교재 : 파이썬 머신러닝 완벽 가이드, 위키북스
부스팅(boosting)
LightGBM
- 예측 성능은 크게 차이나지 않으면서, 학습시간을 많이 줄여준다.
- 데이터가 적으면(10000개 이하) 과적합이 발생하기 쉽다는 게 단점.
- 리프 중심 트리 분할(Leaf Wise) : 필요한 가지는 독립적으로 뎁스를 계속 늘린다.
- max_depth를 크게 가지게 된다.
LightGBM 설치

LightGBM 실습
import lightgbmlightgbm.__version__'3.2.1'from lightgbm import LGBMClassifier
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_splitdataset = load_breast_cancer(as_frame=True)X = dataset.data
y = dataset.target
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=156)
X_tr,X_val,y_tr,y_val = train_test_split(X_train,y_train,test_size=0.1,random_state=156)lgbm = LGBMClassifier(n_estimators=400,learning_rate=0.05)
evals = [(X_tr,y_tr),(X_val,y_val)]
lgbm.fit(X_tr,y_tr,early_stopping_rounds=50,eval_metric='logloss',eval_set=evals,verbose=True)
# valid 최적인 61라운드 이후 +50인 111번에서 학습을 멈춤[1] training's binary_logloss: 0.625671 valid_1's binary_logloss: 0.628248
Training until validation scores don't improve for 50 rounds
[2] training's binary_logloss: 0.588173 valid_1's binary_logloss: 0.601106
[3] training's binary_logloss: 0.554518 valid_1's binary_logloss: 0.577587
[4] training's binary_logloss: 0.523972 valid_1's binary_logloss: 0.556324
[5] training's binary_logloss: 0.49615 valid_1's binary_logloss: 0.537407
[107] training's binary_logloss: 0.00986714 valid_1's binary_logloss: 0.279275
[108] training's binary_logloss: 0.00950998 valid_1's binary_logloss: 0.281427
[109] training's binary_logloss: 0.00915965 valid_1's binary_logloss: 0.280752
[110] training's binary_logloss: 0.00882581 valid_1's binary_logloss: 0.282152
[111] training's binary_logloss: 0.00850714 valid_1's binary_logloss: 0.280894
Early stopping, best iteration is:
[61] training's binary_logloss: 0.0532381 valid_1's binary_logloss: 0.260236
LGBMClassifier(learning_rate=0.05, n_estimators=400)pred = lgbm.predict(X_test)
pred_proba = lgbm.predict_proba(X_test)[:,1]get_clf_eval(y_test,pred,pred_proba)
# 오차행렬
# [[34 3]
# [ 2 75]]
# 정확도:0.9561, 정밀도:0.9615, 재현율0.9740, F1:0.9677, AUC:0.9937오차행렬
[[34 3]
[ 2 75]]
정확도:0.9561, 정밀도:0.9615, 재현율0.9740, F1:0.9677, AUC:0.9877lightgbm.plot_importance(lgbm, figsize=(10,12))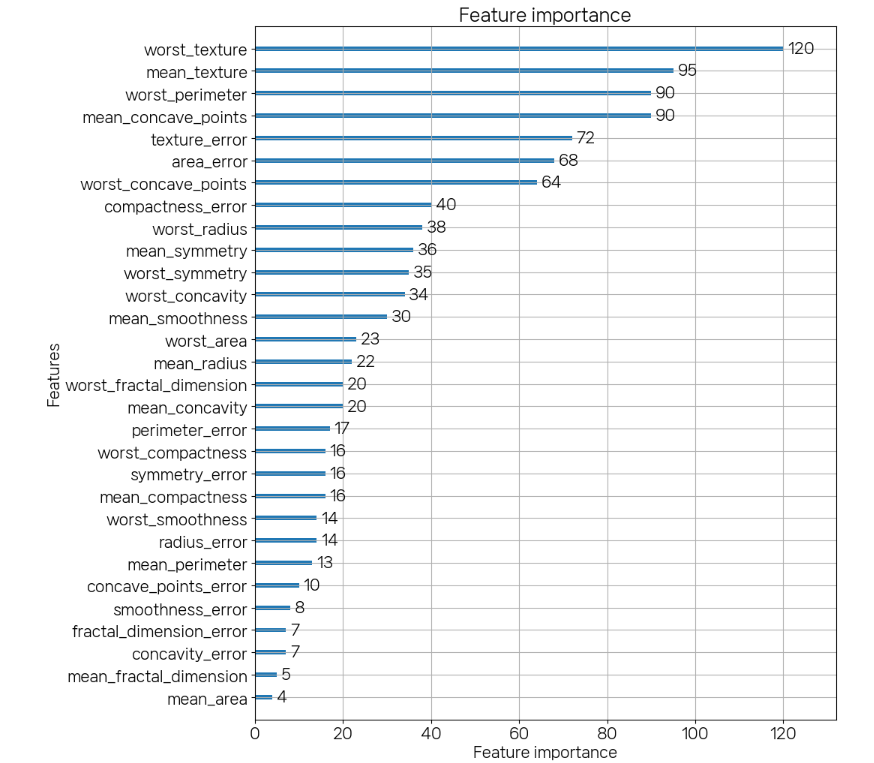
lightgbm.plot_tree(lgbm, figsize=(20,24))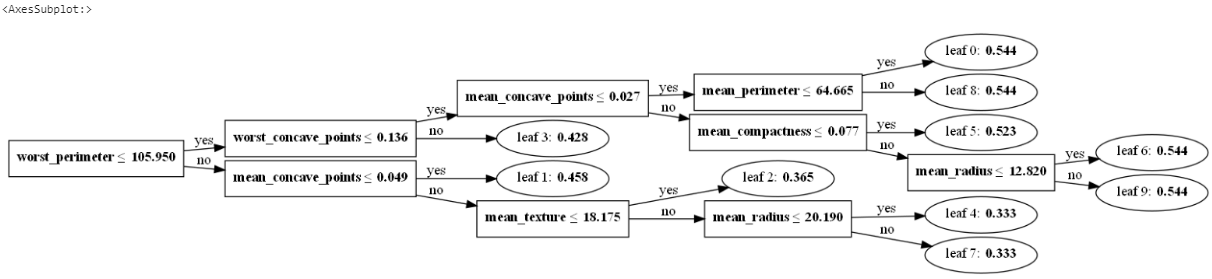
HyperOpt를 이용한 하이퍼 파라미터 튜닝
- 베이지안 최적화 기반
- 실측 값들을 이용하여 예측 함수와 신뢰영역을 만들어 추정
- 실측 값이 늘어날 때마다 추가

import hyperopthyperopt.__version__'0.2.7'dataset = load_breast_cancer(as_frame=True)
X = dataset.data
y = dataset.target
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=156)
X_tr,X_val,y_tr,y_val = train_test_split(X_train,y_train,test_size=0.1,random_state=156)from hyperopt import hp
from sklearn.model_selection import cross_val_score
from xgboost import XGBClassifier
from hyperopt import STATUS_OKsearch_space = {
'max_depth' : hp.quniform('max_depth',5,20,1),
'min_child_weight' : hp.quniform('min_child_weight',1,2,1),
'learning_rate' : hp.uniform('learning_rate',0.01,0.2),
'colsample_bytree' : hp.uniform('colsample_bytree',0.5,1),
}def objective_func(search_space):
xgb_clf = XGBClassifier(n_estimators=100,
max_depth=int(search_space['max_depth']),
min_child_weight=int(search_space['min_child_weight']),
learning_rate=search_space['learning_rate'],
colsample_bytree=search_space['colsample_bytree'],
eval_metric='logloss'
)
accuracy = cross_val_score(xgb_clf,X_train,y_train,scoring='accuracy',cv=3)
return {'loss': -1 * np.mean(accuracy),'status':STATUS_OK}from hyperopt import fmin,tpe,Trialstrial_val = Trials()
best = fmin(fn=objective_func,
space=search_space,
algo=tpe.suggest,
max_evals=50,
trials=trial_val,
rstate=np.random.default_rng(seed=9)
)100%|███████████████████████████████████████████████| 50/50 [00:27<00:00, 1.82trial/s, best loss: -0.9670616939700244]best{'colsample_bytree': 0.5424149213362504,
'learning_rate': 0.12601372924444681,
'max_depth': 17.0,
'min_child_weight': 2.0}model = XGBClassifier(n_estimators=400,
learning_rate=round(best['learning_rate'],5),
max_depth=int(best['max_depth']),
colsample_bytree=round(best['colsample_bytree'],5)
)
evals=[(X_tr,y_tr),(X_val,y_val)]
model.fit(X_tr,
y_tr,
verbose=True,
eval_set=evals,
early_stopping_rounds=50,
eval_metric='logloss')
pred = model.predict(X_test)
pred_proba = model.predict_proba(X_test)
get_clf_eval(y_test,pred,pred_proba[:,1])[0] validation_0-logloss:0.58790 validation_1-logloss:0.61868
[1] validation_0-logloss:0.50508 validation_1-logloss:0.55851
[2] validation_0-logloss:0.43765 validation_1-logloss:0.50619
[3] validation_0-logloss:0.38217 validation_1-logloss:0.46605
[4] validation_0-logloss:0.33580 validation_1-logloss:0.42885
[5] validation_0-logloss:0.29670 validation_1-logloss:0.39902
[6] validation_0-logloss:0.26380 validation_1-logloss:0.37296
[7] validation_0-logloss:0.23558 validation_1-logloss:0.35666
[8] validation_0-logloss:0.20966 validation_1-logloss:0.33804
[9] validation_0-logloss:0.18713 validation_1-logloss:0.32276
[10] validation_0-logloss:0.16775 validation_1-logloss:0.31127
[11] validation_0-logloss:0.15202 validation_1-logloss:0.30293
[12] validation_0-logloss:0.13778 validation_1-logloss:0.29834
[13] validation_0-logloss:0.12497 validation_1-logloss:0.28576
[14] validation_0-logloss:0.11423 validation_1-logloss:0.27825
[15] validation_0-logloss:0.10463 validation_1-logloss:0.27220
[16] validation_0-logloss:0.09516 validation_1-logloss:0.27093
[17] validation_0-logloss:0.08743 validation_1-logloss:0.27057
[18] validation_0-logloss:0.07972 validation_1-logloss:0.26596
[19] validation_0-logloss:0.07365 validation_1-logloss:0.26565
[20] validation_0-logloss:0.06814 validation_1-logloss:0.26198
[21] validation_0-logloss:0.06371 validation_1-logloss:0.26119
[22] validation_0-logloss:0.05880 validation_1-logloss:0.25854
[23] validation_0-logloss:0.05529 validation_1-logloss:0.25734
[24] validation_0-logloss:0.05187 validation_1-logloss:0.25330
[25] validation_0-logloss:0.04833 validation_1-logloss:0.25359
[26] validation_0-logloss:0.04552 validation_1-logloss:0.25237
[27] validation_0-logloss:0.04295 validation_1-logloss:0.25609
[28] validation_0-logloss:0.04063 validation_1-logloss:0.25919
[29] validation_0-logloss:0.03821 validation_1-logloss:0.25908
[30] validation_0-logloss:0.03615 validation_1-logloss:0.25943
[31] validation_0-logloss:0.03422 validation_1-logloss:0.26096
[32] validation_0-logloss:0.03241 validation_1-logloss:0.26072
[33] validation_0-logloss:0.03117 validation_1-logloss:0.26283
[34] validation_0-logloss:0.02953 validation_1-logloss:0.26460
[35] validation_0-logloss:0.02809 validation_1-logloss:0.26650
[36] validation_0-logloss:0.02689 validation_1-logloss:0.26701
[37] validation_0-logloss:0.02573 validation_1-logloss:0.26496
[38] validation_0-logloss:0.02466 validation_1-logloss:0.26396
[39] validation_0-logloss:0.02361 validation_1-logloss:0.26690
[40] validation_0-logloss:0.02276 validation_1-logloss:0.26593
[41] validation_0-logloss:0.02204 validation_1-logloss:0.26334
[42] validation_0-logloss:0.02132 validation_1-logloss:0.26546
[43] validation_0-logloss:0.02046 validation_1-logloss:0.26653
[44] validation_0-logloss:0.01974 validation_1-logloss:0.26633
[45] validation_0-logloss:0.01905 validation_1-logloss:0.26728
[46] validation_0-logloss:0.01859 validation_1-logloss:0.26421
[47] validation_0-logloss:0.01808 validation_1-logloss:0.26579
[48] validation_0-logloss:0.01755 validation_1-logloss:0.26687
[49] validation_0-logloss:0.01712 validation_1-logloss:0.26795
[50] validation_0-logloss:0.01668 validation_1-logloss:0.26988
[51] validation_0-logloss:0.01601 validation_1-logloss:0.26720
[52] validation_0-logloss:0.01555 validation_1-logloss:0.27026
[53] validation_0-logloss:0.01517 validation_1-logloss:0.27005
[54] validation_0-logloss:0.01485 validation_1-logloss:0.26930
[55] validation_0-logloss:0.01458 validation_1-logloss:0.26992
[56] validation_0-logloss:0.01437 validation_1-logloss:0.27048
[57] validation_0-logloss:0.01410 validation_1-logloss:0.27132
[58] validation_0-logloss:0.01388 validation_1-logloss:0.27194
[59] validation_0-logloss:0.01349 validation_1-logloss:0.27346
[60] validation_0-logloss:0.01307 validation_1-logloss:0.26871
[61] validation_0-logloss:0.01288 validation_1-logloss:0.26754
[62] validation_0-logloss:0.01267 validation_1-logloss:0.26841
[63] validation_0-logloss:0.01247 validation_1-logloss:0.26795
[64] validation_0-logloss:0.01230 validation_1-logloss:0.26995
[65] validation_0-logloss:0.01205 validation_1-logloss:0.27063
[66] validation_0-logloss:0.01188 validation_1-logloss:0.27146
[67] validation_0-logloss:0.01171 validation_1-logloss:0.27133
[68] validation_0-logloss:0.01152 validation_1-logloss:0.26995
[69] validation_0-logloss:0.01137 validation_1-logloss:0.26829
[70] validation_0-logloss:0.01123 validation_1-logloss:0.26727
[71] validation_0-logloss:0.01108 validation_1-logloss:0.26811
[72] validation_0-logloss:0.01093 validation_1-logloss:0.26845
[73] validation_0-logloss:0.01079 validation_1-logloss:0.26901
[74] validation_0-logloss:0.01067 validation_1-logloss:0.26842
[75] validation_0-logloss:0.01055 validation_1-logloss:0.26738
[76] validation_0-logloss:0.01042 validation_1-logloss:0.26814
오차행렬
[[34 3]
[ 3 74]]
정확도:0.9474, 정밀도:0.9610, 재현율0.9610, F1:0.9610, AUC:0.9916# 오차행렬
# [[34 3]
# [ 2 75]]
# 정확도:0.9561, 정밀도:0.9615, 재현율0.9740, F1:0.9677, AUC:0.9937
초보 개발자의 학습 저장용 블로그