머신러닝 과 딥러닝의 큰 차이 : 연산량이 어마어마함.
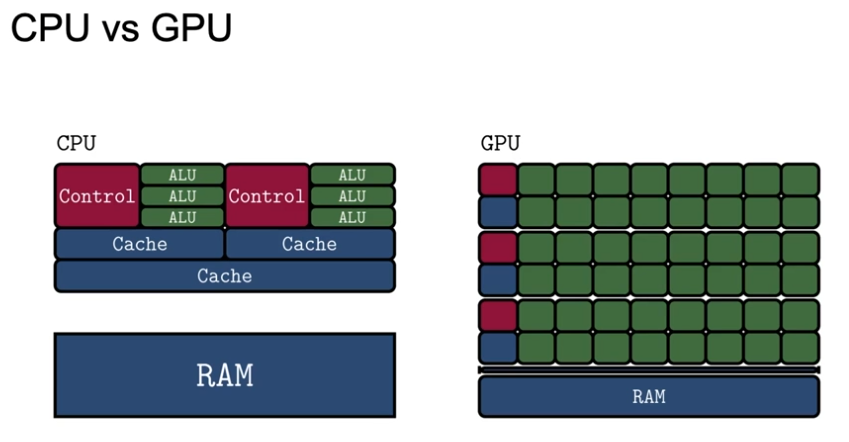
- GPU는 분산처리가 용이함
- 딥러닝 프레임워크: GPU에서 돌릴수 있도록 쉽게 도와주는 도구
- 딥러닝 프레임워크에서 중요한 것
- 텐서 생성하고 다루기
- 연산 정의 : 모델 어떻게 연결
- 최적화(미분)
- 데이터 다루기
Tensorflow vs PyTorch
-
요즘 PyTorch를 이용하는 추세 (논문의 90%정도)
- HuggingFace : 이미 구현된 모델들
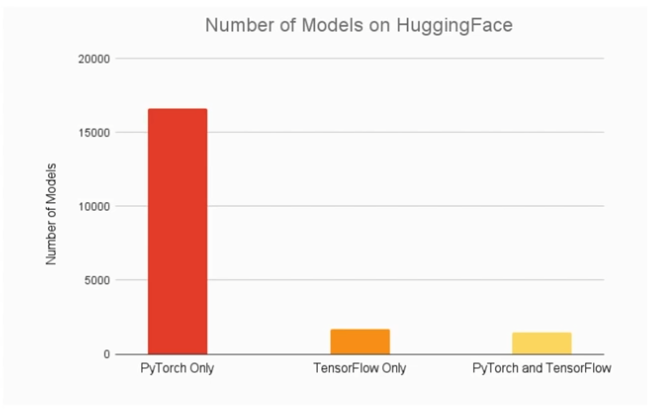
최신 연구에서는 Pytorch가 압도적, 구글에서 나오는 연구는 Tensorflow로
Reinforcement Learning 분야는 예외 -
Production에는 역시 Tensorflow
- TF Extended : Machine Learning 파이프라인 플랫폼
- TF.js : 브라우저, NodeJS에서 바로 ML을 서비스
- TF Lite: 모바일,엣지디바이스 에서 바로 ML을 서비스
뿐만 아니라 구글에서 만든 VertexAI,Kubernetes,Docker 등과 호환이 더 잘됨
인프라,상품화에 장점
※Pytorch는 연구에 활발히 활용, SOTA모델,최신연구에 쉽게 접근, 다만 상품화에 인프라와 기능이 부족, TF는 유의미한 연구결과를 내는 구글에서 사용하고 상품화에 있어 인프라와 기능이 풍족 다만, 최신 연구 중 TF로 공개되는 것은 적다.
★환경세팅★
- 코랩 사용하기
- 런타임 선택 -> 런타임 유형 변경 -> 하드웨어 가속기 GPU 선택
확인하는 방법
!nvidia-smi
import tensorflow as tf
import torch
print(tf.__version__)
print(torch.__version__)- PC에 설정하기
pip install tensorflow==2.7.0
pip install torch==1.10.0 torchvision==0.11.1 torchtext==0.11.0 torchaudio==0.10.0
# 또는 pip install torch torchvision torchaudio torchtext파이토치: https://pytorch.org/get-started/locally/ 에 접속하면 자신의 사양에 맞게 할 수 있음.
GPU 가 있는경우 아래 두가지가 다 있어야 함.
1. CUDA Tool Kit : GPU 개발 툴 모음 (GPU코딩을 위한 컴파일러)
installation: https://developer.nvidia.com/cuda-toolkit
supported GPU: https://developer.nvidia.com/cuda-gpus#compute [GPU 할수있는건지]
- cuDNN : 딥러닝 라이브러리 (CNN,RNN을 최적화 해주는)
installation: https://developer.nvidia.com/rdp/cudnn-download
Constants
- 딥러닝 프레임워크는 기본적으로 Tensor를 다루는 도구
- 텐서를 다룰 때 가장 중요한 것 : shape
(제일 에러 많이 나는 이유, 개발 할 때 이론을 알아야 하는 이유, 함수들의 설정값을 확인해야 하는 이유)
Tensor 생성
생성하는 것은 tf.Tensor 데이터!
- 체크해야하는 것
- shape- dtype
tf.Tensor- Constant(상수)
-tf.constant()
- list -> Tensor
- tuple -> Tensor
- Array -> Tensor
#리스트
li_ten_f=tf.constant([1.,2.,3.])
#튜플
tu_ten=tf.constant(((1,2,3),(1,2,3)),name='sample')
#np.array
arr=np.array([1.,2.,3.])
arr_ten=tf.constant(arr)- ndim 랭크(dimension) 확인 하기
print(li_ten.ndim)
print(tu_ten.ndim)※ dtype
list->tensor : float32
tuple -> tensor: int32
array -> tensor: float64
- double precision: 64bits 64비트로 표현할 수 있는 걸 double
- single precision: 32bits 32비트로 표현할 수 있는 걸 single
- half precision: 16bits 16비트로 표현할 수 있는 걸 half
ex) 3 /10 =0.333333...
데이터를 비트표현을 어떻게 할 까에 따라서 데이터가 가벼워지고 연산속도가 빨라지지만, 오차가 커짐
Numpy array 추출
arr_ten.numpy(),type(arr_ten.numpy())
li_ten.numpy(),type(li_ten.numpy())list만 할 수 있는
matrix=[[1,2,3],[4,5],[6,7,8]]을 tf.constant하면 에러가 발생한다. 텐서 변환 안됨(구조적이지 않는거)
데이터 타입 컨트롤 tf.cast
tf.cast(tensor,dtype=tf.int16) #int16으로 바꾸자특정값의 텐서 생성
- tf.ones
tf.ones(1)- tf.zeros
tf.zeros((2,5),dtype='int32')- tf.range
tf.range(10)Random Value
- tf.random
- tf.random.normal (Normal Distribution)
shape=(3,3)
tf.random.normal(shape,#mean=100,#stddev=10) # 평균,표준편차 바꾸기- tf.random.uniform (Uniform Distribution)
tf.random.uniform(shape)0★Random Seed 관리하기
- tf.random.set_seed({seed_number})
항상 random seed를 고정해두고 개발한다.
random value로 가중치 초기화
이를 관리하지 않으면 동일하게 복구, 재현이 안된다.
Variable
데이터가 들어갈 공간을 정의한다고 생각하자.
- 미지수,가중치를 정의할 때 사용
- 직접 사용할 일이 많지 않음
- 변수 정의는 변수 생성+초기화
tensor=tf.constant([1.0,2.0],[3.0,4.0]])
arr=np.array([[1,2],[3,4]])
li=[[1,2],[3,4]]
te_var=tf.Variable(tensor)
arr_var=tf.Variable(arr)
li_var=tf.Variable(li)variable vs Constant
공간을 재할당 해서 재사용 할 수 있다.
a=tf.Variable([2.0,3.0])
a.assign([1,2])기존 메모리의 크기와 다르면 할당 할 수 없다. 1.0,2.0 은 float 로 생성되서 int값을 넣어도 되지만, int로 생성한 뒤 float 할당은 할 수 없음.
Tensor 연산
- tf.add: 덧셈
+를 이용해도 됨, 하지만 python의 add가 아니고 tensorflow의 add가 불러와짐
a=tf.range(6,dtype=tf.int32)
b=2*tf.ones(6,dtype=tf.int32)
a+b
tf.add(a,b)- tf.subtract : 뺄셈
- tf.multiply : 곱셈
- tf.divide : 나눗셈
- tf.pow : n제곱
- tf.negative : 음수 부호
여러가지 연산
- tf.abs : 절대값
- tf.sign : 부호
- tf.round : 반올림
- tf.ceil : 올림
- tf.floor : 내림
- tf.square : 제곱
- tf.sqrt : 제곱근
- tf.maximum : 두 텐서의 각 원소에서 최댓값만 반환
- tf.minimum : 두 텐서의 각 원소에서 최소값만 반환
- tf.cumsum : 누적합
- tf.cumprod : 누적곱
Axis
텐서는 차원이 있기 때문에 axis 이해가 중요
- 3차원
rank_3=tf.random.normal((3,3,3))
rank_3<tf.Tensor: shape=(3, 3, 3), dtype=float32, numpy=
array([[[-0.785365 , -0.14951527, 0.7898834 ],
[ 1.6614823 , 1.3986127 , 1.8451853 ],
[-0.09502801, -1.2018238 , -0.76950115]], <-axis 0의 0의 원소
[[-0.05696192, -1.0351526 , 0.15891126],
[-0.01851465, 0.60389733, -0.0193509 ],
[-0.92432773, 1.0425829 , 0.36150223]], <-axis 0의 1의 원소
[[-1.7199396 , 0.89606565, 0.6456121 ],
[-1.2237988 , -0.7233174 , -0.87720877], <-axis 0 의 2의 원소
[-1.1135597 , 1.499205 , -0.99680024]]], dtype=float32)>shape 이 3 by 3 by 3
-
0.0193509 : rank_3[1,1,2]
-
-0.92432773 : rank_3[1,2,0]
-
4차원
rank_4=tf.random.normal((3,3,3,3))
rank_4array([[[[-1.1977218 , 1.4106507 , 0.02985195],
[ 0.1853268 , 1.1153575 , -1.8254622 ],
[-0.22258121, -0.91995853, 1.2042358 ]],
[[-0.88101554, 0.08310289, 1.120979 ],
[-2.153404 , 0.8123266 , -0.87209094],
[ 2.0952816 , 0.28967106, -0.3915192 ]],
[[ 1.347707 , 1.4567065 , 1.2672193 ],
[ 2.0305731 , -1.1752279 , -0.8256832 ],
[ 0.45798892, 0.42518482, 1.3228331 ]]],
[[[-0.31125122, -0.31733438, 0.08505055],
[ 1.253486 , 1.617412 , -1.5700681 ],
[-0.8406574 , -0.6096752 , 0.83215636]],
[[-0.06353501, 0.7819116 , 0.94118196],
[-0.6063586 , 0.13212796, -0.65157884],
[-0.13943893, -1.5827788 , -0.71198285]],
[[ 0.79945457, 0.63886446, -0.25782853],
[ 0.3010725 , -0.30323339, -0.49271744],
[ 0.6646602 , 0.7729394 , -0.03544683]]],
[[[-0.1185328 , -0.6936849 , -1.2964959 ],
[-0.2348005 , -1.206046 , 0.28030595],
[-0.02895945, 0.04022552, -0.15515332]],
[[-0.7175442 , -2.160909 , 0.48714104],
[ 0.49451953, -0.4811295 , 0.40870458],
[-0.00473751, -0.79214007, 0.5231748 ]],
[[-0.8522025 , -0.79864043, 0.11275982],
[-1.0728081 , 1.7563201 , -0.33675656],
[-1.2303987 , -0.62026685, -1.1419879 ]]]], dtype=float32)>차원 축소 연산
tf.reduce
axis=0을 하면 차원을 줄이는 연산 , keepdims인자 True하면 차원 유지
- tf.reduce_mean : 설정한 축의 평균
- tf.reduce_max : 설정한 축의 최댓값
- tf.reduce_min : 설정한 축의 최솟값
- tf.reduce_prod : 설정한 축의 요소를 모두 곱
- tf.reduce_sum : 설정한 축의 요소를 모두 덧셈
행렬 관련 연산
- tf.matmul: 내적
- tf.linalg.inv: 역행렬
★크기 및 차원 바꾸는 명령어
- tf.reshape : 벡터 행렬 크기 변환
- tf.transpose : 전치 연산
- tf.expand_dims : 지정한 축으로 차원 추가
- tf.squeeze : 벡터로 차원 축소
a=tf.range(6,dtype=tf.int32)
a_2d=tf.reshape(a,[2,3]) # 1차원 벡터 2x3크기의 2차원 행렬 변환
a_2d_t=tf.transpose(a_2d) #2x3크기의 2차원 행렬을 3x2크기의 2차원 행렬 변환
a_3d=tf.expand_dims(a_2d,0) # 2x3크기의 2차원 행렬을 1x2x3 크기의 3차원 행렬 변환(axis 이용)
a_4d=tf.expand_dims(a_3d),3) #1x2x3크기의 3차원 행렬을 1x2x3x1 크기의 4차원 행렬 변환
a_1d=tf.squeeze(a_4d) # 1x2x3x1크기의 4차원 행렬을 1차원 벡터로 반환텐서를 나누거나 두개 이상의 텐서 합치기
- tf.slice : 특정 부분 추출
- tf.split : 분할
- tf.concat : 합치기
- tf.tile : 복제-붙이기
- tf.stack : 합성 # 추가적인 차원으로 붙임
- tf.unstack : 분리 #고차원 텐서를 0차원으로 풀음
