머신러닝 환경설정
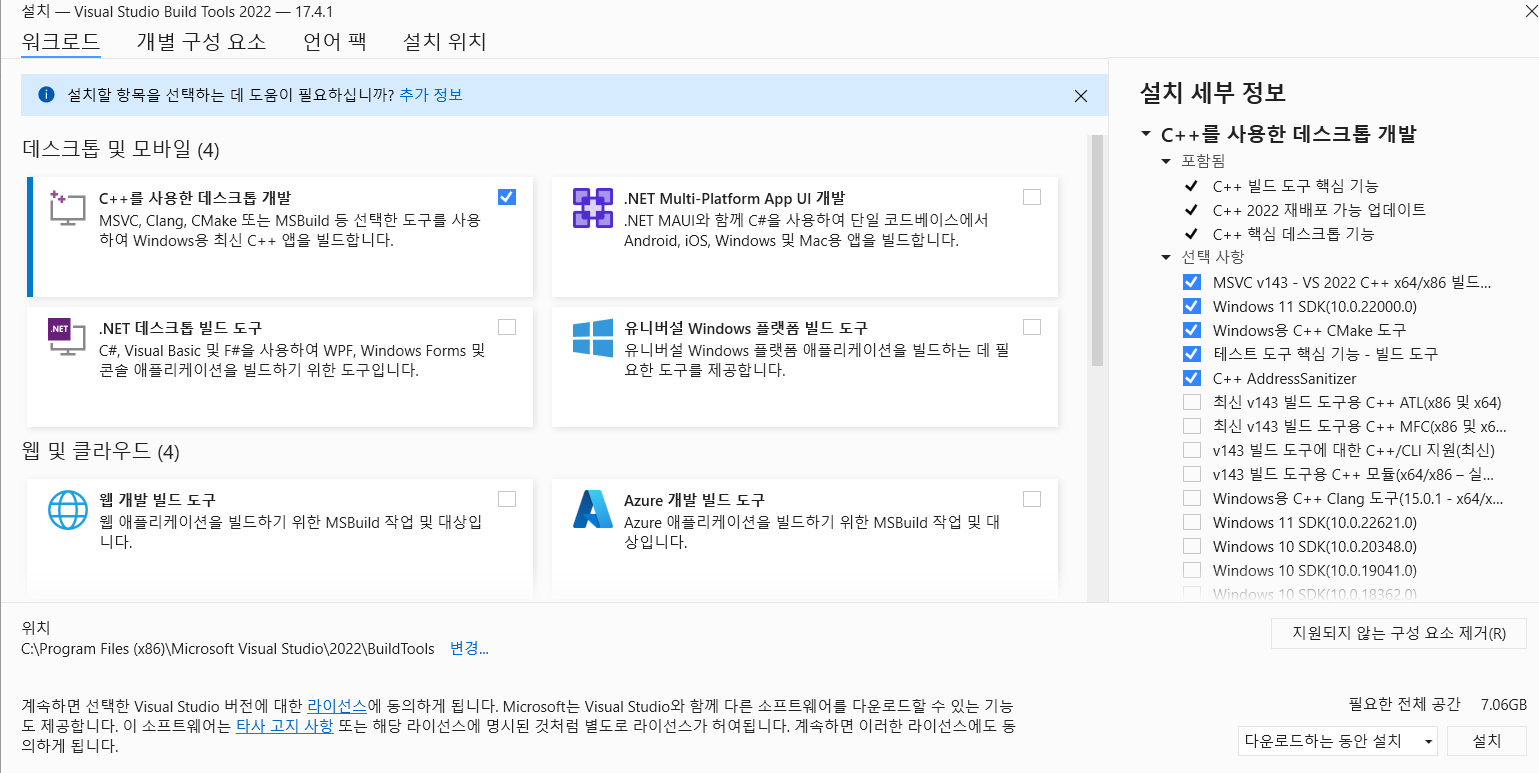
Visual Studio Tools

머신러닝 개요
- 지도 학습
- 비지도 학습
- 강화 학습
지도 학습
- 분류
- 군집화
- 선형 회귀
선형회귀
- 손실함수 : 실측값에서 오차값 뺀 값을 제곱
- 경사하강법 : 기울기가 0인 곳을 향하여 이동
- https://blog.naver.com/beyondlegend/222161152322
비지도학습
- 군집 : K-means Clustering(평균 군집)
사이킷런
- 수업 교재 : 파이썬 머신러닝 완벽 가이드(위키북스, 권철민)
- 교재 2장에 해당되는 내용
!python -V-> Python 3.9.13
import sklearnsklearn.__version__-> '1.0.2'
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
import pandas as pdiris = load_iris(as_frame=True)
iris.data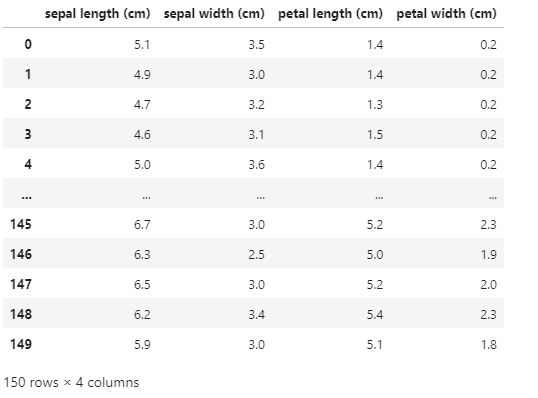
K-fold
- 보통 5분할 후 하나씩 돌려가면서 나머지 집단을 학습시켜서 테스트
cv_accuracy = []
n_iter = 0
for train_index,test_index in kfold.split(iris.data):
# print(train_index)
# print(test_index)
X_train,X_test = iris.data[train_index],iris.data[test_index]
y_train,y_test = iris.target[train_index],iris.target[test_index]
dt_clf.fit(X_train,y_train)
pred = dt_clf.predict(X_test)
n_iter += 1
accuracy = accuracy_score(y_test,pred)
cv_accuracy.append(accuracy)
print(n_iter,accuracy)
print(y_test)

초보 개발자의 학습 저장용 블로그