과대적합 피하기
데이터 증식 사용하기
- 기존 데이터를 변형하여 새로운 데이터를 만들어내는 방법
- 일반화를 보완하지만 근본적인 해결책은 아님
- 데이터가 다양해지므로 테스트 성능이 높아짐.
- 케라스가 이미지 제너레이터(ImageGenerator)를 제공.
from keras.utils import load_img, img_to_array # 케라스가 업데이트되면서 경로가 바뀌었다.
from keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
import numpy as nptrain_datagen = ImageDataGenerator(horizontal_flip=True, # 이미지 수평 방향 뒤집기
vertical_flip=True, # 이미지 수직 방향 뒤집기
shear_range=0.5, # 밀림 강도를 50%조절
brightness_range=[0.5,1.5], # 밝기를 0.5~1.5로 조절
zoom_range=0.2, # 확대 비율 20%
width_shift_range=0.1, # 너비 방향 이동 10%
height_shift_range=0.1, # 높이 방향 이동 10%
rotation_range=30, # 이미지 회전 30도
fill_mode='nearest') # 이미지 변환시 픽셀 변환을 근처를 가져옴img = img_to_array(load_img('img04.jpg')).astype(np.uint8)
plt.imshow(img)<matplotlib.image.AxesImage at 0x7f3ca01915b0>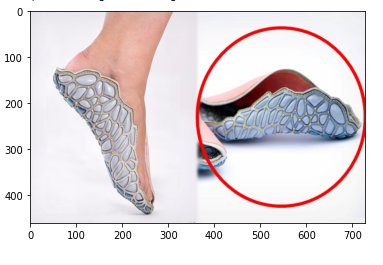
result = img.reshape((1,)+img.shape)
img.shape,result.shape((460, 728, 3), (1, 460, 728, 3))train_generator = train_datagen.flow(result,batch_size=1)fig = plt.figure(figsize=(5,5))
fig.suptitle('증강 이미지')
for i in range(9):
data = next(train_generator)
image = data[0]
plt.subplot(3,3,i+1)
plt.xticks([])
plt.yticks([])
plt.imshow(np.array(image,dtype=np.uint8))
plt.show()/usr/local/lib/python3.8/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 51613 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.8/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 44053 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.8/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 51060 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.8/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 48120 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.8/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 51648 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.8/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 51613 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.8/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 44053 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.8/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 51060 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.8/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 48120 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.8/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 51648 missing from current font.
font.set_text(s, 0, flags=flags)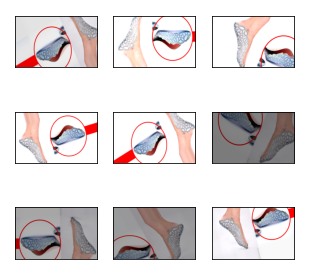
from keras.datasets import cifar10
import numpy as np
from sklearn.model_selection import train_test_split
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_mean = np.mean(x_train,axis=(0,1,2))
x_std = np.std(x_train, axis = (0,1,2))
x_train = (x_train - x_mean) / x_std
x_test = (x_test - x_mean) / x_std
x_train, x_val, y_train, y_val = train_test_split(x_train,y_train,test_size=0.3,random_state=777)train_datagen = ImageDataGenerator(horizontal_flip=True,
zoom_range=0.2,
width_shift_range=0.1,
height_shift_range=0.1,
rotation_range=30,
fill_mode='nearest')
val_datagen = ImageDataGenerator()
batch_size = 32
train_generator = train_datagen.flow(x_train,y_train,batch_size=batch_size)
val_generator = val_datagen.flow(x_val,y_val,batch_size=batch_size)from keras.models import Sequential
from keras.layers import Conv2D, MaxPool2D, Flatten, Dense, Activation, BatchNormalization
from keras.optimizers import Adam
model = Sequential([
Conv2D(filters=32,kernel_size=3,padding='same',input_shape=(32, 32, 3)),
BatchNormalization(),
Activation('relu'),
Conv2D(filters=32,kernel_size=3,padding='same'),
BatchNormalization(),
Activation('relu'),
MaxPool2D(pool_size=(2,2),strides=2,padding='same'),
Conv2D(filters=64,kernel_size=3,padding='same'),
BatchNormalization(),
Activation('relu'),
Conv2D(filters=64,kernel_size=3,padding='same'),
BatchNormalization(),
Activation('relu'),
MaxPool2D(pool_size=(2,2),strides=2,padding='same'),
Conv2D(filters=128,kernel_size=3,padding='same'),
BatchNormalization(),
Activation('relu'),
Conv2D(filters=128,kernel_size=3,padding='same'),
BatchNormalization(),
Activation('relu'),
MaxPool2D(pool_size=(2,2),strides=2,padding='same'),
Flatten(),
Dense(256),
BatchNormalization(),
Activation('relu'),
Dense(10, activation = 'softmax')
])
model.compile(optimizer = Adam(1e-4), loss = 'sparse_categorical_crossentropy',metrics=['acc'])
def get_step(train_len, batch_size):
if(train_len % batch_size > 0):
return train_len // batch_size + 1
else:
return train_len // batch_size
history = model.fit(train_generator,
epochs=100,
steps_per_epoch=get_step(len(x_train),batch_size),
validation_data=val_generator,
validation_steps = get_step(len(x_val), batch_size))Epoch 1/100
1094/1094 [==============================] - 24s 21ms/step - loss: 1.6084 - acc: 0.1101 - val_loss: 1.3281 - val_acc: 0.0959
Epoch 2/100
1094/1094 [==============================] - 23s 21ms/step - loss: 1.3403 - acc: 0.1031 - val_loss: 1.3337 - val_acc: 0.1547
Epoch 99/100
1094/1094 [==============================] - 24s 22ms/step - loss: 0.2939 - acc: 0.1025 - val_loss: 0.4793 - val_acc: 0.1139
Epoch 100/100
1094/1094 [==============================] - 24s 22ms/step - loss: 0.3033 - acc: 0.1030 - val_loss: 0.4288 - val_acc: 0.0973import matplotlib.pyplot as plt
his_dict = history.history
loss = his_dict['loss']
val_loss = his_dict['val_loss']
epochs = range(1, len(loss)+1)
fig = plt.figure(figsize=(10,5))
ax1 = fig.add_subplot(1,2,1)
ax1.plot(epochs,loss,color='blue',label='train_loss')
ax1.plot(epochs,val_loss,color='orange',label='val_loss')
ax1.set_title('loss')
ax1.legend()
acc = his_dict['acc']
val_acc = his_dict['val_acc']
ax2 = fig.add_subplot(1,2,2)
ax2.plot(epochs,acc,color='blue',label='train_acc')
ax2.plot(epochs,val_acc,color='orange',label='val_acc')
ax2.set_title('acc')
ax2.legend()
plt.show()
전이 학습
- 사전 학습된 네트워크의 가중치를 사용. 크게 세 가지
- 기본 과정 : 입력 -> 모델 -> 분류기 -> 출력
- 모델을 변형하지 않고 사용
- 모델 분류기 재학습
- 모델 일부를 재학습시키기
- 전체 재학습은 시간이 많이 걸리므로 일부를 조정해서 이용한다.
from keras.datasets import cifar10
import numpy as np
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
plt.imshow(x_test[0])
x_mean = np.mean(x_train,axis=(0,1,2))
x_std = np.std(x_train, axis = (0,1,2))
x_train = (x_train - x_mean) / x_std
x_test = (x_test - x_mean) / x_std
x_train, x_val, y_train, y_val = train_test_split(x_train,y_train,test_size=0.3,random_state=777)
y_train.shapeDownloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
170498071/170498071 [==============================] - 5s 0us/step
(35000, 1)
x_train.shape(35000, 32, 32, 3)전이 학습 설정하기
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(horizontal_flip=True,
zoom_range=0.2,
width_shift_range=0.1,
height_shift_range=0.1,
rotation_range=30,
fill_mode='nearest')
val_datagen = ImageDataGenerator()
batch_size = 32
train_generator = train_datagen.flow(x_train,y_train,batch_size=batch_size)
val_generator = val_datagen.flow(x_val,y_val,batch_size=batch_size)from keras.models import Sequential
from keras.layers import Conv2D, MaxPool2D, Flatten, Dense, Activation, BatchNormalization
from keras.optimizers import Adam
from keras.applications import VGG16
vgg16 = VGG16(include_top=False,input_shape=(32, 32, 3))
vgg16.summary()Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg16/vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5
58889256/58889256 [==============================] - 0s 0us/step
Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 32, 32, 3)] 0
block1_conv1 (Conv2D) (None, 32, 32, 64) 1792
block1_conv2 (Conv2D) (None, 32, 32, 64) 36928
block1_pool (MaxPooling2D) (None, 16, 16, 64) 0
block2_conv1 (Conv2D) (None, 16, 16, 128) 73856
block2_conv2 (Conv2D) (None, 16, 16, 128) 147584
block2_pool (MaxPooling2D) (None, 8, 8, 128) 0
block3_conv1 (Conv2D) (None, 8, 8, 256) 295168
block3_conv2 (Conv2D) (None, 8, 8, 256) 590080
block3_conv3 (Conv2D) (None, 8, 8, 256) 590080
block3_pool (MaxPooling2D) (None, 4, 4, 256) 0
block4_conv1 (Conv2D) (None, 4, 4, 512) 1180160
block4_conv2 (Conv2D) (None, 4, 4, 512) 2359808
block4_conv3 (Conv2D) (None, 4, 4, 512) 2359808
block4_pool (MaxPooling2D) (None, 2, 2, 512) 0
block5_conv1 (Conv2D) (None, 2, 2, 512) 2359808
block5_conv2 (Conv2D) (None, 2, 2, 512) 2359808
block5_conv3 (Conv2D) (None, 2, 2, 512) 2359808
block5_pool (MaxPooling2D) (None, 1, 1, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 14,714,688
Non-trainable params: 0
_________________________________________________________________모델 동결 해제하기
for layer in vgg16.layers[:-4]: # 모델 끝 4개 층만 선택
layer.trainable = False # 동결을 해제제전이 학습을 통해 학습하기
model = Sequential([
vgg16,
Flatten(),
Dense(256),
BatchNormalization(),
Activation('relu'),
Dense(10, activation='softmax')
])
model.compile(optimizer = Adam(1e-4), loss = 'sparse_categorical_crossentropy',metrics=['acc'])
def get_step(train_len, batch_size):
if(train_len % batch_size > 0):
return train_len // batch_size + 1
else:
return train_len // batch_size
history = model.fit(train_generator,
epochs=100,
steps_per_epoch=get_step(len(x_train),batch_size),
validation_data=val_generator,
validation_steps = get_step(len(x_val), batch_size))Epoch 1/100
1094/1094 [==============================] - 39s 27ms/step - loss: 1.1232 - acc: 0.1066 - val_loss: 0.9254 - val_acc: 0.0801
Epoch 2/100
1094/1094 [==============================] - 29s 27ms/step - loss: 0.9237 - acc: 0.1017 - val_loss: 1.0233 - val_acc: 0.0944
Epoch 99/100
1094/1094 [==============================] - 29s 26ms/step - loss: 0.1001 - acc: 0.1019 - val_loss: 0.9992 - val_acc: 0.1010
Epoch 100/100
1094/1094 [==============================] - 30s 27ms/step - loss: 0.0990 - acc: 0.1019 - val_loss: 1.0171 - val_acc: 0.0897추가 실습
from keras.datasets.mnist import load_data
import numpy as np(x_train, y_train), (x_test, y_test) = load_data()# 홀수여부(홀수:1, 짝수:0)
y_train_odd = []
for y in y_train:
if y%2 ==0:
y_train_odd.append(0)
else:
y_train_odd.append(1)
y_train_odd = np.array(y_train_odd)
y_train_odd.shape(60000,)print(y_train[:10])
print(y_train_odd[:10])[5 0 4 1 9 2 1 3 1 4]
[1 0 0 1 1 0 1 1 1 0]y_test_odd = []
for y in y_test:
if y % 2 == 0:
y_test_odd.append(0)
else:
y_test_odd.append(1)
y_test_odd = np.array(y_test_odd)
y_test_odd.shape(10000,)x_train.min(),x_train.max()(0, 255)x_train = x_train/255.
x_test = x_test/255.x_train.min(),x_train.max()(0.0, 1.0)x_train.shape(60000, 28, 28)x_train_in = np.expand_dims(x_train, -1)
x_test_in = np.expand_dims(x_test, -1)
x_train_in.shape,x_test_in.shape((60000, 28, 28, 1), (10000, 28, 28, 1))from keras.layers import Input, Conv2D,MaxPool2D,Flatten,Dense,Concatenate
from keras.models import Modelinputs = Input(shape=(28, 28, 1))
# 아래 과정에서 inputs가 두 번 쓰이게 됨
# 최대 풀링 처리 루트
conv = Conv2D(32,(3,3),activation='relu')(inputs)
pool = MaxPool2D((2,2))(conv)
flat = Flatten()(pool)
# 홀짝 판별만 하는 루트
flat_inputs = Flatten()(inputs)
concat = Concatenate()([flat,flat_inputs])
outputs = Dense(10,activation='softmax')(concat)
model = Model(inputs=inputs,outputs=outputs)
model.summary()Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 28, 28, 1)] 0 []
conv2d (Conv2D) (None, 26, 26, 32) 320 ['input_1[0][0]']
max_pooling2d (MaxPooling2D) (None, 13, 13, 32) 0 ['conv2d[0][0]']
flatten (Flatten) (None, 5408) 0 ['max_pooling2d[0][0]']
flatten_1 (Flatten) (None, 784) 0 ['input_1[0][0]']
concatenate (Concatenate) (None, 6192) 0 ['flatten[0][0]',
'flatten_1[0][0]']
dense (Dense) (None, 10) 61930 ['concatenate[0][0]']
==================================================================================================
Total params: 62,250
Trainable params: 62,250
Non-trainable params: 0
__________________________________________________________________________________________________from keras.utils import plot_model# 두 갈래로 나뉘어지는지 확인
plot_model(model,show_shapes=True,show_layer_names=True)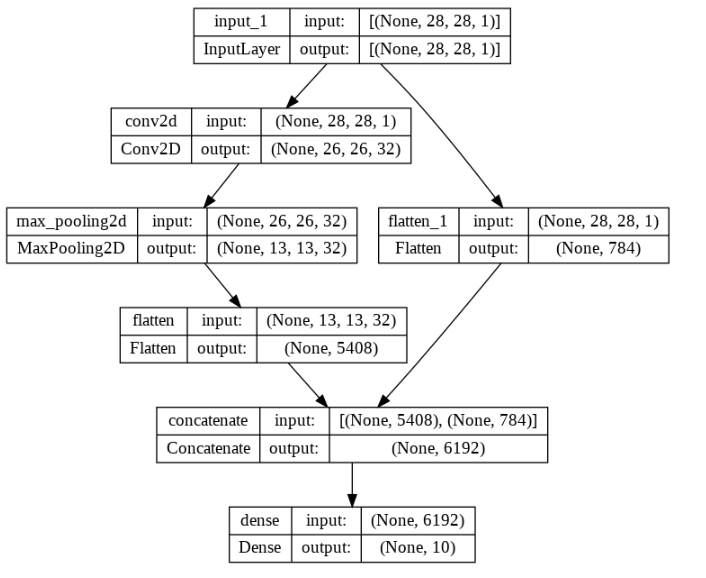
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
history = model.fit(x_train_in,
y_train,
validation_data=(x_test_in,y_test),
epochs=10)
model.evaluate(x_test_in,y_test)Epoch 1/10
1875/1875 [==============================] - 14s 5ms/step - loss: 0.2079 - accuracy: 0.9404 - val_loss: 0.0872 - val_accuracy: 0.9742
Epoch 2/10
1875/1875 [==============================] - 10s 5ms/step - loss: 0.0789 - accuracy: 0.9770 - val_loss: 0.0740 - val_accuracy: 0.9747
Epoch 3/10
1875/1875 [==============================] - 10s 6ms/step - loss: 0.0613 - accuracy: 0.9817 - val_loss: 0.0635 - val_accuracy: 0.9793
Epoch 4/10
1875/1875 [==============================] - 7s 4ms/step - loss: 0.0492 - accuracy: 0.9853 - val_loss: 0.0613 - val_accuracy: 0.9795
Epoch 5/10
1875/1875 [==============================] - 5s 3ms/step - loss: 0.0415 - accuracy: 0.9869 - val_loss: 0.0640 - val_accuracy: 0.9795
Epoch 6/10
1875/1875 [==============================] - 5s 3ms/step - loss: 0.0350 - accuracy: 0.9888 - val_loss: 0.0515 - val_accuracy: 0.9834
Epoch 7/10
1875/1875 [==============================] - 6s 3ms/step - loss: 0.0295 - accuracy: 0.9910 - val_loss: 0.0557 - val_accuracy: 0.9834
Epoch 8/10
1875/1875 [==============================] - 5s 3ms/step - loss: 0.0240 - accuracy: 0.9928 - val_loss: 0.0589 - val_accuracy: 0.9831
Epoch 9/10
1875/1875 [==============================] - 5s 3ms/step - loss: 0.0210 - accuracy: 0.9933 - val_loss: 0.0602 - val_accuracy: 0.9830
Epoch 10/10
1875/1875 [==============================] - 5s 3ms/step - loss: 0.0177 - accuracy: 0.9946 - val_loss: 0.0582 - val_accuracy: 0.9843
313/313 [==============================] - 1s 2ms/step - loss: 0.0582 - accuracy: 0.9843
[0.0582151785492897, 0.9843000173568726]# 필요한 곳에 name을 붙여줌
inputs = Input(shape=(28, 28, 1), name='inputs')
conv = Conv2D(32,(3,3),activation='relu',name='conv2d')(inputs)
pool = MaxPool2D((2,2),name='maxpool')(conv)
flat = Flatten(name='flatten')(pool)
flat_inputs = Flatten()(inputs)
concat = Concatenate()([flat,flat_inputs])
digit_outputs = Dense(10,activation='softmax',name='digit_output')(concat)
odd_outputs = Dense(1,activation='sigmoid',name='odd_output')(flat_inputs)
model = Model(inputs=inputs,outputs=[digit_outputs,odd_outputs])
model.summary()Model: "model_1"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
inputs (InputLayer) [(None, 28, 28, 1)] 0 []
conv2d (Conv2D) (None, 26, 26, 32) 320 ['inputs[0][0]']
maxpool (MaxPooling2D) (None, 13, 13, 32) 0 ['conv2d[0][0]']
flatten (Flatten) (None, 5408) 0 ['maxpool[0][0]']
flatten_2 (Flatten) (None, 784) 0 ['inputs[0][0]']
concatenate_1 (Concatenate) (None, 6192) 0 ['flatten[0][0]',
'flatten_2[0][0]']
digit_output (Dense) (None, 10) 61930 ['concatenate_1[0][0]']
odd_output (Dense) (None, 1) 785 ['flatten_2[0][0]']
==================================================================================================
Total params: 63,035
Trainable params: 63,035
Non-trainable params: 0
__________________________________________________________________________________________________plot_model(model,show_shapes=True,show_layer_names=True)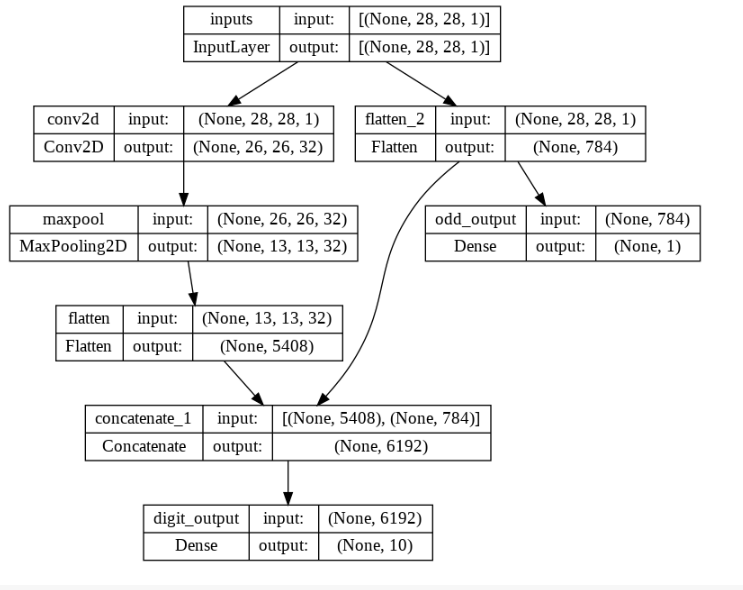
# 입력 쪽 내용 조회
print(model.input)KerasTensor(type_spec=TensorSpec(shape=(None, 28, 28, 1), dtype=tf.float32, name='inputs'), name='inputs', description="created by layer 'inputs'")# 출력 쪽 내용 조회
print(model.output)[<KerasTensor: shape=(None, 10) dtype=float32 (created by layer 'digit_output')>, <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'odd_output')>]model.compile(optimizer='adam',
loss={'digit_output':'sparse_categorical_crossentropy',
'odd_output':'binary_crossentropy'},
loss_weights={'digit_output':1,
'odd_output':0.5},
metrics=['accuracy'])
history = model.fit({'inputs':x_train_in},
{'digit_output':y_train,'odd_output':y_train_odd},
validation_data=({'inputs':x_test_in},
{'digit_output':y_test,'odd_output':y_test_odd}),
epochs=10)Epoch 1/10
1875/1875 [==============================] - 10s 5ms/step - loss: 0.3728 - digit_output_loss: 0.2102 - odd_output_loss: 0.3252 - digit_output_accuracy: 0.9402 - odd_output_accuracy: 0.8633 - val_loss: 0.2362 - val_digit_output_loss: 0.0977 - val_odd_output_loss: 0.2769 - val_digit_output_accuracy: 0.9723 - val_odd_output_accuracy: 0.8891
Epoch 2/10
1875/1875 [==============================] - 8s 4ms/step - loss: 0.2180 - digit_output_loss: 0.0821 - odd_output_loss: 0.2718 - digit_output_accuracy: 0.9758 - odd_output_accuracy: 0.8914 - val_loss: 0.2083 - val_digit_output_loss: 0.0771 - val_odd_output_loss: 0.2624 - val_digit_output_accuracy: 0.9764 - val_odd_output_accuracy: 0.8972
Epoch 3/10
1875/1875 [==============================] - 11s 6ms/step - loss: 0.1927 - digit_output_loss: 0.0613 - odd_output_loss: 0.2629 - digit_output_accuracy: 0.9814 - odd_output_accuracy: 0.8953 - val_loss: 0.2036 - val_digit_output_loss: 0.0732 - val_odd_output_loss: 0.2608 - val_digit_output_accuracy: 0.9778 - val_odd_output_accuracy: 0.8993
Epoch 4/10
1875/1875 [==============================] - 9s 5ms/step - loss: 0.1797 - digit_output_loss: 0.0502 - odd_output_loss: 0.2589 - digit_output_accuracy: 0.9845 - odd_output_accuracy: 0.8974 - val_loss: 0.1881 - val_digit_output_loss: 0.0595 - val_odd_output_loss: 0.2572 - val_digit_output_accuracy: 0.9816 - val_odd_output_accuracy: 0.9000
Epoch 5/10
1875/1875 [==============================] - 8s 4ms/step - loss: 0.1705 - digit_output_loss: 0.0419 - odd_output_loss: 0.2572 - digit_output_accuracy: 0.9877 - odd_output_accuracy: 0.8993 - val_loss: 0.1837 - val_digit_output_loss: 0.0559 - val_odd_output_loss: 0.2557 - val_digit_output_accuracy: 0.9822 - val_odd_output_accuracy: 0.9001
Epoch 6/10
1875/1875 [==============================] - 7s 4ms/step - loss: 0.1644 - digit_output_loss: 0.0366 - odd_output_loss: 0.2557 - digit_output_accuracy: 0.9889 - odd_output_accuracy: 0.8993 - val_loss: 0.1849 - val_digit_output_loss: 0.0570 - val_odd_output_loss: 0.2558 - val_digit_output_accuracy: 0.9822 - val_odd_output_accuracy: 0.9013
Epoch 7/10
1875/1875 [==============================] - 8s 4ms/step - loss: 0.1572 - digit_output_loss: 0.0298 - odd_output_loss: 0.2548 - digit_output_accuracy: 0.9905 - odd_output_accuracy: 0.8997 - val_loss: 0.1882 - val_digit_output_loss: 0.0596 - val_odd_output_loss: 0.2572 - val_digit_output_accuracy: 0.9816 - val_odd_output_accuracy: 0.9013
Epoch 8/10
1875/1875 [==============================] - 7s 4ms/step - loss: 0.1523 - digit_output_loss: 0.0251 - odd_output_loss: 0.2544 - digit_output_accuracy: 0.9923 - odd_output_accuracy: 0.9002 - val_loss: 0.1936 - val_digit_output_loss: 0.0659 - val_odd_output_loss: 0.2552 - val_digit_output_accuracy: 0.9809 - val_odd_output_accuracy: 0.9019
Epoch 9/10
1875/1875 [==============================] - 7s 4ms/step - loss: 0.1495 - digit_output_loss: 0.0226 - odd_output_loss: 0.2537 - digit_output_accuracy: 0.9928 - odd_output_accuracy: 0.9009 - val_loss: 0.1906 - val_digit_output_loss: 0.0624 - val_odd_output_loss: 0.2563 - val_digit_output_accuracy: 0.9830 - val_odd_output_accuracy: 0.9002
Epoch 10/10
1875/1875 [==============================] - 7s 4ms/step - loss: 0.1458 - digit_output_loss: 0.0192 - odd_output_loss: 0.2533 - digit_output_accuracy: 0.9938 - odd_output_accuracy: 0.9014 - val_loss: 0.1906 - val_digit_output_loss: 0.0622 - val_odd_output_loss: 0.2568 - val_digit_output_accuracy: 0.9837 - val_odd_output_accuracy: 0.9015model.evaluate({'inputs':x_test_in}, {'digit_output':y_test, 'odd_output':y_test_odd})313/313 [==============================] - 1s 3ms/step - loss: 0.1906 - digit_output_loss: 0.0622 - odd_output_loss: 0.2568 - digit_output_accuracy: 0.9837 - odd_output_accuracy: 0.9015
[0.1905856430530548,
0.06218775734305382,
0.2567956745624542,
0.9836999773979187,
0.9014999866485596]digit,odd = model.predict(x_test_in)313/313 [==============================] - 1s 2ms/stepnp.argmax(np.round(digit[0],2))7(odd[0]>0.5).astype(int)array([1])import matplotlib.pyplot as plt
plt.imshow(x_test[0],cmap='gray')<matplotlib.image.AxesImage at 0x7f8bf6405520>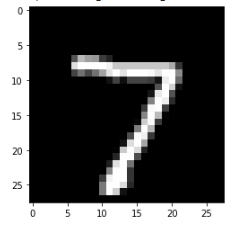
# 단순 플롯 모델
plot_model(model)
plot_model(model,show_shapes=True,show_layer_names=True)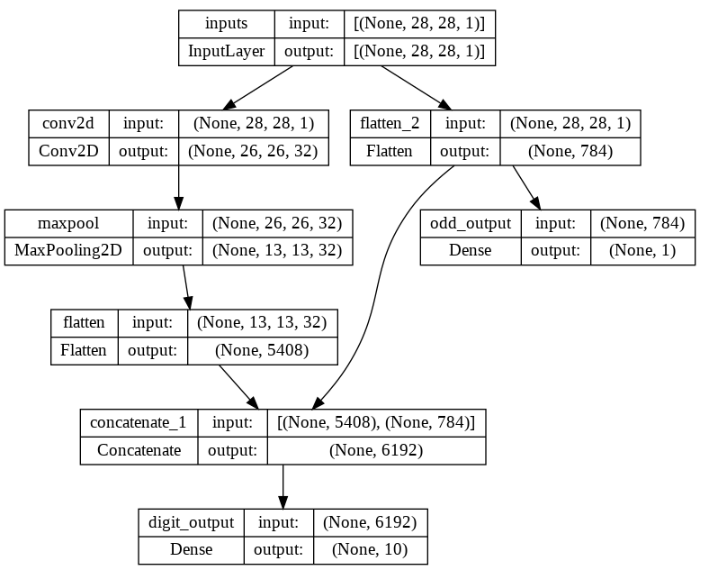
# 왼쪽 경로만 출력
base_model_output = model.get_layer('flatten').outputbase_model = Model(inputs=model.input,outputs=base_model_output,name='base')
plot_model(base_model,show_shapes=True,show_layer_names=True)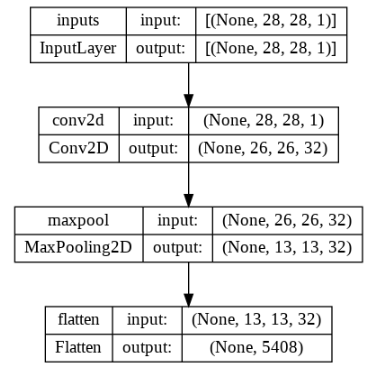
# 최종 경로로
from keras import Sequential
digit_model = Sequential([
base_model,
Dense(10,activation='softmax')
])
plot_model(digit_model,show_shapes=True,show_layer_names=True)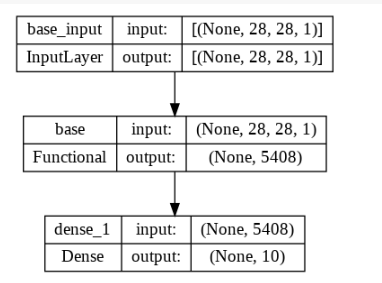
digit_model.summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
base (Functional) (None, 5408) 320
dense_1 (Dense) (None, 10) 54090
=================================================================
Total params: 54,410
Trainable params: 54,410
Non-trainable params: 0
_________________________________________________________________
digit_model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['acc'])
history = digit_model.fit(x_train_in,y_train,
validation_data=(x_test_in,y_test),
epochs=5)Epoch 1/5
1875/1875 [==============================] - 6s 3ms/step - loss: 0.1293 - acc: 0.9640 - val_loss: 0.0618 - val_acc: 0.9806
Epoch 2/5
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0593 - acc: 0.9819 - val_loss: 0.0539 - val_acc: 0.9814
Epoch 3/5
1875/1875 [==============================] - 7s 4ms/step - loss: 0.0448 - acc: 0.9865 - val_loss: 0.0589 - val_acc: 0.9809
Epoch 4/5
1875/1875 [==============================] - 7s 4ms/step - loss: 0.0371 - acc: 0.9883 - val_loss: 0.0604 - val_acc: 0.9821
Epoch 5/5
1875/1875 [==============================] - 5s 3ms/step - loss: 0.0300 - acc: 0.9906 - val_loss: 0.0562 - val_acc: 0.9825- 특정 층을 훈련불가능으로 묶을 수 있다.
base_model_frozen = Model(inputs=model.input,outputs=base_model_output,name='base_frozen')
base_model_frozen.trainable=False
base_model_frozen.summary()Model: "base_frozen"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
inputs (InputLayer) [(None, 28, 28, 1)] 0
conv2d (Conv2D) (None, 26, 26, 32) 320
maxpool (MaxPooling2D) (None, 13, 13, 32) 0
flatten (Flatten) (None, 5408) 0
=================================================================
Total params: 320
Trainable params: 0
Non-trainable params: 320
_________________________________________________________________dense_output = Dense(10,activation='softmax')(base_model_frozen.output)
digit_model_frozen = Model(inputs=base_model_frozen.input,outputs=dense_output)
digit_model_frozen.summary()Model: "model_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
inputs (InputLayer) [(None, 28, 28, 1)] 0
conv2d (Conv2D) (None, 26, 26, 32) 320
maxpool (MaxPooling2D) (None, 13, 13, 32) 0
flatten (Flatten) (None, 5408) 0
dense_2 (Dense) (None, 10) 54090
=================================================================
Total params: 54,410
Trainable params: 54,090
Non-trainable params: 320
_________________________________________________________________- 훈련가능한 파라미터 : 54090
- 훈련불가능 파라미터 : 320
digit_model_frozen.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['acc'])
history = digit_model_frozen.fit(x_train_in,y_train,
validation_data=(x_test_in,y_test),
epochs=10)Epoch 1/10
1875/1875 [==============================] - 6s 3ms/step - loss: 0.0223 - acc: 0.9931 - val_loss: 0.0544 - val_acc: 0.9833
Epoch 2/10
1875/1875 [==============================] - 5s 3ms/step - loss: 0.0179 - acc: 0.9948 - val_loss: 0.0556 - val_acc: 0.9840
Epoch 9/10
1875/1875 [==============================] - 5s 3ms/step - loss: 0.0062 - acc: 0.9984 - val_loss: 0.0635 - val_acc: 0.9835
Epoch 10/10
1875/1875 [==============================] - 5s 3ms/step - loss: 0.0055 - acc: 0.9987 - val_loss: 0.0670 - val_acc: 0.9832digit_model_frozen.get_layer('conv2d').trainableFalse- 훈련불가능 층수를 가져왔으므로 훈련가능여부가 false로 나온다.
- 조정해서 훈련 가능하게 만들 수 있다.
digit_model_frozen.get_layer('conv2d').trainable =Truedigit_model_frozen.summary()Model: "model_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
inputs (InputLayer) [(None, 28, 28, 1)] 0
conv2d (Conv2D) (None, 26, 26, 32) 320
maxpool (MaxPooling2D) (None, 13, 13, 32) 0
flatten (Flatten) (None, 5408) 0
dense_2 (Dense) (None, 10) 54090
=================================================================
Total params: 54,410
Trainable params: 54,410
Non-trainable params: 0
_________________________________________________________________
초보 개발자의 학습 저장용 블로그