📌 HTTP
HTTP 프로토콜에 대해서 설명해주세요.

HTTP(Hypertext Transfer Protocol)는, 전 세계의 웹 브라우저, 서버, 웹 애플리케이션의 대화하는 현대 인터넷 용어라고 할 수 있습니다. HTTP는 수십억 개의 이미지, 페이지, 텍스트 파일 등을 쉬지 않고 웹 서버로 부터 대량의 정보를 받고 옮기는 역할을 합니다. 여기서, 데이터의 손실이나 외곡의 문제는 걱정하지 않아도 되는 장점이 있습니다.
웹 클라이언트와 서버
웹 서버는 HTTP 프로토콜을 통해서 의사소통을 하기 때문에 보통 HTTP 서버라고 불리며, 서버는 인테넷의 데이터를 저장하고, HTTP 클라이언트가 요청한 데이터를 제공합니다. 해당 클라이언트의 예시는 흔히, 크롬, 네이버와 같은 웹 브라우저를 말하게 됩니다.The Short Process on Web
- Index.html 요청 from client
- 해당 html의 타입, 길이 등의 정보를 HTTP 응답에 실어 전송

HTTP의 요청/응답 모델에 대해 설명해주세요.
HTTP Transaction은 요청 명령과 응답 결과로 구성되어 있습니다. 이러한 HTTP 트랜잭션은 HTTP 메세지라고 불리는 정형화된 데이터 덩어리를 이용해 이뤄집니다.
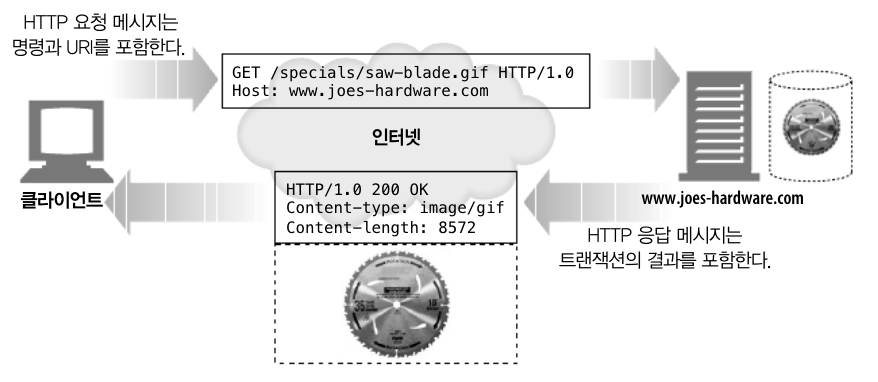
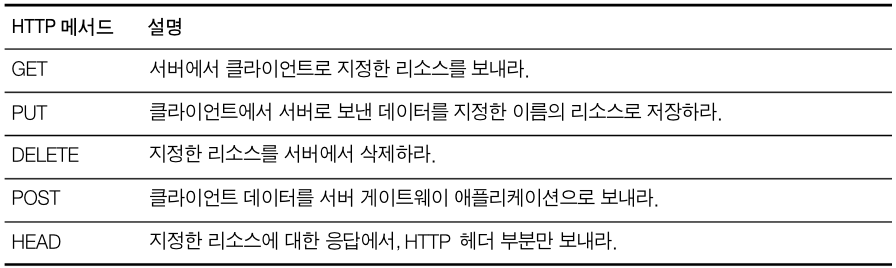
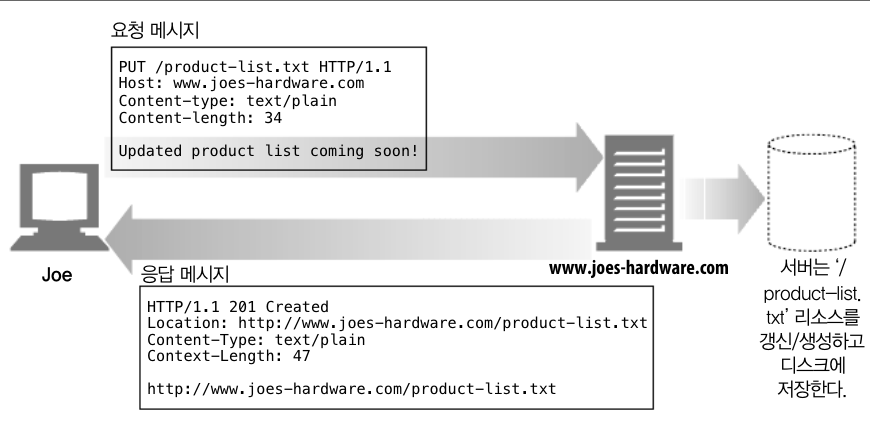
이러한 HTTP Transaction에서 요청 명령을 하기 위해 HTTP Method라는 것을 사용합니다. 모든 HTTP 요청 메세지는 한 개의 메서드를 갖고, 메서드는 서버에게 어떤 동작이 취해져야 하는지 말해줍니다.(웹 페이지 가져오기, 게이트웨이 프로그램 실행하기, 파일 삭제하기 등등) 이러한 HTTP Method는 흔히 다섯개를 말씀 드릴 수 있습니다.
| HTTP Method | Definition |
|---|---|
| GET | 서버에서 클라이언트로 지정한 리소스를 보내라. |
| PUT | 클라이언트에서 서버로 보낸 데이터를 지정한 이름의 리소스로 저장해라. |
| DELETE | 지정한 리소스를 서버에서 삭제하라. |
| POST | 클라이언트 데이터를 서버 게이트웨이 애플리케이션으로 보내라. |
| HEAD | 지정한 리소스에 대한 응답에서 HTTP 헤더 부분만 보내라. |
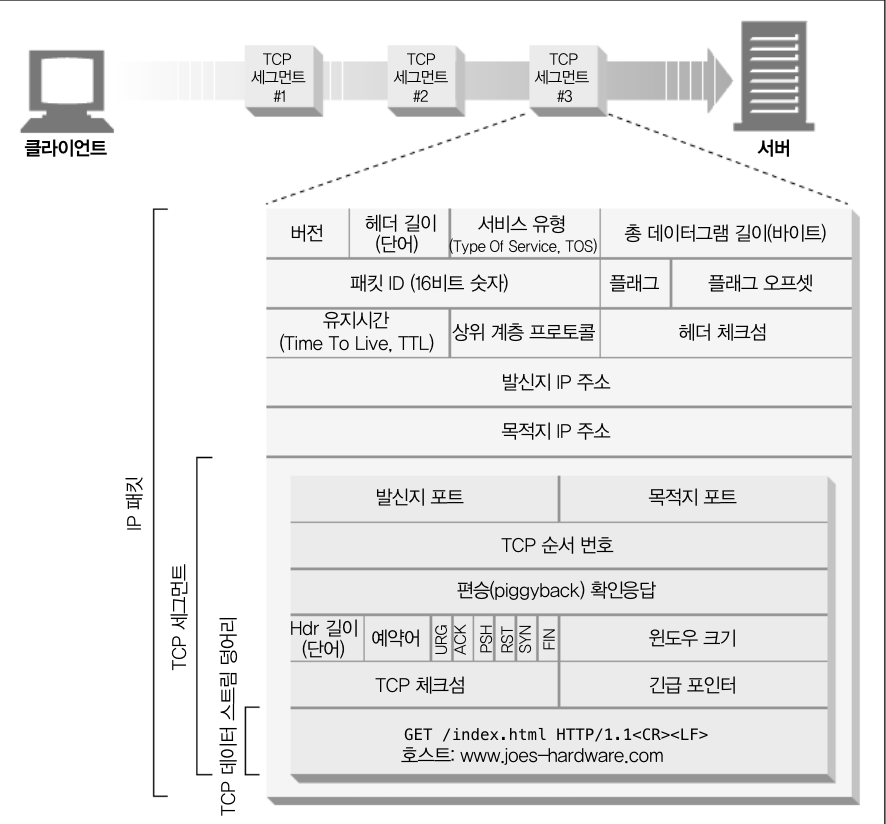
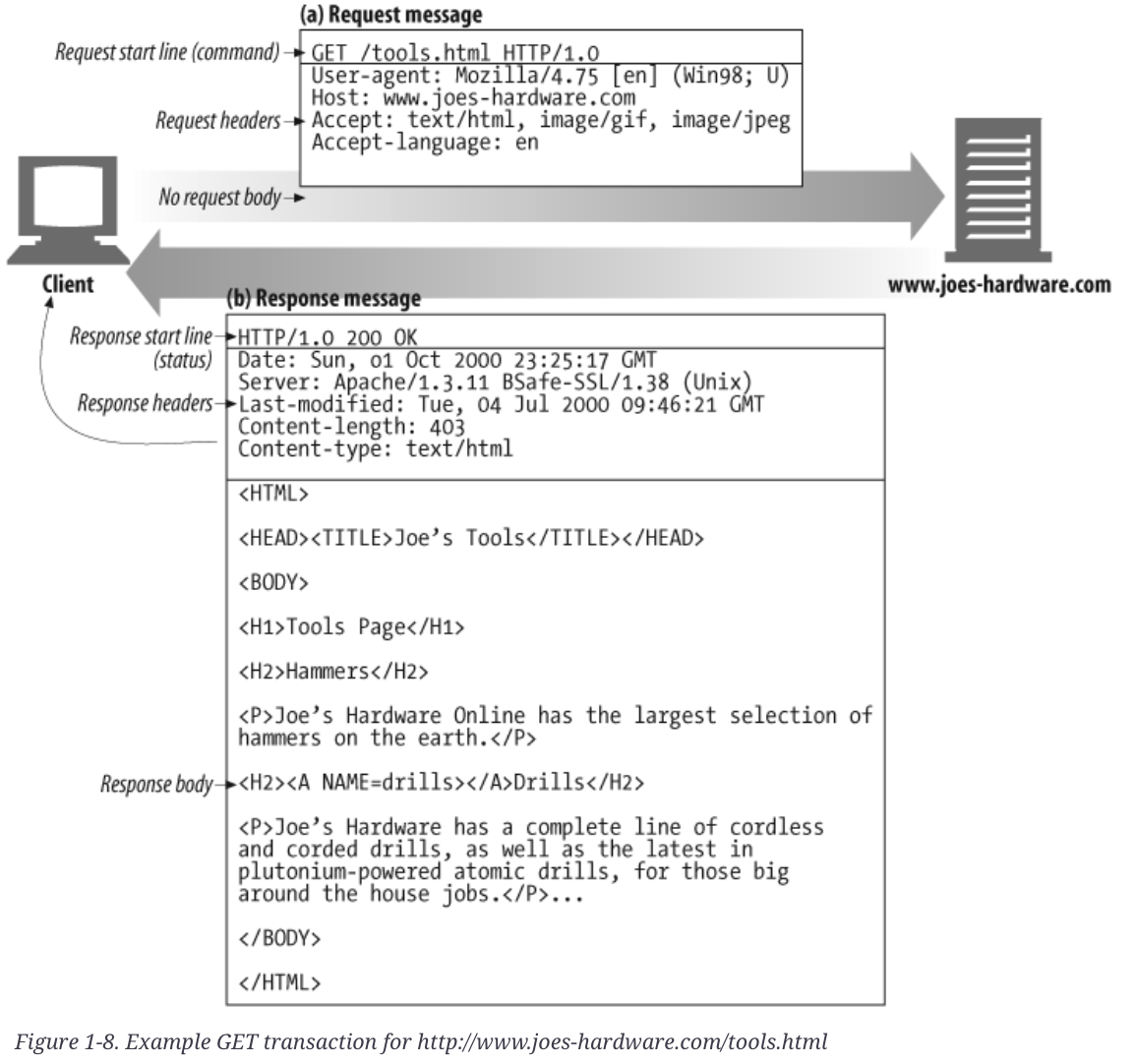
HTML Web에서 구성된 method에 따라 HTTP Message가 구성이 되게 됩니다. 해당 HTTP Message의 구성은 아래와 같습니다.
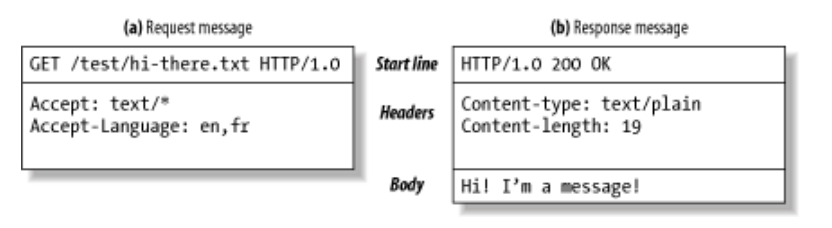
HTTP Message가 Web Client 에서 Web Server 로 전달되는 것을 Request Message 그 반대의 경우는 Response Message라고 합니다. 더 자세한 메세지의 구조는
-
Start Line
Start Line은 말 그대로 메세지의 처음 부분이며, 어떠한 부분을 요청하는지 혹은 응답으로 발생하는 결과에 대해서 암시를 하게 됩니다. -
Header Field
Start Line을 이어 아예 없거나 많은 줄을 차지하는 것이Header Field입니다. Header Field는 name과 value가 콜론(:)으로 나뉘어 쉽게 구분 할 수 있게 나타냅니다. 그리고, Header Field는 뒷 부분을 공백으로 마쳐 다음 줄을 읽기 편하고 쓰기 쉽다는 장점이 있습니다. -
Body
Header Field의 공백 뒤에 Data를 싣고 선택적으로 웹서버에 운반하게 됩니다. 즉, data는 올 수 도 있고 안올 수도 있습니다. 그리고 서버로 준 데이터를 다시 클라이언트로 되돌려 줌으로써, 정보 교환을 합니다. 위의Start Line,Header Field와는 상이하게 Body는 arbitrary binary data(임의의 이진 데이터)를 포함하여 일반 텍스트도 포함할 수 있습니다.
💡 Connections, IP Address and Port Number
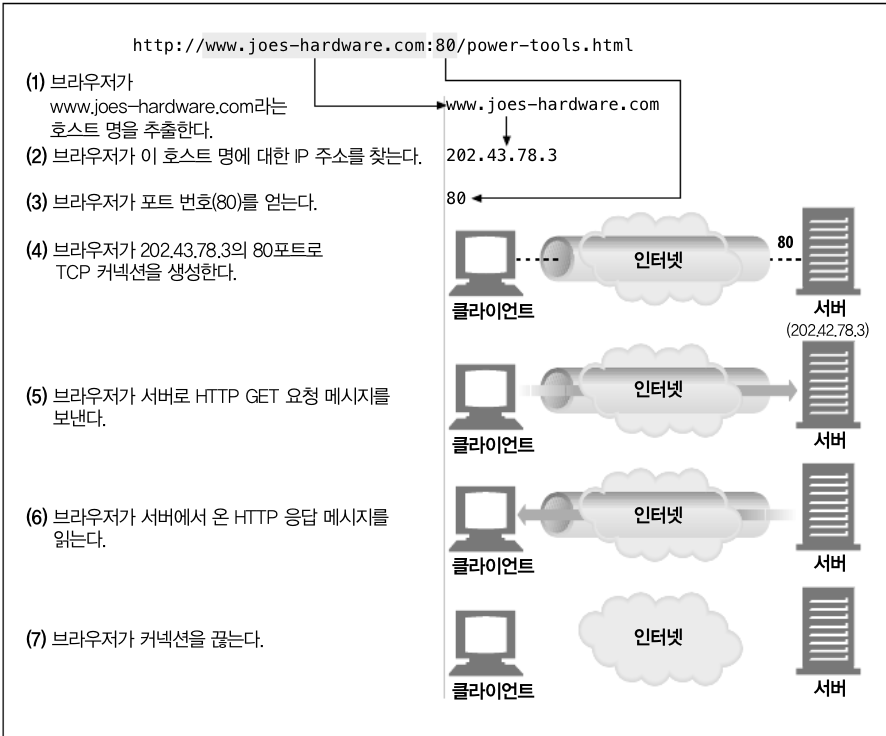
HTTP Client가 서버에 메세지를 전송할 수 있게 되기 전에, 인터넷 프로토콜(IP) 주소와 포트 번호를 사용해 클라이언트와 서버 사이에 TCP/IP 커넥션을 맺어야 합니다. 이 같은 커넥션을 맺는 것은 다른 누군가에게 전화를 거는 것과 유사하다고 할 수 있습니다. 이러한 정보는 URL을 통해서 얻을 수 있습니다.
- http://www.netscape.com/index.html
위 같은 도메인이 있다고 가정을 했을 때, DNS(Domain Name System)에 의하며 쉽게 IP Address로 변환 될 수 있습니다. 그리고 포트번호는 따로 명시되어 있지 않는 이상 기본은 80이라고 생각할 수 있습니다. IP Ads와 Port Number를 이용해 클라이언트는 TCP/IP로 쉽게 통신을 할 수 있게 됩니다.(a) 웹브라우저는 서버의 URL에서 호스트 명을 추출한다.
(b) 웹브라우저는 서버의 호스트 명을 IP로 변환한다.
(c) 웹브라우저는 URL에서 포트번호(있다면)를 추출한다.
(d) 웹브라우저는 웹 서버와 TCP 커넥션을 맺는다.
(e) 웹브라우저는 서버에 HTTP 요청을 보낸다.
(f) 서버는 웹브라우저에 HTTP 응답을 돌려준다.
(g) 커넥션이 닫히면, 웹브라우저는 문서를 보여준다
HTTP 메서드중 GET과 POST의 차이점에 대해 설명해주세요.
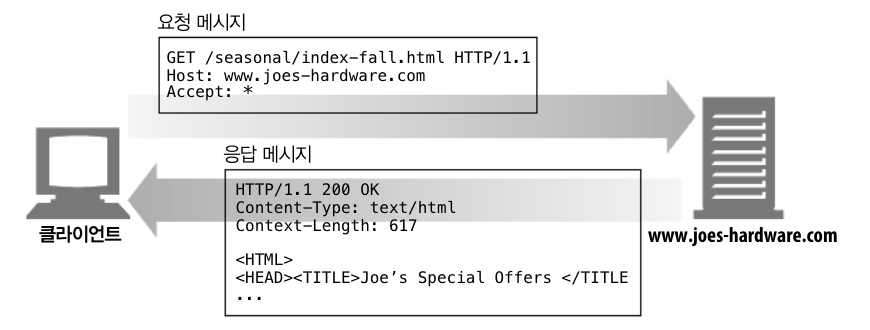
- GET은 가장 흔히 쓰이는 메서드로, 주로 서버에게 리소스를 달라고 요청하기 위해 쓰입니다.
HTTP/1.1은 서버가 해당 메서드를 구현할 것을 요구합니다.
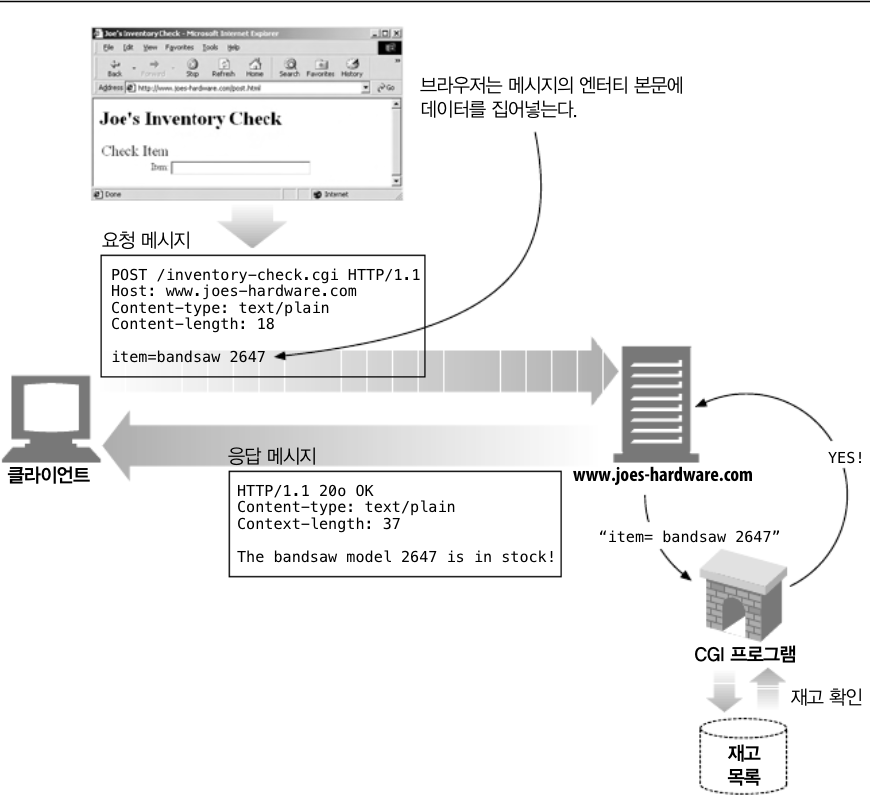
- POST는 서버에 입력 데이터를 전송하기 위해 설계되었습니다. 실제로 HTML Form을 지우너하기 위해서 흔히 사용되며, 폼에 담긴 데이터는 서버로 전송되며 서버는 이를 모아서 필요로 하는 곳에 보내게 됩니다.
간단한 method 요약!
HTTP 메서드중 PUT과 PATCH의 차이점에 대해 설명해주세요.
HTTP 메서드 중 PUT과 PATCH 둘다 리소스를 업데이트하는 데 사용되는 메서드입니다. 그 중에서
- PUT는 HTTP/1.1에서 정의 된 메서드로, GET method가 서버로부터 문서를 읽어 들이는데 반해
PUTmethod는 서버에 새로운 문서를 쓰거나 기존의 리소스를 대체하게 됩니다. 즉, 사용자가 PUT을 이용해 웹페이지를 만들고 웹 서버에 직접 게시할 수 있도록 해주는 method입니다. 이렇게 쓰는 과정을 통해서 서버가 요총의 본문을 가지고 요청 URL의 이름대로 새 문서를 만들거나, 이미 URL이 존재한다면 본문을 사용해서 교체하게 됩니다. 이러한 새로 고쳐쓰는 작업이기 때문에 기존의 웹에서는 이러한 작업 전에 비밀번호 인증 등의 과정을 거치게 됩니다. 이 과정에서 리소스에 있는 값에 대해서 같이 리소스에 대한 값을 넣어 주지 않으면 null값이 들어가게 됩니다.
PUT /users/123 HTTP/1.1
Host: example.com
Content-Type: application/json
{
"name": "홍길동",
"email": "hong@example.com"
}
- PATCH는 리소스의 일부만을 수정하는데 사용되는 메서드로써, 요청 본문에 있는 정보를 사용하여 지정된 URI()의 리소스 중 일부만을 변경합니다. 그렇기 때문에 기존의 리소스 중 일부의 정보만을 수정해도 조작하지 않은 나머지 값들이 null값으로 대체되지 않습니다.
PATCH /users/123 HTTP/1.1
Host: example.com
Content-Type: application/json
{
"email": "newhong@example.com"
}HTTP 상태 코드가 뭔가요? 알고 있는 상태 코드 몇가지 설명해주세요.
| HTTP STATEMENT CODE | DEFINITION |
|---|---|
| 200 OK | 좋다. 문서가 바르게 반환되었다. |
| 301 Moved Permenantly | 요청한 리소스에 대한 URI가 영구적으로 변경되었음을 나타냅니다. 클라이언트는 새 URI로 리다이렉션 됩니다. |
| 404 Not Found | 없음. 리소스를 찾을 수 없다. |
| 500 Internal Server Error | 서버에 오류가 발생하여 요청을 수행할 수 없음을 나타냅니다. |
모든 HTTP 응답 메세지는 상태 코드와 함께 반환됩니다. 상태 코드(Status Codes)는 클라이언트에게 요청이 성공했는지 아니면 추가 조치가 필요한지 알려주는 세자리 숫자를 말합니다. 또한, Reason Phrase가 같이 오는데 이는 오로지 설명을 위한 텍스트이고 실제적인 과정은 상태코드에 의해 이뤄집니다. 각 숫자의 첫 번째 자리는 상태 코드의 유형을 나타 냅니다.
- 1xx (정보) : 요청을 받았으며 프로세스를 계속 진행 중입니다.
- 2xx (성공) : 요청을 성공적으로 받았으며 이해했고 수용하였습니다.
- 3xx (리다이렉션) : 요청을 완료하기 위해 추가 작업을 수행해야 합니다.
- 4xx (클라이언트 오류) : 요청의 문법이 잘못되었거나 요청을 수행할 수 없습니다.
- 5xx (서버 오류) : 서버가 명백히 유효한 요청에 대해 충족시킬 수 없습니다.
200 OK
200 Document attached
200 Success
200 All's cool, dudeURI(Uniform Resource Identifier)
인너넷에서 자원을 고유하게 식별하고 위치를 지정하는 데 사용되는 문자열입니다. 이는 URL과 URN을 포괄하고 있습니다.
- URL : 이는 웹상에 자원이 어디에 위치하는 지를 알려주는 주소로, 웹사이트의 주소를 예로 들 수 있습니다.
- URN : 자원이 어디에 위치하고 있는지와는 상관없이 그 자원의 이름을 제공합니다. URN은 독립적인 자원 식별자로서, 그 자원이 어디에 위치하거나 어떻게 접근되는지에 관계없이 그것을 고유하게 식별할 수 있습니다. 예를들면 도서의 구분 번호인 ISBN을 들 수 있습니다.
HTTP 헤더가 뭘까요? 알고 있는 헤더 몇 가지 설명해주세요.
HTTP Header는 HTTP 요청 또는 응답에 포함된 필드로, 통신에 필요한 다양한 정보를 포합하고 있습니다. 각 헤더는 이름과 값의 쌍으로 구성되며 각각의 필드는 콜론으로 구분됩니다. 이러한 헤더는 더 일반 목적으로 사용할 수 있는 헤더와 응답과 요청 메세지 양쪽 모두에서 정보를 제공하는 헤더가 있습니다. 이는 크게 다섯 가지로 분류됩니다.
- General Header
General Header는 클라이언트와 서보 양쪽 모두가 사용하며, 어딘가에 메시지를 보내는 다른 애플리케이션들을 위해 다양한 목적으로 사용됩니다.
ex ) Date : Tue, 3 Oct 2023 10:10:00 GMT
위의 Date 헤더는 서버와 클라이언트를 가리지 않고 메시지가 만들어진 일시를 지칭하기 위해 사용되는 General Header 입니다.

General Cashed Header
HTTP/1.0은 HTTP 애플리케이션에게 매번 원 서버로 부터 객체를 가져오는 대신 로컬 복사본으로 캐시할 수 있도록 해주는 최초의 헤더를 도입 했습니다. 최신 버전의 HTTP는 매우 풍부한 캐시 매개 변수의 집합을 가지고 있습니다.

-
Request Header
이름에서 드러나는 것과 같이, 요청 메시지를 위한 헤더 입니다. 서버에게 클라이언트가 받고자 하는 데이터의 타입이 무엇인지와 같은 부가 정보를 제공합니다. 즉, 요청이 최초 발생한 곳에서 누가 혹은 무엇이 그 용청을 보냈는지에 대한 정보나 클라이언트의 선호나 능력에 대한 정보를 줍니다.
ex ) Accept : /
위의 Accept Header는 서버에게 클라이언트가 장신의 요쳉에 대응하는 어던 미디어 타입도 받아 들일 것임을 의미합니다.
- Accept connection Headers
클라이언트는 Accept 관련 헤더들을 이용해 서버에게 자신의 선호와 능력을 알려줄 수 있습니다. 그후 서버는 추가 정보를 활용해 무엇을 보낼 것인가에 대해 더 좋은 결정을 내릴 수 있습니다.
- Conditional Request Header
클라이언트는 요청에 몇몇 제약을 넣기도 합니다. 이를 위해서 사용하는 헤더 입니다.
- Request security Header
HTTP는 자체적으로 요청을 위한 간단한 인증요구/응답 체계를 갖고 있습니다.그것을 요청하는 클라이언트가 어느 정도의 리소스에 접근하기 전에 자시을 인증하게 함으로써 트랜잭션을 약간 더 안전하게 만듭니다.
- Proxi Request Header




-
Response Header
응답 메시지는 클라이언트에게 정보를 제공하기 위한 자신만의 헤더를 갖고 있습니다.
ex ) Server : Tiki-Hut/1.0
위의 Server Header는 클라이언트에게 그가 Tiki-Hut서버 1.0과 대화하고 있음을 말해줍니다.
-
Entity Header
Entity Header is header in Entity main context.
ex ) Context-type : text/html; charset = iso-latin-1
엔터티 헤더는 엔터티 본문에 들어 있는 데이터 타입이 무엇인지 말해줄 수 있습니다. 그 특성을 이용해서 Context-type 헤더는 데이터가 iso-latin-1 문자 집합으로 된 hmtl 문서 임을 알려줍니다. -
Extension Header
확장 헤더는 애플리케이션 개발자들에 의해 만들어져 아직 승인된 HTTP 명세에는 추가되지 않은 비표준 헤더 입니다.
- HTTP의 무상태성(Stateless)에 대해서 설명해주세요.
HTTP Keep-Alive에 대해서 설명해주세요.
Keep-alive라는 것은 웹 클라이언트에서 연결한 커넥션 중 지속 커넥션을 지원하기 위해서 확장된 개념으로 HTTP/1.1 부터 본격적으로 사용되어 TCP 연결을 재사용하여 응답 시간을 최소화 했습니다.
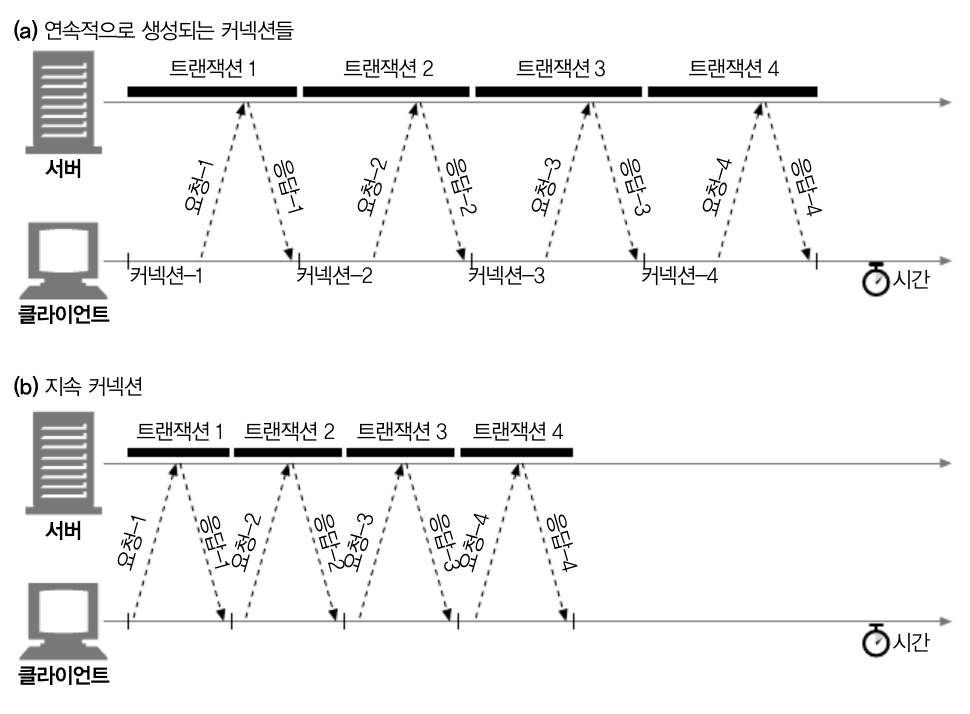
이러한 Keep-alive 커넥션은 요청 메세지에 Connection : Keep-alive라는 메세지를 서버에서 받으면 그에 응하는 응답을 받으며 동작합니다.
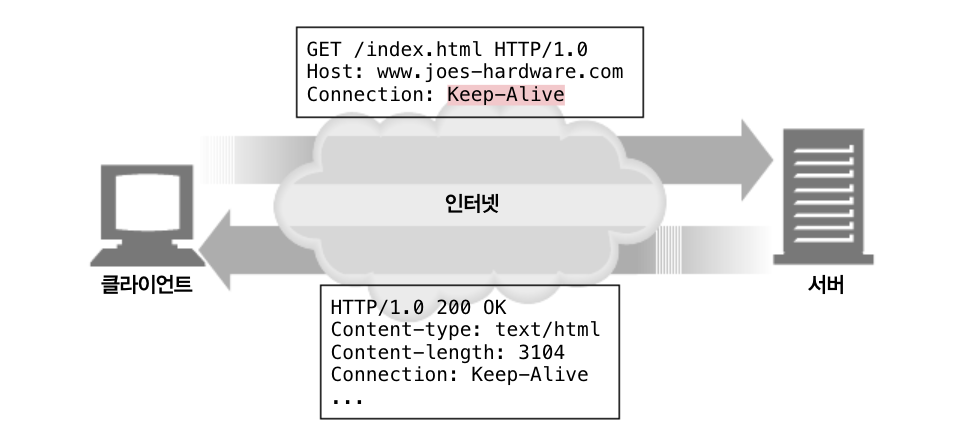
이러한 헤더는 해당 커넥션을 유지하기를 바라는 요청일 뿐이기 때문에 언제든지 keep-alive connection을 끊을 수 있으며, 해당 커넥션에서 처리되는 Transaction의 수를 제한 할 수 도 있습니다.
Connection: Keep-alive
Keep-alive: max = 5, timeout = 120위의 http 코드에에서 max는 몇개의 HTTP Transaction을 처리할 동안 해당 커넥션을 유지할지를 결정하기 위한 파라미터이고, timeout은 커넥션의 유지 시간을 의미하는 파라미터 입니다. 마지막으로, Keep-alive header는 진단이나 디버깅을 주목적으로 하는, 처리되지는 않는 임의의 속성을 지원하기도 합니다. 그 문법은 Name[=value]와 같은 식입니다.
Header의 사용은 자유지만 사용을 하고 싶으면 Connection : Keep-alive 헤더가 존재해야 합니다.
🚨 KEEP-ALIVE 커넥션 제한과 규칙
- keep-alive는 HTTP/1.0에서 기본으로 사용되지는 않는다.
- 커넥션을 계속 유지하려면 모든 메시지에 Connection : Keep-alive header를 호함해 보내야한다.
- 클라이언트는 Conenction : Keep-alive 응답 헤더가 없는 것을 보고 서버가 응답 후에 커넥션을 끊을 것임을 알 수 있다.
- 커넥션이 끊어지기 전에 엔터티 본문의 길이를 알 수 있어야 커넥션을 유지 할 수 있다.
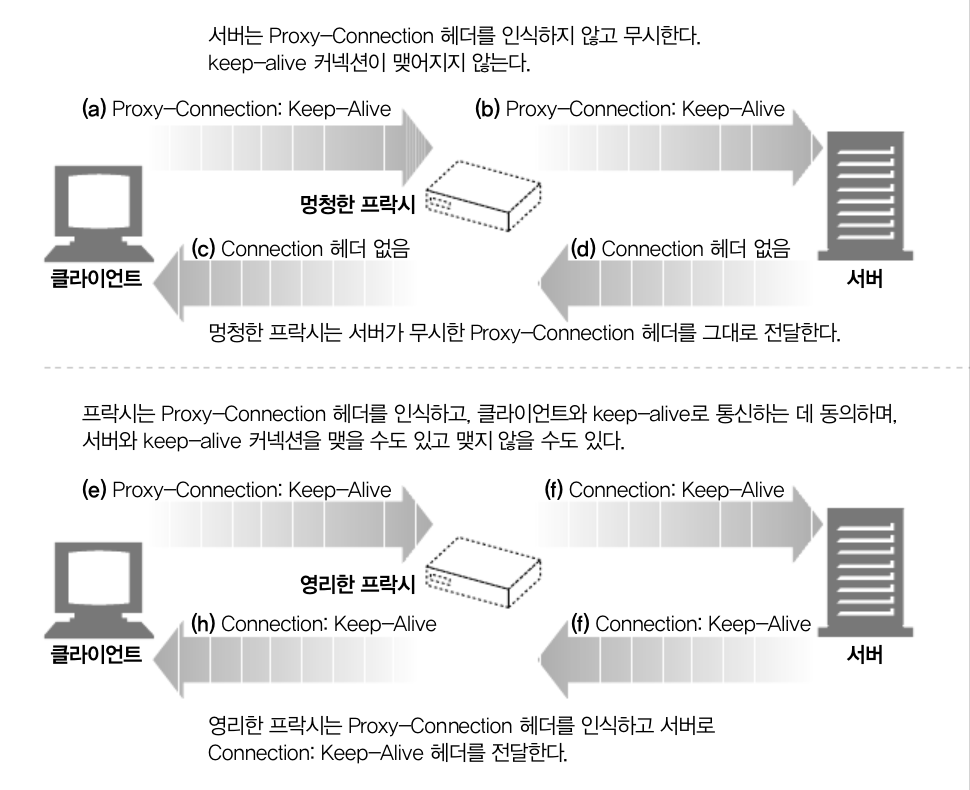
- 프락시와 게이트웨이는 Connection header의 규칙을 철저히 지켜야 한다.
- Keep-alive 커넥션은 Connection Heade를 인식하지 못하는 프락시 서버와는 맺어지면 안된다.(위 같은 프락시 서버를 Dumb proxy server, 라고 한다.)
- 기술적으로 HTTP/1.0을 따르는 기긱로부터 받는 모든 Connection 헤더 필드는 무시해야 한다.
- 크라이언트는, 응답 전체를 모두 받기 전에 커넥션이 끊어졌을 경우, 별다른 문제가 없으면 요청을 다시 보낼 수 있게 준비되어 있어야 한다.
HTTP 파이프라이닝에 대해서 설명해주세요.
HTTP 1.1 버전에서 도입된 파이프라이닝은 Keep-Alive를 확장한 개념입니다. Keep-Alive가 여러 요청을 순차적으로 전송하는 것이라면, 파이프라이닝은 여러 요청을 동시에 전송하는 것입니다. Keep-Alive와 파이프라이닝 모두 HTTP 연결의 재사용을 통해 통신의 효율성을 높이는 방법이지만, Keep-Alive는 연결을 유지하면서 순차적으로 요청을 처리하고, 파이프라이닝은 여러 요청을 동시에 처리하는 방식의 차이가 있습니다.
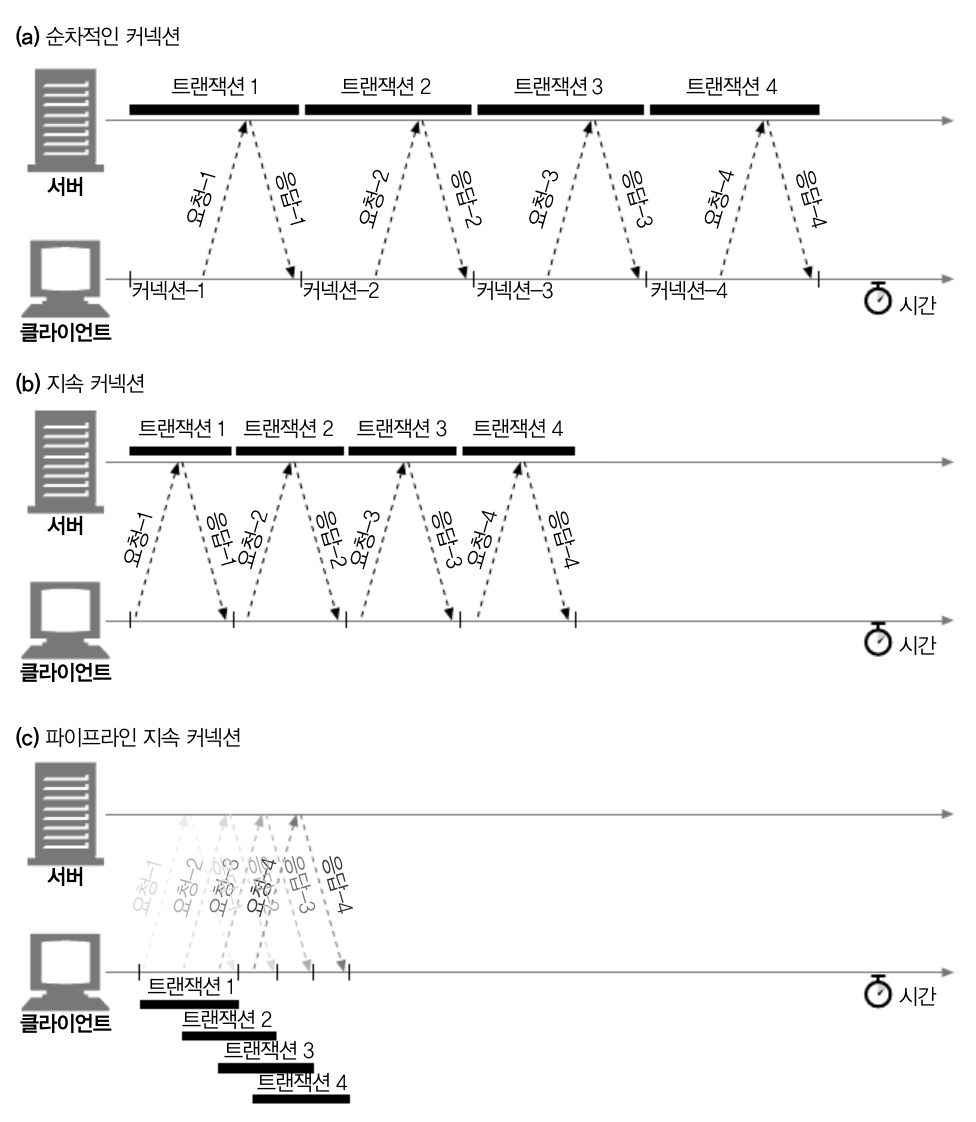
🚨 How is it going to be if we got misconnected Connection on Pipelined Connection and use Method except POST?
- idempotent : 한 번 혹은 여러 번 실행됐는지에 상관없이 같은 결과를 반환하는 것 그때의 Transaction을 idempotent하다고 합니다. 이에 예시는 GET, PUT, DELETE, TRACE, OPTIONS 와 같은 Method를 예시로 들 수 있습니다.
Idempotent하지 않은 method를 가진 request는 파이프라인을 통해서 하면 안됩니다. 그럴 경우 예상치 못하게 커넥션이 끊어졌을 때, 알 수 없는 결과를 발생 시킬 수 도 있습니다. 그리고 도중에 연결이 끊어 질 경우 요청에 대한 업데이트가 안되기 떄문에 그 중에 일어나는 데이터 손실을 알 수 없기 때문에 현재는 잘 사용되지 않습니다. 이러한 문제를 HTTP/2.0의 멀티 플렉싱을 통해 해결했습니다.
HTTP/1.1, HTTP/2, HTTP/3 각각의 특징에 대해 설명해주세요.
오늘날의 쓰이고 있는 HTTP Protocol의 버전은 여러가지가 있습니다. 그 중의 세가지 프로토콜에 대해서 말씀드리겠습니다.
-
HTTP/1.1
본래HTTP/1.0은 매 요청마다 새로운 TCP 연결을 생성했습니다. 이는 많은 네트워크 리소스를 소모하며 웹의 로딩 시간을 지연시키는 요인이 되었습니다. 이러한 문제를 해결하기 위해HTTP/1.1에서는 Persistent Connection(지속적인 연결)을 통해서 하나의 TCP를 통해서 요청을 순차적으로 처리하게 만들었습니다. -
HTTP/2.0
기존의 HTTP/1.1에서 순차적인 요청 처리 방식의 제약을 해결하기 위해서Multiplexing기능이 도입되었습니다. 이는 단일 연결에서 여러 요청과 응답을 동시에 처리하는 기능으로, 이를 통해 웹 페이지의 로딩 시간을 크게 줄일 수 있습니다. -
HTTP/3.0
HTTP/2.0에도 불구하고, TCP 기반의 HTTP 네트워크 지연과 패킷 손실에 취약했습니다. 특히, 불안정한 네트워크 환결에서는 TCP 연결 설정과 복구가 많은 시간을 소모하는 것은 TCP 대신 UDP 기반의 QUIC 프로토콜을 사용합니다.
💡 QUIC Protocol란
구글이 개발한 신형 전송 프로토콜로써, 기존의 TCP와 비교하여 성능 향상을 목표로 하며, 이를 위에 UDP 기반 HTTP/3.을 사용합니다. 주요한 특징은 아래와 같습니다.
- 연결 설정 시간 줄임 : TCP는 연결을 시작할 떄, 3-wayhandshake 과정을 거치는데, 이 과정은 데이터 전송을 시작하기 전에 latency(지연시간)을 추가합니다. 반면 QUIC는 처음 연결 설정 시 0-RTT(왕복 시간 없음) 또는 최대 1-RTT만에 연결을 설정할 수 있습니다.
- 멀티플렉싱 및 헤더 압축 : 여러 개의 데이터 스트림을 하나의 연결로 합쳐 전송하는 멀티 플렉싱을 도입하여 헤더 정보를 압축하여 전송 효율을 높이는데 이용합니다.
- 보안 기능 내장 : TLS(Transport Layer Security)를 사용하여 데이터를 암호화 합니다. (암호화를 하는 방법은 대칭키 암호화와 비대칭키 암호화 방식을 모두 사용합니다.)
- 오류 복구 및 혼잡 제어 : 패킷 손실 시 복구를 위한 메커니즘과 네트워크 혼잡 상화에서의 데이터 전송을 제어하는 기능을 제공합니다.
📌 HTTPS
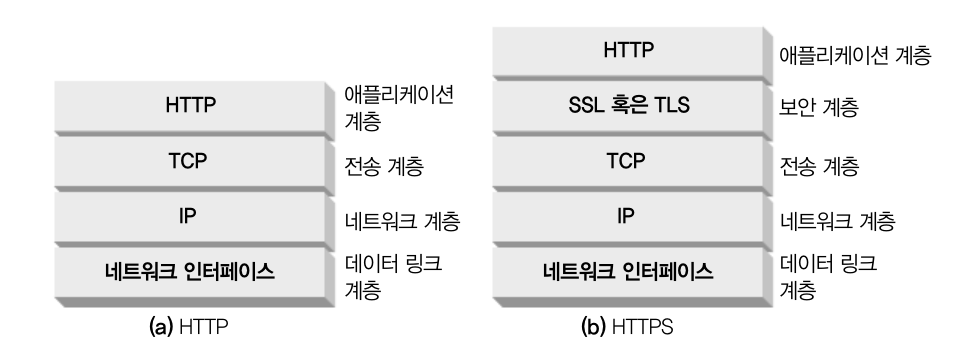
HTTPS에 대해서 설명해주세요.
HTTPS란 HTTP의 보안화된 버전으로 우리가 중요한 업무 등을 처리 하기 위해서 웹 트랜젝션을 사용하는데 이러한 Transaction에 대한 접근을 제한하기 위해서 개발이 되었습니다. HTTP는 서버 인증, 클라이언트 인증, 무결성, 암호화, 효율, 편재성, 관리상 확장성, 적응성, 사회적 생존성에 대한 조건을 만족한 모델이라고 할 수 있습니다. HTTP와 HTTPS 간의

SSL/TLS이 뭔가요?
HTTPS를 사용할 떄, 모든 HTTP 요청과 응답 데이터는 네트워크로 보내지기 전에 암호화 됩니다. 이는 HTTPS protocol에서 HTTP 하위의 보안 계층이 있음으로써 암호화가 동작하는데 이 보안 계층은 SSL(Secure Sokets Layer) 혹은 그를 계승한 TLS(Transport Layer Security)이 있습니다. 즉 데이터를 암호화하는 프로토콜이라고 이해할 수 있습니다.
대칭키 암호화 방식에 대해 설명해주세요.
대칭키 암호화 방식은 인코딩과 디코딩에 같은 키를 사용하는 알고리즘입니다.
비대칭키(공개키) 암호화 방식에 대해서 설명해주세요.
공개키 암호화 방식은 인코딩과 디코딜에 다른 키를 사용하는 알고리즘입니다. 공개키 암호법이라는 것이 존재하는데, 이는 비밀 메시지를 전달하는 수백만 대의 컴퓨터를 쉽게 만들 수 있는 시스템을 말합니다.
전자 서명에 대해서 설명해주세요.
디지털 서명이란 메시지가 위조 혹은 변조되지 않았음을 입증하는 체크섬입니다.
What is the Checksum?
데이터의 무결성을 검사하기 위해 사용되는 간단한 방법입니다. checksum을 데이터와 같이 보내서 데이터의 오류 여부를 판단하기 위해서 전송 혹은 저장합니다. 이를 통해서 파일 전송, 소프트웨어 배포, 데이터베이스, 네트워크 통신, 디지털 포렌식을 함에 있어 데이터의 무결성을 보장하는데 사용이 됩니다.
Checksum은 원본 데이터를 일정한 방식으로 계산하여 얻은 일련의 숫자(또는 해시 값)을 의미하고, 수신 측에서 동일한 방식으로 체크섬을 계산 후 전송된 체크섬과 비교하여 무결성을 확인 합니다. 다른 암호화 방식에 비해서 간단하고 구현이 쉽다는 장점이 있지만, 해당 보안 알고리즘은 단순 오류 감지 기능만을 가지고 있어, 고의적인 데이터 변조를 방지하거나 오류를 수정하는 기능은 없기 때문에 이러한 고급 기능이 필요한 경우에는 해시 함수, 디지털 서명 등을 사용합니다.HTTPS 암호화 과정에 대해 설명해주세요. (SSL Handshake의 동작 과정을 설명해 주세요.)
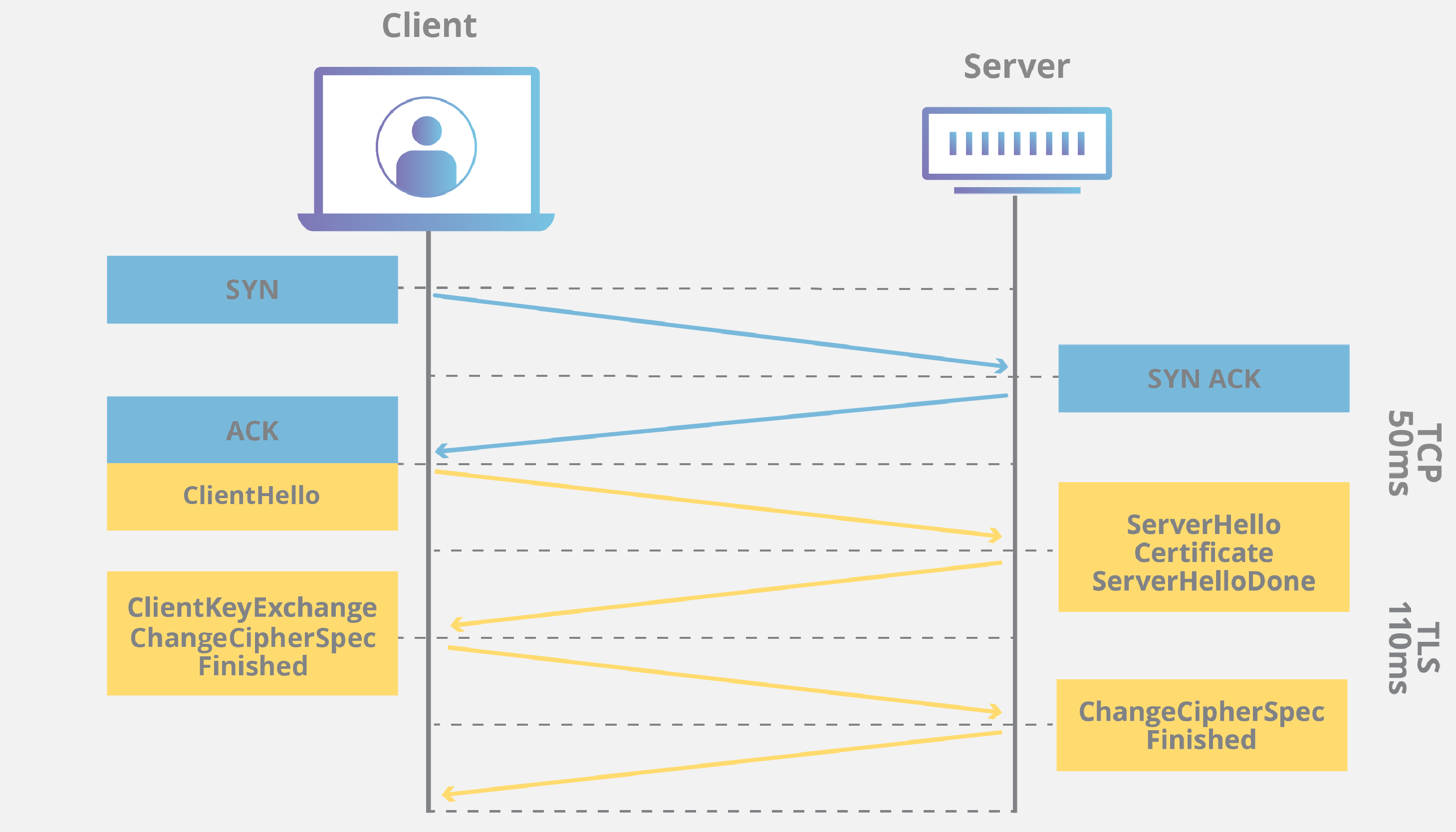
TLS HandShake는 사용자가 HTTPS를 통해 웹 사이트를 탐색하고 브라우저가 처음 해당 웹사이트의 원본 서버를 쿼리하기 시작할 때마다 발생합니다. 다른 통신이 API 호출 및 HTTPS를 통한 DNS 쿼리를 포함하는 HTTPS를 사용할 때에도 매번 TLS 핸드셰이크가 발생합니다. 이러한 TLS Handshake는 HTTPS 작동 원리에 기인하여 동작하기 때문에 TCP 3-way handshake 이후에 진행이 됩니다.
Origin Server & API CALL & DNS QUERY THROUGH HTTPS
ORIGIN SERVER
원본 서버는 인터넷 클라이언트(브라우저)로 부터 들어오는 요청에 대한 응답을 하고 처리하기 위한 것 입니다. 원본 서버는 엣지 서버와 캐싱 서버의 개념을 합쳐 만들어져 기본적으로 들어오는 인터넷 요청들을 수신하고 처리하도록 설계된 하나 이상의 프로그램을 실행하는 컴퓨터라고 할 수 있습니다.CDN EDGE SERVER
CDN EDGE SERVER는 logical extreme or edge of a network에 존재하는 컴퓨터로서, 주로 분리된 네트워크 간의 연결을 제공하는 역할을 합니다. 즉, 특정 네트워크 계층에서 다양한 장치들이 사전에 정의가 된 네트워크 패턴을 사용해서 연결하게 될 것입니다. 이때 네트워크 간의 혹은 더 큰 네트워크로 연결을 해야 할 때 트래픽이 상호간의 흐르게 하기 위해 다리 역할을 하게 됩니다.EDGE
edge는 컴퓨팅의 시점과 네트워크에서 보는 의미가 다르게 됩니다. 컴퓨팅에서 edge는 지연시간과 대역폭의 사용을 최대한 줄이기 위해서 리소스에 가깝게 접근하여 계산을 하는 것에 집중하는 네트워킹 방식을 의미하고 네트워크에서 edge 는 물리적으로 디바이스 혹은 지역 네트워크의 양 끝단 즉 각 장치들을 의미합니다.

TLS HandShake 중 발생하는 일!
- 사용할 TLS VERSION을 지정합니다.
- 사용할 암호 제품군을 결정합니다.
- 서버의 공개 키와 SSL 인증서 기관의 디지털 서명을 통해 서버의 ID를 인증합니다.
- 핸트셰이크가 완료된 후에 대칭 암호화를 사용하기 위하여 세션 키를 생성합니다.
How exactly does TLS Handshake works?
| Orders | Client to Server | Server to Client |
|---|---|---|
| 1 | Client Hello | |
| 2 | Server Hello | |
| 3 | Authentication | |
| 4 | Send to a random String, called Sub-Master Password,to server | |
| 5 | Decoding that String with private(shared) key | |
| 6 | Build Session key | Build Session key |
| 7 | Send a message that it's ready to Server by Session | |
| 8 | Send a message that it's ready to Client by Session | |
| 9 | Continue to do over their steps |
-
Client Hello : 클라이언트가 서버로 "HELLO" 메시지를 전송하면서 핸드셰이크를 개시합니다. 이 메시지에는 클라이언트가 지원하는 TLS 버전, 지원되는 암호 제품군, 그리고 "클라이언트 무작위"라고 하는 무작위 바이트 문자열이 포함됩니다.
-
Server Hello : 클라이언트 헬로 메시지에 대한 응답으로 서버가 서버의 SSL 인증서, 서버에서 선택한 암호 제품군, 그리고 서버에서 생성한 또 다른 무작위 바이트 문자열인 "서버 무작위"를 포함하는 메시지를 전송합니다.
-
Authentication : 클라이언트가 서버의 SSL 인증서를 인증서 발행 기관을 통해 검증합니다. 이를 통해 서버가 인증서에 명시된 서버인지, 그리고 클라이언트가 상호작용 중인 서버가 실제 해당 도메인의 소유자인지를 확인합니다.
-
Sub-Master Password : 클라이언트가 "예비 마스터 암호"라고 하는 무작위 바이트 문자열을 하나 더 전송합니다. 예비 마스터 암호는 공개 키로 암호화되어 있으며, 서버가 개인 키로만 해독할 수 있습니다.(클라이언트는 서버의 SSL 인증서를 통해 공개 키를 받습니다.)
-
개인 키 사용: 서버가 예비 마스터 암호를 해독합니다.
-
세션 키 생성 : 클라이언트와 서버가 모두 클라이언트 무작위, 서버 무작위, 예비 마스터 암호를 이용해 세션 키를 생성합니다. 모두 같은 결과가 나와야 합니다.
-
클라이언트 준비 완료 : 클라이언트가 세션 키로 암호화된 "완료" 메시지를 전송합니다.
-
서버 준비 완료 : 서버가 세션 키로 암호화된 "완료" 메시지를 전송합니다.
-
안전한 대칭 암호화 성공 : 핸드셰이크가 완료되고, 세션 키를 이용해 통신이 계속 진행됩니다.
📌 DNS
DNS가 뭔가요?
DNS는 Domain Name System의 약어로, 인터넷에서의 하나의 전화번호부와 같다고 할 수 있습니다. 우리가 전화번호를 알면 전화를 걸 수 있듯이 우리가 접근하고 싶은 웹사이트의 도메인을 알고 검색을 하면 해당 도메인이 IP Ads로 변환되어 해당 웹의 리소스를 로드하게 됩니다.
DNS 작동 방식에 대해 설명해주세요.
우선 IP라는 것이 각 장치의 인터넷에 주어지는 것이라고 생각할 수 있습니다. 이러한 IP 주소를 DOMAIN이라는 것을 입력 받으면 IP 주소로 변환되어 해당 주소와 일치하는 것을 찾아 리소스를 로드하여 사용자에게 보여주게 됩니다.
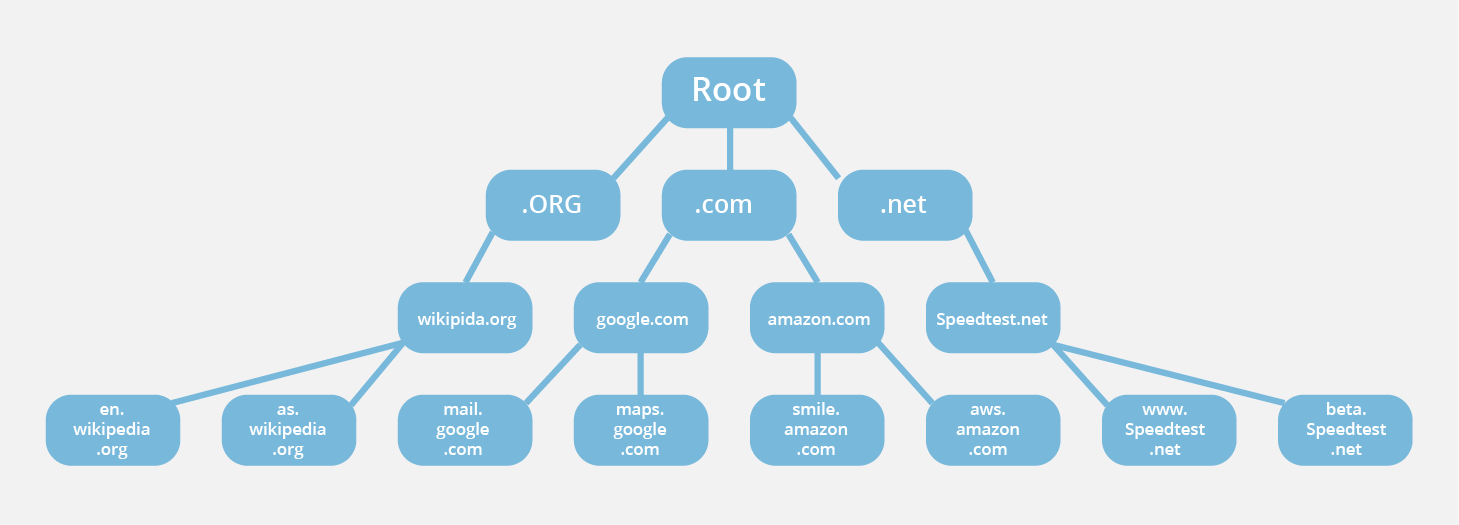
The structure of Domain
통상적으로 도메인의 가장 끝에 있는 점(.)은 생략하고, 이것은 Root Domain이라고 부릅니다. Root Domain의 하위를 Top-level 도메인이라고 부르며 그에는com, net,co.kr등이 있습니다. Top-level 도메인 직속 하위 도메인은 Second-level Domain이라고 부르며 그 직속 하위 도메인을 Sub Domain이라고 부릅니다.🚨 Rule in DNS
- 직속 하위 레벨의 DNS 서버 리스트를 알고 있어야 한다.
- 모든 컴퓨터는 적어도 Root Domain's DNS server를 알고 있어야 합니다.
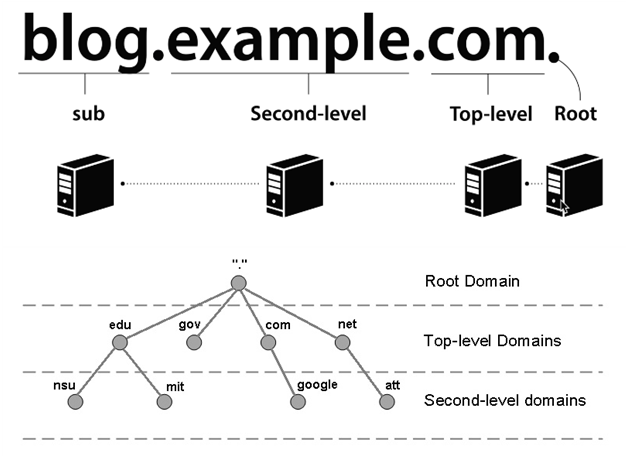
웹 로드와 관련된 4개의 DNS 서버
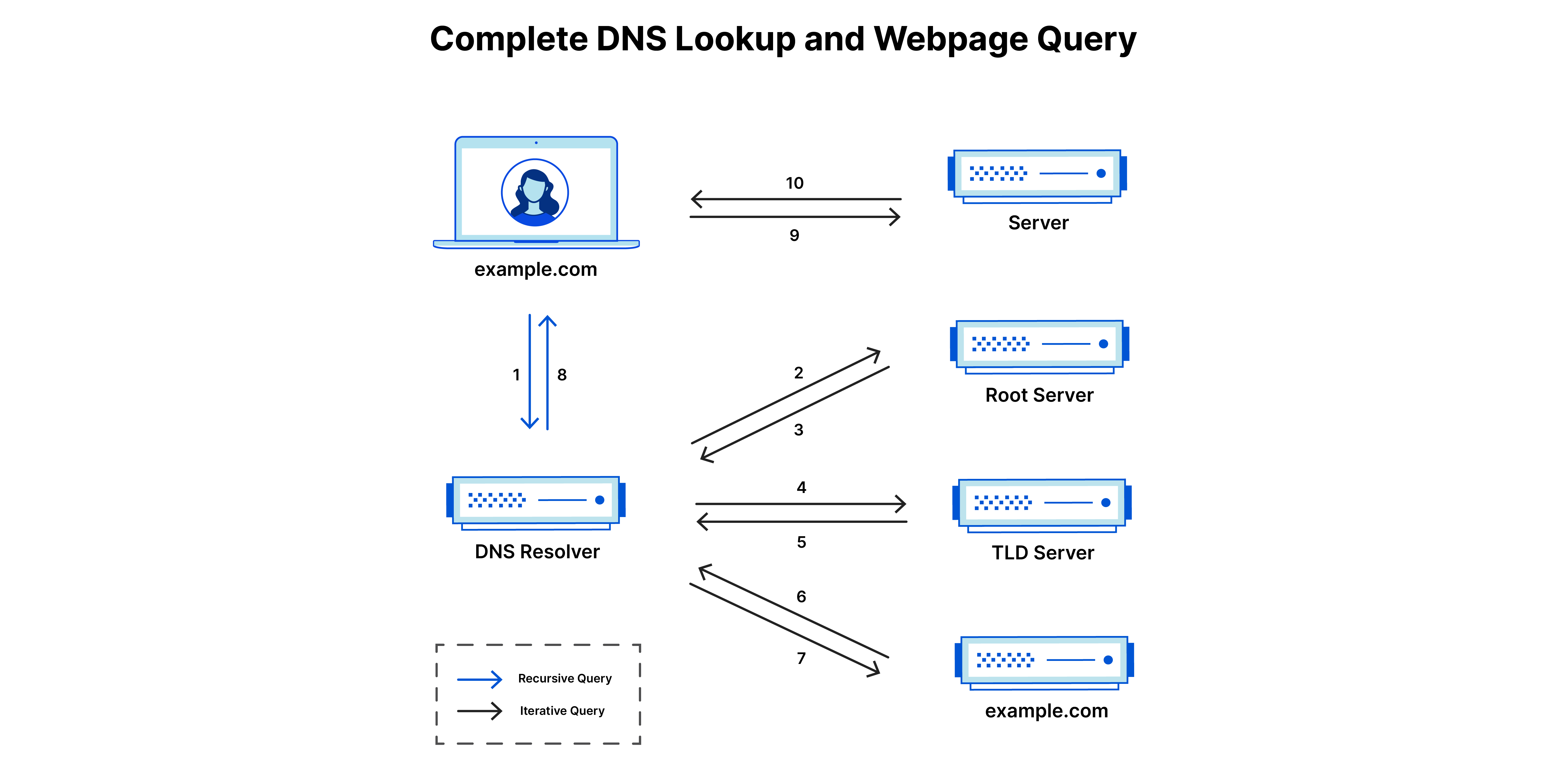
모든 DNS SERVER는 4가지 카테고리 중 하나에 속합니다.(All DNS servers fall into one of four categories.) 이러한 DNS Server는 최종적으로 특정 도메인에 대한 IP 주소를 클라이언트로 전송할때까지 같이 동작을 합니다. 그러한 Server의 종류는 아래와 같습니다.
1. DNS Recursive Resolver
DNS Recursive Resolver는 DNS Query에서 가장 첫번째 단계입니다. 해당 Resolver는 클라이언트와 DNS nameserver사이에서 중간 다리 역할을 하며, Web으로 부터 쿼리를 받고 난 후에는 캐시 데이터와 함께 응답을 하거나 Root nameserver로 요청을 보내고 TLD nameserver로 또 다른 요청에 대한 것을 보냅니다. 그리고 마지막 요청은 Authoritative nameserver로 보내게 됩니다.(총 세개의 쿼리 동시에 처리) 요청된 IP 주소를 포함하여 Authoritative Server로 부터 응답을 받은 후, DNS Recursive Resolver은 클라이언트로 응답을 보냅니다.
해당 처리 과정동안, Recursive solver는 cashed infos를 AN(Authoritative nameserver)로 부터 받고 클라이언트가 최근에 다른 클라이언트에서 요청 받은 도메인의 IP 주소를 요청할때 Resolver가 네임서버와의 통신 프로세스를 우회(circumvent)하고 캐시에서 요청한 레코드를 클라이언트에게 전달할 수 있습니다.
2. DNS Root nameserver
DNS Root nameserver는 Recursive Resolver의 도메인 이름을 포함한 쿼리를 받고 같이 온 도메인의 확장자를 기반으로하여 Recursive Resolver를 TLD nameserver에 반응하게 만듭니다. 해당 nameserver는 13가지 유형이 존재하며, 각각의 여러개의 복사본이 존재합니다. 그리고 Root nameserver는 Root zone안에서 저장되거나 캐시화 된 레코드들을 이용해서 쿼리에 응답을 합니다.
3. TLD nameserver
TLD nameserver는 .com, .net 과 같은 공통된 확장 도메인 이름들의 정보를 유지하고 저장합니다. 만약 사용자가 example.com을 검색했을 경우, Root nameserver의 응답을 받은 후 Recursive Resolver가 .com TLD nameserver로 쿼리를 보낼 것입니다. 그러면 TLD nameserver는 해당 도메인을 AN을 가리킴으로써 응답합니다.
- Generica top-level domains : .com, .org, .net ...
- Country code top-level domains : .uk, .us, .ru, .kr ...
4. Authoritative nameserver
RR이 TLD 네임서버로 부터 응답을 받으면, 해당 응답은 바로 AN으로 향하게 됩니다. Authoritativa nameserver는 마지막 IP 주소의 여행의 마지막 과정입니다. AN은 가지고 있던 특정 도메인에 대한 정보를 유지하고 RR에게 DNS A record 혹은 다른 레코드 안에서 그 서버의 IP 주소를 찾을 수 있도록 정보를 제공합니다.

Recursive DNS resolver & Authoritative DNS Server & DNS resolver
Recursive resolver는 클라이언트로 부터 오는 회귀 요청에 응답하고 DNS record를 추적하는데 걸리는 시간을 컴퓨터 입니다. 일단 해당 resolver는 요청한 레코드에 대해 연속적인 요청을Authoritative DNS nameserver로 닿을때까지 만듭니다. 해당 작업은 cashing(Cashing은 DNS 요약에서 초기에 요청된 리소스 레코드를 전달함으로써 필수적인 요청들을 단락시키는데 도움을 주는 영속적인 데이터 프로세스입니다.)을 통해서 해당 작업을 필수적인 작업을 처리하여 수고스러움을 덜어줍니다!Authoritative DNS Server는 단순하게 DNS 리소스 레코드들을 보관하고 책임지는 장치입니다.
DNS resolver는 DNS 요약에서 가장 처음 과정으로, 클라이언트에서 만든 초기의 요청을 다루는 것을 책임지는 장치를 말합니다.
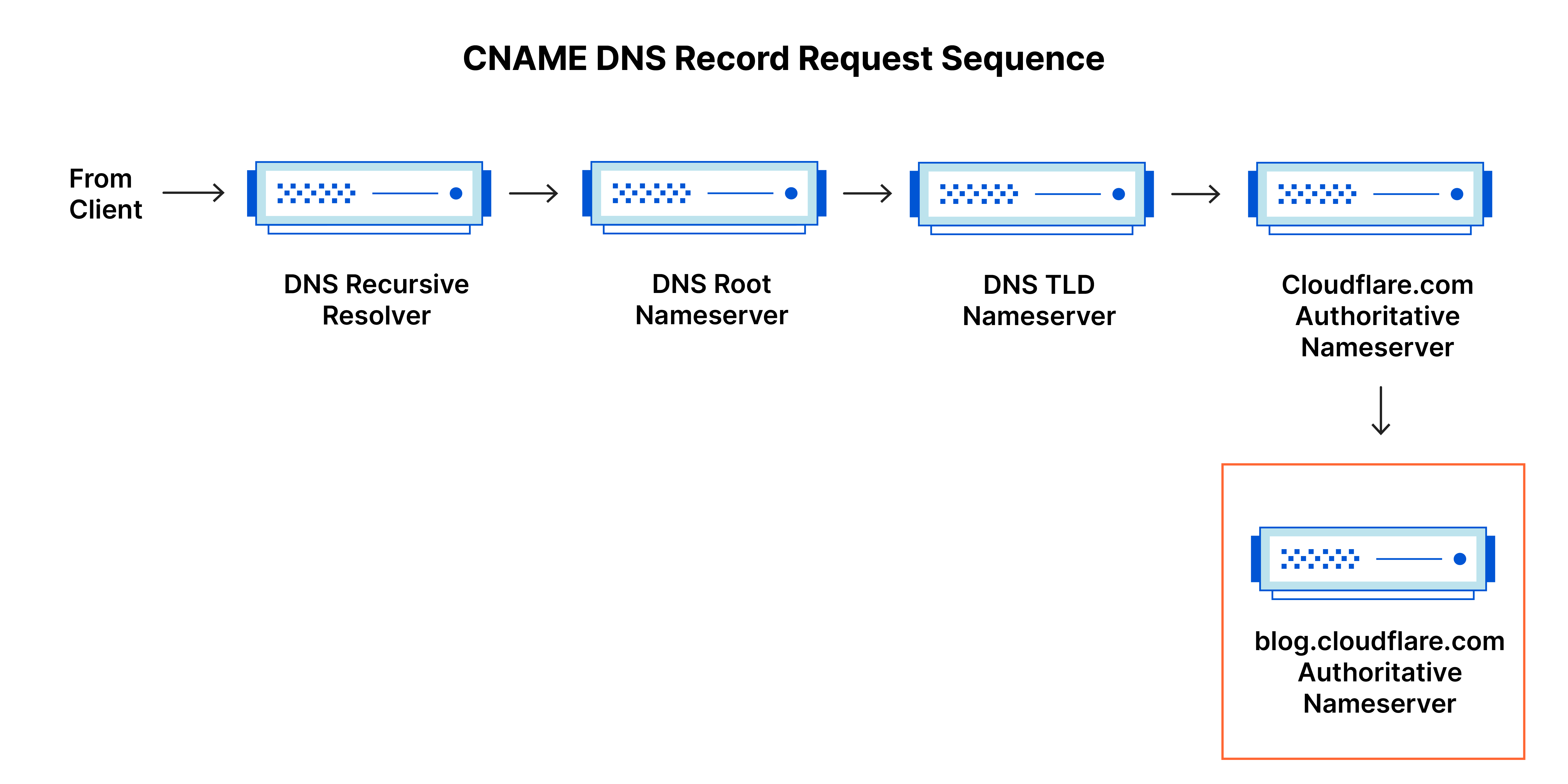

DNS 질의 종류에 대해 설명해주세요.
DNS Query Message는 Client가 DNS Server로 전송하는 요청 메시지를 말합니다. 이때, Client에서 DNS 서버로 부터 특정 유형의 DNS record에 대한 정보를 요청합니다.
이러한 질의 중 자주 쓰이는 것들에 대해서 알아 보겠습니다.
| Common type query message(record) | definition |
|---|---|
| A | 도메인의 IP(IPv4) 주소를 가지고 있는 레코드이다. |
| AAAA | 도메인에 대한 IPv6 주소를 포함하고 있는 레코드이다. |
| CNAME | 앞선 혹은 또 다른 도메인을 향한 서브로 도메인으로, IP주소를 가지고 있지 않는다. |
| MX | 이메일 서버로 메일을 보냅니다. |
| TXT | 관리자가 레코드 안의 텍스트를 저장하게 합니다. 이러한 레코드들은 이메일의 보안을 위해서 주로 사용됩니다. |
| NS | DNS 항목에 대한 네임 서버를 저장합니다. |
| SOA | 도메인에 대한 관리자 정보를 저장합니다. |
| SRV | 특정 서비스에 대한 포트를 지정합니다. |
| PTR | 도메인 네임의 반대 요약 과정을 제공합니다. |

💡 DNS QUERY란?
DNS Lookup에서 세 종류의 쿼리가 발행되는 것을 알수 있습니다. 이러한 쿼리들을 사용해서 DNS의 해상도를 위한 최적화된 과정은 이동 거리의 감소를 도출할 수 있습니다. 즉, 효율적으로 데이터를 전송가능하게 만듭니다!
3 types of DNS queries
Recursive Query : DNS 클라이언트가 DNS recursive resolver에게 요청된 리소드 레코드 혹은 레코드를 찾지 못했을 때 발생하는 에러 메시지에 대하여 응답하게 합니다.
Iterative Query : 해당 쿼리에서는 DNS client는 DNS 서버가 도출할 수 있는 최고의 결과를 반환하게 합니다. 만약 쿼리된 DNS Server에 맞는 query name이 없는 경우, 더 낮은 레벨의 도메인 네임 영역인 Authoritative DNS Server로 참조(referral)를 반환합니다. 그러면 DNS client는 참조하는 주소에 쿼리를 만듭니다. 해당 과정은 계속 추가적인 DNS Servers를 오류나 시간초과가 발생할때까지 쿼리 체인을 사용하게 합니다.
Non-recursive Query : 일반적으로 이는 DNS resolver 클라이언트가 레코드에 대한 권한이 있거나 레코드가 캐시 내부에 존재하기 때문에 액세스할 수 있는 레코드에 대해 DNS 서버를 쿼리할 때 발생합니다.(typically this will occur when a DNS resolver client queries a DNS server for a record that it has access to either because it's authoritative for the record or the record exists inside of its cache.)
DNS 서버에게 IP 주소를 요청할 때, 왜 UDP를 사용하나요?
DNS는 신뢰성보다 속도가 더 중요하고, 많은 클라이언트를 수용하는 것을 필요로 합니다. 따라서 속도가 빠르고, 연결 상태를 유지하지 않고 정보 기록을 최소화하여 많은 클라이언트 수용이 가능한 UDP를 사용합니다. 하지만 이러한 상황에서 중간에 정보가 하이재킹 당하는 등 보안에 위험이 생길 수 있는 문제를 DNS over OLS and DNS over HTTPS, 즉 DNS에 각종 암호화 기법을 결합하여 이와 같은 문제를 해결하는 시도를 합니다.
DNS 레코드가 무엇인가요?
DNS 서버는 데이터베이스 서버의 한 유형이며, 클라이언트로부터 질의를 받았을 떄 그에 맞는 데이터를 응답 해야합니다. 데이터베이스의 한 항목을 DNS 서버에서는 리소스 레코드라고 부르고, DNS 시스템에서 데이터를 표현할때 쓰이는 말입니다.
references
1. HTTP definition
2. HTTP method
3. The whole bundch of comprehension on DNS
