교재 : 파이썬 머신러닝 완벽 가이드, 위키북스
머신러닝 분류
결정 트리(Decision Tree)
- 루트 노드 -> 규칙 노드 -> 리프 노드
- 균일도가 높은 집단을 먼저 분류할수록 좋음
- 엔트로피 지수가 높을수록 균일도가 떨어지고, 지니 계수도 높을수록 균일도가 떨어짐
- 따라서 엔트로피 지수와 지니 계수가 낮은 조건을 찾아서 분류를 하게 됨
결정 트리의 장단점
- 장점 : 직관적. 사전 가공의 영향도가 작음.
- 단점 : 과적합으로 정확도가 떨어짐.
결정 트리 파라미터
min_samples_split
min_samples_leaf
max_features
max_depth
max_leaf_nodes
과적합 방지를 위해 세팅 필요
결정 트리 모델 시각화
Graphviz
- 결정 트리 모델 시각화 도구
- conda install로 설치가 안되는 경우가 있는데 이 경우에는 pip install로 진행하여 해결함.
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_splitdt_clf = DecisionTreeClassifier(random_state=156)
iris = load_iris()
X_train,X_test,y_train,y_test = train_test_split(iris.data,iris.target,test_size=0.2,random_state=11)
dt_clf.fit(X_train,y_train)DecisionTreeClassifier(random_state=156)from sklearn.tree import export_graphvizexport_graphviz(dt_clf,
'iris.dot',
class_names=iris.target_names,
feature_names=iris.feature_names,
filled=True)import graphvizwith open('iris.dot') as f:
dot_graph = f.read()
graphviz.Source(dot_graph)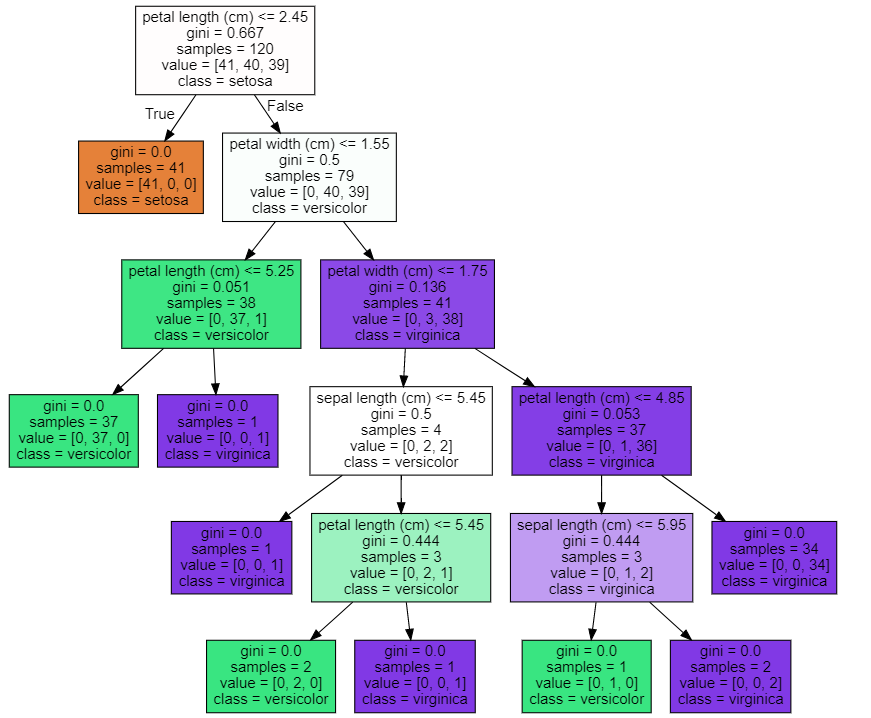
- max_depth로 깊이 조절
dt_clf = DecisionTreeClassifier(random_state=156,max_depth=2)
dt_clf.fit(X_train,y_train)
export_graphviz(dt_clf,
'iris1.dot',
class_names=iris.target_names,
feature_names=iris.feature_names,
filled=True)
with open('iris1.dot') as f:
dot_graph = f.read()
graphviz.Source(dot_graph)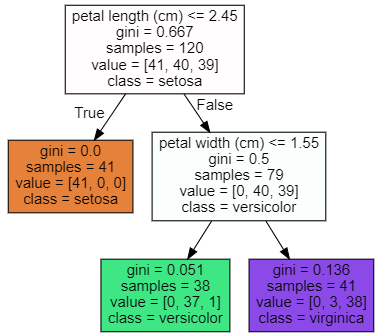
- min_samples_split으로 쪼개기 최소 수 조절
dt_clf = DecisionTreeClassifier(random_state=156,min_samples_split=4)
dt_clf.fit(X_train,y_train)
export_graphviz(dt_clf,
'iris1.dot',
class_names=iris.target_names,
feature_names=iris.feature_names,
filled=True)
with open('iris1.dot') as f:
dot_graph = f.read()
graphviz.Source(dot_graph)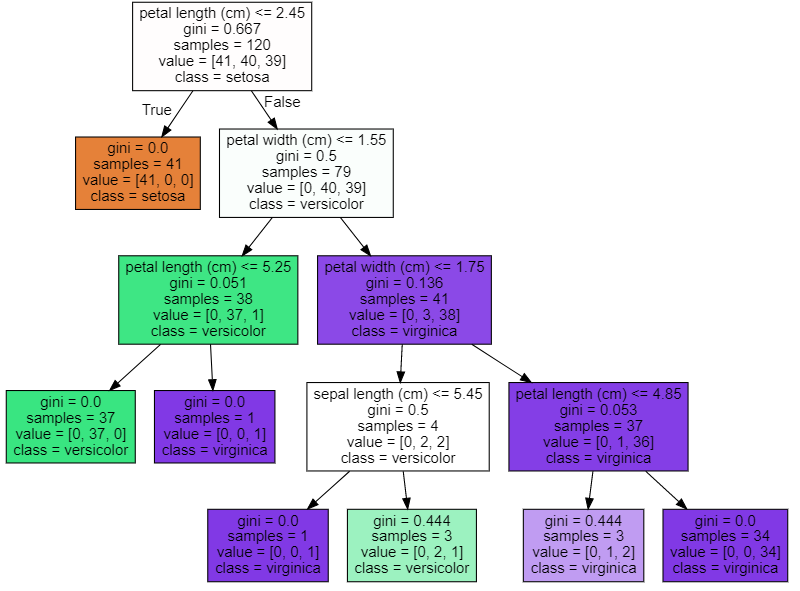
결정 트리 과적합(Overfitting)
- 결정 트리 모델로 과적합이 어떻게 나타나는지 시각화 해보기
from sklearn.datasets import make_classification
import matplotlib.pyplot as pltX, y = make_classification(n_features=2,n_redundant=0,n_classes=3,n_clusters_per_class=1,random_state=0)plt.scatter(X[:,0],X[:,1])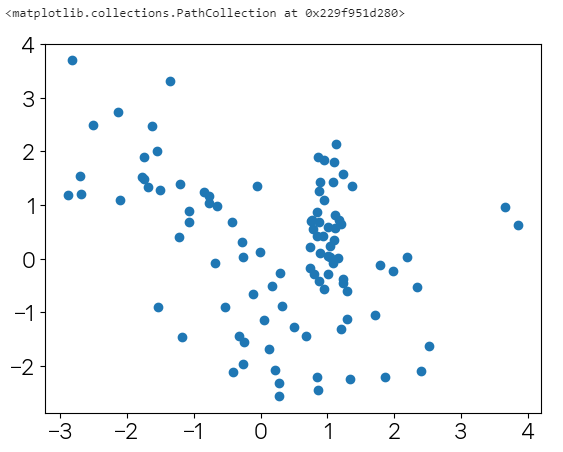
plt.rcParams['axes.unicode_minus']=False
plt.scatter(X[:,0],X[:,1],c=y,edgecolors='k',s=25)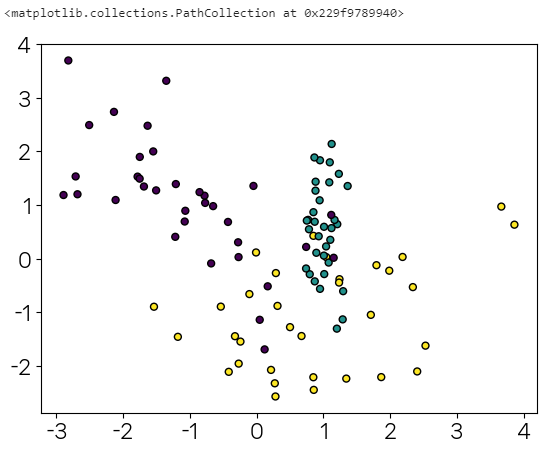
dt_clf = DecisionTreeClassifier(random_state=156).fit(X,y)func01.visualize_boundary(dt_clf,X,y)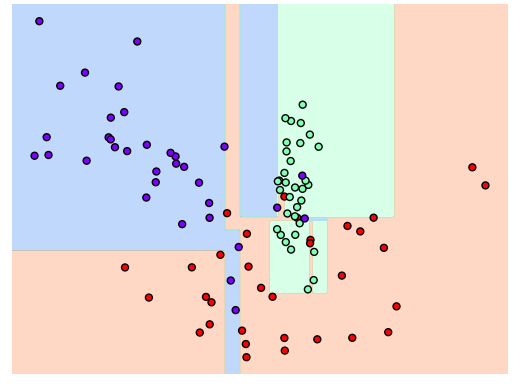
- 결정 기준 경계가 많고 복잡하므로, 6개 이하의 데이터는 리프 노드를 생성하지 않게 만든다.
dt_clf = DecisionTreeClassifier(min_samples_leaf=6,random_state=156).fit(X,y)
func01.visualize_boundary(dt_clf,X,y)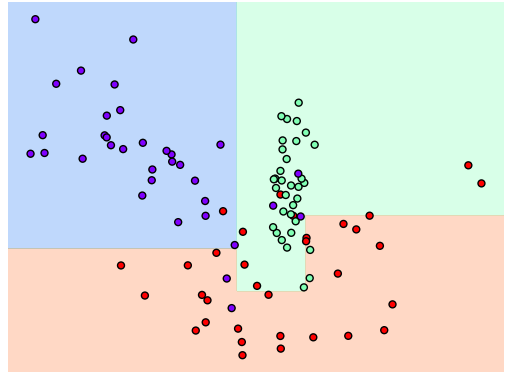
Human Activity Recognition Using Smartphones Data Set
*https://archive.ics.uci.edu/ml/datasets/human+activity+recognition+using+smartphones

초보 개발자의 학습 저장용 블로그