교재 : 파이썬 머신러닝 완벽 가이드, 위키북스
데이터 전처리
- NaN, Null값 제거
데이터 인코딩
레이블 인코딩
- 데이터마다 레이블값을 매김
- 단점 : 1, 2, 3 식으로 레이블값을 매기므로, 알고리즘(회귀 등)에 따라 숫자에 가중치를 부여할 수 있음
원-핫 인코딩
- 컬럼을 레이블 갯수만큼 만들어 해당되면 1, 아니면 0값을 매기는 방식
피처 스케일링과 정규화
- MinMaxScaler를 이용해 표준화와 정규화
- fit, transform 사용.
- 유의점 : fit은 학습 데이터에만 적용하고 테스트 데이터에는 적용하면 안 된다.
->테스트 데이터도 fit을 주면 결과값이 바뀔 수 있음.
items = ['TV','냉장고','전자레인지','컴퓨터','선풍기','선풍기','믹서','믹서']
encoder = LabelEncoder()
encoder.fit(items)
labels = encoder.transform(items)items
items_t = np.array(items).reshape(-1, 1)
items_tarray([['TV'],
['냉장고'],
['전자레인지'],
['컴퓨터'],
['선풍기'],
['선풍기'],
['믹서'],
['믹서']], dtype='<U5')items_l = [['TV'],
['냉장고'],
['전자레인지'],
['컴퓨터'],
['선풍기'],
['선풍기'],
['믹서'],
['믹서']]oh_encoder = OneHotEncoder()
oh_encoder.fit(items_l)
result = oh_encoder.transform(items_l)
result.toarray()array([[1., 0., 0., 0., 0., 0.],
[0., 1., 0., 0., 0., 0.],
[0., 0., 0., 0., 1., 0.],
[0., 0., 0., 0., 0., 1.],
[0., 0., 0., 1., 0., 0.],
[0., 0., 0., 1., 0., 0.],
[0., 0., 1., 0., 0., 0.],
[0., 0., 1., 0., 0., 0.]])oh_encoder.categories_[array(['TV', '냉장고', '믹서', '선풍기', '전자레인지', '컴퓨터'], dtype=object)]oh_encoder.inverse_transform([[1., 0., 0., 0., 0., 0.]])array([['TV']], dtype=object)import pandas as pddf = pd.DataFrame({'item':['TV', '냉장고', '전자레인지', '컴퓨터', '선풍기', '선풍기', '믹서', '믹서']})pd.get_dummies(df['item'])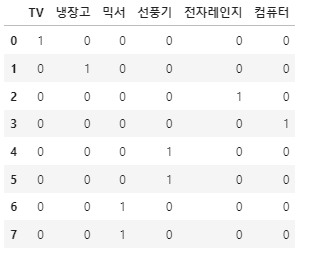
타이타닉 생존자 예측
pd.read_csv('titanic.csv')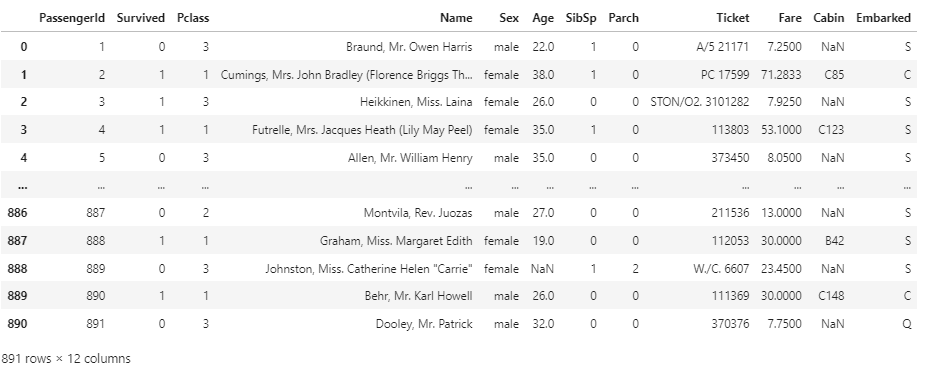
df = pd.read_csv('titanic.csv')
df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KBdf.isnull().sum()PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64df['Age'].fillna(df['Age'].mean(),inplace=True)
df['Cabin'].fillna('N',inplace=True)
df['Embarked'].fillna('N',inplace=True)df.isnull().sum()PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 0
Embarked 0
dtype: int64plt.figure(figsize=(10,6))
group_name = ['Unknown','Baby','Child','Teenager','Student','Young Adult','Adult','Elderly']
sns.barplot(data=df,x='Age_cat',y='Survived',hue='Sex',order=group_name)

초보 개발자의 학습 저장용 블로그