최적화
자동미분
텐서플로의 자동 미분
- tf.GradientTape
tf.GradientTape 는 컨텍스트 안에서 실행된 모든 연산을 테이프에 기록
그 다음 텐서플로는 후진 방식 자동 미분을 사용해 테이프에 기록된 연산의 gradient를 계산
x=tf.Variable(3.0) #x는 constant가 아니고 variable
with tf.GradientTape() as tape:
y=x**2dy_dx=tape.gradient(y,x)
dy_dx.numpy()- scalar를 vector로 미분
w= tf.Variable(tf.random.normal((3,2)),name='w')
b=tf.Variable(tf.zeros(2,dtype=tf.float32),name='b')
x=[[1.,2.,3.]]
with tf.GradientTape(persistent=True) as tape:
y=x@w+b
loss=tf.reduce_mean(y**2)
[dl_dw,dl_db]=tape.gradient(loss,[w,b])
[dl_dw,dl_db]- 자동 미분 컨트롤 하기
-tf.Variable만 기록- A variable + tensor 는 tensor 반환
trainable조건으로 미분 기록을 제어
- 기록되고 있는 variable 확인하기
watched_variables()
Linear regression(1)
- 구현하기
가상 데이터 셋
import matplotlib.pyplot as plt
tf.random.set_seed(777)
W_true=3.0
B_true=2.0
x=tf.random.normal((500,1))
noise=tf.random.normal((500,1))
y=x+W_true+B_true+noise학습
w=tf.Variable(5.0)
b=tf.Variable(0.)
lr=0.03
w_records=[]
b_records=[]
for epoch in range(100):
#매 epoch 한 번 씩 학습
with tf.GradientTape() as tape:
y_hat=X*w+b
loss= tf.reduce_mean(tf.sqaure(y-y_hat))
w.records.append(w.numpy())
b_records.append(b.numpy())
dw,db=tape.gradient(loss,[w,b])
w.assign_sub(lr*dw)
b.assign_sub(lr*db)Linear Regression(2)
당뇨병 데이터
from sklearn.datasets import load_diabetes
import pandas as pd
diabetes=load_diabetes()
df=pd.DataFrame(diabetes.data,columns=diabetes.feature_names,dtype=np.float32)
df['const']=np.ones(df.shape[0])
df.tail(3)를 Feature,를 가중치 벡터, 를 Target이라고 할때
의 역행렬이 존재한다고 가정했을 때
아래의 식을 이용해 의 추정치 구하기
=
X=df
y=np.exapand_dims(diabetes.target,axis=1)
XT=tf.transpose(X)
w=tf.matmul(tf.matmul(tf.linalg.inv(tf.matmul(XT,X)),XT),y)
y_pred=tf.matmul(X,w)SGD 방식으로 구현하기
- Conditions
- 가중치는 Gaussian normal distribution에서 난수로 초기화함- step size==0.03
- 100 iteration
- step size==0.03
lr=0.03
num_iter=100w_inittf.random.normal([X.shape[-1],1))
w=tf.Variable(w_init)
for i in range(num_iter):
with tf.GradientTape() as tape:
y_hat=tf.matmul(X,w)
loss=tf.reduce_mean((y-y_hat)**2)
dw=tape.gradient(loss,w)
w.assign_sub(lr*dw)Perceptron
iris 데이터 중 두 종류를 분류하는 퍼셉트론 제작하기
y값은 1또는 -1 을 사용하고 활성화 함수로 하이퍼탄젠트 함수를 사용
비용함수는 다음과 같이
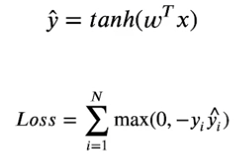
from sklearn.datasets import load_iris
iris=load_iris()
print(iris.DESCR)전처리 : 두가지만 이용할 거기 때문에
idx=np.in1d(iris.target,[0,2])
X_data=iris.data[idx,0:2]
y_data=(iris.target[idx]-1.0)[:,np.newaxis]
X_data.shape,y_data.shape- perceptron 구현
- 데이터 하나당 한번씩 weights 업데이트- step size= 0.0003
- iteration = 200
num_iter=500
lr=0.0003
zero=tf.constant(0,dtype=tf.float64)
w=tf.Variable(tf.random.normal([2,1],dtype=tf.float64))
b=tf.Variable(tf.random.normal([1,1],dtype=tf.float64))
for epoch in range(num_iter):
for i in range(X_data.shape[0]):
x=X_data[i:i+1]
y=y_data[i:i+1]
with tf.GradientTape() as tape:
logit=tf.matmul(x,w)+b
y_hat=tf.tanh(logit)
loss=tf.maximum(zero,tf.multiply(-y,y_hat))
grad=tape.gradient(loss,[w,b])
w.assign_sub(lr*grad[0])
b.assign_sub(lr*grad[1])
