교재 : 백견불여일타 딥러닝 입문 with 텐서플로우 2.x, 로드북
컨볼루션 신경망(Convolution Neural Network)
일단 적용해보기
from keras.datasets import fashion_mnist(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz
29515/29515 [==============================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz
26421880/26421880 [==============================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz
5148/5148 [==============================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz
4422102/4422102 [==============================] - 0s 0us/stepimport matplotlib.pyplot as plt
import numpy as npx_train.shape(60000, 28, 28)np.random.seed(777)
class_name = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
sample_size = 9
# 0~59999에서 무작위로 정수값 추출
random_idx = np.random.randint(60000, size = sample_size)
x_train = np.reshape(x_train/255,(-1,28,28,1)) # 맨 뒤에 흑백의 컬러값으로 1을 넣어줌 ex) grayscale=3
x_test = np.reshape(x_test/255,(-1,28,28,1))x_train.shape(60000, 28, 28, 1)x_train.min(),x_train.max()(0.0, 1.0)y_train[0]9from keras.utils import to_categorical# 각 데이터의 레이블을 범주형 형태로 변경
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)y_train[0]array([0., 0., 0., 0., 0., 0., 0., 0., 0., 1.], dtype=float32)from sklearn.model_selection import train_test_splitx_train,x_val,y_train,y_val = train_test_split(x_train,y_train,test_size=0.3,random_state=777)from keras.models import Sequential
from keras.layers import Dense, Flatten, Conv2D, MaxPool2D# 모델 구성하기
model = Sequential([
Conv2D(filters = 16, kernel_size = 3, strides = (1,1), padding = 'same', activation='relu', input_shape = (28, 28, 1)),
MaxPool2D(pool_size = (2,2), strides=2, padding='same'),
# 필터를 늘려서 층 수를 추가로 적용
Conv2D(filters = 32, kernel_size = 3, strides = (1,1), padding = 'same', activation='relu'),
MaxPool2D(pool_size = (2,2), strides=2, padding='same'),
Conv2D(filters = 64, kernel_size = 3, strides = (1,1), padding = 'same', activation='relu'),
MaxPool2D(pool_size = (2,2), strides=2, padding='same'),
Flatten(),
Dense(64, activation='relu'),
Dense(10, activation='softmax')
])
# 모델 학습시키기
model.compile(optimizer = 'adam', loss='categorical_crossentropy', metrics=['acc'])
model.summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 28, 28, 16) 160
max_pooling2d (MaxPooling2D (None, 14, 14, 16) 0
)
conv2d_1 (Conv2D) (None, 14, 14, 32) 4640
max_pooling2d_1 (MaxPooling (None, 7, 7, 32) 0
2D)
conv2d_2 (Conv2D) (None, 7, 7, 64) 18496
max_pooling2d_2 (MaxPooling (None, 4, 4, 64) 0
2D)
flatten (Flatten) (None, 1024) 0
dense (Dense) (None, 64) 65600
dense_1 (Dense) (None, 10) 650
=================================================================
Total params: 89,546
Trainable params: 89,546
Non-trainable params: 0
_________________________________________________________________model.fit(x_train,y_train,epochs=30,batch_size=32,validation_data=(x_val,y_val))Epoch 1/30
1313/1313 [==============================] - 49s 38ms/step - loss: 0.4646 - acc: 0.8325 - val_loss: 0.3444 - val_acc: 0.8775
Epoch 2/30
1313/1313 [==============================] - 53s 40ms/step - loss: 0.3265 - acc: 0.8824 - val_loss: 0.3151 - val_acc: 0.8857
Epoch 3/30
1313/1313 [==============================] - 51s 39ms/step - loss: 0.2817 - acc: 0.8967 - val_loss: 0.3020 - val_acc: 0.8896
Epoch 29/30
1313/1313 [==============================] - 51s 39ms/step - loss: 0.0347 - acc: 0.9874 - val_loss: 0.5286 - val_acc: 0.9118
Epoch 30/30
1313/1313 [==============================] - 46s 35ms/step - loss: 0.0365 - acc: 0.9864 - val_loss: 0.5274 - val_acc: 0.9129
<keras.callbacks.History at 0x7f65801b0f70>from keras.utils import plot_modelplot_model(model, './model.png',show_shapes=True)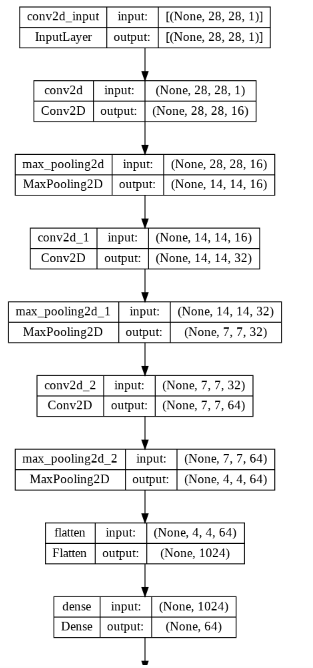
# 테스트 결과
pred = model.predict(x_test)313/313 [==============================] - 4s 11ms/step# 테스트 결과값 확인
pred[0]array([8.9170865e-14, 4.2583481e-25, 9.5145649e-20, 1.6950283e-20,
3.7162090e-18, 3.9351281e-07, 5.7551694e-23, 2.8031328e-09,
7.0376129e-18, 9.9999958e-01], dtype=float32)np.round(pred[0],2)array([0., 0., 0., 0., 0., 0., 0., 0., 0., 1.], dtype=float32)class_name[np.argmax(np.round(pred[0],2))]'Ankle boot'x_test.shape(10000, 28, 28, 1)# 출력
plt.imshow(x_test[0].reshape((28,28)),cmap='gray') # (28,28,1)인 3차원이므로 reshape로 형태변환을 해줘야 함<matplotlib.image.AxesImage at 0x7f657f8499a0> 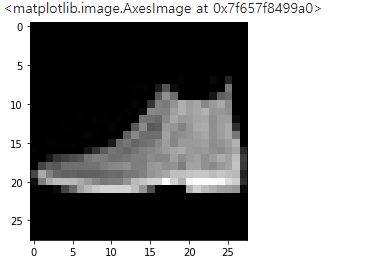
# 모델 저장. 경로 지정 후 이름을 추가로 써줘야 함
model.save_weights('/content/drive/MyDrive/Colab Notebooks/sesac_deeplearning/model/07_cnn_fashion_mnist/model')# 신규 모델 구성
model1 = Sequential([
Conv2D(filters = 16, kernel_size = 3, strides = (1,1), padding = 'same', activation='relu', input_shape = (28, 28, 1)),
MaxPool2D(pool_size = (2,2), strides=2, padding='same'),
Conv2D(filters = 32, kernel_size = 3, strides = (1,1), padding = 'same', activation='relu'),
MaxPool2D(pool_size = (2,2), strides=2, padding='same'),
Conv2D(filters = 64, kernel_size = 3, strides = (1,1), padding = 'same', activation='relu'),
MaxPool2D(pool_size = (2,2), strides=2, padding='same'),
Flatten(),
Dense(64, activation='relu'),
Dense(10, activation='softmax')
])model1.load_weights('/content/drive/MyDrive/Colab Notebooks/sesac_deeplearning/model/07_cnn_fashion_mnist/model')<tensorflow.python.training.tracking.util.CheckpointLoadStatus at 0x7f657f35c550>pred = model1.predict(x_test)313/313 [==============================] - 3s 10ms/step# 신규 모델 결과 확인
np.round(pred[0],2)array([0., 0., 0., 0., 0., 0., 0., 0., 0., 1.], dtype=float32)컨볼루션층과 풀링층
- 완전연결층은 1차원 배열의 형태라 공간 정보를 손실하게 된다.
- 컨볼루션층은 이미지 픽셀 사이의 관계를 고려하기 때문에 공간정보를 유지한다.
- 필터(filter=kernel)를 정의하여 사용할 수 있음.
- 필터는 짝수 개면 비대칭이 되므로, 홀수 개로 지정하여야 한다.
from keras.datasets import fashion_mnist# 데이터 다운로드
(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz
29515/29515 [==============================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz
26421880/26421880 [==============================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz
5148/5148 [==============================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz
4422102/4422102 [==============================] - 0s 0us/stepimport matplotlib.pyplot as pltplt.imshow(x_train[0],cmap='gray')<matplotlib.image.AxesImage at 0x7faa7d395d00>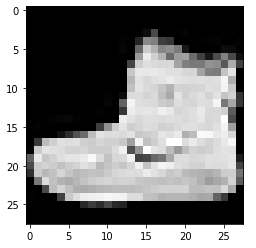
import numpy as np
import cv2# 가로선을 추출하기 위한 필터
h_filter = np.array([[1.,2.,1.],
[0.,0.,0.],
[-1.,-2.,-1.]])
# 세로선을 추출하기 위한 필터
v_filter = np.array([[1.,0.,-1.],
[2.,0.,-2.],
[1.,0.,-1.]])# 계산의 편의를 위해 이미지를 (27, 27)로 줄임.
test_image = cv2.resize(x_train[0],(27,27))
test_image.shape(27, 27)# 사이즈 변환
image_size = test_image.shape[0]
output_size = int((image_size - 3)/1 + 1) # 필터가 세개이므로 3을 빼줌. 그 다음에 strider + 1로 나눔
output_size25filter_size = 3
def get_filtered_image(filter):
filtered_image = np.zeros((output_size,output_size))
for i in range(output_size):
for j in range(output_size):
indice_image = test_image[i:(i+filter_size),j:(j+filter_size)] * filter # i*j에 filter_size(=3)을을 더함.
indice_sum = np.sum(indice_image)
if(indice_sum>255):
indice_sum =255
filtered_image[i,j] = indice_sum
return filtered_imageh_filtered_image = get_filtered_image(h_filter)
v_filtered_image = get_filtered_image(v_filter)plt.subplot(1,2,1)
plt.title('vertical')
plt.imshow(v_filtered_image,cmap='gray')
plt.subplot(1,2,2)
plt.title('horizontal')
plt.imshow(h_filtered_image,cmap='gray')
plt.show()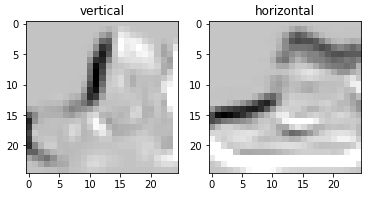
# 수직 + 수평 최종 결과
sobel_image = np.sqrt(np.square(h_filtered_image) + np.square(v_filtered_image))
plt.imshow(sobel_image,cmap='gray')<matplotlib.image.AxesImage at 0x7faa6f66b610>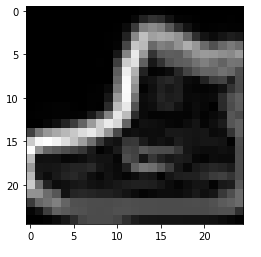
- 스트라이드 : 필터가 움직이는 크기를 말한다. 예를 들어 데이터셋 5X5에서 3X3 필터가 stride 1이면 3X3가지, stride가 2이면 2X2가 나온다.
- 패딩 : 가장자리에 칸을 추가하여 입력 데이터와 동일한 사이즈를 얻기 위해 사용
풀링 연산 알아보기
- 평균 풀링 : 평균값 이용
- 최대 풀링 : 최댓값 이용
- 해당 윈도우에서 평균or최댓값을 특징값으로 사용함
- 최대 풀링은 신경망에 이동 불변성을 가지게 해주고, 모델 파라미터 수를 줄여줌. 1X1스트라이드 사용을 권장함.
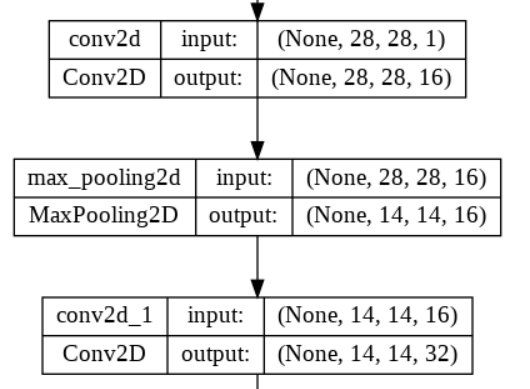
- 최대 풀링 사용 후 파라미터 수가 반으로 줄어든 걸 볼 수 있다.
from keras.datasets import cifar10CIFAR-10 데이터셋 다운받기
(x_train, y_train), (x_test, y_test) = cifar10.load_data()Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
170498071/170498071 [==============================] - 13s 0us/stepx_train.shape,x_test.shape((50000, 32, 32, 3), (10000, 32, 32, 3))y_train[0]array([6], dtype=uint8)x_train.min(), x_train.max()(0, 255)import matplotlib.pyplot as plt
import numpy as npCIFAR-10 데이터 그려보기
np.random.seed(777)
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
sample_size = 9
random_idx = np.random.randint(50000, size=sample_size)
plt.figure(figsize=(5,5))
for i, idx in enumerate(random_idx):
plt.subplot(3,3,i+1)
plt.xticks([])
plt.yticks([])
plt.imshow(x_train[idx], cmap='gray')
plt.xlabel(class_names[int(y_train[idx])])
plt.show()
CIFAR-10 데이터셋 전처리 과정
# 채널별로 평균과 표준편차 구하기
x_mean = np.mean(x_train,axis=(0,1,2))
x_std = np.std(x_train, axis = (0,1,2))
x_train = (x_train - x_mean) / x_std
x_test = (x_test - x_mean) / x_stdx_train.min(), x_train.max()(-1.98921279913639, 2.1267894095169213)np.mean(x_train)5.2147915615326686e-17np.round(np.mean(x_train),1)0.0from sklearn.model_selection import train_test_splitx_train, x_val, y_train, y_val = train_test_split(x_train,y_train,test_size=0.3,random_state=777)x_train.shape,x_val.shape((35000, 32, 32, 3), (15000, 32, 32, 3))# from keras.utils import to_categorical
# y_train = to_categorical(y_train)
# y_test = to_categorical(y_test)from keras.models import Sequential
from keras.layers import Conv2D, MaxPool2D, Flatten, Dense
from keras.optimizers import Adamfrom keras import activations
from pyparsing import actions
model = Sequential([
Conv2D(filters=32,kernel_size=3,padding='same',activation='relu',input_shape=(32,32,3)),
Conv2D(filters=32,kernel_size=3,padding='same',activation='relu'),
MaxPool2D(pool_size=(2,2),strides=2,padding='same'),
Conv2D(filters=64,kernel_size=3,padding='same',activation='relu'),
Conv2D(filters=64,kernel_size=3,padding='same',activation='relu'),
MaxPool2D(pool_size=(2,2),strides=2,padding='same'),
Conv2D(filters=128,kernel_size=3,padding='same',activation='relu'),
Conv2D(filters=128,kernel_size=3,padding='same',activation='relu'),
MaxPool2D(pool_size=(2,2),strides=2,padding='same'),
Flatten(),
Dense(256, activation = 'relu'),
Dense(10, activation = 'softmax')
])
model.compile(optimizer = Adam(1e-4), loss = 'sparse_categorical_crossentropy',metrics=['acc'])history = model.fit(x_train,y_train,epochs=30,batch_size=32,validation_data=(x_val,y_val))Epoch 1/30
1094/1094 [==============================] - 16s 7ms/step - loss: 1.6539 - acc: 0.4047 - val_loss: 1.4130 - val_acc: 0.4871
Epoch 2/30
1094/1094 [==============================] - 7s 7ms/step - loss: 1.2898 - acc: 0.5387 - val_loss: 1.2232 - val_acc: 0.5573
Epoch 3/30
1094/1094 [==============================] - 7s 7ms/step - loss: 1.1068 - acc: 0.6098 - val_loss: 1.0855 - val_acc: 0.6133
Epoch 28/30
1094/1094 [==============================] - 7s 7ms/step - loss: 0.0478 - acc: 0.9837 - val_loss: 1.7936 - val_acc: 0.7169
Epoch 29/30
1094/1094 [==============================] - 7s 7ms/step - loss: 0.0442 - acc: 0.9852 - val_loss: 1.8437 - val_acc: 0.7233
Epoch 30/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.0374 - acc: 0.9878 - val_loss: 1.7594 - val_acc: 0.7243신경망 시각화해보기
- 딥러닝 신경망의 큰 단점 중 하나는 모델을 쉽게 해석할 수 없다는 것.
- 의료나 금융에서는 소비자에게 설명 못하는 게 큰 단점
- 설명 가능한 AI(XAI:eXplainable AI) : 모델을 설명하기 위해 등장한 개념
- 모델이 학습한 특징을 시각화하는 게 하나의 방법이 될 수 있음
- 특성맵을 시각화해보는 작업 실습
import matplotlib.pyplot as plt
his_dict = history.history
loss = his_dict['loss']
val_loss = his_dict['val_loss']
epochs = range(1, len(loss)+1)
fig = plt.figure(figsize=(10,5))
ax1 = fig.add_subplot(1,2,1)
ax1.plot(epochs,loss,color='blue',label='train_loss')
ax1.plot(epochs,val_loss,color='orange',label='val_loss')
ax1.set_title('train and val loss')
ax1.legend()
acc = his_dict['acc']
val_acc = his_dict['val_acc']
ax2 = fig.add_subplot(1,2,2)
ax2.plot(epochs,acc,color='blue',label='train_acc')
ax2.plot(epochs,val_acc,color='orange',label='val_acc')
ax2.set_title('train and val acc')
ax2.legend()
plt.show()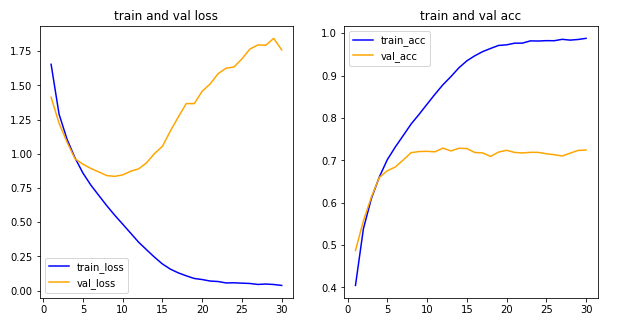
get_output = [layer.output for layer in model.layers]
get_output[<KerasTensor: shape=(None, 32, 32, 32) dtype=float32 (created by layer 'conv2d')>,
<KerasTensor: shape=(None, 32, 32, 32) dtype=float32 (created by layer 'conv2d_1')>,
<KerasTensor: shape=(None, 16, 16, 32) dtype=float32 (created by layer 'max_pooling2d')>,
<KerasTensor: shape=(None, 16, 16, 64) dtype=float32 (created by layer 'conv2d_2')>,
<KerasTensor: shape=(None, 16, 16, 64) dtype=float32 (created by layer 'conv2d_3')>,
<KerasTensor: shape=(None, 8, 8, 64) dtype=float32 (created by layer 'max_pooling2d_1')>,
<KerasTensor: shape=(None, 8, 8, 128) dtype=float32 (created by layer 'conv2d_4')>,
<KerasTensor: shape=(None, 8, 8, 128) dtype=float32 (created by layer 'conv2d_5')>,
<KerasTensor: shape=(None, 4, 4, 128) dtype=float32 (created by layer 'max_pooling2d_2')>,
<KerasTensor: shape=(None, 2048) dtype=float32 (created by layer 'flatten')>,
<KerasTensor: shape=(None, 256) dtype=float32 (created by layer 'dense')>,
<KerasTensor: shape=(None, 10) dtype=float32 (created by layer 'dense_1')>]x_test[1].shape(32, 32, 3)visual_model = tf.keras.models.Model(inputs=model.input,outputs=get_output)
test_img = np.expand_dims(x_test[1], axis=0)
test_img.shape(1, 32, 32, 3)feature_maps = visual_model.predict(test_img)
feature_maps1/1 [==============================] - 0s 237ms/stepfor layer_name,feature_map in zip(get_layer_name,feature_maps):
# Dense층은 제외
if (len(feature_map.shape)==4):
img_size = feature_map.shape[1]
features = feature_map.shape[-1]
display_grid = np.zeros((img_size,img_size*features))
# 각 특성맵을 이어붙여서 반복함.
for i in range(features):
x = feature_map[0,:,:,i]
x -= x.mean()
x /= x.std()
x *= 64
x += 128
x = np.clip(x,0,255).astype('uint8')
display_grid[:,i*img_size:(i+1)*img_size] = x # 그리드에 특성맵을 한장씩 붙이는 위치를 지정해준다.
plt.figure(figsize=(features,2+1./features))
plt.title(layer_name,fontsize=20)
plt.grid(False)
plt.imshow(display_grid,aspect='auto')<ipython-input-26-24ed10875a76>:11: RuntimeWarning: invalid value encountered in true_divide
x /= x.std()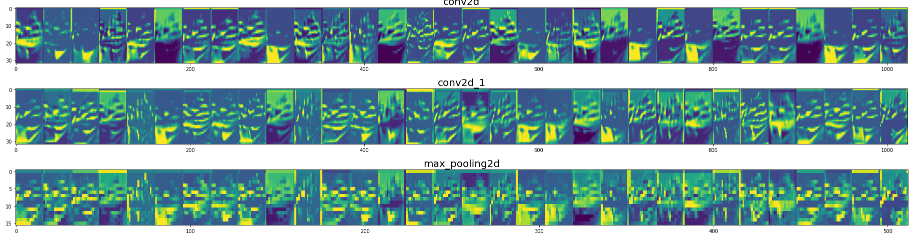
과대적합 피하기
- 과대적합 방지를 위한 3가지 방법
- 어디까지나 예방책일 뿐 근본적인 해결책은 아님
규제화 함수 사용하기
- L1이나 L2등의 규제화 함수를 이용하여 모델의 복잡도를 제한시킬 수 있음
from keras.datasets import cifar10
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import train_test_split
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
# 채널별로 평균과 표준편차 구하기기
x_mean = np.mean(x_train,axis=(0,1,2))
x_std = np.std(x_train, axis = (0,1,2))
x_train = (x_train - x_mean) / x_std
x_test = (x_test - x_mean) / x_std
x_train, x_val, y_train, y_val = train_test_split(x_train,y_train,test_size=0.3,random_state=777)Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
170498071/170498071 [==============================] - 8s 0us/stepfrom keras.models import Sequential
from keras.layers import Conv2D, MaxPool2D, Flatten, Dense
from keras.optimizers import Adam
from keras.regularizers import l2
model = Sequential([
Conv2D(filters=32,kernel_size=3,padding='same',activation='relu',input_shape=(32,32,3)),
Conv2D(filters=32,kernel_size=3,padding='same',activation='relu'),
MaxPool2D(pool_size=(2,2),strides=2,padding='same'),
Conv2D(filters=64,kernel_size=3,padding='same',activation='relu'),
Conv2D(filters=64,kernel_size=3,padding='same',activation='relu'),
MaxPool2D(pool_size=(2,2),strides=2,padding='same'),
Conv2D(filters=128,kernel_size=3,padding='same',activation='relu'),
Conv2D(filters=128,kernel_size=3,padding='same',activation='relu'),
MaxPool2D(pool_size=(2,2),strides=2,padding='same'),
Flatten(),
Dense(256, activation = 'relu', kernel_regularizer = l2(0.001)),
Dense(10, activation = 'softmax')
])
model.compile(optimizer = Adam(1e-4), loss = 'sparse_categorical_crossentropy',metrics=['acc'])
history = model.fit(x_train,y_train,epochs=30,batch_size=32,validation_data=(x_val,y_val))Epoch 1/30
1094/1094 [==============================] - 21s 9ms/step - loss: 1.8911 - acc: 0.4160 - val_loss: 1.5588 - val_acc: 0.5231
Epoch 2/30
1094/1094 [==============================] - 9s 9ms/step - loss: 1.4633 - acc: 0.5561 - val_loss: 1.3681 - val_acc: 0.5793
Epoch 3/30
1094/1094 [==============================] - 10s 9ms/step - loss: 1.2645 - acc: 0.6245 - val_loss: 1.2592 - val_acc: 0.6083
Epoch 28/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.1669 - acc: 0.9797 - val_loss: 1.5413 - val_acc: 0.7316
Epoch 29/30
1094/1094 [==============================] - 8s 7ms/step - loss: 0.1563 - acc: 0.9826 - val_loss: 1.7126 - val_acc: 0.7165
Epoch 30/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.1536 - acc: 0.9830 - val_loss: 1.6584 - val_acc: 0.7255import matplotlib.pyplot as plt
his_dict = history.history
loss = his_dict['loss']
val_loss = his_dict['val_loss']
epochs = range(1, len(loss)+1)
fig = plt.figure(figsize=(10,5))
ax1 = fig.add_subplot(1,2,1)
ax1.plot(epochs,loss,color='blue',label='train_loss')
ax1.plot(epochs,val_loss,color='orange',label='val_loss')
ax1.set_title('loss')
ax1.legend()
acc = his_dict['acc']
val_acc = his_dict['val_acc']
ax2 = fig.add_subplot(1,2,2)
ax2.plot(epochs,acc,color='blue',label='train_acc')
ax2.plot(epochs,val_acc,color='orange',label='val_acc')
ax2.set_title('acc')
ax2.legend()
plt.show()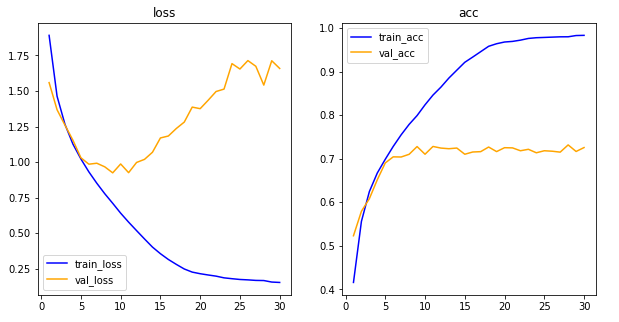
- 이전 그래프보다 꺾이는 각도가 더 안정적임
드롭아웃
- 과대적합을 피하기 위해 학습동안 일부 유닛을 제외(드롭)함.
- 제외한 만큼 제외하지 않은 유닛을 집중적으로 학습. 선택과 집중
from keras.datasets import cifar10
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import train_test_split
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
# 채널별로 평균과 표준편차 구하기기
x_mean = np.mean(x_train,axis=(0,1,2))
x_std = np.std(x_train, axis = (0,1,2))
x_train = (x_train - x_mean) / x_std
x_test = (x_test - x_mean) / x_std
x_train, x_val, y_train, y_val = train_test_split(x_train,y_train,test_size=0.3,random_state=777)Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
170498071/170498071 [==============================] - 15s 0us/stepfrom keras.models import Sequential
from keras.layers import Conv2D, MaxPool2D, Flatten, Dense, Dropout
from keras.optimizers import Adam
model = Sequential([
Conv2D(filters=32,kernel_size=3,padding='same',activation='relu',input_shape=(32,32,3)),
Conv2D(filters=32,kernel_size=3,padding='same',activation='relu'),
MaxPool2D(pool_size=(2,2),strides=2,padding='same'),
Conv2D(filters=64,kernel_size=3,padding='same',activation='relu'),
Conv2D(filters=64,kernel_size=3,padding='same',activation='relu'),
MaxPool2D(pool_size=(2,2),strides=2,padding='same'),
Conv2D(filters=128,kernel_size=3,padding='same',activation='relu'),
Conv2D(filters=128,kernel_size=3,padding='same',activation='relu'),
MaxPool2D(pool_size=(2,2),strides=2,padding='same'),
Dropout(0.2),
Flatten(),
Dense(256, activation = 'relu'),
Dense(10, activation = 'softmax')
])
model.compile(optimizer = Adam(1e-4), loss = 'sparse_categorical_crossentropy',metrics=['acc'])
history = model.fit(x_train,y_train,epochs=30,batch_size=32,validation_data=(x_val,y_val))Epoch 1/30
1094/1094 [==============================] - 17s 7ms/step - loss: 1.6590 - acc: 0.3996 - val_loss: 1.3811 - val_acc: 0.4973
Epoch 2/30
1094/1094 [==============================] - 7s 6ms/step - loss: 1.3029 - acc: 0.5350 - val_loss: 1.1778 - val_acc: 0.5735
Epoch 3/30
1094/1094 [==============================] - 7s 6ms/step - loss: 1.1445 - acc: 0.5943 - val_loss: 1.0843 - val_acc: 0.6103
Epoch 28/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.1084 - acc: 0.9623 - val_loss: 1.0363 - val_acc: 0.7561
Epoch 29/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.1062 - acc: 0.9633 - val_loss: 1.0809 - val_acc: 0.7517
Epoch 30/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.0933 - acc: 0.9675 - val_loss: 1.1280 - val_acc: 0.7526import matplotlib.pyplot as plt
his_dict = history.history
loss = his_dict['loss']
val_loss = his_dict['val_loss']
epochs = range(1, len(loss)+1)
fig = plt.figure(figsize=(10,5))
ax1 = fig.add_subplot(1,2,1)
ax1.plot(epochs,loss,color='blue',label='train_loss')
ax1.plot(epochs,val_loss,color='orange',label='val_loss')
ax1.set_title('loss')
ax1.legend()
acc = his_dict['acc']
val_acc = his_dict['val_acc']
ax2 = fig.add_subplot(1,2,2)
ax2.plot(epochs,acc,color='blue',label='train_acc')
ax2.plot(epochs,val_acc,color='orange',label='val_acc')
ax2.set_title('acc')
ax2.legend()
plt.show()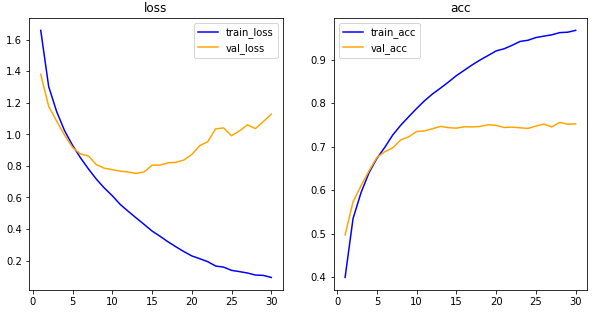
배치 정규화
- 직접적으로 과대적합을 피하기 위한 방법은 아니지만, 드롭아웃과 비교가 많이 됨.
- 출력값 분포의 범위를 줄여주어서 불확실성을 감소시킴.
from keras.datasets import cifar10
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import train_test_split
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
# 채널별로 평균과 표준편차 구하기기
x_mean = np.mean(x_train,axis=(0,1,2))
x_std = np.std(x_train, axis = (0,1,2))
x_train = (x_train - x_mean) / x_std
x_test = (x_test - x_mean) / x_std
x_train, x_val, y_train, y_val = train_test_split(x_train,y_train,test_size=0.3,random_state=777)from keras.models import Sequential
from keras.layers import Conv2D, MaxPool2D, Flatten, Dense, Activation, BatchNormalization
from keras.optimizers import Adam
model = Sequential([
Conv2D(filters=32,kernel_size=3,padding='same',input_shape=(32, 32, 3)),
BatchNormalization(),
Activation('relu'),
Conv2D(filters=32,kernel_size=3,padding='same'),
BatchNormalization(),
Activation('relu'),
MaxPool2D(pool_size=(2,2),strides=2,padding='same'),
Conv2D(filters=64,kernel_size=3,padding='same'),
BatchNormalization(),
Activation('relu'),
Conv2D(filters=64,kernel_size=3,padding='same'),
BatchNormalization(),
Activation('relu'),
MaxPool2D(pool_size=(2,2),strides=2,padding='same'),
Conv2D(filters=128,kernel_size=3,padding='same'),
BatchNormalization(),
Activation('relu'),
Conv2D(filters=128,kernel_size=3,padding='same'),
BatchNormalization(),
Activation('relu'),
MaxPool2D(pool_size=(2,2),strides=2,padding='same'),
Flatten(),
Dense(256),
BatchNormalization(),
Activation('relu'),
Dense(10, activation = 'softmax')
])
model.compile(optimizer = Adam(1e-4), loss = 'sparse_categorical_crossentropy',metrics=['acc'])
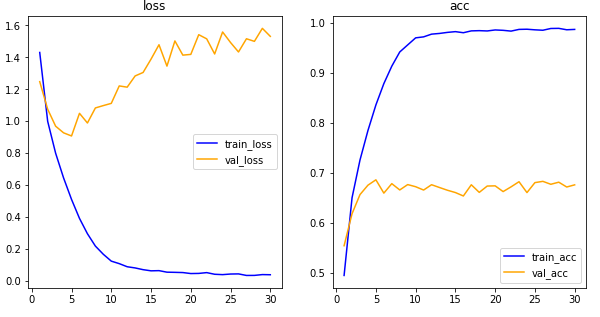
history = model.fit(x_train,y_train,epochs=30,batch_size=32,validation_data=(x_val,y_val))Epoch 1/30
1094/1094 [==============================] - 16s 10ms/step - loss: 1.4305 - acc: 0.4954 - val_loss: 1.2480 - val_acc: 0.5548
Epoch 2/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.9997 - acc: 0.6507 - val_loss: 1.0756 - val_acc: 0.6189
Epoch 3/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.8003 - acc: 0.7263 - val_loss: 0.9694 - val_acc: 0.6571
Epoch 28/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.0361 - acc: 0.9897 - val_loss: 1.5000 - val_acc: 0.6819
Epoch 29/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.0411 - acc: 0.9868 - val_loss: 1.5814 - val_acc: 0.6723
Epoch 30/30
1094/1094 [==============================] - 10s 9ms/step - loss: 0.0402 - acc: 0.9875 - val_loss: 1.5313 - val_acc: 0.6766import matplotlib.pyplot as plt
his_dict = history.history
loss = his_dict['loss']
val_loss = his_dict['val_loss']
epochs = range(1, len(loss)+1)
fig = plt.figure(figsize=(10,5))
ax1 = fig.add_subplot(1,2,1)
ax1.plot(epochs,loss,color='blue',label='train_loss')
ax1.plot(epochs,val_loss,color='orange',label='val_loss')
ax1.set_title('loss')
ax1.legend()
acc = his_dict['acc']
val_acc = his_dict['val_acc']
ax2 = fig.add_subplot(1,2,2)
ax2.plot(epochs,acc,color='blue',label='train_acc')
ax2.plot(epochs,val_acc,color='orange',label='val_acc')
ax2.set_title('acc')
ax2.legend()
plt.show()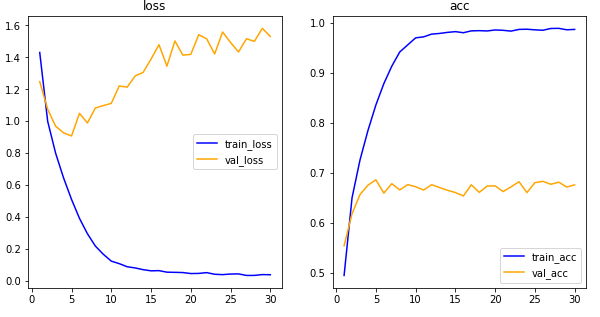
비교용 그래프 정리
- 초기 CIFAR-10
- 규제화 함수 사용
- 드롭아웃 사용
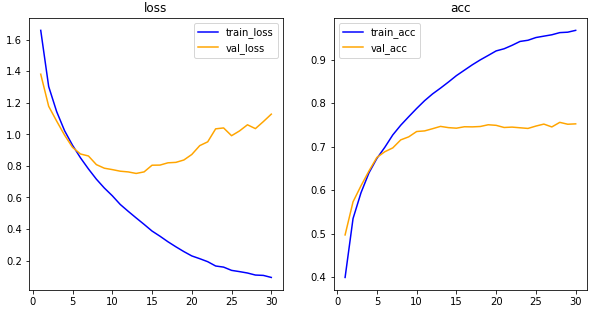
- 배치 정규화 사용

초보 개발자의 학습 저장용 블로그