP 기반 라우팅 : L3 load balancer는 IP 주소와 같은 네트워크 계층 정보를 기반으로 라우팅을 결정합니다.
- 경로 결정 : 네트워크 경로를 결정하고, 네트워크 트래픽을 효율적으로 분산시키기 사용됩니다.
- 빠른 처리 속도 : 네트워크 계층에서 작동하기 때문에, 페이로드 내용을 확인하지 않고 빠른 속도로 라우팅 결정을 내릴 수 있습니다.
DNS Resolver는 리스트를 재배치하여 클라이언트에게 리턴하고 클라이언트에서 후에 리턴된 리스트의 가장 첫번째 ip로 연결을 시도하게 됩니다.
L4 로드밸런서(트랜스포트 계층)
- TCP/UDP 기반 라우팅 : L4 로드 밸런서는 TCP나 UDP 포트 정보와 같은 전송 계층 정보를 이용하여 트래픽을 분산시킵니다.
- 세션 지속성 제공 : 클라이언트의 세션을 특정 서버에 고정시키기 위해 사용됩니다. 이를 통해 세션 데이터의 일관성을 유지할 수 있습니다.
- NAT : 클라이언트의 IP주소와 포트 번호를 변경하여 내부 서버에 전송합니다.
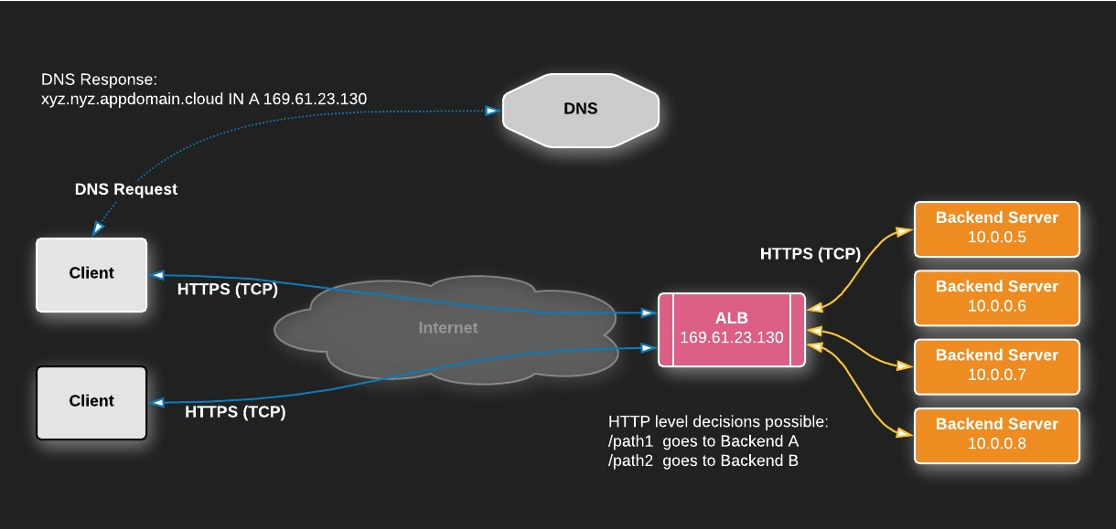
L7 로드 밸런서에 대해서 설명해주세요.
L7 로드 밸런서은 Application Load Balancing 이라고 해서 OSI 7 Layers 를 기준으로 7번쨰 Application Layer를 기준으로 로드 밸런싱을 하는 장치입니다.
IP와 포트정보뿐만 아니라 패킷의 URL 정보, 쿠키, Payload를 보고 정해진 정책에 따라 라우팅 해주게 됩니다. 하위 로드밸런서와 비교했을 때 더욱 세부적인 부하 처리가 가능합니다. 또한 해당 계층의 데이터를 분석하여 특정 유형의 공격으로 부터 보호할 수도 있습니다.
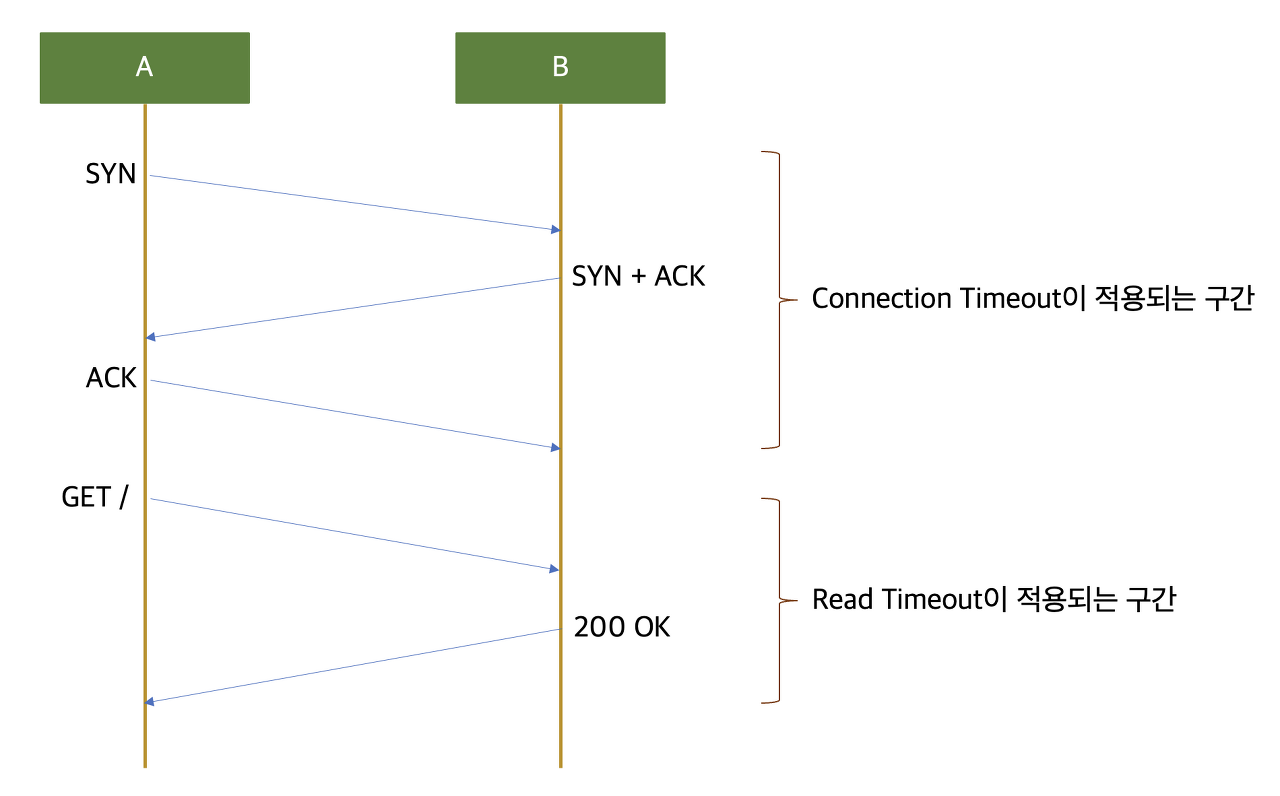
커넥션 타임아웃과 리드 타임아웃에 대해 설명해주세요.
Connection Timeout
종단 간 연결하는데 소요되는 최대 시간을 의미합니다. 이 시간을 넘기게 되면 연결 할 수 없는 것으로 판단하고 에러가 발생 합니다. 이때 연결은 TCP 3 way handshake를 통해 TCP 연결이 생성되는 것을 의미합니다.
Read Timeout
종간 간에 데이터를 주고 받을 때 소요되는 최대 시간을 의미 합니다. 이 시간을 넘기게 되면 데이터를 받을 수 없는 것으로 판단하고 에러가 발생합니다.
REST API에서 타임 아웃 적용 구간
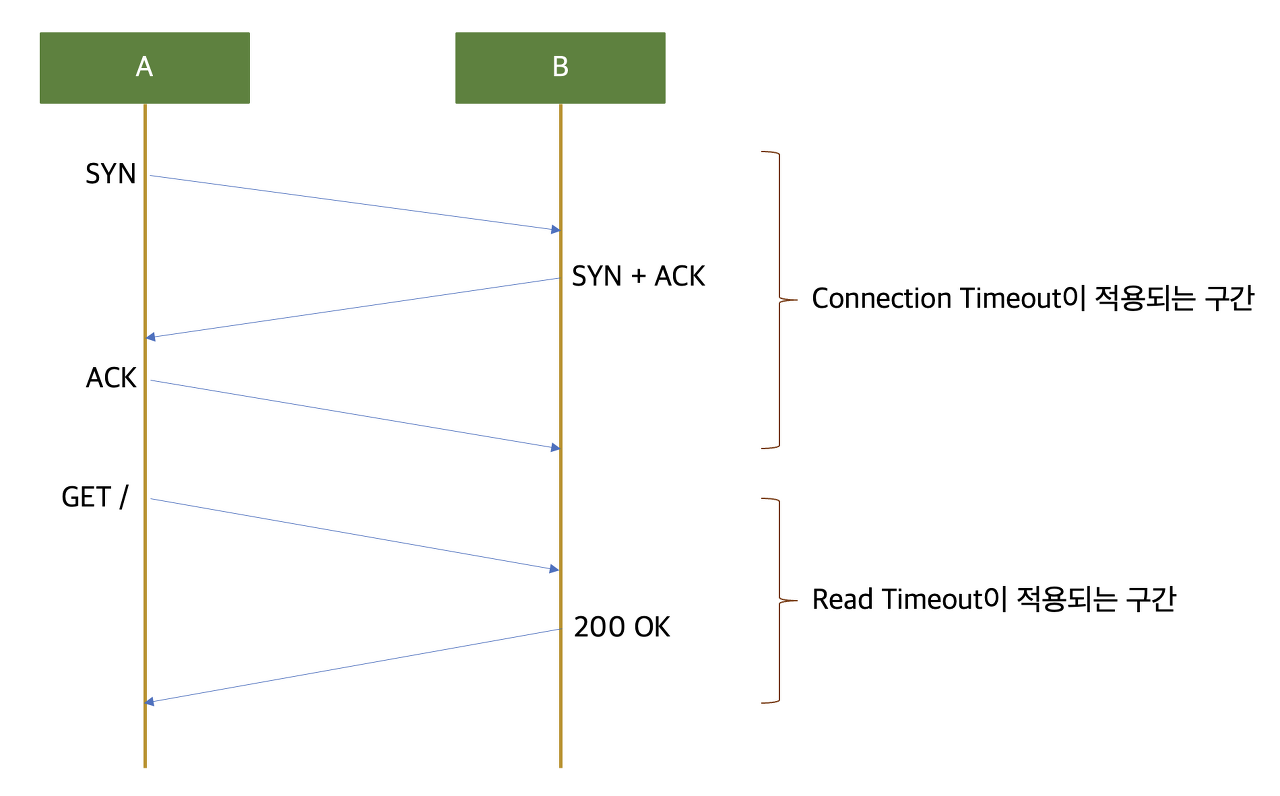
타임아웃을 설정하기 위해서는 적당한 기준을 정해야 합니다.
- 네트워크 상에서 패킷 유실은 꼭 장애 상황이 아니더라도 언제든 발생할 수 있습니다. 하지만, 기술의 발전으로 한번의 패킷 유실 정도는 재전송을 통해 해결할 수 있습니다 :)
- 네트워크 상에서 문제가 발생했다면 가능한 빨리 인지해야 합니다.
references
1. RESTful API
2. CORS & SOP
3. Load Balancer
4. TimeOut
5. TCP 혼잡 제어
6. Cookie & Session
7. Authorization
