Euroset
- 실습용 데이터
import tensorflow as tf
import numpy as np
import json
import matplotlib.pyplot as plt
import tensorflow_datasets as tfdsdata_dir = 'dataset/'
tfds.load('eurosat/rgb', split=['train[:80%]','train[80%:]'],
shuffle_files=True, # 내용을 섞어서 가져옴
as_supervised=True, # 딕셔너리 형식으로 가져옴
with_info=True, # 정보도 같이 가져옴
data_dir=data_dir) # 가져올 위치Downloading and preparing dataset 89.91 MiB (download: 89.91 MiB, generated: Unknown size, total: 89.91 MiB) to dataset/eurosat/rgb/2.0.0...
Dl Completed...: 0 url [00:00, ? url/s]
Dl Size...: 0 MiB [00:00, ? MiB/s]
Extraction completed...: 0 file [00:00, ? file/s]
Generating splits...: 0%| | 0/1 [00:00<?, ? splits/s]
Generating train examples...: 0%| | 0/27000 [00:00<?, ? examples/s]
Shuffling dataset/eurosat/rgb/2.0.0.incompleteNKC38O/eurosat-train.tfrecord*...: 0%| | 0/27000 [00:…
Dataset eurosat downloaded and prepared to dataset/eurosat/rgb/2.0.0. Subsequent calls will reuse this data.
([<PrefetchDataset element_spec=(TensorSpec(shape=(64, 64, 3), dtype=tf.uint8, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))>,
<PrefetchDataset element_spec=(TensorSpec(shape=(64, 64, 3), dtype=tf.uint8, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))>],
tfds.core.DatasetInfo(
name='eurosat',
full_name='eurosat/rgb/2.0.0',
description="""
EuroSAT dataset is based on Sentinel-2 satellite images covering 13 spectral
bands and consisting of 10 classes with 27000 labeled and
geo-referenced samples.
Two datasets are offered:
- rgb: Contains only the optical R, G, B frequency bands encoded as JPEG image.
- all: Contains all 13 bands in the original value range (float32).
URL: https://github.com/phelber/eurosat
""",
config_description="""
Sentinel-2 RGB channels
""",
homepage='https://github.com/phelber/eurosat',
data_path='dataset/eurosat/rgb/2.0.0',
file_format=tfrecord,
download_size=89.91 MiB,
dataset_size=89.50 MiB,
features=FeaturesDict({
'filename': Text(shape=(), dtype=tf.string),
'image': Image(shape=(64, 64, 3), dtype=tf.uint8),
'label': ClassLabel(shape=(), dtype=tf.int64, num_classes=10),
}),
supervised_keys=('image', 'label'),
disable_shuffling=False,
splits={
'train': <SplitInfo num_examples=27000, num_shards=1>,
},
citation="""@misc{helber2017eurosat,
title={EuroSAT: A Novel Dataset and Deep Learning Benchmark for Land Use and Land Cover Classification},
author={Patrick Helber and Benjamin Bischke and Andreas Dengel and Damian Borth},
year={2017},
eprint={1709.00029},
archivePrefix={arXiv},
primaryClass={cs.CV}
}""",
))data_dir = 'dataset/'
(train_ds,valid_ds),info = tfds.load('eurosat/rgb', split=['train[:80%]','train[80%:]'],
shuffle_files=True, # 내용을 섞어서 가져욤
as_supervised=True, # 딕셔너리 형식으로 가져옴
with_info=True, # 정보도 같이 가져옴
data_dir=data_dir) # 가져올 위치train_ds,valid_ds(<PrefetchDataset element_spec=(TensorSpec(shape=(64, 64, 3), dtype=tf.uint8, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))>,
<PrefetchDataset element_spec=(TensorSpec(shape=(64, 64, 3), dtype=tf.uint8, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))>)tfds.show_examples(train_ds,info)
tfds.as_dataframe(valid_ds.take(5),info)| image | label | |
|---|---|---|
| 0 | 5 (Pasture) | |
| 1 | 7 (Residential) | |
| 2 | 0 (AnnualCrop) | |
| 3 | 1 (Forest) | |
| 4 | 0 (AnnualCrop) |
num_classes = info.features['label'].num_classes
num_classes10# 개별 데이터값 확인
print(info.features['label'].int2str(7))Residentialbatch_size=64 # 한번에 올리는 데이터 숫자
buffer_size=1000 # 미리 준비해두는 데이터 단위. 배치사이즈수량이 빠져나가면 다시 원데이터에서 같은 수량을 가져온다.
def preprocess_data(image,label):
image = tf.cast(image,tf.float32)/255.
return image, label
train_data = train_ds.map(preprocess_data,num_parallel_calls=tf.data.AUTOTUNE) # 오토튠은 데이터를 제공할 때 병렬처리를 해줌.
valid_data = valid_ds.map(preprocess_data,num_parallel_calls=tf.data.AUTOTUNE)
train_data = train_data.shuffle(buffer_size).batch(batch_size).prefetch(tf.data.AUTOTUNE)
valid_data = valid_data.batch(batch_size).cache().prefetch(tf.data.AUTOTUNE) # 섞을 필요가 없어 셔플 미사용.from keras import Sequential
from keras.layers import Dense, Dropout, Flatten,Conv2D,MaxPooling2D,BatchNormalization
def build_model():
model = Sequential([
BatchNormalization(),
Conv2D(32,(3,3), padding='same',activation='relu'),
MaxPooling2D((2,2)),
BatchNormalization(),
Conv2D(64,(3,3), padding='same',activation='relu'),
MaxPooling2D((2,2)),
Flatten(),
Dense(128,activation='relu'),
Dropout(0.3),
Dense(64,activation='relu'),
Dropout(0.3),
Dense(num_classes,activation='softmax')
])
return model
model = build_model()model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['acc'])history = model.fit(train_data,validation_data=valid_data,epochs=50)Epoch 1/50
338/338 [==============================] - 15s 21ms/step - loss: 1.6741 - acc: 0.4277 - val_loss: 1.6587 - val_acc: 0.4246
Epoch 2/50
338/338 [==============================] - 4s 13ms/step - loss: 1.2652 - acc: 0.5557 - val_loss: 1.0137 - val_acc: 0.6717
Epoch 49/50
338/338 [==============================] - 5s 14ms/step - loss: 0.1965 - acc: 0.9435 - val_loss: 0.5312 - val_acc: 0.8728
Epoch 50/50
338/338 [==============================] - 4s 13ms/step - loss: 0.1959 - acc: 0.9439 - val_loss: 0.5340 - val_acc: 0.8785def plot_loss_acc(history,epoch):
loss,val_loss = history.history['loss'],history.history['val_loss']
acc,val_acc = history.history['acc'],history.history['val_acc']
fig, axes = plt.subplots(1,2,figsize=(12,4))
axes[0].plot(range(1, epoch+1), loss, label='train_loss')
axes[0].plot(range(1, epoch+1), val_loss, label='valid_loss')
axes[0].legend(loc='best')
axes[0].set_title('Loss')
axes[1].plot(range(1, epoch+1), acc, label='train_acc')
axes[1].plot(range(1, epoch+1), val_acc, label='valid_acc')
axes[1].legend(loc='best')
axes[1].set_title('Acc')
plt.show()
plot_loss_acc(history,50)
image_batch , label_batch = next(iter(train_data.take(1)))
image_batch.shape,label_batch.shape(TensorShape([64, 64, 64, 3]), TensorShape([64]))image = image_batch[0]
label = label_batch[0].numpy()
image,label증강 데이터 작성 예시
- 일부 경우에는 적정 범위를 벗어나니 경고 메시지가 출력됨.
plt.imshow(image)
plt.title(info.features['label'].int2str(label))Text(0.5, 1.0, 'Industrial')
def plot_augmentation(original,augmented):
fig,axes = plt.subplots(1,2,figsize=(12,4))
axes[0].imshow(original)
axes[0].set_title('Original')
axes[1].imshow(augmented)
axes[1].set_title('Augmented')
plt.show()plot_augmentation(image,tf.image.flip_left_right(image))
plot_augmentation(image,tf.image.flip_up_down(image)) 
plot_augmentation(image,tf.image.rot90(image))
plot_augmentation(image,tf.image.transpose(image))
plot_augmentation(image,tf.image.central_crop(image,central_fraction=0.6))
plot_augmentation(image,tf.image.resize_with_crop_or_pad(image, 64+20, 64+20))
plot_augmentation(image,tf.image.adjust_brightness(image,0.3))WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
plot_augmentation(image,tf.image.adjust_saturation(image,0.5))
plot_augmentation(image,tf.image.adjust_contrast(image,2))WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
plot_augmentation(image,tf.image.random_crop(image,size=[64,64,3]))
batch_size=64
buffer_size = 1000
def preprocess_data(image,label):
image = tf.image.random_flip_left_right(image)
image = tf.image.random_flip_up_down(image)
image = tf.image.random_brightness(image, max_delta=0.3)
image = tf.image.random_contrast(image,0.5,1.5)
image = tf.cast(image,tf.float32)/255.
return image,label
train_aug = train_ds.map(preprocess_data,num_parallel_calls=tf.data.AUTOTUNE)
valid_aug = valid_ds.map(preprocess_data,num_parallel_calls=tf.data.AUTOTUNE)
train_aug = train_aug.shuffle(buffer_size).batch(batch_size).prefetch(tf.data.AUTOTUNE)
valid_aug = valid_aug.batch(batch_size).cache().prefetch(tf.data.AUTOTUNE)image_batch , label_batch = next(iter(train_aug.take(1)))
image_batch.shape,label_batch.shape
image = image_batch[0]
label = label_batch[0].numpy()
# image,label
plt.imshow(image)
plt.title(info.features['label'].int2str(label))Text(0.5, 1.0, 'River')
aug_model = build_model()
aug_model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['acc'])
aug_history = aug_model.fit(train_aug,validation_data=valid_aug,epochs=50)
plot_loss_acc(aug_history,50)Epoch 1/50
338/338 [==============================] - 8s 22ms/step - loss: 2.0178 - acc: 0.2523 - val_loss: 1.7844 - val_acc: 0.3406
Epoch 2/50
338/338 [==============================] - 9s 25ms/step - loss: 1.7576 - acc: 0.3144 - val_loss: 1.5007 - val_acc: 0.4502
Epoch 49/50
338/338 [==============================] - 7s 20ms/step - loss: 0.6050 - acc: 0.8011 - val_loss: 0.5275 - val_acc: 0.8196
Epoch 50/50
338/338 [==============================] - 7s 20ms/step - loss: 0.5799 - acc: 0.8091 - val_loss: 0.5147 - val_acc: 0.8265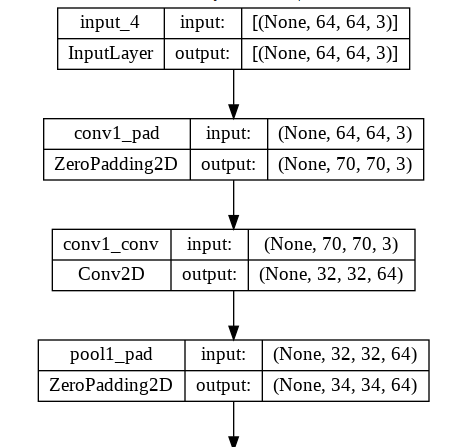
- 이 순서도는 크기가 커져서 중략하였음.
from keras.applications import ResNet50V2
from keras.utils import plot_model
pre_trained_base = ResNet50V2(include_top=False,input_shape=[64,64,3])
pre_trained_base.trainable = False
plot_model(pre_trained_base,show_shapes=True,show_layer_names=True)Output hidden; open in https://colab.research.google.com to view.def build_transfer_model():
model = Sequential([
pre_trained_base,
Flatten(),
Dense(128,activation='relu'),
Dropout(0.3),
Dense(64,activation='relu'),
Dropout(0.3),
Dense(num_classes,activation='softmax')
])
return modelt_model = build_transfer_model()
t_model.summary()Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
resnet50v2 (Functional) (None, 2, 2, 2048) 23564800
flatten_3 (Flatten) (None, 8192) 0
dense_9 (Dense) (None, 128) 1048704
dropout_6 (Dropout) (None, 128) 0
dense_10 (Dense) (None, 64) 8256
dropout_7 (Dropout) (None, 64) 0
dense_11 (Dense) (None, 10) 650
=================================================================
Total params: 24,622,410
Trainable params: 1,057,610
Non-trainable params: 23,564,800
_________________________________________________________________t_model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['acc'])
t_history = t_model.fit(train_aug,validation_data=valid_aug,epochs=50)
plot_loss_acc(aug_history,50)Epoch 1/50
338/338 [==============================] - 17s 35ms/step - loss: 1.1214 - acc: 0.6397 - val_loss: 0.6685 - val_acc: 0.7769
Epoch 2/50
338/338 [==============================] - 10s 30ms/step - loss: 0.7960 - acc: 0.7432 - val_loss: 0.5797 - val_acc: 0.8081
Epoch 49/50
338/338 [==============================] - 11s 31ms/step - loss: 0.4032 - acc: 0.8671 - val_loss: 0.4170 - val_acc: 0.8631
Epoch 50/50
338/338 [==============================] - 11s 31ms/step - loss: 0.4009 - acc: 0.8635 - val_loss: 0.4285 - val_acc: 0.8539
pred = t_model.predict(image.numpy().reshape(-1,64,64,3))
pred1/1 [==============================] - 2s 2s/step
array([[6.0538650e-03, 2.8989831e-05, 8.7860419e-04, 3.2317329e-02,
1.4384495e-05, 2.2318615e-02, 2.9983968e-04, 7.3251408e-07,
9.3794680e-01, 1.4082357e-04]], dtype=float32)CatsAndDogs
- 강아지와 고양이 이미지를 이용한 실습
import tensorflow as tf
from keras.preprocessing.image import ImageDataGenerator
import numpy as np
import matplotlib.pyplot as plt
import zipfilefrom google.colab import drive
drive.mount("/content/drive")Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount("/content/drive", force_remount=True).path = '/content/drive/MyDrive/Colab Notebooks/sesac_deeplearning/cats_and_dogs.zip'
zip_ref = zipfile.ZipFile(path,'r')
zip_ref.extractall('dataset/')
zip_ref.close()image_gen = ImageDataGenerator(rescale=(1/255.))
train_dir = '/content/dataset/cats_and_dogs_filtered/train'
valid_dir = '/content/dataset/cats_and_dogs_filtered/validation'
train_gen = image_gen.flow_from_directory(train_dir,
target_size=(224,224),
batch_size=32,
classes=['cats','dogs'],
class_mode='binary',
seed=2020)
valid_gen = image_gen.flow_from_directory(valid_dir,
target_size=(224,224),
batch_size=32,
classes=['cats','dogs'],
class_mode='binary',
seed=2020)Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.class_labels=['cats','dogs']
batch = next(train_gen)
images, labels = batch[0],batch[1]
plt.figure(figsize=(16,8))
for i in range(32):
ax = plt.subplot(4,8,i+1)
plt.imshow(images[i])
plt.title(class_labels[labels[i].astype(int)])
plt.axis('off')
plt.tight_layout()
plt.show()
images.shape(32, 224, 224, 3)from keras import Sequential
from keras.layers import Dense,Dropout,Flatten,Conv2D,MaxPooling2D,BatchNormalization
from keras.optimizers import Adam
from keras.losses import BinaryCrossentropy
def build_model():
model = Sequential([
BatchNormalization(),
Conv2D(32,(3,3),padding='same',activation='relu'),
MaxPooling2D((2,2)),
BatchNormalization(),
Conv2D(64,(3,3),padding='same',activation='relu'),
MaxPooling2D((2,2)),
BatchNormalization(),
Conv2D(128,(3,3),padding='same',activation='relu'),
MaxPooling2D((2,2)),
Flatten(),
Dense(256,activation='relu'),
Dropout(0.3),
Dense(1,activation='sigmoid'),
])
return modelmodel = build_model()model.compile(optimizer=Adam(0.001),loss=BinaryCrossentropy(),metrics=['acc'])
history = model.fit(train_gen,validation_data=valid_gen,epochs=20)Epoch 1/20
63/63 [==============================] - 14s 189ms/step - loss: 7.1242 - acc: 0.5330 - val_loss: 0.6887 - val_acc: 0.5930
Epoch 2/20
63/63 [==============================] - 11s 171ms/step - loss: 0.6544 - acc: 0.6050 - val_loss: 0.6836 - val_acc: 0.5790
Epoch 19/20
63/63 [==============================] - 11s 167ms/step - loss: 0.3159 - acc: 0.8475 - val_loss: 0.7343 - val_acc: 0.6910
Epoch 20/20
63/63 [==============================] - 11s 169ms/step - loss: 0.2872 - acc: 0.8525 - val_loss: 0.7057 - val_acc: 0.7140def plot_loss_acc(history,epoch):
loss,val_loss = history.history['loss'],history.history['val_loss']
acc,val_acc = history.history['acc'],history.history['val_acc']
fig, axes = plt.subplots(1,2,figsize=(12,4))
axes[0].plot(range(1, epoch+1), loss, label='train_loss')
axes[0].plot(range(1, epoch+1), val_loss, label='valid_loss')
axes[0].legend(loc='best')
axes[0].set_title('Loss')
axes[1].plot(range(1, epoch+1), acc, label='train_acc')
axes[1].plot(range(1, epoch+1), val_acc, label='valid_acc')
axes[1].legend(loc='best')
axes[1].set_title('Acc')
plt.show()plot_loss_acc(history,20)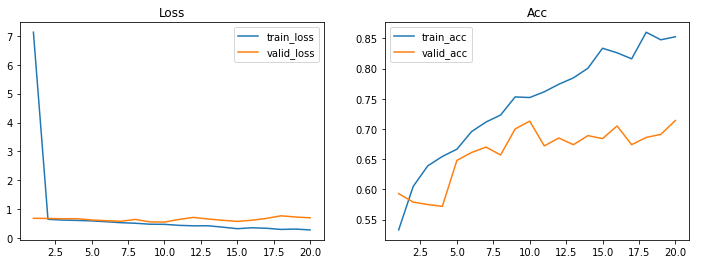
image_gen = ImageDataGenerator(rescale=(1/255.), horizontal_flip=True, zoom_range=0.2, rotation_range=35)
train_dir = '/content/dataset/cats_and_dogs_filtered/train'
valid_dir = '/content/dataset/cats_and_dogs_filtered/validation'
train_gen_aug = image_gen.flow_from_directory(train_dir,
target_size=(224,224),
batch_size=32,
classes=['cats','dogs'],
class_mode='binary',
seed=2020)
valid_gen_aug = image_gen.flow_from_directory(valid_dir,
target_size=(224,224),
batch_size=32,
classes=['cats','dogs'],
class_mode='binary',
seed=2020)Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.model_aug = build_model()
model_aug.compile(optimizer=Adam(0.001),loss=BinaryCrossentropy(),metrics=['acc'])
history_aug = model_aug.fit(train_gen_aug,validation_data=valid_gen_aug,epochs=20)Epoch 1/20
63/63 [==============================] - 38s 587ms/step - loss: 4.4823 - acc: 0.5235 - val_loss: 0.6911 - val_acc: 0.5040
Epoch 2/20
63/63 [==============================] - 36s 577ms/step - loss: 0.6575 - acc: 0.6090 - val_loss: 0.6842 - val_acc: 0.5250
Epoch 19/20
63/63 [==============================] - 36s 573ms/step - loss: 0.5465 - acc: 0.7170 - val_loss: 0.5709 - val_acc: 0.7040
Epoch 20/20
63/63 [==============================] - 36s 570ms/step - loss: 0.5493 - acc: 0.7085 - val_loss: 0.5507 - val_acc: 0.7240plot_loss_acc(history_aug,20)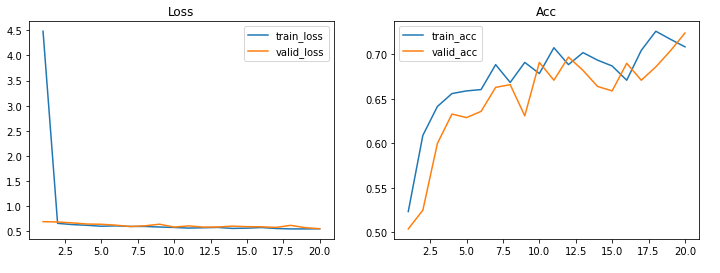
from keras.applications import ResNet50V2
pre_trained_base = ResNet50V2(include_top=False,
weights='imagenet',
input_shape=[224, 224, 3])
pre_trained_base.trainable = False
def build_trainsfer_model():
model = tf.keras.Sequential([
# Pre-trained Base
pre_trained_base,
# Classifier 출력층
Flatten(),
Dense(256,activation='relu'),
Dropout(0.3),
Dense(1,activation='sigmoid'),
])
return modelDownloading data from https://storage.googleapis.com/tensorflow/keras-applications/resnet/resnet50v2_weights_tf_dim_ordering_tf_kernels_notop.h5
94668760/94668760 [==============================] - 1s 0us/steptc_model = build_trainsfer_model()
tc_model.compile(optimizer=Adam(0.001),loss=BinaryCrossentropy(),metrics=['acc'])
history_t = tc_model.fit(train_gen_aug,validation_data=valid_gen_aug,epochs=20)Epoch 1/20
63/63 [==============================] - 41s 615ms/step - loss: 1.9358 - acc: 0.9325 - val_loss: 1.3339 - val_acc: 0.9550
Epoch 2/20
63/63 [==============================] - 38s 601ms/step - loss: 1.0656 - acc: 0.9605 - val_loss: 0.6684 - val_acc: 0.9720
Epoch 19/20
63/63 [==============================] - 37s 592ms/step - loss: 0.0573 - acc: 0.9885 - val_loss: 0.1257 - val_acc: 0.9730
Epoch 20/20
63/63 [==============================] - 38s 610ms/step - loss: 0.0309 - acc: 0.9910 - val_loss: 0.1306 - val_acc: 0.9700plot_loss_acc(history_t,20)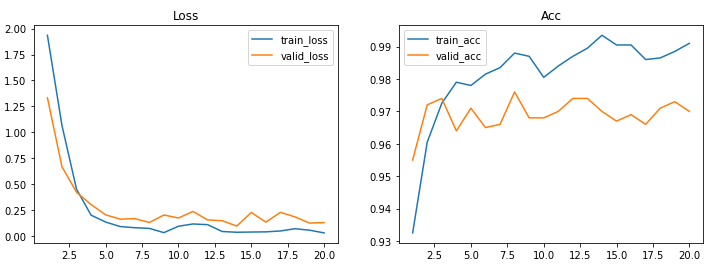

초보 개발자의 학습 저장용 블로그