교재 : 파이썬 머신러닝 완벽 가이드, 위키북스
회귀
- 이전 모델들보다 독립변수가 중요.
- 입력값들이 독립변수로 움직여서 결과값인 종속변수로 나오게 됨.
- 분류에서 예측값이 이산형으로 나온다면 회귀에서는 연속형으로 나옴.
- 다중공선성(Multi-collinearity) : 변수 간 상관관계가 높으면 분산이 커져서 오류에 매우 민감하게 반응하는 현상. 과적합처럼 최대한 방지해야 한다.
- 규제(Regularization) : 과적합 문제를 해결하기 위해 회귀 계수에 페널티를 주는 것.
- RSS(Residual Sum of Squares) : 오류값의 제곱을 구해서 더하는 방식.
회귀 모델 유형
- 일반 선형 회귀 : 예측값과 실제 값의 RSS를 최소화할 수 있도록 회귀 계수를 최적화한 모델. 규제를 적용하지 않는다.
- 릿지(Ridge) : 릿지 회귀는 선형 회귀에 L2 규제를 추가한 회귀 모델이다. L2 규제는 회귀 계수값을 더 작게 만드는 규제 모델이다.
- 라쏘(Lasso) : 라쏘 회귀는 선형 회귀에 L1 규제를 적용한 방식이다. L1 규제는 예측 영향력이 작은 feature의 회귀 계수를 0으로 만들어 선택되지 않게 하는 것이다. 이러한 특성 때문에 L1 규제는 feature 선택 기능이라고도 한다.
- 엘라스틱넷(ElasticNet) : L2, L1 규제를 함께 결합한 모델이다. 주로 feature가 많은 dataset에서 적용되며, L1 규제로 feature의 개수를 줄임과 동시에 L2 규제로 계수 값의 크기를 조정한다.
- 로지스틱 회귀(Logistic Regression) : 분류에 사용되는 선형 모델이다. 일반적으로 이진 분류 뿐만 아니라 희소 영역의 분류, 예를 들어 텍스트 분류와 같은 영역에서 뛰어난 예측 성능을 보인다.
경사하강법
import numpy as np
import matplotlib.pyplot as pltX = 2 * np.random.rand(100,1)y = 6 + 4 * X
plt.scatter(X, y)
y = 6 + 4 * X + np.random.randn(100,1)plt.scatter(X, y)
y = 6 + 4 * X + np.random.randn(100,1)plt.scatter(X, y)싸이킷런을 이용한 보스턴 주택 가격 예측
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_boston
import warnings
warnings.filterwarnings('ignore')boston = load_boston()pd.DataFrame(boston.data,columns=boston.feature_names)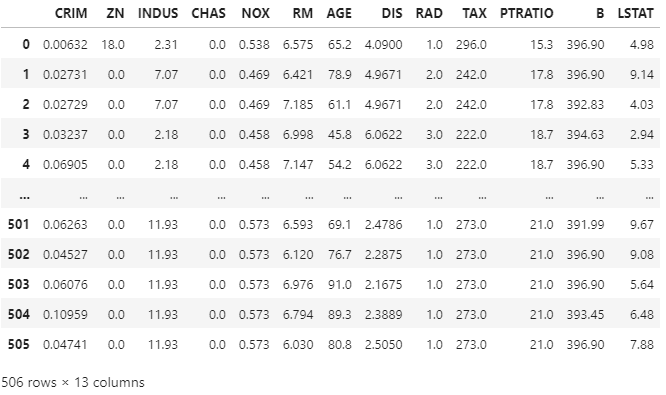
df = pd.DataFrame(boston.data,columns=boston.feature_names)
df['PRICE'] = boston.targetdf.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 506 entries, 0 to 505
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 CRIM 506 non-null float64
1 ZN 506 non-null float64
2 INDUS 506 non-null float64
3 CHAS 506 non-null float64
4 NOX 506 non-null float64
5 RM 506 non-null float64
6 AGE 506 non-null float64
7 DIS 506 non-null float64
8 RAD 506 non-null float64
9 TAX 506 non-null float64
10 PTRATIO 506 non-null float64
11 B 506 non-null float64
12 LSTAT 506 non-null float64
13 PRICE 506 non-null float64
dtypes: float64(14)
memory usage: 55.5 KBdf.columnsIndex(['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX',
'PTRATIO', 'B', 'LSTAT', 'PRICE'],
dtype='object')lm_features = ['ZN', 'INDUS', 'NOX', 'RM', 'AGE', 'RAD', 'PTRATIO', 'LSTAT']
fig,axs = plt.subplots(figsize=(16,8),ncols=4,nrows=2)
for i, feature in enumerate(lm_features):
row = int(i/4)
col = i % 4
sns.regplot(x=feature,y="PRICE",data=df,ax=axs[row][col])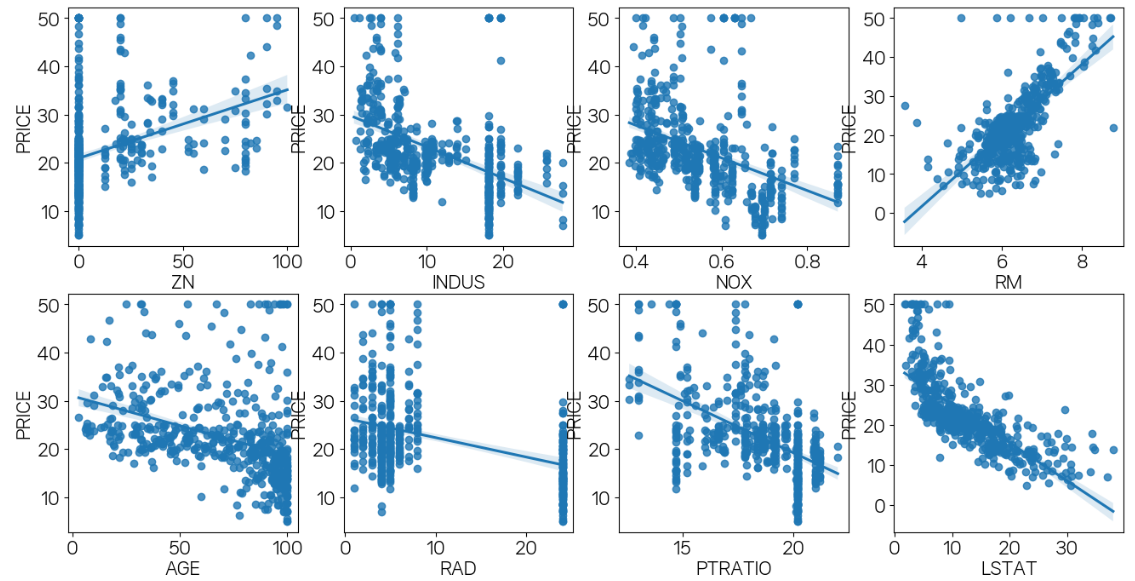
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error,r2_scorey = df['PRICE']
X = df.drop(columns=['PRICE'])
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=156)
lr = LinearRegression()
lr.fit(X_train,y_train)
pred = lr.predict(X_test)
mse = mean_squared_error(y_test,pred)
rmse = np.sqrt(mse)
print(f'MSE:{mse}, RMSE:{rmse}, R2:{r2_score(y_test,pred)}')MSE:17.296915907901973, RMSE:4.158956107955694, R2:0.7572263323138947lr.coef_,1(array([-1.12979614e-01, 6.55124002e-02, 3.44366694e-02, 3.04589777e+00,
-1.97958320e+01, 3.35496880e+00, 5.93713290e-03, -1.74185354e+00,
3.55884364e-01, -1.42954516e-02, -9.20180066e-01, 1.03966156e-02,
-5.66182106e-01]),
1)np.round(lr.coef_,1)array([ -0.1, 0.1, 0. , 3. , -19.8, 3.4, 0. , -1.7, 0.4,
-0. , -0.9, 0. , -0.6])pd.Series(np.round(lr.coef_,1),index=X.columns).sort_values(ascending=False)RM 3.4
CHAS 3.0
RAD 0.4
ZN 0.1
INDUS 0.0
AGE 0.0
TAX -0.0
B 0.0
CRIM -0.1
LSTAT -0.6
PTRATIO -0.9
DIS -1.7
NOX -19.8
dtype: float64lr.intercept_40.995595172164585from sklearn.model_selection import cross_val_scoreneg_mse_scores = cross_val_score(lr,X,y,scoring='neg_mean_squared_error',cv=5)neg_mse_scoresarray([-12.46030057, -26.04862111, -33.07413798, -80.76237112,
-33.31360656])np.mean(np.sqrt(neg_mse_scores * -1))5.828658946215817from sklearn.linear_model import Ridge
from sklearn.model_selection import cross_val_scoreridge = Ridge(alpha=10)
neg_mse_scores = cross_val_score(ridge,X,y,scoring='neg_mean_squared_error',cv=5)np.mean(np.sqrt(neg_mse_scores * -1))5.518166280868971alphas=[0,0.1,1,10,100]
for alpha in alphas:
ridge = Ridge(alpha=alpha)
neg_mse_scores = cross_val_score(ridge,X,y,scoring='neg_mean_squared_error',cv=5)
print(np.mean(np.sqrt(neg_mse_scores * -1)))5.828658946215802
5.788486627032408
5.652570965613541
5.518166280868971
5.329589628472145fig, axs = plt.subplots(figsize=(18,6),nrows=1,ncols=5)
coeff_df = pd.DataFrame()
for pos, alpha in enumerate(alphas):
ridge = Ridge(alpha=alpha)
ridge.fit(X,y)
coeff = pd.Series(ridge.coef_,index=X.columns)
colname = 'alpha:'+str(alpha)
coeff_df[colname] = coeff
coeff = coeff.sort_values(ascending=False)
axs[pos].set_title(colname)
axs[pos].set_xlim(-3,6)
sns.barplot(x=coeff.values,y=coeff.index,ax=axs[pos])
plt.show()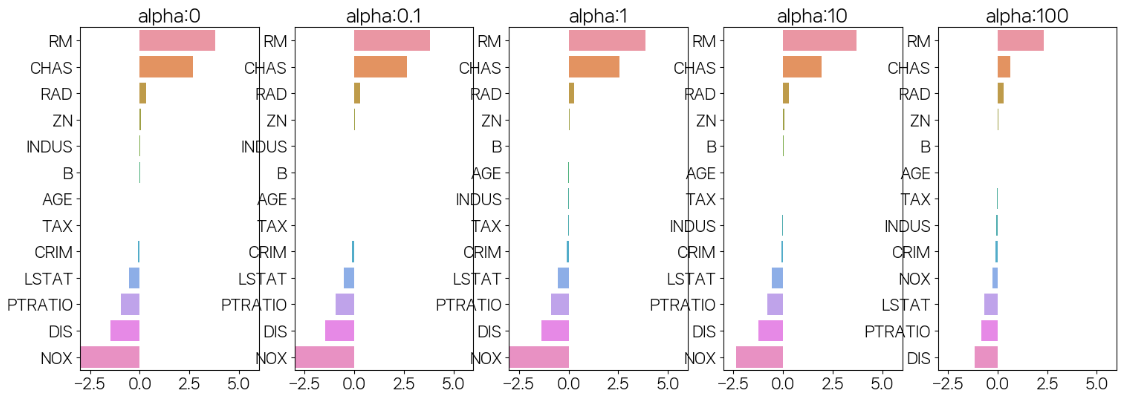
ridge_alphas = [0, 0.1, 1, 10, 100]
sort_column = 'alpha:'+str(ridge_alphas[0])
coeff_df.sort_values(by=sort_column, ascending=False)
from sklearn.linear_model import Lasso, ElasticNet
# alpha값에 따른 회귀 모델의 폴드 평균 RMSE를 출력하고 회귀 계수값들을 DataFrame으로 반환
def get_linear_reg_eval(model_name, params=None, X_data_n=None, y_target_n=None,
verbose=True, return_coeff=True):
coeff_df = pd.DataFrame()
if verbose : print('####### ', model_name , '#######')
for param in params:
if model_name =='Ridge': model = Ridge(alpha=param)
elif model_name =='Lasso': model = Lasso(alpha=param)
elif model_name =='ElasticNet': model = ElasticNet(alpha=param, l1_ratio=0.7)
neg_mse_scores = cross_val_score(model, X_data_n,
y_target_n, scoring="neg_mean_squared_error", cv = 5)
avg_rmse = np.mean(np.sqrt(-1 * neg_mse_scores))
print('alpha {0}일 때 5 폴드 세트의 평균 RMSE: {1:.3f} '.format(param, avg_rmse))
# cross_val_score는 evaluation metric만 반환하므로 모델을 다시 학습하여 회귀 계수 추출
model.fit(X_data_n , y_target_n)
if return_coeff:
# alpha에 따른 피처별 회귀 계수를 Series로 변환하고 이를 DataFrame의 컬럼으로 추가.
coeff = pd.Series(data=model.coef_ , index=X_data_n.columns )
colname='alpha:'+str(param)
coeff_df[colname] = coeff
return coeff_df
# end of get_linear_regre_eval# 라쏘에 사용될 alpha 파라미터의 값을 정의하고 get_linear_reg_eval() 함수 호출
lasso_alphas = [0.05,0.07,0.1,0.5,1,3]
coeff_lasso_df = get_linear_reg_eval('Lasso',
params=lasso_alphas,
X_data_n=X,
y_target_n=y)####### Lasso #######
alpha 0.05일 때 5 폴드 세트의 평균 RMSE: 5.628
alpha 0.07일 때 5 폴드 세트의 평균 RMSE: 5.612
alpha 0.1일 때 5 폴드 세트의 평균 RMSE: 5.615
alpha 0.5일 때 5 폴드 세트의 평균 RMSE: 5.669
alpha 1일 때 5 폴드 세트의 평균 RMSE: 5.776
alpha 3일 때 5 폴드 세트의 평균 RMSE: 6.189 elastic_alphas = [0.05,0.07,0.1,0.5,1,3]
coeff_elastic_df = get_linear_reg_eval('ElasticNet',
params=elastic_alphas,
X_data_n=X,
y_target_n=y)####### ElasticNet #######
alpha 0.05일 때 5 폴드 세트의 평균 RMSE: 5.555
alpha 0.07일 때 5 폴드 세트의 평균 RMSE: 5.542
alpha 0.1일 때 5 폴드 세트의 평균 RMSE: 5.526
alpha 0.5일 때 5 폴드 세트의 평균 RMSE: 5.467
alpha 1일 때 5 폴드 세트의 평균 RMSE: 5.597
alpha 3일 때 5 폴드 세트의 평균 RMSE: 6.068 from sklearn.preprocessing import StandardScaler, MinMaxScaler, PolynomialFeatures
# method는 표준 정규 분포 변환(Standard), 최대값/최소값 정규화(MinMax), 로그변환(Log) 결정
# p_degree는 다향식 특성을 추가할 때 적용. p_degree는 2이상 부여하지 않음.
def get_scaled_data(method='None', p_degree=None, input_data=None):
if method == 'Standard':
scaled_data = StandardScaler().fit_transform(input_data)
elif method == 'MinMax':
scaled_data = MinMaxScaler().fit_transform(input_data)
elif method == 'Log':
scaled_data = np.log1p(input_data)
else:
scaled_data = input_data
if p_degree != None:
scaled_data = PolynomialFeatures(degree=p_degree,
include_bias=False).fit_transform(scaled_data)
return scaled_dataalphas=[0.1,1,10,100]
scale_methods=[(None,None),
('Standard',None),
('Standard',2),
('MinMax',None),
('MinMax',2),
('Log',None)]
for scale_method in scale_methods:
X_scaled_data = get_scaled_data(method=scale_method[0], p_degree=scale_method[1], input_data=X)
print(f'{scale_method[0]} {scale_method[1]}')
coeff_elastic_df = get_linear_reg_eval('Ridge',
params=alphas,
X_data_n=X_scaled_data,
y_target_n=y,
return_coeff=False)None None
####### Ridge #######
alpha 0.1일 때 5 폴드 세트의 평균 RMSE: 5.788
alpha 1일 때 5 폴드 세트의 평균 RMSE: 5.653
alpha 10일 때 5 폴드 세트의 평균 RMSE: 5.518
alpha 100일 때 5 폴드 세트의 평균 RMSE: 5.330
Standard None
####### Ridge #######
alpha 0.1일 때 5 폴드 세트의 평균 RMSE: 5.826
alpha 1일 때 5 폴드 세트의 평균 RMSE: 5.803
alpha 10일 때 5 폴드 세트의 평균 RMSE: 5.637
alpha 100일 때 5 폴드 세트의 평균 RMSE: 5.421
Standard 2
####### Ridge #######
alpha 0.1일 때 5 폴드 세트의 평균 RMSE: 8.827
alpha 1일 때 5 폴드 세트의 평균 RMSE: 6.871
alpha 10일 때 5 폴드 세트의 평균 RMSE: 5.485
alpha 100일 때 5 폴드 세트의 평균 RMSE: 4.634
MinMax None
####### Ridge #######
alpha 0.1일 때 5 폴드 세트의 평균 RMSE: 5.764
alpha 1일 때 5 폴드 세트의 평균 RMSE: 5.465
alpha 10일 때 5 폴드 세트의 평균 RMSE: 5.754
alpha 100일 때 5 폴드 세트의 평균 RMSE: 7.635
MinMax 2
####### Ridge #######
alpha 0.1일 때 5 폴드 세트의 평균 RMSE: 5.298
alpha 1일 때 5 폴드 세트의 평균 RMSE: 4.323
alpha 10일 때 5 폴드 세트의 평균 RMSE: 5.185
alpha 100일 때 5 폴드 세트의 평균 RMSE: 6.538
Log None
####### Ridge #######
alpha 0.1일 때 5 폴드 세트의 평균 RMSE: 4.770
alpha 1일 때 5 폴드 세트의 평균 RMSE: 4.676
alpha 10일 때 5 폴드 세트의 평균 RMSE: 4.836
alpha 100일 때 5 폴드 세트의 평균 RMSE: 6.241 - 그래프 중 인과관계가 선명히 나오는 것은 RM, LSTAT이다.

초보 개발자의 학습 저장용 블로그